
Hvordan forbedre lesbarheten for AI-systemer og AI-søkemotorer
Lær hvordan du optimaliserer innholdslesbarhet for AI-systemer, ChatGPT, Perplexity og AI-søkemotorer. Oppdag beste praksis for struktur, formatering og klarhet...
8 min lesing

Lær hvordan du tester innholdsformater for AI-siteringer ved hjelp av A/B-testmetodikk. Finn ut hvilke formater som gir høyest AI-synlighet og siteringsrate på ChatGPT, Google AI Overviews og Perplexity.
Kunstig intelligens prosesserer innhold grunnleggende annerledes enn menneskelige lesere, og er avhengig av strukturerte signaler for å forstå mening og trekke ut informasjon. Mens mennesker kan navigere gjennom kreativ formatering eller tett tekst, krever AI-modeller klare organisatoriske hierarkier og semantiske markører for å effektivt kunne tolke og forstå innholdsverdi. Forskning viser at strukturert innhold med riktige overskriftshierarkier oppnår siteringsrater som er 156 % høyere enn ustrukturerte alternativer, noe som avdekker et kritisk gap mellom menneskevennlig og AI-vennlig innhold. Denne forskjellen eksisterer fordi AI-systemer trenes på enorme datasett der godt organisert innhold vanligvis korrelerer med autoritative, pålitelige kilder. Å forstå og teste ulike innholdsformater har blitt avgjørende for merkevarer som ønsker synlighet i AI-drevne søkeresultater og svarmotorer.
Ulike AI-plattformer viser distinkte preferanser for innholdskilder og formater, noe som skaper et komplekst landskap for optimalisering. Forskning som analyserer 680 millioner siteringer på tvers av store plattformer, avslører slående forskjeller i hvordan ChatGPT, Google AI Overviews og Perplexity henter informasjonen sin. Disse plattformene siterer ikke bare de samme kildene – de prioriterer ulike typer innhold basert på sine underliggende algoritmer og treningsdata. Å forstå disse plattformspesifikke mønstrene er avgjørende for å utvikle målrettede innholdsstrategier som maksimerer synlighet på flere AI-systemer.
| Plattform | Mest siterte kilde | Siteringsprosent | Foretrukket format |
|---|---|---|---|
| ChatGPT | Wikipedia | 7,8 % av totale siteringer | Autoritative kunnskapsbaser, leksikalsk innhold |
| Google AI Overviews | 2,2 % av totale siteringer | Diskusjonsfora, brukergenerert innhold | |
| Perplexity | 6,6 % av totale siteringer | Informasjon fra bruker til bruker, fellesskapsinnsikt |
ChatGPTs overveldende preferanse for Wikipedia (som utgjør 47,9 % av deres topp 10 kilder) demonstrerer en slagside mot autoritativt, faktabasert innhold med etablert troverdighet. I motsetning viser både Google AI Overviews og Perplexity mer balanserte fordelinger, der Reddit dominerer siteringsmønstrene. Dette avslører at Perplexity prioriterer fellesskapsdrevet informasjon med 46,7 % av toppkildene, mens Google opprettholder en mer variert tilnærming på tvers av flere plattformtyper. Dataene viser tydelig at én strategi ikke passer for alle – merkevarer må tilpasse tilnærmingen etter hvilke AI-plattformer som er viktigst for deres publikum.
Schema markup er kanskje den viktigste faktoren for sannsynligheten for AI-sitering, der korrekt implementert JSON-LD-markup gir siteringsrater som er 340 % høyere enn identisk innhold uten strukturert data. Denne dramatiske forskjellen skyldes hvordan AI-motorer tolker semantisk mening – strukturert data gir eksplisitt kontekst som fjerner tvetydighet fra tolkningen av innholdet. Når en AI-motor møter schema markup, forstår den straks entitetsrelasjoner, innholdstyper og hierarkisk betydning uten kun å være avhengig av naturlig språkprosessering.
De mest effektive schema-implementeringene inkluderer Article-schema for blogginnlegg, FAQ-schema for spørsmål-og-svar-seksjoner, HowTo-schema for instruksjonsinnhold og Organization-schema for merkevaregjenkjenning. JSON-LD-formatet utkonkurrerer spesielt andre strukturerte dataformater fordi AI-motorer kan tolke det uavhengig av HTML-innholdet, noe som gir renere datauttrekk og reduserer prosesseringskompleksiteten. Semantiske HTML-tagger som <header>, <nav>, <main>, <section>, og <article> gir ytterligere klarhet som hjelper AI-systemer å forstå innholdsstruktur og hierarki mer effektivt enn enkel markup.
A/B-testing gir den mest pålitelige metoden for å avgjøre hvilke innholdsformater som gir høyest AI-siteringsrate i din nisje. I stedet for å stole på generelle beste praksiser, lar kontrollerte eksperimenter deg måle den faktiske effekten av formatendringer på publikummet ditt og AI-synlighet. Prosessen krever nøye planlegging for å isolere variabler og sikre statistisk gyldighet, men innsikten du får rettferdiggjør investeringen.
Følg denne systematiske A/B-test-rammen:
Statistisk signifikans krever nøye oppmerksomhet til utvalgsstørrelse og testvarighet. I AI-applikasjoner med sparsom data eller lang hale-fordelinger kan det være utfordrende å samle nok observasjoner raskt. De fleste eksperter anbefaler å kjøre tester i minst 2–4 uker for å ta høyde for tidsvariasjoner og sikre pålitelige resultater.
Forskning på tusenvis av AI-siteringer viser tydelige ytelseshierarkier blant ulike innholdsformater. Listebasert innhold får 68 % flere AI-siteringer enn avsnittstunge alternativer, hovedsakelig fordi lister gir diskrete, lett-parsede informasjonsenheter som AI-motorer enkelt kan trekke ut og sammenfatte. Når de genererer svar, kan AI-plattformer referere til spesifikke listepunkter uten å måtte restrukturere eller omskrive komplekse setninger, noe som gjør listebasert innhold svært verdifullt for sitering.
Tabeller viser eksepsjonell ytelse med opptil 96 % nøyaktighet i AI-parsing, og overgår klart prosa-beskrivelser av identisk informasjon. Tabulært innhold lar AI-systemer raskt hente ut spesifikke datapunkter uten kompleks tekstparsing, noe som gjør tabeller spesielt verdifulle for faktabasert, sammenlignende eller statistisk innhold. Spørsmål-og-svar-formater gir 45 % høyere AI-synlighet sammenlignet med tradisjonelle avsnittsformater for identiske temaer, fordi Q&A-innhold speiler hvordan brukere samhandler med AI-plattformer og hvordan AI-systemer genererer svar.
Sammenligningsformater (X vs Y) fungerer også svært godt fordi de gir binære, lett oppsummerbare strukturer som samsvarer med hvordan AI-systemer utvider forespørsler til undertemaer. Casestudier kombinerer fortelling med data, noe som gjør dem overbevisende for lesere og tolkningsvennlige for AI gjennom problem-løsning-resultat-strukturen sin. Egen forskning og ekspertinnsikt får fortrinnsbehandling fordi de gir unik data som ikke finnes andre steder, og tilfører troverdighetssignaler som AI-systemer gjenkjenner og belønner. Hovedinnsikten er at inget enkelt format fungerer universelt – den beste tilnærmingen kombinerer flere formater strategisk ut fra innholdstype og målrettede AI-plattformer.
Implementering av schema markup krever at du forstår de ulike typene som finnes, og velger de mest relevante for innholdet ditt. For blogginnlegg og artikler gir Article-schema omfattende metadata som forfatter, publiseringsdato og innholdsstruktur. FAQ-schema fungerer eksepsjonelt bra for spørsmål-og-svar-seksjoner, og merker eksplisitt spørsmål og svar slik at AI-systemer kan hente dem ut pålitelig. HowTo-schema er nyttig for instruksjonsinnhold ved å definere sekvensielle trinn, mens Product-schema hjelper nettbutikker å kommunisere spesifikasjoner og priser.
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "Hva er det beste innholdsformatet for AI-siteringer?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Det beste innholdsformatet avhenger av plattformen og publikummet ditt, men strukturerte formater som lister, tabeller og spørsmål-og-svar-seksjoner oppnår jevnt over høyere AI-siteringsrater. Lister får 68 % flere siteringer enn avsnitt, mens tabeller oppnår 96 % nøyaktighet i parsing."
}
}
]
}
Gjennomføringen krever nøyaktighet i syntaks – ugyldig schema markup kan faktisk skade AI-siteringsmulighetene dine i stedet for å forbedre dem. Bruk Googles Rich Results Test eller Schema.orgs valideringsverktøy for å verifisere markeringen før publisering. Oppretthold konsistente formateringshierarkier med H2 til hovedseksjoner, H3 til underpunkter, og korte avsnitt (maks 50–75 ord) med fokus på ett konsept av gangen. Legg til TL;DR-oppsummeringer i starten eller slutten av seksjoner for å gi AI klare utdrag som kan stå alene som brukbare svar.
Måling av AI-motors ytelse krever andre måleverdier enn tradisjonell SEO, med fokus på sporing av siteringer, innslagsrater i svar og omtale i kunnskapsgraf fremfor rangering. Overvåkning av siteringer på tvers av store plattformer gir det mest direkte innblikket i om testingen av innholdsformater gir resultater, og avslører hvilke innholdselementer AI-systemene faktisk refererer til. Verktøy som AmICited sporer spesifikt hvordan AI-plattformer siterer merkevaren din på ChatGPT, Google AI Overviews, Perplexity og andre svaremotorer, og gir innsikt i siteringsmønstre og trender.
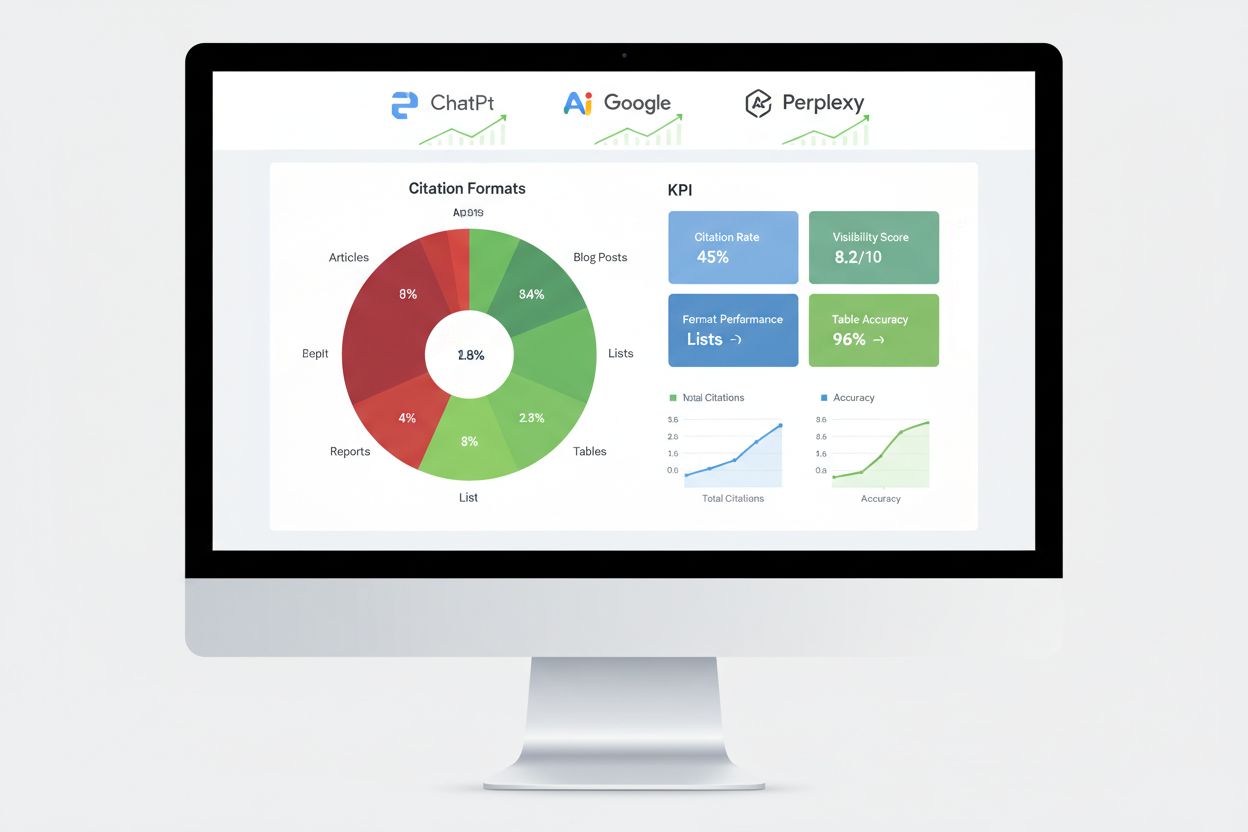
Viktige tilnærminger til måling inkluderer å spore andelen av featured snippets, som viser innhold AI-systemene finner særlig verdifulle for direkte svar. Fremkomst i kunnskapspanel signaliserer at AI-systemene gjenkjenner merkevaren din som en autoritativ entitet verdt å vise dedikert informasjon om. Resultater i talesøk viser om innholdet ditt dukker opp i konversasjons-AI-svar, mens responsrate fra generative motorer måler hvor ofte AI-systemene refererer til innholdet ditt når de besvarer brukerforespørsler. A/B-testing av ulike formattilnærminger gir de mest pålitelige ytelsesdataene ved å isolere enkeltvariabler og identifisere spesifikke påvirkningsfaktorer. Sett grunnleggende måleverdier før du gjør endringer, og overvåk ytelsen ukentlig for å avdekke trender og avvik som kan indikere vellykkede eller mislykkede formatendringer.
Mange organisasjoner som tester formater, faller i forutsigbare feller som kompromitterer resultatene og gir feil konklusjoner. For små utvalg er den vanligste feilen – testing med for få siteringer eller interaksjoner gir statistisk ubetydelige resultater som kan fremstå som meningsfulle, men som egentlig bare gjenspeiler tilfeldige variasjoner. Sørg for å samle minst 100 siteringer per variant før du trekker konklusjoner, og bruk statistiske kalkulatorer for å finne nøyaktig nødvendig utvalgsstørrelse for ønsket konfidensnivå og effektstørrelse.
Forstyrrende variabler gir skjevheter når flere faktorer endres samtidig, slik at det blir umulig å fastslå hvilke endringer som faktisk har effekt. Hold alle elementer identiske bortsett fra formatet som testes – bruk samme nøkkelord, lengde, struktur og publiseringstidspunkt. Tidsmessig skjevhet oppstår når du tester i unormale perioder (ferier, store nyhetshendelser, endringer i plattformalgoritmer) som forvrenger resultatene. Kjør tester i normale perioder og ta høyde for sesongvariasjon ved å teste i minst 2–4 uker. Seleksjonsskjevhet oppstår når testgruppene skiller seg ut på måter som påvirker resultatene – sørg for tilfeldig tildeling av innhold til variantene. Feiltolking av korrelasjon som årsakssammenheng gir gale slutninger når eksterne faktorer tilfeldig sammenfaller med testperioden. Vurder alltid alternative forklaringer for observerte endringer, og bekreft resultatene gjennom flere testrunder før du gjennomfører permanente endringer.
Et teknologiselskap som testet innholdsformater for AI-synlighet, oppdaget at det å konvertere produkt-sammenligningsartikler fra avsnittsformat til strukturerte sammenligningstabeller økte AI-siteringene med 52 % i løpet av 60 dager. Tabellene ga klar, oversiktlig informasjon som AI-systemene kunne trekke ut direkte, mens den opprinnelige prosateksten krevde mer kompleks parsing. De beholdt identisk innholdslengde og nøkkelordoptimalisering, slik at formatendringen var eneste variabel.
Et finansselskap implementerte FAQ-schema på eksisterende innhold uten å skrive om noe, men kun ved å legge til strukturert markup på eksisterende spørsmål-og-svar-seksjoner. Dette ga 34 % økning i fremkomst som featured snippet og 28 % økning i AI-siteringer på 45 dager. Schema-markupen endret ikke selve innholdet, men gjorde det mye lettere for AI-systemene å identifisere og hente ut relevante svar. Et SaaS-selskap gjennomførte multivariat testing på tre formater samtidig – lister, tabeller og tradisjonelle avsnitt – for identisk innhold om sine produktfunksjoner. Resultatene viste at lister overgikk avsnitt med 68 %, mens tabeller ga høyest nøyaktighet i AI-parsing, men lavere total siteringsvolum. Dette viste at formateffektivitet varierer med innholdstype og AI-plattform, og bekrefter at testing er avgjørende fremfor å stole på generelle beste praksiser. Disse virkelige eksemplene viser at testing av formater gir målbare, betydelige forbedringer i AI-synlighet når det gjøres riktig.
Landskapet for testing av innholdsformater utvikler seg stadig etter hvert som AI-systemene blir mer sofistikerte og nye optimaliseringsteknikker dukker opp. Multi-armed bandit-algoritmer representerer et betydelig fremskritt over tradisjonell A/B-testing, ved dynamisk å justere trafikkfordelingen til ulike varianter basert på løpende resultater i stedet for å vente til forhåndsdefinerte testperioder er over. Denne tilnærmingen forkorter tiden det tar å identifisere de beste variantene og maksimerer ytelsen i selve testperioden.
Adaptiv eksperimentering drevet av forsterkende læring lar AI-modeller kontinuerlig lære og tilpasse seg på grunnlag av løpende eksperimenter, og forbedre ytelsen i sanntid i stedet for gjennom diskrete testsykluser. AI-drevet automatisering av A/B-testing bruker AI selv til å automatisere eksperimentdesign, resultat-analyse og optimaliseringsanbefalinger, slik at organisasjoner kan teste flere varianter samtidig uten tilsvarende økning i kompleksitet. Disse nye tilnærmingene lover raskere iterasjonssykluser og mer sofistikerte optimaliseringsstrategier. Organisasjoner som mestrer testing av innholdsformater i dag, vil ha konkurransefortrinn når disse avanserte teknikkene blir standard, og vil kunne dra nytte av nye AI-plattformer og endrede siteringsalgoritmer før konkurrentene rekker å tilpasse sine strategier.
Det beste innholdsformatet avhenger av plattformen og publikummet ditt, men strukturerte formater som lister, tabeller og spørsmål-og-svar-seksjoner oppnår jevnt over høyere AI-siteringsrater. Lister får 68 % flere siteringer enn avsnitt, mens tabeller oppnår 96 % nøyaktighet i parsing. Nøkkelen er å teste ulike formater med ditt spesifikke innhold for å finne ut hva som fungerer best.
De fleste eksperter anbefaler å kjøre tester i minst 2–4 uker for å ta høyde for tidsvariasjoner og sikre pålitelige resultater. Denne varigheten gjør at du kan samle nok datapunkter (typisk 100+ siteringer per variant) og ta høyde for sesongvariasjoner eller endringer i plattformalgoritmer som kan påvirke resultatene.
Ja, du kan gjennomføre multivariat testing på tvers av flere formater samtidig, men dette krever nøye planlegging for å unngå kompleksitet i tolkning av resultatene. Start med enkle A/B-tester hvor to formater sammenlignes, og gå deretter videre til multivariat testing når du har forstått det grunnleggende og har tilstrekkelige statistiske ressurser.
Du trenger vanligvis minst 100 siteringer eller interaksjoner per variant for å oppnå statistisk signifikans. Bruk statistiske kalkulatorer for å finne nøyaktig utvalgsstørrelse tilpasset ditt ønskede konfidensnivå og effektstørrelse. Større utvalg gir mer pålitelige resultater, men krever lengre testperiode.
Start med å identifisere den mest relevante schema-typen for innholdet ditt (Article, FAQ, HowTo, osv.), og bruk deretter JSON-LD-format for implementeringen. Valider markeringen din med Googles Rich Results Test eller Schema.orgs valideringsverktøy før publisering. Ugyldig schema markup kan faktisk skade dine AI-siteringsmuligheter, så nøyaktighet er avgjørende.
Prioriter ut fra publikummet ditt og forretningsmål. ChatGPT foretrekker autoritative kilder som Wikipedia, Google AI Overviews foretrekker innhold fra fellesskapet som Reddit, og Perplexity vektlegger informasjon fra bruker til bruker. Analyser hvilke plattformer som gir mest relevant trafikk til nettstedet ditt, og optimaliser for disse først.
Implementer kontinuerlig testing som del av innholdsstrategien din. Start med kvartalsvise testsykluser for formater, og øk frekvensen etter hvert som du får mer erfaring og etablerer grunnleggende måleverdier. Regelmessig testing gjør at du holder deg foran endringer i AI-plattformenes algoritmer og oppdager nye formatpreferanser.
Følg med på forbedring i siteringsrater, andel av featured snippets, fremkomst i kunnskapspanel og responsrater fra generative motorer. Etabler grunnleggende måleverdier før testing, og overvåk deretter resultatene ukentlig for å identifisere trender. En vellykket test gir vanligvis 20 %+ forbedring i hovedmålet ditt innen 4–8 uker.
Følg med på hvordan AI-plattformer siterer innholdet ditt på tvers av ulike formater. Oppdag hvilke innholdsstrukturer som gir mest AI-synlighet og optimaliser strategien din med reelle data.
Lær hvordan du optimaliserer innholdslesbarhet for AI-systemer, ChatGPT, Perplexity og AI-søkemotorer. Oppdag beste praksis for struktur, formatering og klarhet...
Lær hvordan du kan omstrukturere innholdet ditt for AI-systemer med praktiske før og etter eksempler. Oppdag teknikker for å forbedre AI-siteringer og synlighet...
Oppdag hvilke innholdsformater som oftest siteres av AI-modeller. Analyser data fra over 768 000 AI-sitater for å optimalisere din innholdsstrategi for ChatGPT,...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.