Når SEO-rangeringer ikke gir AI-synlighet: Avstanden mellom kanalene
Oppdag hvorfor høye Google-rangeringer ikke garanterer AI-synlighet. Lær forskjellen mellom SEO og AI-sitater, og hvordan du optimaliserer for begge søkekanalen...
6 min lesing

Graden av åpenhet AI-plattformer har om hvordan de velger og rangerer kilder når de genererer svar. AI-rangeringstransparens refererer til synligheten av algoritmer og kriterier som avgjør hvilke kilder som vises i AI-genererte svar, og skiller seg fra tradisjonell søkemotorrangering. Denne transparensen er avgjørende for innholdsskapere, utgivere og brukere som trenger å forstå hvordan informasjon velges og prioriteres. Uten transparens kan ikke brukere verifisere kilders troverdighet eller forstå potensielle skjevheter i AI-generert innhold.
Graden av åpenhet AI-plattformer har om hvordan de velger og rangerer kilder når de genererer svar. AI-rangeringstransparens refererer til synligheten av algoritmer og kriterier som avgjør hvilke kilder som vises i AI-genererte svar, og skiller seg fra tradisjonell søkemotorrangering. Denne transparensen er avgjørende for innholdsskapere, utgivere og brukere som trenger å forstå hvordan informasjon velges og prioriteres. Uten transparens kan ikke brukere verifisere kilders troverdighet eller forstå potensielle skjevheter i AI-generert innhold.
AI-rangeringstransparens refererer til åpenhet om hvordan kunstig intelligens velger, prioriterer og presenterer kilder når den genererer svar på brukerforespørsler. I motsetning til tradisjonelle søkemotorer som viser rangerte lenkelister, integrerer moderne AI-plattformer som Perplexity, ChatGPT og Googles AI Overviews kildeutvalg i selve svargenereringen, noe som gjør rangeringskriteriene stort sett usynlige for brukerne. Denne uklarheten skaper et kritisk gap mellom hva brukerne ser (et syntetisert svar) og hvordan svaret er konstruert (hvilke kilder ble valgt, vektet og sitert). For innholdsskapere og utgivere betyr denne mangelen på transparens at deres synlighet avhenger av algoritmer de ikke kan forstå eller påvirke gjennom tradisjonelle optimaliseringsmetoder. Skillet fra tradisjonell søkemotortransparens er betydelig: Mens Google publiserer generelle rangeringsfaktorer og kvalitetsretningslinjer, behandler AI-plattformer ofte sine kildeutvalgsmekanismer som forretningshemmeligheter. Viktige interessenter som påvirkes inkluderer innholdsskapere som søker synlighet, utgivere opptatt av trafikkattribusjon, merkevareansvarlige som overvåker omdømme, forskere som vil verifisere informasjonskilder, og brukere som trenger å forstå troverdigheten til AI-genererte svar. Å forstå AI-rangeringstransparens har blitt essensielt for alle som produserer, distribuerer eller stoler på digitalt innhold i et stadig mer AI-formidlet informasjonslandskap.
AI-plattformer benytter Retrieval-Augmented Generation (RAG)-systemer som kombinerer språkmodeller med sanntidsinformasjonshenting for å forankre svar i faktiske kilder i stedet for kun å stole på treningsdata. RAG-prosessen har tre hovedfaser: henting (finne relevante dokumenter), rangering (ordne kilder etter relevans) og generering (syntetisere informasjon med opprettholdte sitater). Ulike plattformer implementerer ulike rangeringsmetoder—Perplexity prioriterer kildeautoritet og aktualitet, Googles AI Overviews vektlegger tematisk relevans og E-E-A-T-signaler (Erfaring, Ekspertise, Autoritet, Troværdighet), mens ChatGPT Search balanserer kildekvalitet med svarkompletthet. Faktorene som påvirker kildeutvalg inkluderer vanligvis domeneautoritet (etablert rykte og lenkeprofil), innholdets aktualitet (ferskhet), tematisk relevans (semantisk samsvar med forespørselen), engasjementssignaler (brukerinteraksjon) og siteringsfrekvens (hvor ofte kilder refereres av andre autoritative nettsteder). AI-systemer vektlegger disse signalene ulikt avhengig av forespørselsintensjon—faktuelle spørsmål kan prioritere autoritet og aktualitet, mens meningsbaserte spørsmål kan vektlegge ulike perspektiver og engasjement. Rangeringsalgoritmene forblir stort sett uoffentliggjorte, selv om plattformdokumentasjon gir noe innsyn i vektingsmekanismer.
| Plattform | Siteringstransparens | Kildeutvalgskriterier | Rangeringsalgoritme åpenhet | Brukerkontroll |
|---|---|---|---|---|
| Perplexity | Høy – kilder med lenker i teksten | Autoritet, aktualitet, relevans, temakunnskap | Moderat – noe dokumentasjon | Middels – kildefiltrering |
| Google AI Overviews | Middels – kilder listet | E-E-A-T, tematisk relevans, ferskhet, engasjement | Lav – minimal innsyn | Lav – begrenset tilpasning |
| ChatGPT Search | Middels – kilder separat | Kvalitet, relevans, omfang, autoritet | Lav – proprietær algoritme | Lav – ingen rangeringstilpasning |
| Brave Leo | Middels – kildeattributtering | Personvernvennlige kilder, relevans, autoritet | Lav – personvernfokusert uklarhet | Middels – kildevalg |
| Consensus | Svært høy – akademisk fokus med målinger | Siteringsantall, fagfellevurdering, aktualitet, fagrelevans | Høy – akademiske standarder åpne | Høy – filtrering etter studietype/kvalitet |
AI-bransjen mangler standardiserte åpenhetspraksiser for hvordan rangeringssystemer fungerer, noe som skaper et fragmentert landskap der hver plattform bestemmer sitt eget transparensnivå. OpenAIs ChatGPT Search gir minimal forklaring på kildevalg, Metas AI-systemer har begrenset dokumentasjon, og Googles AI Overviews avslører mer enn konkurrentene, men holder fortsatt tilbake viktige algoritmedetaljer. Plattformene motsetter seg full åpenhet grunnet konkurransefordeler, forretningshemmeligheter og kompleksiteten i å forklare maskinlæringssystemer for allmennheten—men denne uklarheten hindrer ekstern revisjon og ansvarlighet. “Kildelaundring”-problemet oppstår når AI-systemer siterer kilder som selv sammenfatter eller omskriver originalt innhold, og slik skjuler informasjonens egentlige opphav og potensielt forsterker feilinformasjon gjennom flere lag med syntese. Regulatorisk press øker: EUs AI-forordning krever at høy-risiko AI-systemer dokumenterer treningsdata og beslutningsprosesser, mens NTIAs AI-ansvarlighetspolicy ber selskaper avsløre AI-systemers kapabiliteter, begrensninger og hensiktsmessig bruk. Spesifikke åpenhetssvikt inkluderer Perplexitys første utfordringer med korrekt attribuering (senere forbedret), Googles vage forklaring på hvordan AI Overviews velger kilder, og ChatGPTs begrensede transparens om hvorfor noen kilder vises og andre ikke. Mangelen på standardiserte målemetoder for transparens gjør det vanskelig for brukere og tilsyn å sammenligne plattformer objektivt.
Uklarheten i AI-rangeringssystemer skaper betydelige synlighetsutfordringer for innholdsskapere, ettersom tradisjonelle SEO-strategier ikke direkte kan overføres til optimalisering for AI-plattformer. Utgivere kan ikke lett forstå hvorfor innholdet deres vises i noen AI-svar, men ikke andre, noe som gjør det umulig å utvikle målrettede strategier for bedre synlighet i AI-genererte svar. Siteringsskjevhet oppstår når AI-systemer i uforholdsmessig grad favoriserer visse kilder—etablerte nyhetsmedier, akademiske institusjoner eller høyt trafikkerte nettsteder—mens mindre utgivere, uavhengige skapere og nisjeeksperter blir marginalisert, selv om de kan ha like verdifull informasjon. Mindre utgivere møter særlige ulemper fordi AI-rangeringssystemer ofte vektlegger domeneautoritet, og nyere eller spesialiserte nettsteder mangler lenkeprofiler og merkevarekjennskap som etablerte aktører har. Forskning fra Search Engine Land viser at AI Overviews har redusert klikkraten til tradisjonelle søkeresultater med 18–64% avhengig av forespørselstype, med trafikk konsentrert blant de få kildene som siteres i AI-svar. Skillet mellom SEO (Search Engine Optimization) og GEO (Generative Engine Optimization) blir kritisk—mens SEO fokuserer på rangering i tradisjonelt søk, krever GEO forståelse og optimalisering for AI-plattformers utvalgskriterier, som forblir stort sett uklare. Innholdsskapere trenger verktøy som AmICited.com for å overvåke hvor innholdet deres vises i AI-svar, spore siteringsfrekvens og forstå synlighet på tvers av ulike AI-plattformer.
AI-bransjen har utviklet flere rammeverk for å dokumentere og avsløre systematferd, selv om etterlevelsen varierer mellom plattformer. Modellkort gir standardisert dokumentasjon av maskinlæringsmodellers ytelse, tiltenkte bruksområder, begrensninger og skjevhetsanalyse—tilsvarende næringsinnhold på matvarer. Datasettark dokumenterer sammensetning, innsamlingsmetodikk og mulige skjevheter i treningsdata, med utgangspunkt i at AI kun er så god som treningsinformasjonen. Systemkort tar en bredere tilnærming og dokumenterer systemets helhetlige atferd, inkludert komponentinteraksjoner, mulige feilmoduser og reell ytelse på tvers av brukergrupper. NTIA AI-ansvarlighetspolicy anbefaler at selskaper fører detaljert dokumentasjon av utvikling, testing og utrulling av AI-systemer, spesielt for høy-risiko anvendelser som påvirker offentligheten. EUs AI-forordning pålegger høy-risiko AI-systemer å opprettholde teknisk dokumentasjon, treningsdataregistreringer og ytelseslogger, samt krav til transparensrapporter og brukeropplysning. Bransjens beste praksis inkluderer i økende grad:
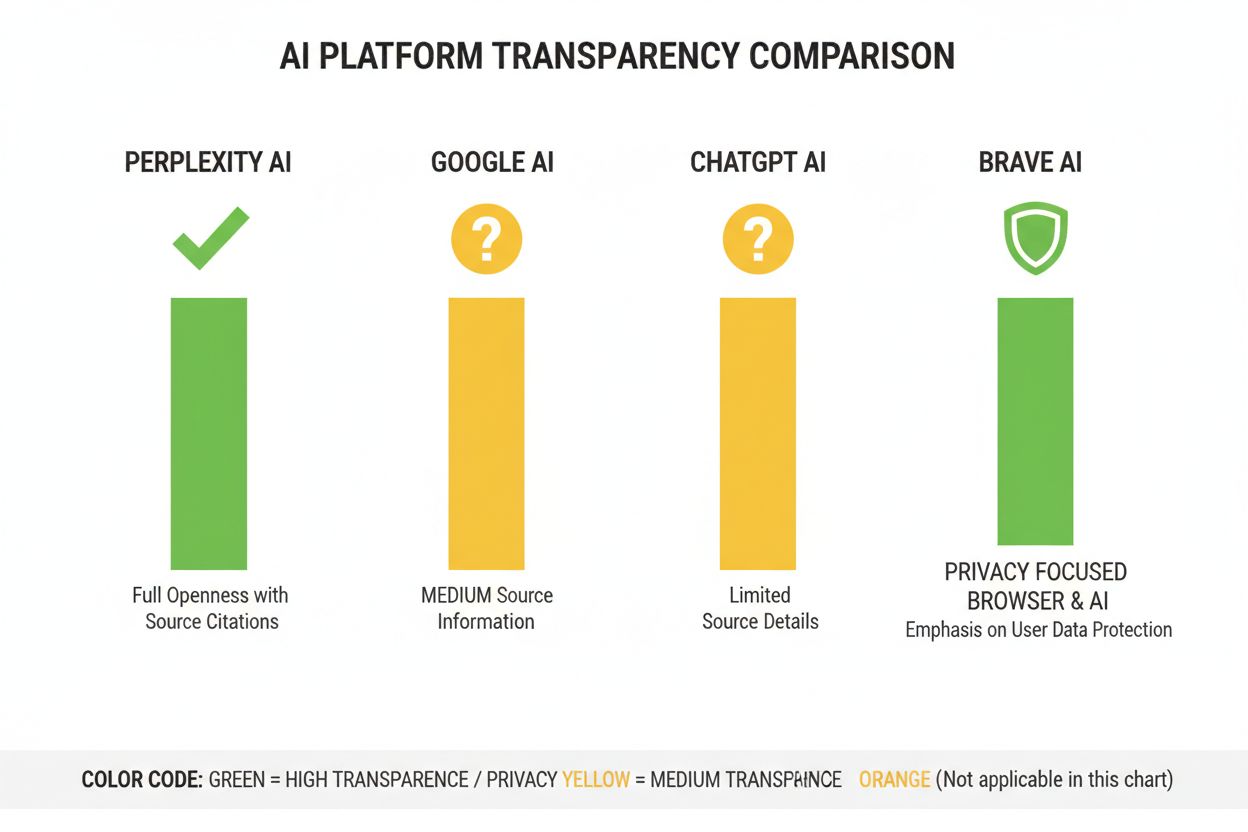
Perplexity har posisjonert seg som den mest siteringstransparente AI-plattformen, med kildelenker direkte i svarene slik at brukere ser hvilke kilder som har bidratt til hver uttalelse. Plattformen gir relativt tydelig dokumentasjon av rangeringsmetoden, med vekt på kildeautoritet, temakunnskap og innholdets aktualitet, selv om den nøyaktige vektingen forblir proprietær. Googles AI Overviews tilbyr moderat transparens ved å liste kilder på slutten av svarene, men gir begrenset forklaring på hvorfor visse kilder ble valgt eller hvordan rangeringsalgoritmen vekter ulike signaler. Googles dokumentasjon vektlegger E-E-A-T-prinsipper, men avslører ikke fullt ut hvordan disse måles eller vektes i AI-rangeringen. OpenAIs ChatGPT Search utgjør et mellomnivå, med kilder separat fra svareteksten og mulighet for å klikke seg til originalinnhold, men med minimal forklaring på utvalgskriterier og rangeringsmetodikk. Brave Leo prioriterer personvernrettet transparens, og informerer om at den bruker personvernvennlige kilder og ikke sporer brukerforespørsler, men dette går på bekostning av detaljert forklaring av rangeringsmekanismer. Consensus skiller seg ut med fokus på akademisk forskning, høy transparens gjennom siteringsmålinger, fagfellevurdering og kvalitetsindikatorer—og er den mest algoritmisk åpne plattformen for forskningsspørsmål. Brukerkontroll varierer betydelig: Perplexity gir kildefiltrering, Consensus lar brukerne filtrere på studietype og kvalitet, mens Google og ChatGPT tilbyr minimal tilpasning av rangeringspreferanser. Variasjonen i transparensstrategier reflekterer ulike forretningsmodeller og målgrupper, der akademiske plattformer prioriterer åpenhet, mens forbrukerplattformer balanserer transparens med forretningshemmelighold.
Tillit og troverdighet er avhengig av at brukere forstår hvordan informasjon når dem—når AI-systemer skjuler kilder eller rangeringslogikk, kan ikke brukerne selvstendig verifisere påstander eller vurdere kilders pålitelighet. Transparens muliggjør verifisering og faktasjekk, slik at forskere, journalister og kunnskapsrike brukere kan spore påstander tilbake til originalkilder og vurdere nøyaktighet og kontekst. Forebygging av feilinformasjon og skjevhet er et stort gode: når rangeringsalgoritmer er synlige, kan forskere avdekke systematiske skjevheter (som favorisering av visse politiske syn eller kommersielle interesser), og plattformer kan holdes ansvarlige for spredning av feilinformasjon. Algoritmisk ansvarlighet er en grunnleggende brukersrett i demokratiske samfunn—folk fortjener å vite hvordan systemene som former deres informasjonsmiljø tar beslutninger, spesielt når disse systemene påvirker opinion, kjøpsvalg og tilgang til kunnskap. For forskning og akademisk arbeid er transparens avgjørende fordi forskere må forstå kildeutvalg for å kunne tolke AI-genererte oppsummeringer riktig og sikre at de ikke uforvarende baserer seg på skjeve eller mangelfulle kildesett. Forretningsmessig er konsekvensene store: uten kunnskap om rangeringsfaktorer kan utgivere ikke optimalisere innholdsstrategien, mindre aktører får ikke konkurrere på like vilkår, og økosystemet blir mindre meritokratisk. Transparens beskytter også brukere mot manipulasjon—når rangeringskriterier er skjult, kan aktører utnytte ukjente svakheter for å fremme villedende innhold, mens åpne systemer kan revideres og forbedres.
Regulatoriske trender presser mot obligatorisk transparens: EUs AI-forordning fra 2025–2026 vil kreve detaljert dokumentasjon og åpenhet for høy-risiko AI-systemer, mens lignende reguleringer er på vei i Storbritannia, California og andre jurisdiksjoner. Bransjen beveger seg mot standardisering av transparenspraksis, med organisasjoner som Partnership on AI og akademiske institusjoner som utvikler felles rammeverk for dokumentasjon og åpenhet om AI-systemers atferd. Brukerkravet om transparens øker etter hvert som bevisstheten vokser rundt AIs rolle i informasjonsdistribusjon—undersøkelser viser at over 70 % av brukere vil forstå hvordan AI-systemer velger kilder og rangerer informasjon. Teknologiske fremskritt innen forklarbar AI (XAI) gjør det stadig mer mulig å gi detaljerte forklaringer på rangeringsbeslutninger uten å avsløre hele algoritmen, for eksempel med teknikker som LIME (Local Interpretable Model-agnostic Explanations) og SHAP (SHapley Additive exPlanations). Overvåkningsverktøy som AmICited.com vil bli stadig viktigere etter hvert som plattformer implementerer transparensmekanismer, og hjelpe innholdsskapere og utgivere å følge sin synlighet på tvers av flere AI-systemer og forstå hvordan rangeringsendringer påvirker rekkevidden. Samspillet mellom regulatoriske krav, brukerforventninger og teknologiske muligheter tilsier at 2025–2026 blir avgjørende år for AI-rangeringstransparens, med sannsynlig innføring av mer standardiserte åpenhetspraksiser, bedre brukerkontroll over kildeutvalg og tydeligere forklaringer på rangeringslogikk. Fremtidens landskap vil trolig preges av lagdelt transparens—akademiske og forskningsorienterte plattformer i front med høy åpenhet, forbrukerplattformer med moderat transparens og brukertilpasning, og regulatorisk etterlevelse som et minste krav i hele bransjen.
AI-rangeringstransparens handler om hvor åpent AI-plattformer avslører algoritmene sine for valg og rangering av kilder i genererte svar. Det er viktig fordi brukere må forstå kilders troverdighet, innholdsskapere må optimalisere for AI-synlighet, og forskere må kunne etterprøve informasjonskilder. Uten transparens kan AI-systemer forsterke feilinformasjon og skape urettferdige fordeler for etablerte aktører fremfor mindre utgivere.
AI-plattformer bruker Retrieval-Augmented Generation (RAG)-systemer som kombinerer språkmodeller med sanntidsinformasjonshenting. De rangerer kilder basert på faktorer som domeneautoritet, innholdets aktualitet, tematisk relevans, engasjementssignaler og siteringsfrekvens. Den nøyaktige vektingen av disse faktorene forblir imidlertid stort sett proprietær og ikke offentliggjort av de fleste plattformer.
Tradisjonell SEO fokuserer på rangering i søkemotorenes lenkelister, der Google publiserer generelle rangeringsfaktorer. AI-rangeringstransparens handler om hvordan AI-plattformer velger kilder for syntetiserte svar, noe som involverer andre kriterier og i stor grad er uoffentliggjort. Mens SEO-strategier er godt dokumentert, er AI-rangeringsfaktorer for det meste uklare.
Du kan klikke deg videre til de opprinnelige kildene for å verifisere påstander i full kontekst, sjekke om kildene kommer fra autoritative domener, se etter fagfellevurdering (spesielt i akademisk innhold), og kryssreferere informasjon på tvers av flere kilder. Verktøy som AmICited hjelper deg å spore hvilke kilder som vises i AI-svar og hvor ofte innholdet ditt blir sitert.
Consensus leder an i transparens ved å fokusere utelukkende på fagfellevurdert akademisk forskning med tydelige siteringsmålinger. Perplexity gir kildesiteringer direkte i teksten og moderat dokumentasjon av rangeringsfaktorer. Googles AI Overviews tilbyr middels transparens, mens ChatGPT Search og Brave Leo gir begrenset innsyn i sine rangeringsalgoritmer.
Modellkort er standardisert dokumentasjon av AI-systemets ytelse, tiltenkte bruksområder, begrensninger og skjevhetsanalyse. Datasettark dokumenterer sammensetning av treningsdata, innsamlingsmetoder og potensielle skjevheter. Systemkort beskriver systemets totalatferd. Disse verktøyene gjør AI-systemer mer transparente og sammenlignbare, på samme måte som næringsinnhold på matvarer.
EUs AI-forordning krever at høy-risiko AI-systemer opprettholder detaljert teknisk dokumentasjon, treningsdataregistreringer og ytelseslogger. Den pålegger transparensrapporter og varsling til brukere om bruk av AI-systemer. Disse kravene driver AI-plattformer mot større åpenhet om rangeringsmekanismer og utvalgskriterier for kilder.
AmICited.com er en AI-siteringsovervåkningsplattform som sporer hvordan AI-systemer som Perplexity, Google AI Overviews og ChatGPT siterer merkevaren og innholdet ditt. Den gir innsikt i hvilke kilder som vises i AI-svar, hvor ofte innholdet ditt blir sitert, og hvordan rangeringstransparensen din er på tvers av ulike AI-plattformer.
Følg med på hvordan AI-plattformer som Perplexity, Google AI Overviews og ChatGPT siterer innholdet ditt. Forstå din rangeringstransparens og optimaliser synligheten din på tvers av AI-søkemotorer med AmICited.
Oppdag hvorfor høye Google-rangeringer ikke garanterer AI-synlighet. Lær forskjellen mellom SEO og AI-sitater, og hvordan du optimaliserer for begge søkekanalen...

Lær hvordan Googles AI-rangeringssystemer, inkludert RankBrain, BERT og Neural Matching, fungerer for å forstå søk og rangere nettsider for relevans og kvalitet...
Oppdag kritiske AI-synlighetsblindsoner der konkurrenter får fordeler. Lær rammeverk for hullanalyse og verktøy for å overvåke AI-tilstedeværelse på tvers av Ch...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.