
Jak radzić sobie z duplikatami treści dla wyszukiwarek AI
Dowiedz się, jak zarządzać i zapobiegać duplikatom treści podczas korzystania z narzędzi AI. Poznaj znaczniki kanoniczne, przekierowania, narzędzia do wykrywani...
11 min czytania

Dowiedz się, jak adresy URL kanoniczne zapobiegają problemom z duplikacją treści w systemach wyszukiwania AI. Poznaj najlepsze praktyki wdrażania kanonicznych adresów, aby poprawić widoczność w AI i zapewnić właściwe przypisanie treści.
Duże modele językowe i systemy wyszukiwania AI stosują zaawansowane algorytmy klasteryzacji, aby identyfikować i grupować niemal identyczne adresy URL, traktując wiele wersji tej samej treści jako jedną jednostkę na potrzeby rankingu i cytowania. Gdy systemy AI napotykają duplikaty treści, muszą wybrać, którą wersję priorytetyzować—decyzja ta bezpośrednio wpływa na to, który adres URL otrzyma widoczność, sygnały autorytetu oraz przypisanie użytkownika. Krytyczny problem pojawia się, gdy AI wybierze niewłaściwą wersję: jeśli Twój adres kanoniczny wskazuje preferowaną stronę, ale system AI grupuje i promuje duplikat niższej jakości, Twoja treść traci widoczność i uznanie w cytowaniach. Sygnały intencji zostają rozmyte pomiędzy duplikaty, rozpraszając autorytet, który powinien być skonsolidowany na jednym adresie URL, przez co każdy duplikat otrzymuje słabsze sygnały rankingowe, niż gdyby cały autorytet był zjednoczony na wersji kanonicznej.
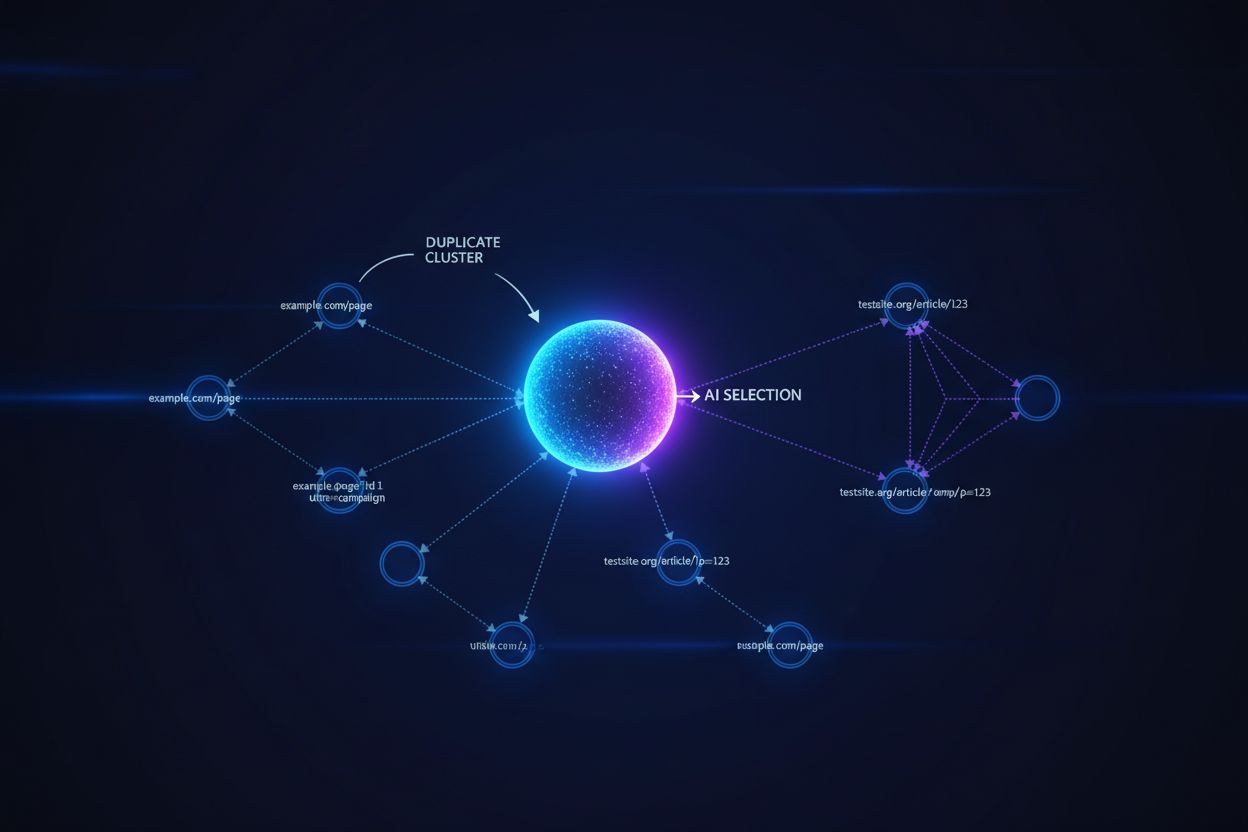
Tagi kanoniczne służą jako wyraźny sygnał dla systemów AI, która wersja zduplikowanej treści powinna być uznana za autorytatywną, bezpośrednio wpływając na to, czy Twój preferowany adres pojawi się w odpowiedziach generowanych przez AI i otrzyma właściwe przypisanie. Bez tagów kanonicznych, systemy AI muszą samodzielnie podejmować decyzje klasteryzujące na podstawie podobieństwa treści, profilu linków i sygnałów aktualności—co często skutkuje wyborem niewłaściwej wersji jako źródła kanonicznego. Gdy istnieje duplikacja treści bez prawidłowego wdrożenia kanonicznego, odpowiedzi AI mogą cytować wersję syndykowaną, kopię z pamięci podręcznej lub wariant niższej jakości zamiast Twojej oryginalnej treści, rozpraszając widoczność między wiele adresów. Kanoniczne adresy URL zapewniają, że gdy systemy AI napotkają Twoją treść na różnych domenach, z różnymi parametrami lub w różnych wersjach, rozumieją, który pojedynczy adres powinien otrzymać uznanie i być wyświetlany w odpowiedziach.
| Scenariusz | Bez kanonicznego | Z kanonicznym |
|---|---|---|
| Wpływ na AI | AI samodzielnie grupuje duplikaty; może wybrać niewłaściwą wersję do rankingu | AI rozpoznaje jedno autorytatywne źródło; konsoliduje wszystkie sygnały do kanonicznego adresu URL |
| Przypisanie cytatów | Przypisanie rozproszone między wiele adresów; słabszy autorytet dla każdego | Wszystkie cytowania i autorytet trafiają do kanonicznego adresu; silniejsza widoczność |
| Efekt | Treść pojawia się w odpowiedziach AI, ale niewłaściwy adres dostaje uznanie; rozproszona widoczność | Preferowany adres pojawia się w odpowiedziach AI z pełną konsolidacją autorytetu |
Tagi kanoniczne i przekierowania służą różnym celom w zarządzaniu duplikacją treści dla systemów AI: tagi kanoniczne informują wyszukiwarki i AI, która wersja jest preferowana przy zachowaniu dostępności obu adresów, natomiast przekierowania trwale kierują użytkowników i boty z jednego adresu na inny. Przekierowania (301 dla trwałych przeniesień, 302 dla tymczasowych) są silniejszym sygnałem, ponieważ całkowicie konsolidują autorytet pod jednym adresem i eliminują duplikat z sieci, co czyni je idealnym rozwiązaniem, gdy na stałe wycofujesz adres lub konsolidujesz domeny. Tagi kanoniczne są lepsze, gdy musisz utrzymać wiele adresów ze względów biznesowych—takich jak parametry śledzące do analityki, zachowanie starych adresów dla zakładek użytkowników, czy serwowanie różnych wersji różnym odbiorcom—jednocześnie wskazując systemom AI, która wersja jest autorytatywna. Stosuj przekierowania podczas konsolidacji domen po migracji, usuwaniu nieaktualnych wersji lub eliminowaniu wariantów parametrów, które nie mają sensu. Stosuj tagi kanoniczne, gdy musisz utrzymać wiele adresów, ale chcesz zapobiec karom za duplikację i zapewnić AI zrozumienie preferowanej wersji.
Najważniejsze różnice między kanonicznymi a przekierowaniami:
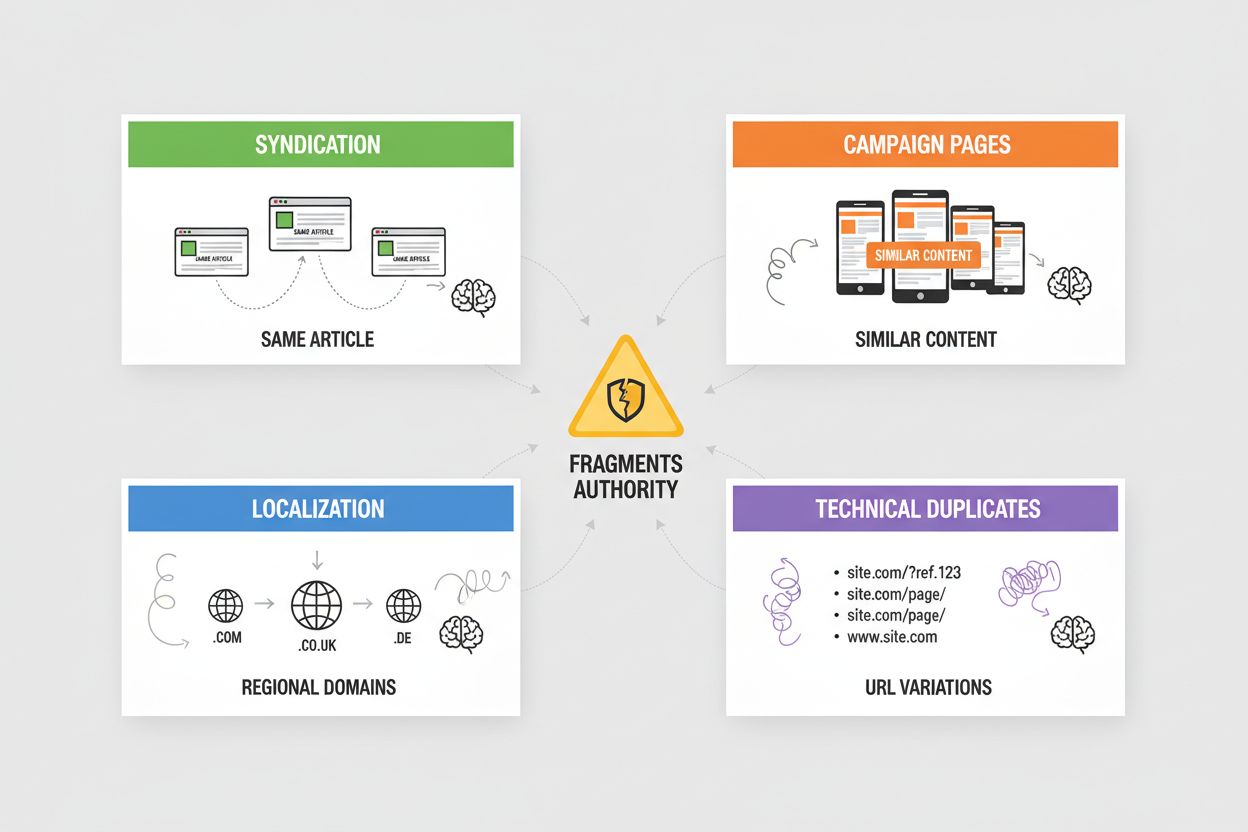
Syndykacja powoduje szeroką duplikację, gdy Twoje artykuły są przedrukowywane na stronach partnerskich, agregatorach wiadomości czy w sieciach treści—systemy AI muszą zdecydować, czy uznać oryginał czy wersję syndykowaną, często wybierając tę napotkaną jako pierwszą podczas indeksowania. Strony kampanii generują duplikaty przy tworzeniu wielu landing page’y z identyczną lub niemal identyczną treścią dla różnych kanałów marketingowych, parametrów UTM lub testów A/B, co prowadzi do rozproszenia autorytetu przez AI między warianty, które powinny być skonsolidowane. Lokalizacja i internacjonalizacja produkują duplikaty, gdy serwujesz podobną treść na domenach regionalnych (example.com, example.co.uk, example.de) lub w wersjach językowych—wymagane są tagi hreflang i wdrożenie kanonicznych, by systemy AI nie traktowały tego jako duplikatów, lecz zamierzone warianty. Duplikaty techniczne powstają przez ID sesji, parametry śledzące, wersje do druku oraz wariacje adresów (www vs. bez www, http vs. https, końcowe ukośniki), które prowadzą do wielu adresów wskazujących na tę samą treść—AI widzi je jako duplikaty i musi zdecydować, którą wersję priorytetyzować. Każdy z tych scenariuszy osłabia autorytet, który powinien skupiać się na preferowanym adresie, zmniejszając widoczność w odpowiedziach AI i rozpraszając cytowania między wiele wersji.
Zawsze używaj bezwzględnych adresów URL w tagach kanonicznych zamiast względnych, dzięki czemu systemy AI i wyszukiwarki mogą jednoznacznie zidentyfikować docelowy adres bez względu na miejsce umieszczenia tagu. Stosuj samoodwołujące się kanoniczne na preferowanych stronach—nawet strony bez duplikatów powinny wskazywać same siebie jako kanoniczne, by zapobiec domyślnemu wybieraniu kanonicznego przez AI na podstawie linków lub podobieństwa treści. Umieszczaj tagi kanoniczne w sekcji <head> dokumentu HTML, a dla treści nie-HTML (PDF, obrazy) implementuj kanoniczne poprzez nagłówki HTTP, by AI rozpoznawało preferencję niezależnie od typu treści.
<!-- Poprawna implementacja kanonicznego w sekcji head HTML -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
Umieszczaj kanoniczne adresy w mapach XML, by wzmocnić wskazanie wersji autorytatywnych, i łącz je z tagami hreflang przy obsłudze treści międzynarodowych lub lokalizowanych, aby zapobiec traktowaniu wariantów regionalnych jako duplikatów przez AI. Unikaj typowych błędów: nigdy nie twórz łańcuchów kanonicznych (A→B→C), nie wskazuj stron z noindex jako kanonicznych i nie używaj kanonicznych do manipulowania rankingami przez wskazywanie niepowiązanej treści. Monitoruj wdrożenie kanonicznych za pomocą narzędzi takich jak Google Search Console, Bing Webmaster Tools i AmICited.com, by sprawdzić, czy systemy AI rozpoznają preferowane adresy i prawidłowo przypisują treści.
<!-- Poprawna implementacja z hreflang dla treści międzynarodowych -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/article/canonical-urls-ai" />
<link rel="alternate" hreflang="de" href="https://example.de/artikel/canonical-urls-ai" />
Audytuj adresy kanoniczne za pomocą pełnego crawlowania strony narzędziami takimi jak Screaming Frog, SEMrush lub Ahrefs, by wykryć strony bez kanonicznych, zerwane łańcuchy kanoniczne lub kanoniczne wskazujące na strony z noindex—te błędy uniemożliwiają AI prawidłową konsolidację autorytetu. Skorzystaj z raportu Pokrycie w Google Search Console, by znaleźć strony z problemami z duplikacją oraz sprawdzić, czy Google rozpoznaje Twoje preferencje kanoniczne, a następnie porównaj z Bing Webmaster Tools, by zapewnić spójność między systemami AI. Wdróż IndexNow, aby natychmiast powiadamiać wyszukiwarki i boty AI o dodaniu, aktualizacji lub usunięciu tagów kanonicznych, przyspieszając wykrycie preferencji zamiast czekać na naturalne cykle indeksowania. Monitoruj cytowania AI za pomocą narzędzi takich jak AmICited.com i wyszukiwań ręcznych w ChatGPT, Claude i Perplexity, by upewnić się, że preferowane adresy otrzymują uznanie w odpowiedziach AI—jeśli cytowane są duplikaty, ponownie przejrzyj wdrożenie kanonicznych i upewnij się, że tagi są poprawnie sformatowane i umieszczone. Regularnie audytuj nowe duplikaty treści powstałe w wyniku współpracy syndykacyjnej, uruchamiania kampanii czy zmian technicznych, wdrażając kanoniczne proaktywnie, by utrzymać spójną widoczność w AI.
Adres URL kanoniczny to preferowana wersja strony, którą chcesz, aby wyszukiwarki i systemy AI rozpoznawały jako autorytatywną. Ma to znaczenie dla wyszukiwania AI, ponieważ modele językowe grupują niemal identyczne adresy URL i wybierają jedną wersję jako reprezentanta zbioru. Bez poprawnej implementacji kanonicznej systemy AI mogą cytować niewłaściwą wersję Twojej treści, rozpraszając widoczność i przypisanie między wiele adresów URL.
Systemy AI wykorzystują algorytmy klasteryzacji do grupowania niemal identycznych adresów URL w pojedyncze jednostki, a następnie wybierają jedną wersję do reprezentowania całego klastra. Różni się to od tradycyjnych wyszukiwarek, ponieważ odpowiedzi AI wymagają pojedynczego adresu źródłowego do przypisania. Jeśli Twój adres kanoniczny nie jest poprawnie wdrożony, AI może wybrać wersję syndykowaną, kopię z pamięci podręcznej lub niższej jakości wariant zamiast preferowanego adresu URL.
Używaj tagów kanonicznych, gdy musisz utrzymać wiele adresów URL ze względów biznesowych (parametry śledzące, stare adresy, różne grupy odbiorców), jednocześnie sygnalizując preferencję systemom AI. Używaj przekierowań, gdy na stałe wycofujesz adres URL, konsolidujesz domeny lub eliminujesz niepotrzebne wariacje parametrów. Przekierowania są silniejszym sygnałem, ponieważ całkowicie konsolidują autorytet, podczas gdy kanoniczne rozdzielają autorytet, ale wskazują preferencję.
Najczęstsze problemy to: syndykacja (przedruk artykułów na stronach partnerskich), strony kampanii (wiele landing page'y z identyczną treścią), lokalizacja (podobna treść na domenach regionalnych) oraz duplikaty techniczne (parametry URL, ID sesji, końcowe ukośniki). Każda z tych sytuacji rozprasza autorytet między wiele adresów URL, zmniejszając widoczność w odpowiedziach generowanych przez AI.
Zawsze używaj bezwzględnych adresów URL (https://example.com/page, nie /page), umieszczaj tagi kanoniczne w sekcji head HTML, stosuj samoodwołujące się kanoniczne na wszystkich stronach i unikaj łańcuchów kanonicznych (A→B→C). Dla treści nie-HTML, takich jak PDF, używaj nagłówków HTTP. Umieść kanoniczne w mapie strony XML i łącz je z tagami hreflang dla treści międzynarodowych.
Użyj Google Search Console i Bing Webmaster Tools, by zweryfikować rozpoznanie kanonicznych, monitoruj cytowania AI za pomocą AmICited.com i wyszukiwań ręcznych w ChatGPT/Claude/Perplexity oraz audytuj stronę narzędziami typu Screaming Frog lub SEMrush. Jeśli cytowane są duplikaty zamiast kanonicznych, sprawdź implementację i upewnij się, że tagi są poprawnie sformatowane i umieszczone w sekcji head HTML.
IndexNow to protokół natychmiast powiadamiający wyszukiwarki oraz roboty AI o dodaniu, aktualizacji lub usunięciu tagów kanonicznych, zamiast czekać na naturalny cykl indeksowania. Przyspiesza to wykrycie Twoich preferencji kanonicznych i pomaga szybciej zapewnić, że systemy AI rozpoznają preferowane adresy URL, skracając czas pojawiania się duplikatów w odpowiedziach AI.
Tak, tagi kanoniczne są silnym sygnałem, ale nie poleceniem. Systemy AI mogą zignorować Twoją preferencję kanoniczną, jeśli uznają, że inna wersja jest bardziej autorytatywna na podstawie jakości treści, profilu linków, aktualności lub innych sygnałów. Dlatego właściwa implementacja w połączeniu z mocną treścią i autorytetem zwiększa szansę, że systemy AI uszanują Twój wybór kanoniczny.
Śledź, jak systemy AI, takie jak ChatGPT, Claude i Perplexity, cytują Twoje treści. Upewnij się, że Twoje adresy kanoniczne są prawidłowo rozpoznawane, a Twoja marka otrzymuje właściwe przypisanie w odpowiedziach generowanych przez AI.
Dowiedz się, jak zarządzać i zapobiegać duplikatom treści podczas korzystania z narzędzi AI. Poznaj znaczniki kanoniczne, przekierowania, narzędzia do wykrywani...
Dyskusja społeczności na temat tego, jak systemy AI radzą sobie z duplikatami treści inaczej niż tradycyjne wyszukiwarki. Specjaliści SEO dzielą się spostrzeżen...
Dowiedz się, czym jest kannibalizacja treści przez AI, jak różni się od zduplikowanej treści, dlaczego szkodzi pozycjonowaniu oraz poznaj strategie ochrony swoi...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.