Query Fanout
Lær hvordan Query Fanout fungerer i AI-søkesystemer. Oppdag hvordan AI utvider én enkelt forespørsel til flere underforespørsler for å forbedre svarenes nøyakti...
10 min lesing
Oppdag hvordan moderne AI-systemer som Google AI Mode og ChatGPT deler opp én forespørsel til flere søk. Lær om fanout-mekanismer, konsekvenser for AI-synlighet og optimalisering av innholdsstrategi.
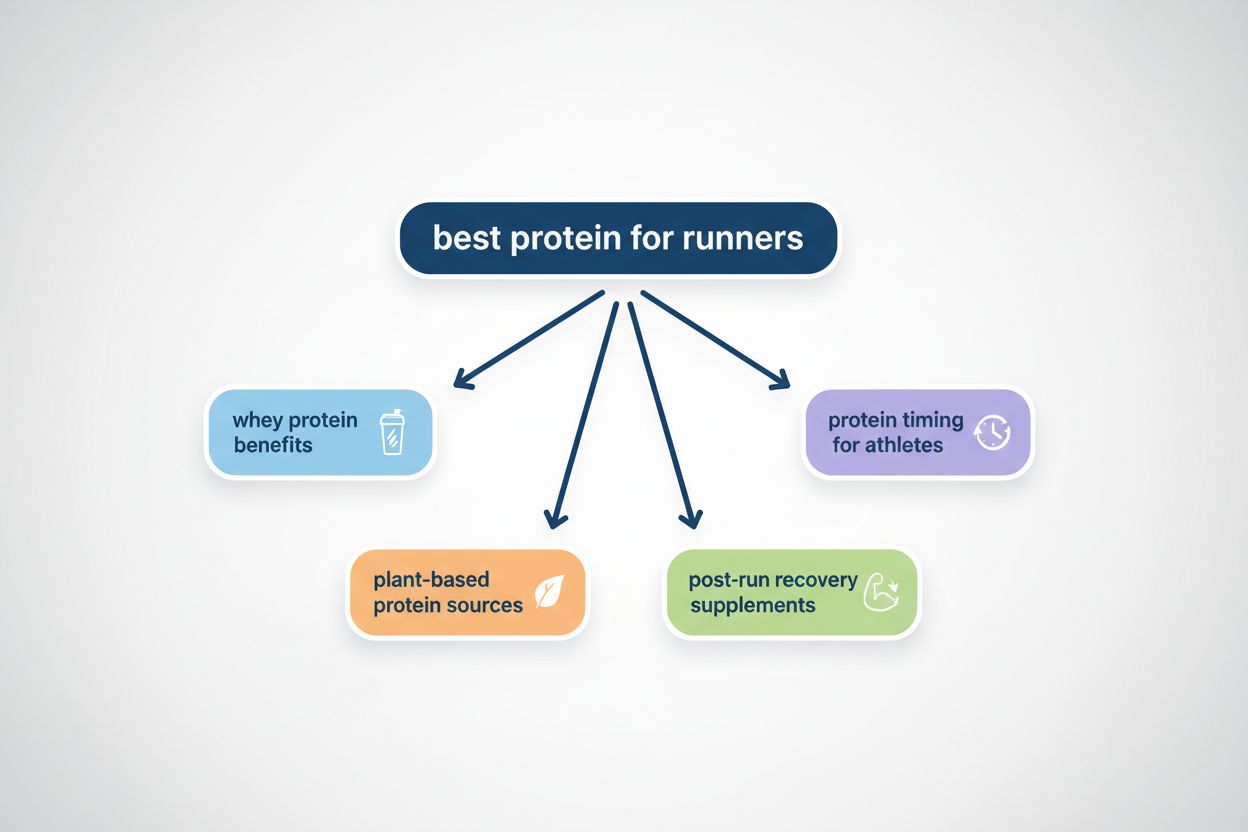
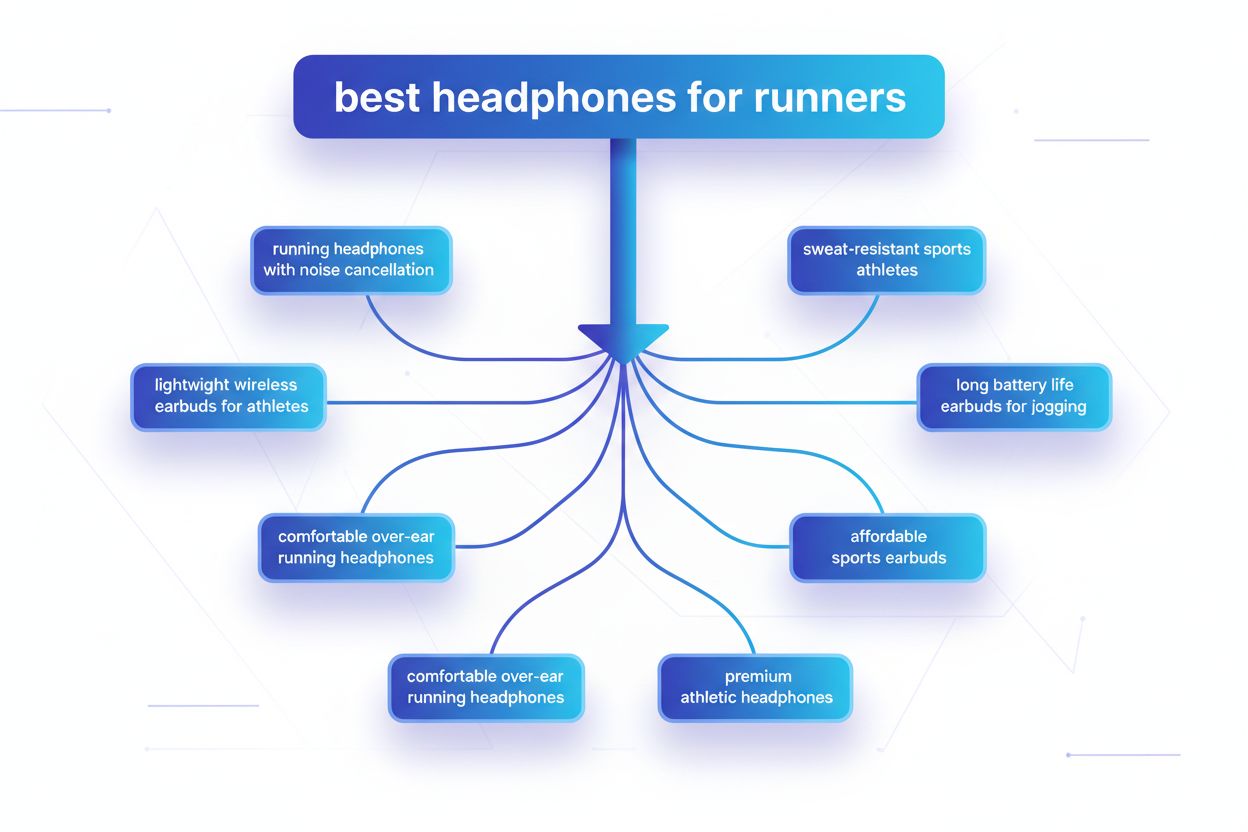
Query fanout er prosessen der store språkmodeller automatisk deler opp én brukerforespørsel i flere underforespørsler for å samle mer omfattende informasjon fra ulike kilder. I stedet for å utføre ett enkelt søk, deler moderne AI-systemer brukerens hensikt opp i 5–15 relaterte forespørsler som fanger opp ulike vinkler, tolkninger og aspekter av det opprinnelige ønsket. For eksempel, når en bruker søker etter “beste hodetelefoner for løpere” i Googles AI-modus, genererer systemet omtrent 8 forskjellige søk, inkludert varianter som “løpehodetelefoner med støydemping”, “lette trådløse ørepropper for idrettsutøvere”, “svetteresistente sportshodetelefoner” og “ørepropper med lang batteritid for jogging”. Dette representerer et grunnleggende avvik fra tradisjonelt søk, hvor én enkelt søkestreng matches mot et indeks. Nøkkeltrekk ved query fanout inkluderer:
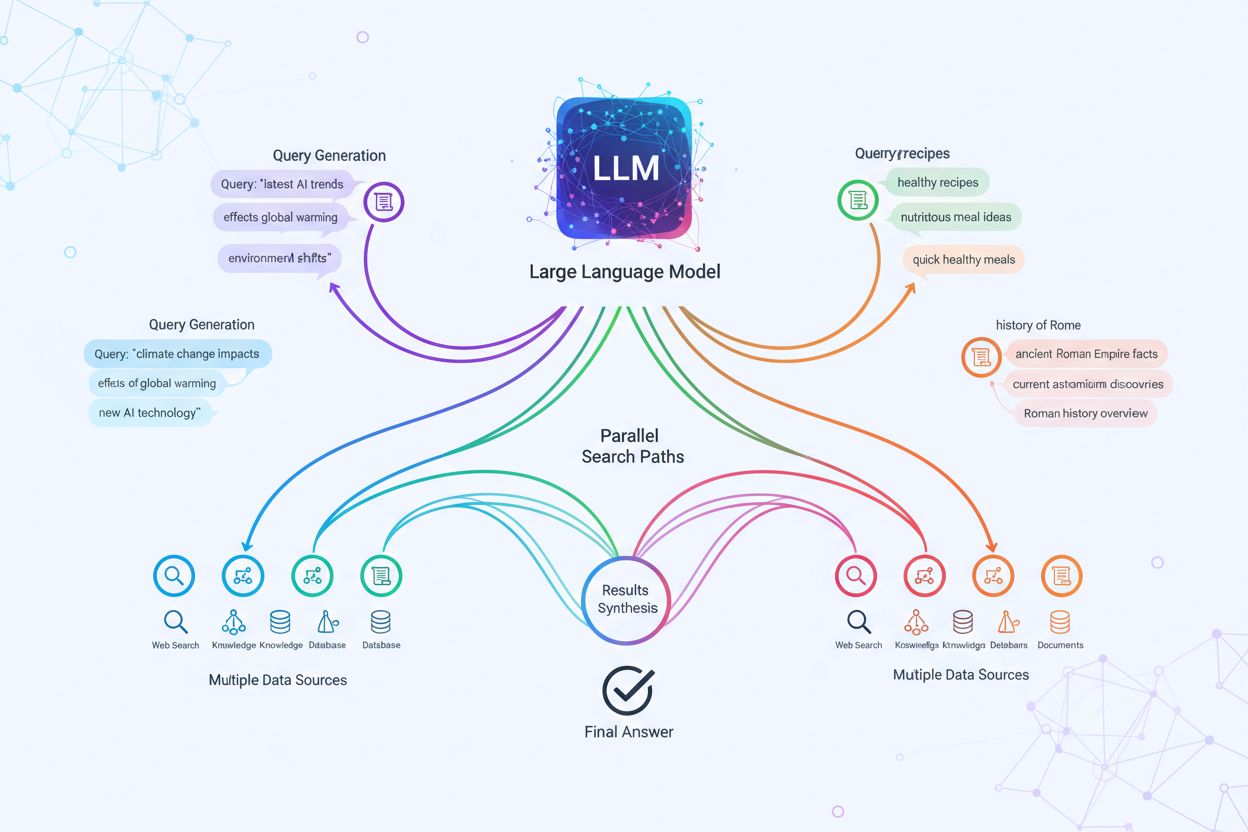
Den tekniske implementeringen av query fanout bygger på avanserte NLP-algoritmer som analyserer forespørsels-kompleksitet og genererer semantisk meningsfulle varianter. LLM-er produserer åtte hovedtyper av forespørselsvarianter: ekvivalente forespørsler (omformulering med identisk betydning), oppfølgingsforespørsler (utforsker relaterte temaer), generaliseringsforespørsler (utvider omfanget), spesifikasjonsforespørsler (avgrenser fokus), kanoniseringsforespørsler (standardiserer terminologi), oversettelsesforespørsler (konverterer mellom domener), implikasjonsforespørsler (utforsker logiske konsekvenser) og oppklaringsforespørsler (avklarer tvetydige termer). Systemet bruker nevrale språkmodeller for å vurdere forespørsels-kompleksitet—målt i for eksempel antall entiteter, tetthet av relasjoner og semantisk tvetydighet—for å avgjøre hvor mange underforespørsler som skal genereres. Når de er generert, utføres disse forespørslene parallelt på tvers av flere innhentingssystemer, inkludert nettcrawlere, kunnskapsgrafer (som Googles Knowledge Graph), strukturerte databaser og vektorlignende indekser. Ulike plattformer implementerer denne arkitekturen med ulik grad av transparens og sofistikasjon:
| Plattform | Mekanisme | Transparens | Antall forespørsler | Rangeringsmetode |
|---|---|---|---|---|
| Google AI Mode | Eksplisitt fanout med synlige søk | Høy | 8–12 forespørsler | Flerstegs rangering |
| Microsoft Copilot | Iterativ Bing Orchestrator | Middels | 5–8 forespørsler | Relevanspoeng |
| Perplexity | Hybridinnhenting med flerstegs rangering | Høy | 6–10 forespørsler | Siteringsbasert |
| ChatGPT | Implisitt forespørselgenerering | Lav | Ukjent | Intern vekting |
Komplekse forespørsler gjennomgår avansert oppdeling der systemet bryter dem opp i underliggende entiteter, attributter og relasjoner før varianter genereres. Når systemet behandler en forespørsel som “Bluetooth-hodetelefoner med komfortabel over-ear-design og lang batteritid egnet for løpere”, benytter det entitetsbasert forståelse for å identifisere nøkkelentiteter (Bluetooth-hodetelefoner, løpere) og trekker ut viktige attributter (komfortabel, over-ear, lang batteritid). Oppdelingsprosessen bruker kunnskapsgrafer for å forstå hvordan disse entitetene henger sammen og hvilke semantiske variasjoner som finnes—å erkjenne at “over-ear-hodetelefoner” og “circumaurale hodetelefoner” er ekvivalente, eller at “lang batteritid” kan bety 8+ timer, 24+ timer eller flere dager, avhengig av kontekst. Systemet identifiserer relaterte konsepter gjennom semantiske likhetsmål, og forstår at forespørsler om “svetteresistens” og “vannresistens” er beslektet men forskjellige, samt at “løpere” også kan være interessert i “syklister”, “treningsentusiaster” eller “utendørsidrettsutøvere”. Denne oppdelingen muliggjør generering av målrettede underforespørsler som fanger ulike sider ved brukerens hensikt, istedenfor bare å omformulere den opprinnelige forespørselen.
Query fanout styrker grunnleggende innhentingsdelen av Retrieval-Augmented Generation (RAG)-rammeverk ved å muliggjøre rikere og mer mangfoldig bevisinnhenting før genereringsfasen. I tradisjonelle RAG-pipelines blir én forespørsel embedded og matchet mot en vektordatabase, noe som potensielt kan medføre at relevant informasjon med annen terminologi eller konseptuell vinkling overses. Query fanout løser denne begrensningen ved å utføre flere innhentingsoperasjoner parallelt, hver optimalisert for én spesifikk forespørselsvariant, som samlet henter bevis fra forskjellige vinkler og kilder. Denne parallelle innhentingsstrategien reduserer risikoen for hallusinasjoner betydelig ved å forankre LLM-svar i flere uavhengige kilder—når systemet henter informasjon om “over-ear-hodetelefoner”, “circumaurale design” og “fullstørrelse hodetelefoner” separat, kan det kryssreferere og validere påstander på tvers av disse mangfoldige innhentingsresultatene. Arkitekturen omfatter semantisk chunking og passasjebasert innhenting, der dokumenter deles inn i meningsfulle semantiske enheter istedenfor faste lengder, slik at systemet kan hente de mest relevante avsnittene uavhengig av dokumentstruktur. Ved å kombinere bevis fra flere underforespørsler, produserer RAG-systemer svar som er mer helhetlige, bedre underbygget og mindre utsatt for de selvsikre, men uriktige outputene som preger enkelt-forespørselsinnhenting.
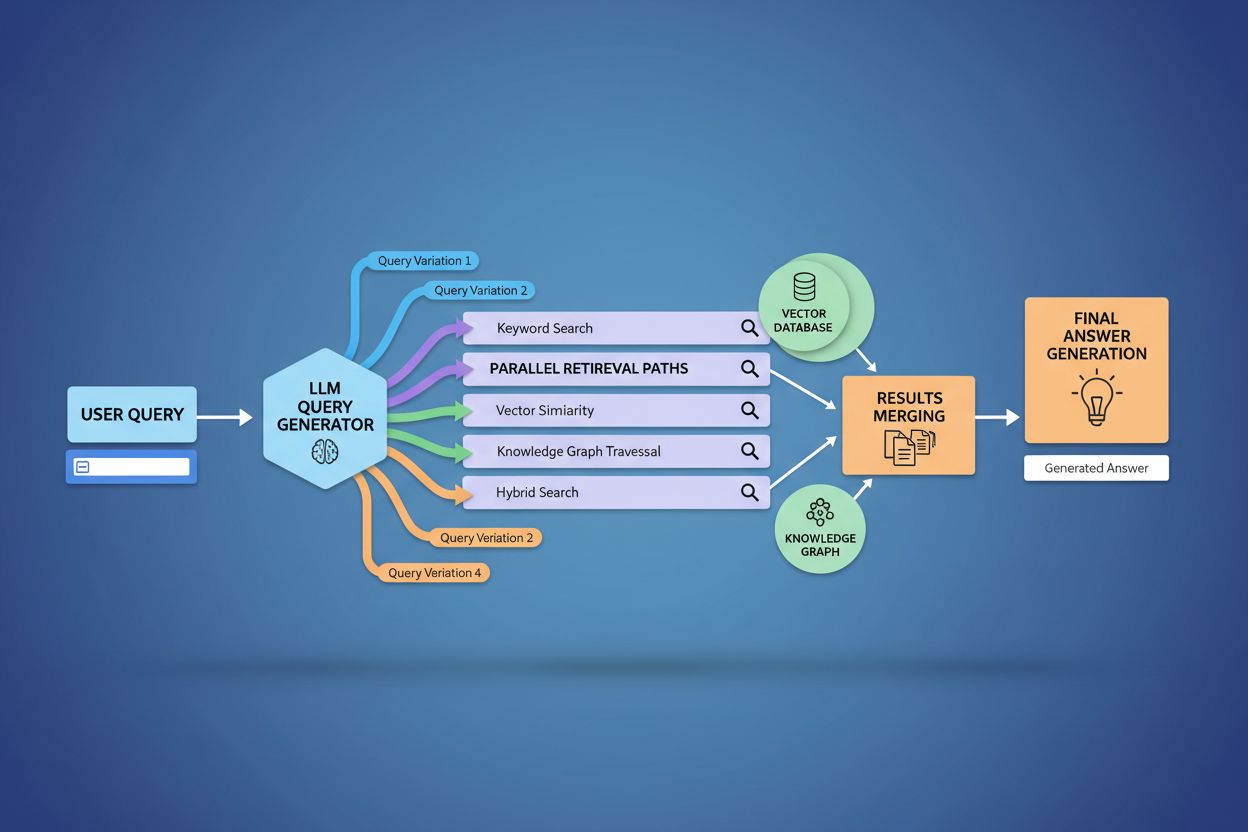
Brukerkontekst og personaliseringssignaler former dynamisk hvordan query fanout utvider individuelle forespørsler, og skaper personlige innhentingsstier som kan avvike betydelig mellom brukere. Systemet inkorporerer flere personaliseringsdimensjoner, inkludert brukerens attributter (geografisk plassering, demografisk profil, yrkesrolle), søkehistorikk (tidligere søk og klikk), tidsmessige signaler (tid på døgnet, sesong, aktuelle hendelser) og oppgavekontekst (om brukeren forsker, handler eller lærer). For eksempel utvides en forespørsel om “beste hodetelefoner for løpere” ulikt for en 22 år gammel ultramaratonløper i Kenya og en 45 år gammel mosjonist i Minnesota—førstnevntes utvidelse kan vektlegge slitestyrke og varmeresistens, mens den andres vektlegger komfort og tilgjengelighet. Men denne personaliseringen introduserer “to-punkt-transformasjon”-problemet, der systemet behandler nåværende forespørsler som varianter av historiske mønstre, noe som kan begrense utforsking og forsterke eksisterende preferanser. Personalisering kan utilsiktet skape filterbobler der forespørselsutvidelsen systematisk favoriserer kilder og perspektiver i tråd med brukerens historikk, og dermed begrenser eksponering for alternative synsvinkler eller ny informasjon. Å forstå disse personaliseringsmekanismene er avgjørende for innholdsskapere, ettersom samme innhold kan bli hentet eller ikke, avhengig av brukerens profil og historikk.
Store AI-plattformer implementerer query fanout med markant ulike arkitekturer, transparensnivåer og strategiske tilnærminger som reflekterer deres underliggende infrastruktur og designfilosofi. Googles AI-modus bruker eksplisitt, synlig query fanout der brukerne ser de 8–12 genererte underforespørslene presentert sammen med resultatene, og avfyrer hundrevis av individuelle søk mot Googles indeks for å samle omfattende bevis. Microsoft Copilot bruker en iterativ tilnærming drevet av Bing Orchestrator, som genererer 5–8 forespørsler sekvensielt og raffinerer settet basert på mellomresultater før siste innhentingsfase. Perplexity implementerer en hybrid innhentingsstrategi med flerstegs rangering, genererer 6–10 forespørsler og kjører disse mot både webkilder og sin egen indeks, deretter anvendes avanserte rangeringsalgoritmer for å vise de mest relevante avsnittene. ChatGPTs tilnærming er i stor grad uklar for brukeren, med forespørselsgenerering som skjer implisitt i modellens interne prosessering, slik at det er vanskelig å vite nøyaktig hvor mange forespørsler som genereres eller hvordan de utføres. Disse arkitektoniske forskjellene har stor betydning for transparens, reproduserbarhet og innholdsoptimalisering for hver plattform:
| Aspekt | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Forespørselssynlighet | Fullt synlig | Delvis synlig | Synlig i siteringer | Skjult |
| Utførelsesmodell | Parallell batch | Iterativ sekvensiell | Parallell med rangering | Intern/implisitt |
| Kildediversitet | Kun Google-indeks | Bing + egen | Web + egen indeks | Treningsdata + plugins |
| Siteringstransparens | Høy | Middels | Svært høy | Lav |
| Tilpasningsmuligheter | Begrenset | Middels | Høy | Middels |
Query fanout introduserer flere tekniske og semantiske utfordringer som kan gjøre at systemet avviker fra brukerens egentlige hensikt, og henter inn teknisk relaterte, men lite nyttige resultater. Semantisk drift oppstår gjennom generativ utvidelse når LLM-en skaper forespørselsvarianter som, selv om de er beslektet med den opprinnelige, gradvis endrer betydning—en forespørsel om “beste hodetelefoner for løpere” kan utvides til “treningshodetelefoner”, deretter “sportsutstyr” og “treningsutstyr”, og bevege seg vekk fra opprinnelig hensikt. Systemet må skille mellom latent hensikt (hva brukeren kanskje ønsker hvis de visste mer) og eksplisitt hensikt (det de faktisk spurte om), og aggressiv forespørselsutvidelse kan blande disse kategoriene, og hente inn informasjon brukeren aldri hadde tenkt på. Iterativ utvidelsesavvik oppstår når hver genererte forespørsel gir opphav til nye underforespørsler, og skaper et forgrenet tre av stadig mer perifere søk som til slutt henter inn informasjon langt fra opprinnelig forespørsel. Filterbobler og personaliseringsskjevhet gjør at to brukere med identiske spørsmål får systematisk ulike forespørselsutvidelser basert på profilen sin, og kan skape ekkokamre der hver brukers utvidelse forsterker eksisterende preferanser. Virkelige scenarier viser disse fallgruvene: en bruker som søker etter “rimelige hodetelefoner” kan få utvidet forespørselen til å inkludere luksusmerker basert på nettleserhistorikk, eller en forespørsel om “hodetelefoner for hørselshemmede” kan utvides til å inkludere generelle tilgjengelighetsprodukter og dermed utvanne spesifisiteten i det opprinnelige ønsket.
Fremveksten av query fanout flytter innholdsstrategi fundamentalt fra optimalisering for nøkkelordrangering til siteringsbasert synlighet, og krever at innholdsskapere revurderer hvordan de strukturerer og presenterer informasjon. Tradisjonell SEO fokuserte på rangering for bestemte søkeord; AI-drevet søk prioriterer å bli sitert som autoritativ kilde på tvers av flere forespørselsvarianter og kontekster. Innholdsskapere bør ta i bruk atomiske, entitetsrike innholdsstrategier der informasjon struktureres rundt bestemte entiteter (produkter, konsepter, personer) med rik semantisk markup slik at AI-systemer kan trekke ut og sitere relevante avsnitt. Temaklynger og tematisk autoritet blir stadig viktigere—i stedet for å lage isolerte artikler om enkeltord, lykkes innhold som gir bred dekning av temaområder, og dermed oftere hentes frem gjennom de mangfoldige forespørselsvarianter generert av fanout. Skjema-markup og strukturert data gjør at AI-systemer forstår innholdsstruktur og kan trekke ut relevant informasjon mer effektivt, noe som øker sjansen for å bli sitert. Suksessmålinger flyttes fra å spore nøkkelordrangering til å overvåke siteringsfrekvens gjennom verktøy som AmICited.com, som sporer hvor ofte merkevarer og innhold vises i AI-genererte svar. Praktiske anbefalinger inkluderer: å lage omfattende, veldokumentert innhold som dekker flere vinkler av et tema; implementere rik skjema-markup (Organization-, Product-, Article-skjema); bygge tematisk autoritet med sammenkoblet innhold; og jevnlig gjennomgå hvordan innholdet ditt vises i AI-svar på tvers av ulike plattformer og brukersegmenter.
Query fanout representerer det mest betydningsfulle arkitektoniske skiftet i søk siden mobil-først-indeksering, og omstrukturerer fundamentalt hvordan informasjon oppdages og presenteres for brukere. Utviklingen mot semantisk infrastruktur betyr at søkesystemer i økende grad vil operere på mening fremfor nøkkelord, med query fanout som standardmekanisme for informasjonsinnhenting i stedet for et valgfritt tillegg. Siteringsmålinger blir like viktige som tilbakekoblinger for å avgjøre innholdssynlighet og autoritet—innhold som blir sitert i 50 forskjellige AI-svar veier tyngre enn innhold som rangerer #1 for ett enkelt søkeord. Dette gir både utfordringer og muligheter: tradisjonelle SEO-verktøy for nøkkelordrangering blir mindre relevante, og krever nye målerammer med fokus på siteringsfrekvens, kildediversitet og synlighet på tvers av ulike forespørselsvarianter. Samtidig skapes det muligheter for merkevarer til å optimalisere spesifikt for AI-søk ved å bygge autoritativt, godt strukturert innhold som fungerer som pålitelig kilde gjennom flere tolkninger. Fremtiden vil trolig innebære økt transparens rundt fanout-mekanismer, med plattformer som konkurrerer om å vise tydelig hvordan de resonnementerer bak sine multi-forespørselsprosesser, og innholdsskapere som utvikler spesialiserte strategier for å maksimere synligheten på tvers av de mangfoldige innhentingsstiene som fanout skaper.
Query fanout er den automatiserte prosessen der AI-systemer deler opp en enkelt brukerforespørsel i flere underforespørsler og utfører dem parallelt, mens query expansion tradisjonelt handler om å legge til relaterte termer til en enkelt forespørsel. Query fanout er mer sofistikert, og genererer semantisk ulike varianter som fanger opp forskjellige vinkler og tolkninger av den opprinnelige hensikten.
Query fanout har stor innvirkning på synligheten fordi innholdet ditt må kunne oppdages på tvers av flere forespørselsvarianter, ikke bare den eksakte brukerforespørselen. Innhold som dekker forskjellige vinkler, bruker variert terminologi og er godt strukturert med skjema-markup, har større sannsynlighet for å bli hentet frem og sitert gjennom de ulike underforespørslene generert av fanout.
Alle større AI-søkeplattformer benytter query fanout-mekanismer: Google AI Mode bruker eksplisitt, synlig fanout (8-12 forespørsler); Microsoft Copilot benytter iterativ fanout via Bing Orchestrator; Perplexity kombinerer hybrid innhenting med flerstegs rangering; og ChatGPT bruker implisitt forespørselgenerering. Hver plattform implementerer det forskjellig, men alle deler opp komplekse forespørsler til flere søk.
Ja. Optimaliser ved å lage atomisk, entitetsrikt innhold strukturert rundt spesifikke konsepter; implementer omfattende skjema-markup; bygg tematisk autoritet gjennom sammenkoblet innhold; bruk tydelig, variert terminologi og dekk flere vinkler av et tema. Verktøy som AmICited.com hjelper deg å overvåke hvordan innholdet ditt vises på tvers av ulike forespørselsoppdelinger.
Query fanout øker latenstiden fordi flere forespørsler kjøres parallelt, men moderne systemer demper dette gjennom parallellprosessering. Mens en enkelt forespørsel kan ta 200ms, vil å kjøre 8 forespørsler parallelt vanligvis bare legge til 300-500ms total latenstid på grunn av samtidighet. Byttet er verdt det for bedre svar-kvalitet.
Query fanout styrker Retrieval-Augmented Generation (RAG) ved å muliggjøre rikere bevisinnhenting. I stedet for å hente dokumenter for én forespørsel, henter fanout bevis for flere forespørselsvarianter parallelt, og gir LLM-en mer mangfoldig, omfattende kontekst for å generere presise svar og redusere risiko for hallusinasjoner.
Personalisering former hvordan forespørsler deles opp basert på brukerens attributter (lokasjon, historikk, demografi), tidsmessige signaler og oppgavens kontekst. Samme forespørsel utvides forskjellig for ulike brukere, og skaper personlige innhentingsstier. Dette kan øke relevansen, men skaper også filterbobler der brukere systematisk får ulike resultater basert på profilene sine.
Query fanout representerer det mest betydningsfulle skiftet i søk siden mobil-først-indeksering. Tradisjonelle nøkkelordrangeringer blir mindre relevante ettersom samme forespørsel utvides forskjellig for ulike brukere. SEO-spesialister må flytte fokuset fra nøkkelordrangering til siteringsbasert synlighet, innholdsstruktur og entitetsoptimalisering for å lykkes i AI-drevne søk.
Forstå hvordan merkevaren din vises på AI-søkeplattformer når forespørsler utvides og deles opp. Følg med på siteringer og omtaler i AI-genererte svar.
Lær hvordan Query Fanout fungerer i AI-søkesystemer. Oppdag hvordan AI utvider én enkelt forespørsel til flere underforespørsler for å forbedre svarenes nøyakti...

Lær de essensielle første stegene for å optimalisere innholdet ditt for AI-søkemotorer som ChatGPT, Perplexity og Google AI Overviews. Oppdag hvordan du struktu...
Lær hva føderert AI-søk er, hvordan det fungerer, dets fordeler for virksomheter, og hvordan det skiller seg fra tradisjonelle sentraliserte søkesystemer. Oppda...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.