
Hvordan håndtere duplikatinnhold for AI-søkemotorer
Lær hvordan du håndterer og forhindrer duplikatinnhold når du bruker AI-verktøy. Oppdag kanoniske tagger, videresendinger, deteksjonsverktøy og beste praksis fo...
11 min lesing

Lær hvordan kanoniske URL-er forhindrer problemer med duplikatinnhold i AI-søkesystemer. Oppdag beste praksis for implementering av kanoniske for å forbedre AI-synlighet og sikre korrekt attribuering av innhold.
Store språkmodeller og AI-søkesystemer bruker sofistikerte klustringsalgoritmer for å identifisere og gruppere nesten-identiske URL-er, slik at flere versjoner av det samme innholdet behandles som én enhet for rangering og sitat. Når AI-systemer møter duplikatinnhold, må de velge hvilken versjon som skal prioriteres—et valg som direkte påvirker hvilken URL som får synlighet, autoritetssignaler og brukerattribuering. Problemet oppstår når AI velger feil versjon: hvis din kanoniske URL peker til den foretrukne siden, men AI-systemet klustrer og rangerer en duplikat av lavere kvalitet i stedet, mister innholdet ditt synlighet og siteringskreditt. Intensjonssignaler blir utvannet på tvers av duplikatversjoner, og fragmenterer autoriteten som burde vært samlet på én URL, slik at hver duplikat mottar svakere rangering enn om all autoritet hadde vært samlet på den kanoniske versjonen.
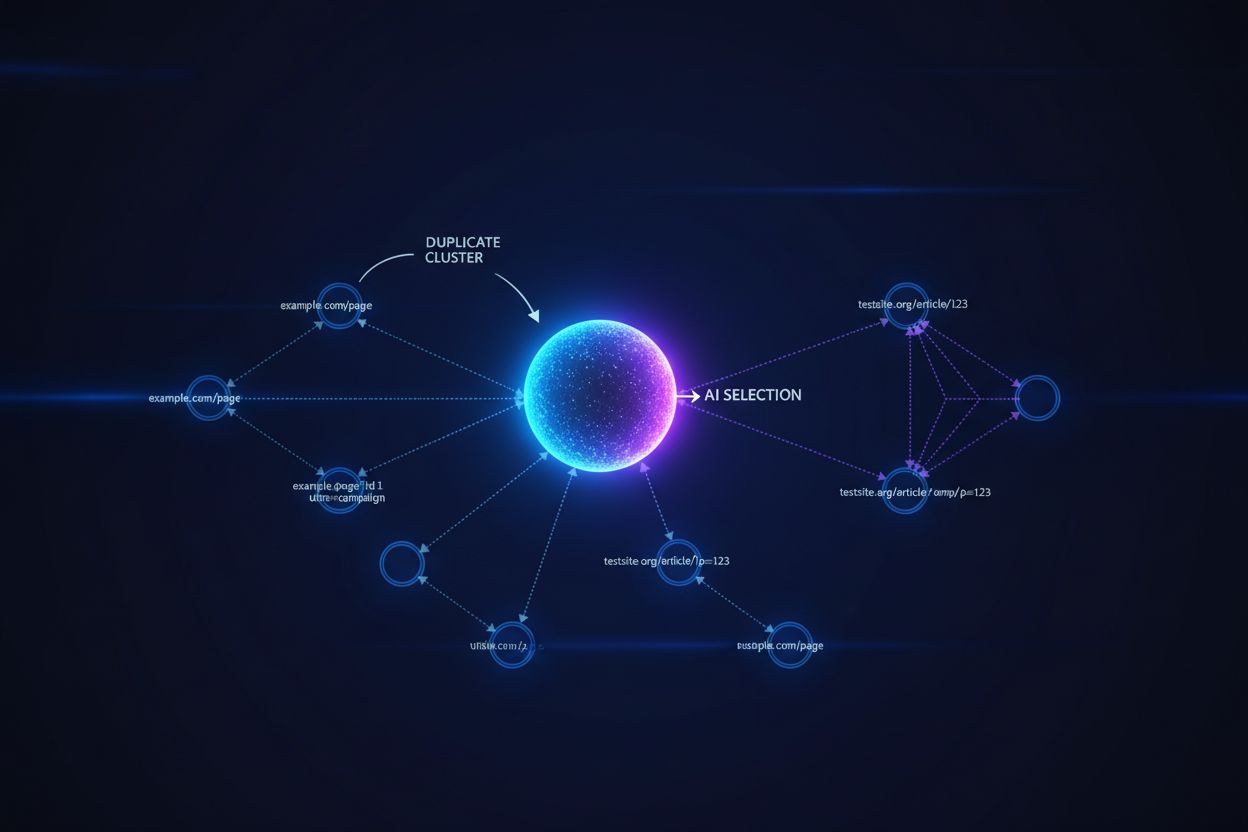
Kanoniske tagger fungerer som eksplisitte signaler til AI-systemer om hvilken versjon av duplikatinnhold som skal anses som autoritativ, og påvirker direkte om din foretrukne URL vises i AI-genererte svar og får korrekt attribuering. Uten kanoniske tagger må AI-systemer selv ta klustringsbeslutninger basert på innholdslikhet, lenkemønstre og ferskhetssignaler—ofte med det resultat at feil versjon velges som kanonisk kilde. Når duplikatinnhold eksisterer uten korrekt kanonisk implementering, kan AI-svar sitere en syndikert versjon, en hurtigbufferkopi eller en variant av lavere kvalitet i stedet for ditt originale innhold, og fragmentere synligheten din på tvers av flere URL-er. Kanoniske URL-er sørger for at når AI-systemer møter innholdet ditt på ulike domener, parametre eller versjoner, forstår de hvilken enkelt URL som skal motta kreditt og fremheves i svar.
| Scenario | Uten kanonisk | Med kanonisk |
|---|---|---|
| Innvirkning på AI | AI klustrer duplikater uavhengig; kan velge feil versjon for rangering | AI gjenkjenner én autoritativ kilde; konsoliderer alle signaler til kanonisk URL |
| Siteringskreditt | Attribuering spres over flere URL-er; svakere autoritet per URL | Alle siteringer og autoritet flyter til kanonisk URL; sterkere synlighet |
| Resultat | Innhold vises i AI-svar, men feil URL får kreditt; fragmentert synlighet | Foretrukket URL vises i AI-svar med konsoliderte autoritetssignaler |
Kanoniske tagger og omdirigeringer har ulike formål når det gjelder å håndtere duplikatinnhold for AI-systemer: kanoniske tagger forteller søkemotorer og AI-systemer hvilken versjon som er foretrukket, samtidig som begge URL-ene er tilgjengelige, mens omdirigeringer permanent sender brukere og crawlere fra én URL til en annen. Omdirigeringer (301 for permanente, 302 for midlertidige) er sterkere signaler fordi de konsoliderer all autoritet i en enkelt URL og eliminerer duplikatet fullstendig fra nettet, noe som gjør dem ideelle når du permanent fjerner en URL eller konsoliderer domener. Kanoniske tagger er å foretrekke når du må opprettholde flere URL-er av forretningsmessige grunner—som sporingsparametre for analyse, gamle URL-er for bokmerker, eller ulike versjoner for ulike målgrupper—men likevel signalisere til AI-systemer hvilken versjon som er autoritativ. Bruk omdirigeringer når du konsoliderer domener etter migrasjon, fjerner utdaterte versjoner, eller eliminerer parametervarianter som ikke har noen distinkt funksjon. Bruk kanoniske tagger når du må opprettholde flere URL-er, men ønsker å forhindre duplikatstraff og sikre at AI-systemer forstår din foretrukne versjon.
Viktige forskjeller mellom kanoniske og omdirigeringer:
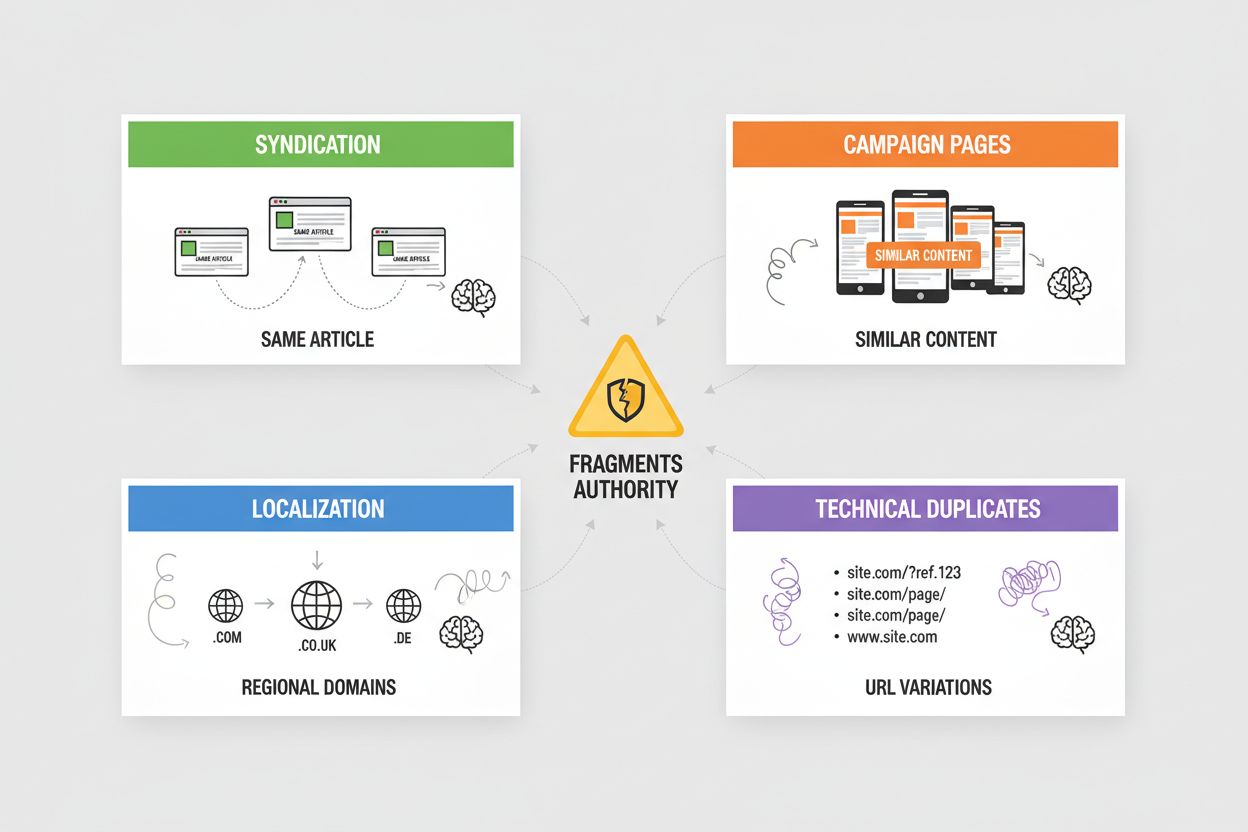
Syndikering skaper omfattende duplikatinnhold når artiklene dine republiseres på partnersider, nyhetsaggregatorer eller innholdsnettverk—AI-systemer må avgjøre om de skal kreditere originalkilden eller den syndikerte versjonen, ofte velger de den som ble funnet først. Kampanjesider genererer duplikater når du lager flere landingssider med identisk eller nesten identisk innhold for ulike markedsføringskanaler, UTM-parametre eller A/B-testing, og AI-systemer fragmenterer autoritet på tvers av varianter som burde vært konsolidert. Lokalisering og internasjonalisering gir duplikater når du har lignende innhold på regionale domener (eksempel.com, eksempel.co.uk, eksempel.de) eller språkversjoner, og krever hreflang-tagger og kanonisk implementering for å forhindre at AI-systemer behandler dem som duplikatinnhold i stedet for tilsiktede varianter. Tekniske duplikater oppstår fra sesjons-ID-er, sporingsparametre, printervennlige versjoner og URL-varianter (www vs. ikke-www, http vs. https, skråstreker) som skaper flere URL-er som peker til identisk innhold—AI-systemer ser disse som duplikater og må avgjøre hvilken versjon de skal prioritere. Hver av disse scenariene utvanner autoriteten som burde konsentreres på din foretrukne URL, reduserer synligheten din i AI-genererte svar og fører til at siteringskreditt blir spredt over flere versjoner.
Bruk alltid absolutte URL-er i dine kanoniske tagger i stedet for relative URL-er, slik at AI-systemer og søkemotorer entydig kan identifisere mål-URL-en uansett hvor taggen vises. Inkluder selvrefererende kanoniske på dine foretrukne sider—selv sider uten duplikater bør referere til seg selv som kanonisk, slik at AI-systemer ikke utleder kanoniske basert på lenkemønstre eller innholdslikhet. Plasser kanoniske tagger i <head>-seksjonen i HTML-dokumentet ditt, og for ikke-HTML-innhold (PDF-er, bilder), implementer kanoniske via HTTP-headere for å sikre at AI-crawlere gjenkjenner din preferanse uansett innholdstype.
<!-- Korrekt kanonisk implementering i HTML-head -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
Inkluder kanoniske URL-er i XML-sitemaps for å forsterke hvilke versjoner som er autoritative, og kombiner kanoniske med hreflang-tagger når du håndterer internasjonalt eller lokalisert innhold for å unngå at AI-systemer behandler regionale varianter som duplikater. Unngå vanlige feil: aldri lag kjeder av kanoniske (A→B→C), aldri pek kanoniske til sider med noindex, og aldri bruk kanoniske for å manipulere rangeringer ved å peke til ikke-relatert innhold. Overvåk implementeringen din med verktøy som Google Search Console, Bing Webmaster Tools og AmICited.com for å verifisere at AI-systemer gjenkjenner dine foretrukne URL-er og attribuerer innholdet korrekt.
<!-- Korrekt implementering med hreflang for internasjonalt innhold -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/article/canonical-urls-ai" />
<link rel="alternate" hreflang="de" href="https://example.de/artikel/canonical-urls-ai" />
Revider dine kanoniske URL-er ved å crawle hele nettstedet med verktøy som Screaming Frog, SEMrush eller Ahrefs for å identifisere sider med manglende kanoniske, ødelagte kanoniske kjeder eller kanoniske som peker til sider med noindex—disse problemene hindrer AI-systemer fra å konsolidere autoritet riktig. Bruk Google Search Console sin dekning-rapport for å finne sider med duplikatinnholdsproblemer og verifisere at Google gjenkjenner dine kanoniske preferanser, og kryssjekk med Bing Webmaster Tools for å sikre konsistens på tvers av AI-søkesystemer. Implementer IndexNow for å varsle søkemotorer og AI-crawlere umiddelbart når du legger til, oppdaterer eller fjerner kanoniske tagger, slik at dine preferanser oppdages raskere enn ved naturlige crawl-sykluser. Overvåk AI-sitater med verktøy som AmICited.com og manuelle søk i ChatGPT, Claude og Perplexity for å verifisere at dine foretrukne URL-er får attribuering i AI-genererte svar—hvis duplikater blir sitert i stedet, gjennomgå din kanoniske implementering og sørg for at taggene er korrekt formatert og plassert. Revider jevnlig for nytt duplikatinnhold som oppstår gjennom syndikeringspartnere, kampanjelanseringer eller tekniske endringer, og implementer kanoniske proaktivt for å opprettholde konsistent AI-synlighet.
En kanonisk URL er den foretrukne versjonen av en side du ønsker at søkemotorer og AI-systemer skal gjenkjenne som autoritativ. Det er viktig for AI-søk fordi LLM-er klustrer nesten-identiske URL-er og velger én versjon som representant. Uten korrekt implementering av kanonisk kan AI-systemer sitere feil versjon av innholdet ditt, noe som fragmenterer synligheten og attribueringen på tvers av flere URL-er.
AI-systemer bruker klustringsalgoritmer for å gruppere nesten-identiske URL-er til én enhet, og velger så én versjon som representant for hele klustret. Dette skiller seg fra tradisjonelle søkemotorer fordi AI-svar krever én kilde-URL for attribuering. Hvis din kanoniske ikke er korrekt implementert, kan AI velge en syndikert versjon, en hurtigbufferkopi eller en variant av lavere kvalitet i stedet for din foretrukne URL.
Bruk kanoniske tagger når du må opprettholde flere URL-er av forretningsmessige årsaker (sporingsparametre, gamle URL-er, ulike målgrupper) samtidig som du signaliserer preferanse til AI-systemer. Bruk omdirigeringer når du permanent fjerner en URL, konsoliderer domener eller eliminerer parametervarianter som ikke har noen hensikt. Omdirigeringer er sterkere signaler fordi de fullt ut konsoliderer autoritet, mens kanoniske distribuerer autoritet, men signaliserer preferanse.
De vanligste problemene er: syndikering (publiserte artikler på partnersider), kampanjesider (flere landingssider med identisk innhold), lokaliseringsproblematikk (lignende innhold på regionale domener) og tekniske duplikater (URL-parametre, sesjons-ID-er, skråstreker). Hver av disse fragmenterer autoriteten på tvers av flere URL-er, noe som reduserer synligheten i AI-genererte svar.
Bruk alltid absolutte URL-er (https://eksempel.no/side, ikke /side), plasser kanoniske tagger i HTML-headen, inkluder selvrefererende kanoniske på alle sider, og unngå kanoniske kjeder (A→B→C). For ikke-HTML-innhold som PDF-er, bruk HTTP-headere. Inkluder kanoniske i XML-sitemap og par dem med hreflang-tagger for internasjonalt innhold.
Bruk Google Search Console og Bing Webmaster Tools for å verifisere kanonisk gjenkjenning, overvåk AI-sitater med AmICited.com og manuelle søk i ChatGPT/Claude/Perplexity, og gjennomfør revisjon av nettstedet med verktøy som Screaming Frog eller SEMrush. Hvis duplikater blir sitert i stedet for din kanoniske, gjennomgå implementeringen på nytt og sørg for at taggene er korrekt formatert og plassert i HTML-headen.
IndexNow er en protokoll som varsler søkemotorer og AI-crawlere umiddelbart når du legger til, oppdaterer eller fjerner kanoniske tagger, i stedet for å vente på naturlige crawl-sykluser. Dette akselererer oppdagelsen av dine kanoniske preferanser og hjelper med å sikre at AI-systemer raskere gjenkjenner dine foretrukne URL-er, og reduserer tiden duplikater vises i AI-svar.
Ja, kanoniske tagger er sterke signaler, men ikke direktiver. AI-systemer kan overstyre din kanoniske preferanse hvis de vurderer at en annen versjon er mer autoritativ basert på innholdskvalitet, lenkemønster, ferskhet eller andre signaler. Derfor er korrekt implementering kombinert med sterke innholds- og autoritetssignaler viktig—det øker sannsynligheten for at AI-systemer respekterer din kanoniske preferanse.
Følg med på hvordan AI-systemer som ChatGPT, Claude og Perplexity siterer innholdet ditt. Sikre at dine kanoniske URL-er blir korrekt gjenkjent og at merkevaren din får riktig attribuering i AI-genererte svar.
Lær hvordan du håndterer og forhindrer duplikatinnhold når du bruker AI-verktøy. Oppdag kanoniske tagger, videresendinger, deteksjonsverktøy og beste praksis fo...
Diskusjon i fellesskapet om hvordan AI-systemer håndterer duplisert innhold annerledes enn tradisjonelle søkemotorer. SEO-fagfolk deler innsikt om innholdsunikh...
Lær hva AI-innholdskannibalisering er, hvordan det skiller seg fra duplisert innhold, hvorfor det skader rangeringer, og strategier for å beskytte innholdet dit...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.