
Hvordan identifisere AI-crawlere i serverloggene dine
Lær å identifisere og overvåke AI-crawlere som GPTBot, ClaudeBot og PerplexityBot i serverloggene dine. Komplett guide med user-agent-strenger, IP-verifisering ...
8 min lesing

Lær hvordan du reviderer AI-crawlertilgang til nettstedet ditt. Oppdag hvilke boter som kan se innholdet ditt og løs blokkeringer som hindrer AI-synlighet i ChatGPT, Perplexity og andre AI-søkemotorer.
Landskapet for søk og innholdsoppdagelse endres dramatisk. Med AI-drevne søkeverktøy som ChatGPT, Perplexity og Google AI Overviews i eksplosiv vekst, har synligheten til innholdet ditt for AI-crawlere blitt like kritisk som tradisjonell søkemotoroptimalisering. Hvis AI-boter ikke får tilgang til innholdet ditt, blir nettstedet ditt usynlig for millioner av brukere som stoler på disse plattformene for svar. Innsatsen er høyere enn noen gang: Mens Google kanskje kommer tilbake til nettstedet ditt hvis noe går galt, opererer AI-crawlere på et annet paradigme – og å miste det første kritiske crawlet kan bety måneder med tapt synlighet og tapte muligheter for siteringer, trafikk og merkevareautoritet.
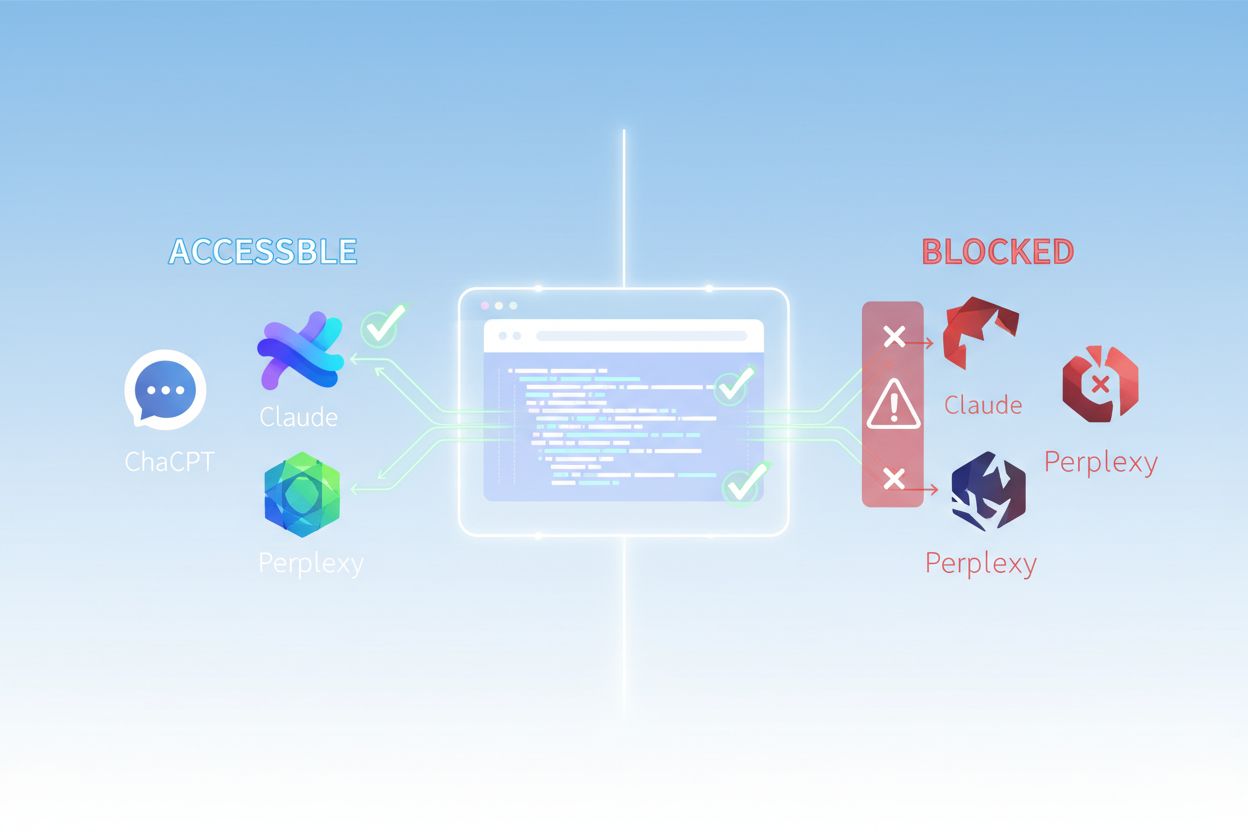
AI-crawlere opererer etter fundamentalt andre regler enn Google- og Bing-botene du har optimalisert for i årevis. Den viktigste forskjellen: AI-crawlere gjengir ikke JavaScript, noe som betyr at dynamisk innhold lastet via klientside-skript er usynlig for dem – i sterk kontrast til Googles avanserte gjengivelsesevner. I tillegg besøker AI-crawlere nettsteder med dramatisk høyere frekvens, noen ganger 100 ganger oftere enn tradisjonelle søkemotorer, noe som skaper både muligheter og utfordringer for serverressurser. I motsetning til Googles indekseringsmodell, opprettholder ikke AI-crawlere en vedvarende indeks som stadig oppdateres; de crawler på forespørsel hver gang en bruker søker i systemene deres. Dette betyr at det ikke finnes noen re-indekseringskø, ingen Search Console for å be om ny crawling, og ingen andre sjanser hvis nettstedet ditt feiler på førsteinntrykket. Å forstå disse forskjellene er avgjørende for å optimalisere innholdsstrategien din.
| Funksjon | AI-crawlere | Tradisjonelle boter |
|---|---|---|
| JavaScript-gjengivelse | Nei (bare statisk HTML) | Ja (full gjengivelse) |
| Crawl-frekvens | Svært høy (100x+ oftere) | Moderat (ukentlig/månedlig) |
| Re-indekseringsevne | Ingen (kun på forespørsel) | Ja (kontinuerlige oppdateringer) |
| Innholdskrav | Ren HTML, skjemaoppmerking | Fleksibelt (håndterer dynamisk innhold) |
| User-Agent-blokkering | Spesifikk per bot (GPTBot, ClaudeBot, osv.) | Generisk (Googlebot, Bingbot) |
| Cache-strategi | Kortsiktige øyeblikksbilder | Langsiktig indeksvedlikehold |
Innholdet ditt kan være usynlig for AI-crawlere av grunner du kanskje aldri har vurdert. Her er de viktigste hindringene som hindrer AI-boter fra å få tilgang til og forstå innholdet ditt:
Din robots.txt-fil er hovedmekanismen for å kontrollere hvilke AI-boter som får tilgang til innholdet ditt, og den fungerer gjennom spesifikke User-Agent-regler som retter seg mot individuelle crawlere. Hver AI-plattform bruker egne user-agent-strenger – OpenAIs GPTBot, Anthropics ClaudeBot, Perplexitys PerplexityBot – og du kan tillate eller nekte hver enkelt uavhengig av hverandre. Denne granulære kontrollen lar deg bestemme hvilke AI-systemer som kan trene på eller sitere innholdet ditt, noe som er avgjørende for å beskytte konfidensiell informasjon eller håndtere konkurransehensyn. Mange nettsteder blokkerer imidlertid uvitende AI-crawlere gjennom altfor brede regler laget for eldre boter, eller de unnlater å implementere riktige regler i det hele tatt.
Her er et eksempel på hvordan du konfigurerer robots.txt for ulike AI-boter:
# Tillat OpenAIs GPTBot
User-agent: GPTBot
Allow: /
# Blokker Anthropics ClaudeBot
User-agent: ClaudeBot
Disallow: /
# Tillat Perplexity, men begrens enkelte kataloger
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# Standardregel for alle andre boter
User-agent: *
Allow: /
I motsetning til Google, som kontinuerlig crawler og re-indekserer nettstedet ditt, opererer AI-crawlere på en “one-shot”-basis – de besøker når en bruker søker i systemet, og hvis innholdet ditt ikke er tilgjengelig akkurat da, har du tapt muligheten. Denne grunnleggende forskjellen betyr at nettstedet ditt må være teknisk klart fra dag én; det finnes ingen prøvetid, ingen andre sjanse til å rette feil før synligheten lider. En dårlig første crawl-opplevelse – enten på grunn av JavaScript-gjengivelsesfeil, manglende skjemaoppmerking eller serverfeil – kan føre til at innholdet ditt blir utelatt fra AI-genererte svar i uker eller måneder. Det finnes ingen manuell re-indekseringsmulighet, ingen “Be om indeksering”-knapp i en konsoll, noe som gjør proaktiv overvåking og optimalisering uunnværlig. Presset for å lykkes på første forsøk har aldri vært større.
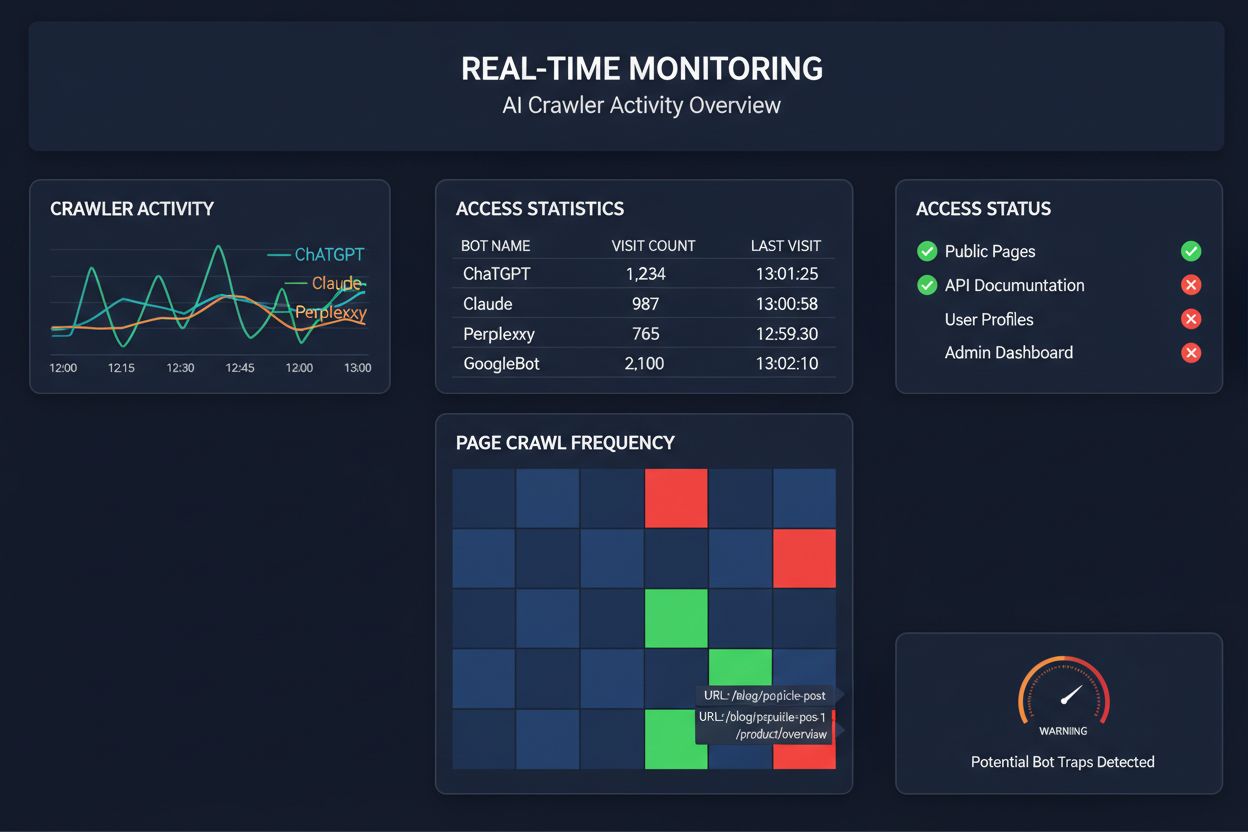
Å stole på planlagte crawls for å overvåke AI-crawlertilgang er som å sjekke huset ditt for brann én gang i måneden – du går glipp av de kritiske øyeblikkene når problemer oppstår. Sanntidsovervåking oppdager problemer idet de skjer, slik at du kan reagere før innholdet ditt blir usynlig for AI-systemer. Planlagte revisjoner, som ofte kjøres ukentlig eller månedlig, skaper farlige blindsone der nettstedet ditt kan feile for AI-crawlere i flere dager uten at du vet det. Sanntidsløsninger sporer crawleratferd kontinuerlig, og varsler deg om JavaScript-gjengivelsesfeil, skjemaoppmerkingsfeil, brannmurblokker eller serverproblemer etter hvert som de oppstår. Denne proaktive tilnærmingen gjør revisjonen om fra en reaktiv samsvarsjekk til en aktiv synlighetsstyringsstrategi. Med AI-crawlertrafikk potensielt 100 ganger høyere enn tradisjonelle søkemotorer, kan kostnaden av å mangle tilgjengelighet bare i noen få timer være betydelig.
Flere plattformer tilbyr nå spesialiserte verktøy for overvåking og optimalisering av AI-crawlertilgang. Cloudflare AI Crawl Control gir infrastruktur-nivå styring av AI-bot-trafikk, slik at du kan sette rate-limits og tilgangspolicyer. Conductor tilbyr omfattende overvåkingsdashbord som sporer hvordan ulike AI-crawlere interagerer med innholdet ditt. Elementive fokuserer på tekniske SEO-revisjoner med spesielt fokus på AI-crawlerkrav. AdAmigo og MRS Digital tilbyr spesialiserte rådgivnings- og overvåkingstjenester for AI-synlighet. For kontinuerlig, sanntidsovervåking spesielt designet for å spore AI-crawlertilgangsmønstre og varsle deg om problemer før de påvirker synligheten, skiller AmICited seg ut som en dedikert løsning. AmICited spesialiserer seg på å overvåke hvilke AI-systemer som får tilgang til innholdet ditt, hvor ofte de crawler, og om de støter på tekniske sperrer. Dette spesialiserte fokuset på AI-crawleratferd – heller enn tradisjonelle SEO-målinger – gjør det til et uunnværlig verktøy for organisasjoner som tar AI-synlighet på alvor.
Å gjennomføre en omfattende AI-crawlerrevisjon krever en systematisk tilnærming. Trinn 1: Etabler et utgangspunkt ved å sjekke din nåværende robots.txt-fil og identifisere hvilke AI-boter du for øyeblikket tillater eller blokkerer. Trinn 2: Revider din tekniske infrastruktur ved å teste nettstedets tilgjengelighet for crawlere uten JavaScript, sjekke serverresponstider og påse at viktig innhold serveres i statisk HTML. Trinn 3: Implementer og valider skjemaoppmerking på innholdet ditt, og sørg for at forfatterskap, publiseringsdatoer, innholdstype og annen metadata er riktig strukturert i JSON-LD-format. Trinn 4: Overvåk crawleratferd med verktøy som AmICited for å spore hvilke AI-boter som får tilgang til nettstedet ditt, hvor ofte, og om de støter på feil. Trinn 5: Analyser resultatene ved å gjennomgå crawl-logger, identifisere feil-mønstre og prioritere utbedringer etter innvirkning. Trinn 6: Gjennomfør utbedringer med høyest effekt først, som JavaScript-gjengivelsesproblemer eller manglende skjema, deretter sekundære optimaliseringer. Trinn 7: Etabler kontinuerlig overvåking for å fange opp nye problemer før de påvirker synligheten, og sett opp varsler for crawlfeil eller tilgangsblokker.
Du trenger ikke en total ombygging for å forbedre AI-crawlertilgang – flere tiltak med stor effekt kan gjennomføres raskt. Server viktig innhold i ren HTML i stedet for å stole på JavaScript-gjengivelse; hvis du må bruke JavaScript, sørg for at viktig tekst og metadata også er tilgjengelig i opprinnelig HTML. Legg til omfattende skjemaoppmerking med JSON-LD-format, inkludert artikkelskjema, forfatterinformasjon, publiseringsdatoer og innholdsrelasjoner – dette hjelper AI-crawlere med å forstå kontekst og tilskrive innholdet riktig. Sørg for tydelig forfatterskapsinformasjon gjennom skjemaoppmerking og bylines, ettersom AI-systemer i økende grad prioriterer å sitere autoritative kilder. Overvåk og optimaliser Core Web Vitals (Largest Contentful Paint, First Input Delay, Cumulative Layout Shift) siden trege sider kan bli forlatt av crawlere før de er ferdig prosessert. Gå gjennom og oppdater robots.txt for å forsikre deg om at du ikke ved et uhell blokkerer AI-boter du ønsker skal få tilgang til innholdet ditt. Fiks tekniske problemer som omdirigeringskjeder, brutte lenker og serverfeil som kan få crawlere til å forlate nettstedet ditt midt i en crawl.
Ikke alle AI-crawlere har samme formål, og å forstå forskjellene hjelper deg å ta informerte valg om tilgangskontroll. GPTBot (OpenAI) brukes hovedsakelig til innsamling av treningsdata og forbedring av modellens evner, og er relevant hvis du vil at innholdet ditt skal prege ChatGPTs svar. OAI-SearchBot (OpenAI) crawler spesifikt for siteringsformål i søk, altså er det boten som inkluderer innholdet ditt i ChatGPTs søkebaserte svar. ClaudeBot (Anthropic) har lignende funksjon for Claude, Anthropics AI-assistent. PerplexityBot (Perplexity) crawler for sitering i Perplexitys AI-drevne søkemotor, som har blitt en betydelig trafikkilde for mange utgivere. Hver bot har ulike crawl-mønstre, frekvens og formål – noen fokuserer på treningsdata, andre på sanntids sitering i søk. Hvilke boter du tillater eller blokkerer bør samsvare med innholdsstrategien din: hvis du ønsker sitering i AI-søkeresultater, tillat søkespesifikke boter; hvis du er bekymret for bruk i treningsdata, kan du blokkere datainnsamlingsboter og samtidig tillate søkeboter. Denne nyanserte tilnærmingen til botstyring er langt mer sofistikert enn den tradisjonelle “tillat alle” eller “blokkér alle”-mentaliteten.
En AI-crawlerrevisjon er en omfattende vurdering av nettstedets tilgjengelighet for AI-boter som ChatGPT, Claude og Perplexity. Den identifiserer tekniske hindringer, problemer med JavaScript-gjengivelse, manglende skjemaoppmerking og andre faktorer som hindrer AI-crawlere i å få tilgang til og forstå innholdet ditt. Revisjonen gir konkrete anbefalinger for å forbedre synligheten din i AI-drevne søke- og svarmotorer.
Vi anbefaler å gjennomføre en omfattende revisjon minst kvartalsvis, eller når du gjør vesentlige endringer i nettstedets tekniske infrastruktur, innholdsstruktur eller robots.txt-fil. Kontinuerlig sanntidsovervåking er imidlertid ideelt for å oppdage problemer umiddelbart når de oppstår. Mange virksomheter bruker automatiserte overvåkingsverktøy som varsler om crawl-feil i sanntid, supplert med kvartalsvise dybdegående revisjoner.
Å tillate AI-crawlere betyr at innholdet ditt kan nås, analyseres og potensielt siteres av AI-systemer, noe som kan øke synligheten i AI-genererte svar og anbefalinger. Å blokkere AI-crawlere hindrer dem i å få tilgang til innholdet ditt, noe som beskytter konfidensiell informasjon, men kan redusere synligheten i AI-søkeresultater. Det riktige valget avhenger av forretningsmål, innholdssensitivitet og konkurranseposisjonering.
Ja, absolutt. Din robots.txt-fil gir granulær kontroll via User-Agent-regler. Du kan blokkere GPTBot og samtidig tillate PerplexityBot, eller tillate søkefokuserte boter (som OAI-SearchBot) mens du blokkerer datainnsamlingsboter (som GPTBot). Denne nyanserte tilnærmingen lar deg optimalisere innholdsstrategien basert på hvilke AI-plattformer som er viktigst for din virksomhet.
Hvis AI-crawlere ikke får tilgang til innholdet ditt, betyr det at nettstedet ditt i praksis er usynlig for AI-drevne søkemotorer og svarplattformer. Innholdet ditt vil ikke bli sitert, anbefalt eller inkludert i AI-genererte svar, selv om det er svært relevant. Dette kan føre til tapt trafikk, redusert merkevaresynlighet og tapte muligheter for å etablere autoritet i AI-søkeresultater.
Du kan sjekke serverloggene dine for User-Agent-strenger fra kjente AI-crawlere (GPTBot, ClaudeBot, PerplexityBot, etc.), eller bruke spesialiserte overvåkingsverktøy som AmICited som sporer AI-crawleraktivitet i sanntid. Disse verktøyene viser hvilke boter som får tilgang til nettstedet ditt, hvor ofte de crawler, hvilke sider de besøker, og om de møter noen feil eller blokkeringer.
Dette avhenger av din spesifikke situasjon. Hvis innholdet ditt er konfidensielt, sensitivt, eller du er bekymret for bruk i treningsdata, kan blokkering være hensiktsmessig. Men hvis du ønsker synlighet i AI-søkeresultater og sitering fra AI-systemer, er det viktig å tillate crawlere. Mange virksomheter velger en mellomløsning: de tillater søkefokuserte boter som gir sitering, men blokkerer datainnsamlingsboter.
AI-crawlere gjengir ikke JavaScript, noe som betyr at alt innhold som lastes dynamisk via klientsideskript er usynlig for dem. Hvis nettstedet ditt er avhengig av JavaScript for viktig innhold, navigasjon eller strukturert data, vil AI-crawlere kun se rå HTML og gå glipp av viktig informasjon. Dette kan ha stor betydning for hvordan innholdet ditt blir forstått og representert i AI-svar. Å levere kritisk innhold i statisk HTML er avgjørende for AI-tilgjengelighet.
Få sanntidsinnsikt i hvilke AI-boter som får tilgang til innholdet ditt og hvordan de ser nettstedet ditt. Start din gratis revisjon i dag og sørg for at merkevaren din er synlig på alle AI-søkeplattformer.
Lær å identifisere og overvåke AI-crawlere som GPTBot, ClaudeBot og PerplexityBot i serverloggene dine. Komplett guide med user-agent-strenger, IP-verifisering ...

Lær hvordan du blokkerer eller tillater AI-crawlere som GPTBot og ClaudeBot ved hjelp av robots.txt, blokkering på servernivå og avanserte beskyttelsesmetoder. ...

Lær hvordan du tester om AI-crawlere som ChatGPT, Claude og Perplexity kan få tilgang til innholdet på nettstedet ditt. Oppdag testmetoder, verktøy og beste pra...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.