Kompletna lista crawlerów AI w 2025 roku: Wszystkie boty, które powinieneś znać
Kompleksowy przewodnik po crawlerach AI w 2025 roku. Zidentyfikuj GPTBot, ClaudeBot, PerplexityBot i ponad 20 innych botów AI. Dowiedz się, jak blokować, zezwalać lub monitorować crawlery za pomocą robots.txt i zaawansowanych technik.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
Crawlery AI to zautomatyzowane boty stworzone do systematycznego przeszukiwania i zbierania danych ze stron internetowych, jednak ich cel zasadniczo zmienił się w ostatnich latach. Podczas gdy tradycyjne crawlery wyszukiwarek, takie jak Googlebot, skupiają się na indeksowaniu treści do wyników wyszukiwania, nowoczesne crawlery AI priorytetowo traktują zbieranie danych treningowych dla dużych modeli językowych i systemów generatywnej AI. Według najnowszych danych Playwire, crawlery AI stanowią obecnie około 80% całego ruchu botów AI, co oznacza ogromny wzrost liczby i różnorodności zautomatyzowanych odwiedzin stron. Ta zmiana odzwierciedla szerszą transformację sposobu rozwoju i trenowania systemów sztucznej inteligencji, które odchodzą od ogólnodostępnych zbiorów danych na rzecz bieżącego pozyskiwania treści z sieci. Zrozumienie tych crawlerów stało się kluczowe dla właścicieli stron, wydawców i twórców treści, którzy muszą podejmować świadome decyzje dotyczące swojej obecności w internecie.
Trzy kategorie crawlerów AI
Crawlery AI można zaklasyfikować do trzech odrębnych kategorii w zależności od ich funkcji, zachowania i wpływu na Twoją stronę. Crawlery treningowe stanowią największy segment, odpowiadając za około 80% ruchu botów AI, i są przeznaczone do zbierania treści na potrzeby trenowania modeli uczenia maszynowego; te crawlery zazwyczaj działają na dużą skalę i nie generują ruchu zwrotnego, przez co są wymagające pod względem przepustowości, ale mało prawdopodobne, by sprowadzały użytkowników z powrotem na Twoją stronę. Crawlery wyszukiwania i cytowania pracują ze średnią intensywnością i są specjalnie zaprojektowane do wyszukiwania i odwoływania się do treści w wynikach wyszukiwania i aplikacjach opartych o AI; w przeciwieństwie do crawlerów treningowych, te boty mogą faktycznie przekierowywać ruch na Twoją stronę, gdy użytkownicy klikają odpowiedzi generowane przez AI. Fetchery wywoływane przez użytkowników to najmniejsza kategoria, działająca na żądanie, gdy użytkownicy ręcznie proszą o pobranie treści przez aplikacje AI, takie jak funkcja przeglądania w ChatGPT; te crawlery mają niski wolumen, ale wysoką trafność względem konkretnych zapytań użytkowników.
Kategoria
Cel
Przykłady
Crawlery treningowe
Zbieranie danych do trenowania modeli AI
GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider
Crawlery wyszukiwania/cytowania
Wyszukiwanie i cytowanie treści w odpowiedziach AI
OpenAI prowadzi najbardziej różnorodny i agresywny ekosystem crawlerów w krajobrazie AI, z wieloma botami obsługującymi różne cele w ramach ich produktów. GPTBot to ich główny crawler treningowy, odpowiedzialny za zbieranie treści w celu ulepszania GPT-4 i przyszłych modeli, a według danych Cloudflare jego ruch wzrósł o imponujące 305%; ten bot działa z relacją pobrań do odesłań 400:1, co oznacza, że pobiera treści 400 razy na jedno skierowanie użytkownika na Twoją stronę. OAI-SearchBot pełni zupełnie inną funkcję, skupiając się na wyszukiwaniu i cytowaniu treści na potrzeby funkcji wyszukiwania ChatGPT, bez wykorzystywania ich do trenowania modeli. ChatGPT-User to najszybciej rosnąca kategoria, z niesamowitym wzrostem ruchu o 2 825%, działającym zawsze, gdy użytkownik włącza opcję „Przeglądaj z Bing”, by pobrać aktualne treści na żądanie. Crawlery te można rozpoznać po user-agentach: GPTBot/1.0, OAI-SearchBot/1.0 i ChatGPT-User/1.0, a OpenAI udostępnia metody weryfikacji IP, by potwierdzić autentyczność ruchu botów ze swojej infrastruktury.
Crawlery AI Anthropic i Google
Anthropic, firma stojąca za Claude, prowadzi jedną z najbardziej selektywnych, ale intensywnych operacji crawlerów w branży. ClaudeBot to ich główny crawler treningowy i działa z niezwykłą relacją pobrań do odesłań 38 000:1, pobierając treści znacznie bardziej agresywnie niż boty OpenAI w stosunku do wysyłanego ruchu; ta skrajna proporcja odzwierciedla nacisk Anthropic na kompleksowe zbieranie danych do trenowania modeli. Claude-Web i Claude-SearchBot pełnią inne role — pierwszy obsługuje pobieranie treści na żądanie użytkownika, a drugi skupia się na funkcjach wyszukiwania i cytowania. Google zaadaptował swoją strategię crawlerów do ery AI, wprowadzając Google-Extended, specjalny token umożliwiający stronom wybór udziału w treningu AI przy jednoczesnym blokowaniu tradycyjnego indeksowania przez Googlebot, oraz Gemini-Deep-Research, który realizuje głębokie zapytania badawcze dla użytkowników produktów AI od Google. Wielu właścicieli stron zastanawia się, czy blokować Google-Extended, ponieważ pochodzi od tej samej firmy, która kontroluje ruch z wyszukiwarki, przez co decyzja jest trudniejsza niż w przypadku crawlerów AI firm trzecich.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Meta, Apple, Amazon i Perplexity
Meta stała się znaczącym graczem w obszarze crawlerów AI dzięki Meta-ExternalAgent, który odpowiada za około 19% ruchu crawlerów AI i służy do trenowania modeli AI oraz zasilania funkcji w Facebooku, Instagramie i WhatsAppie. Meta-WebIndexer pełni funkcję uzupełniającą, skupiając się na indeksowaniu sieci na potrzeby funkcji AI i rekomendacji. Apple wprowadził Applebot-Extended na potrzeby Apple Intelligence, czyli funkcji AI na urządzeniach, a jego crawler stale rośnie wraz z rozwojem AI na iPhone’ach, iPadach i Macach. Amazon obsługuje Amazonbot na potrzeby Alexy i Rufusa, asystenta zakupowego AI, co czyni go istotnym dla stron e-commerce i treści produktowych. PerplexityBot to jeden z najbardziej dynamicznych przypadków wzrostu wśród crawlerów, notując imponujący wzrost ruchu o 157 490%, co odzwierciedla gwałtowny rozwój Perplexity AI jako alternatywy dla wyszukiwarek; pomimo tego wzrostu, Perplexity odpowiada za mniejszy wolumen niż OpenAI i Google, lecz trend wskazuje na szybko rosnące znaczenie.
Nowe i wyspecjalizowane crawlery
Poza głównymi graczami, wiele nowych i wyspecjalizowanych crawlerów AI aktywnie zbiera dane z całej sieci. Bytespider, obsługiwany przez ByteDance (właściciela TikToka), zanotował gwałtowny spadek ruchu o 85%, co może oznaczać zmianę strategii lub mniejszą potrzebę zbierania danych do trenowania. Cohere, Diffbot i CCBot projektu Common Crawl to przykłady wyspecjalizowanych crawlerów skupiających się na określonych zastosowaniach — od trenowania modeli językowych po ekstrakcję danych strukturalnych. You.com, Mistral i DuckDuckGo prowadzą własne crawlery wspierające wyszukiwanie i asystentów opartych na AI, dokładając się do coraz większej złożoności ekosystemu crawlerów. Nowe crawlery pojawiają się regularnie — zarówno startupy, jak i uznane firmy nieustannie wdrażają produkty AI wymagające gromadzenia danych z sieci. Bycie na bieżąco z nowymi crawlerami jest kluczowe, ponieważ ich blokowanie lub dopuszczanie może znacząco wpłynąć na Twoją widoczność w nowych platformach i aplikacjach opartych na AI.
Jak rozpoznać crawlery AI
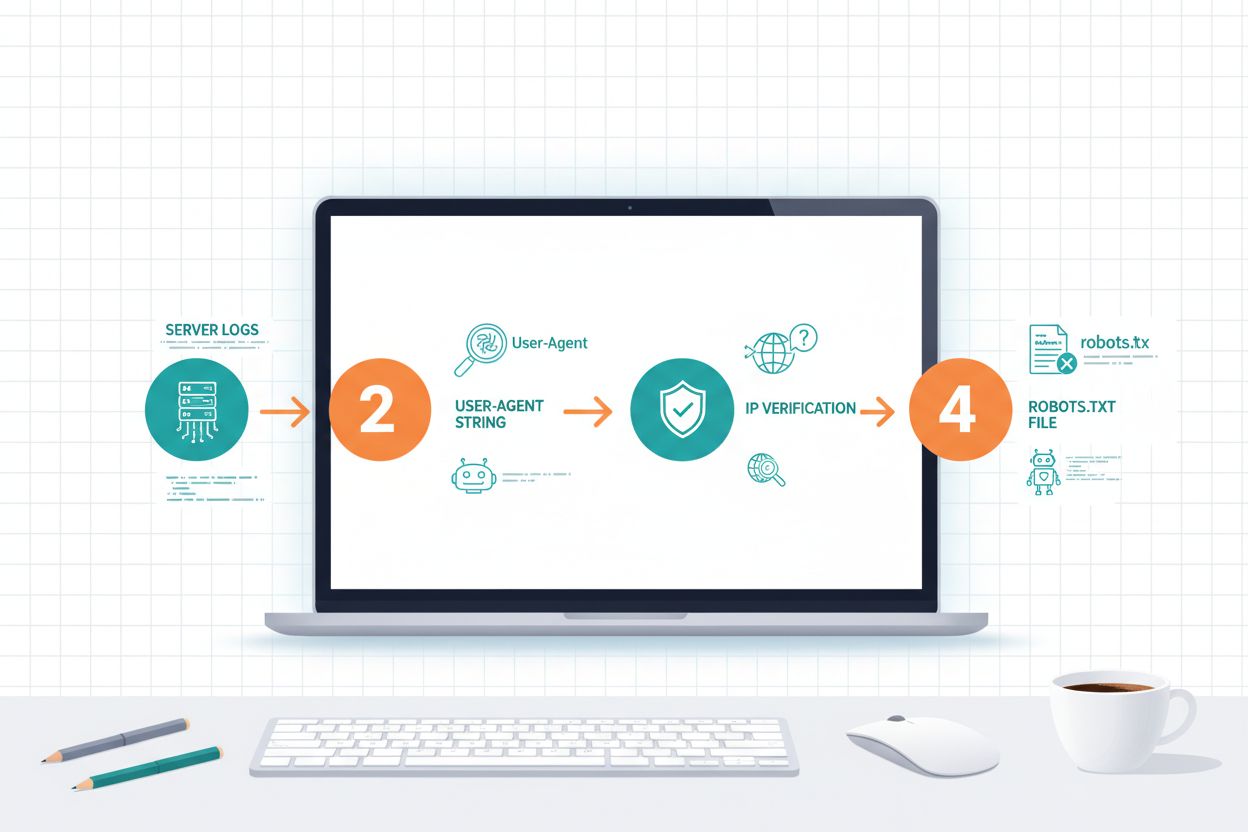
Identyfikacja crawlerów AI wymaga zrozumienia, jak się one przedstawiają i analizowania wzorców ruchu na Twoim serwerze. Ciągi user-agent to główna metoda identyfikacji, ponieważ każdy crawler podaje charakterystyczny identyfikator w żądaniach HTTP; na przykład GPTBot używa GPTBot/1.0, ClaudeBot — Claude-Web/1.0, a PerplexityBot — PerplexityBot/1.0. Analiza logów serwera (zwykle w /var/log/apache2/access.log na serwerach Linux lub w logach IIS na Windows) pozwala sprawdzić, które crawlery odwiedzają Twoją stronę i jak często. Weryfikacja IP to kolejna ważna technika — można sprawdzić, czy crawler podający się za OpenAI lub Anthropic faktycznie korzysta z oficjalnych zakresów IP publikowanych dla bezpieczeństwa przez te firmy. Sprawdzenie pliku robots.txt ujawnia, które crawlery zostały wyraźnie dopuszczone lub zablokowane, a porównanie tego z faktycznym ruchem pokazuje, czy crawlery przestrzegają wytycznych. Narzędzia takie jakCloudflare Radar zapewniają wgląd w czasie rzeczywistym w ruch botów i pomagają ustalić, które z nich są najbardziej aktywne na Twojej stronie. Praktyczne kroki identyfikacji obejmują: sprawdzanie ruchu botów w platformie analitycznej, przeglądanie surowych logów serwera pod kątem wzorców user-agent, weryfikację adresów IP względem opublikowanych zakresów crawlerów oraz korzystanie z narzędzi online do weryfikacji podejrzanych źródeł ruchu.
Dylemat: blokować czy pozwalać?
Decyzja o dopuszczeniu lub blokowaniu crawlerów AI wymaga rozważenia kilku konkurujących ze sobą czynników biznesowych i nie ma tutaj uniwersalnej odpowiedzi. Najważniejsze kompromisy obejmują:
Widoczność w aplikacjach AI: Pozwalając crawlerom na dostęp, zapewniasz obecność swoich treści w wynikach wyszukiwania, platformach odkrywania i odpowiedziach asystentów AI, co może generować ruch z nowych źródeł
Przepustowość i obciążenie serwera: Crawlery treningowe zużywają dużo pasma i zasobów, a niektóre strony notują wzrost ruchu o 10–30% tylko z powodu botów AI, co może zwiększyć koszty hostingu
Ochrona treści kontra ruch: Blokowanie crawlerów chroni Twoje treści przed wykorzystaniem do trenowania AI, ale eliminuje możliwość otrzymania ruchu z platform AI
Potencjał ruchu zwrotnego: Crawlery wyszukiwania i cytowania, jak PerplexityBot i OAI-SearchBot, mogą kierować ruch na Twoją stronę, podczas gdy crawlery treningowe, jak GPTBot i ClaudeBot, zazwyczaj tego nie robią
Pozycja konkurencyjna: Konkurenci pozwalający na dostęp crawlerów mogą uzyskać przewagę w widoczności w aplikacjach AI, podczas gdy Ty pozostaniesz niewidoczny, co wpływa na pozycję na rynku AI
Ponieważ 80% ruchu botów AI pochodzi od crawlerów treningowych o niskim potencjale ruchu zwrotnego, wielu wydawców decyduje się blokować crawlerów treningowych, pozwalając jednocześnie na dostęp crawlerom wyszukiwania i cytowania. Ostateczna decyzja zależy od modelu biznesowego, rodzaju treści i priorytetów strategicznych dotyczących widoczności w AI oraz zużycia zasobów.
Konfiguracja robots.txt dla crawlerów AI
Plik robots.txt to podstawowe narzędzie do komunikowania polityki wobec crawlerów AI, choć należy pamiętać, że jego przestrzeganie jest dobrowolne i technicznie niewymuszane. Robots.txt wykorzystuje dopasowanie user-agenta do określenia reguł dla konkretnych botów; możesz na przykład zablokować GPTBot, a pozwolić OAI-SearchBot, lub zablokować wszystkie crawlery treningowe, dopuszczając tylko wyszukiwarkowe. Według najnowszych badań tylko 14% z 10 000 największych domen wdrożyło reguły robots.txt specyficzne dla AI, co oznacza, że większość stron nie zoptymalizowała jeszcze polityki crawlerów pod kątem AI. Składnia pliku jest prosta — podajesz nazwę user-agenta, a następnie dyrektywy disallow lub allow; możesz używać znaków wieloznacznych do dopasowania wielu botów o podobnych nazwach.
Oto trzy praktyczne scenariusze konfiguracji robots.txt:
Pamiętaj, że robots.txt ma jedynie charakter doradczy, a złośliwe lub nieprzestrzegające boty mogą całkowicie ignorować Twoje wytyczne. Dopasowanie user-agenta nie jest rozróżniane pod względem wielkości liter, więc gptbot, GPTBot i GPTBOT odnoszą się do tego samego crawlery, a User-agent: * tworzy reguły dla wszystkich crawlerów.
Zaawansowane metody ochrony
Poza robots.txt istnieją zaawansowane metody mocniejszej ochrony przed niechcianymi crawlerami AI, choć każda z nich różni się skutecznością i złożonością wdrożenia. Weryfikacja IP i reguły zapory sieciowej pozwalają blokować ruch z określonych zakresów adresów IP przypisanych crawlerom AI; zakresy te można uzyskać z dokumentacji operatorów crawlerów i skonfigurować zaporę lub Web Application Firewall (WAF) do odrzucania żądań z tych adresów IP, ale wymaga to ciągłej aktualizacji wraz ze zmianami zakresów. Blokowanie na poziomie serwera przez .htaccess w Apache umożliwia sprawdzanie user-agenta i adresu IP przed udostępnieniem treści, gwarantując większą skuteczność niż robots.txt, ponieważ działa na poziomie serwera, nie polegając na dobrej woli crawlerów.
Oto praktyczny przykład .htaccess dla blokowania crawlerów:
# Blokuj crawlery treningowe AI na poziomie serwera<IfModulemod_rewrite.c> RewriteEngine On# Blokuj po ciągu user-agent RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|Meta-ExternalAgent|Amazonbot|Bytespider) [NC]
RewriteRule ^.*$ - [F,L]
# Blokuj po adresie IP (przykładowe IP - zamień na faktyczne adresy crawlerów) RewriteCond %{REMOTE_ADDR} ^192\.0\.2\.0$ [OR]
RewriteCond %{REMOTE_ADDR} ^198\.51\.100\.0$
RewriteRule ^.*$ - [F,L]
# Pozwól określonym crawlerom, blokując inne RewriteCond %{HTTP_USER_AGENT} !OAI-SearchBot [NC]
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule># Podejście z meta tagami HTML (dodaj do nagłówków strony)# <meta name="robots" content="noarchive, noimageindex"># <meta name="googlebot" content="noindex, nofollow">
Meta tagi HTML takie jak <meta name="robots" content="noarchive"> oraz <meta name="googlebot" content="noindex"> zapewniają kontrolę na poziomie strony, choć są mniej niezawodne niż blokowanie serwerowe, ponieważ crawler musi przeanalizować HTML, aby je zobaczyć. Warto pamiętać, że podszywanie się pod adresy IP jest technicznie możliwe, więc zaawansowani aktorzy mogą udawać legalne IP crawlerów, dlatego łączenie wielu metod daje lepszą ochronę niż poleganie na jednej. Każda metoda ma inne zalety: robots.txt jest łatwy do wdrożenia, ale nieegzekwowalny, blokowanie IP jest skuteczne, lecz wymaga aktualizacji, .htaccess zapewnia egzekwowanie na poziomie serwera, a meta tagi umożliwiają precyzyjną kontrolę na poziomie strony.
Monitorowanie i weryfikacja
Samo wdrożenie polityki wobec crawlerów to połowa sukcesu — musisz aktywnie monitorować, czy crawlery przestrzegają Twoich wytycznych i dostosowywać strategię w oparciu o rzeczywiste wzorce ruchu. Logi serwera to podstawowe źródło danych, zlokalizowane zwykle w /var/log/apache2/access.log na Linuxie lub w katalogu logów IIS na Windows, gdzie możesz wyszukać konkretne ciągi user-agent i policzyć, które crawlery odwiedzają stronę. Platformy analityczne takie jak Google Analytics, Matomo czy Plausible można skonfigurować do osobnego śledzenia ruchu botów względem użytkowników, co pozwala analizować wolumen i zachowania różnych crawlerów w czasie. Cloudflare Radar zapewnia wgląd w czasie rzeczywistym w ruch crawlerów w całym internecie i umożliwia porównanie ruchu na Twojej stronie do średniej branżowej. Aby sprawdzić, czy crawlery respektują blokady, możesz użyć narzędzi online do testowania pliku robots.txt, przeglądać logi serwera pod kątem zablokowanych user-agentów oraz porównywać adresy IP z opublikowanymi zakresami, by potwierdzić legalność źródeł ruchu. Praktyczne kroki monitoringu obejmują: cotygodniową analizę logów pod kątem wolumenu crawlerów, konfigurację powiadomień o nietypowej aktywności, comiesięczny przegląd ruchu botów w analityce oraz kwartalne przeglądy polityk crawlerów, by upewnić się, że są zgodne z aktualnymi celami biznesowymi. Regularny monitoring pozwala identyfikować nowe crawlery, wykrywać naruszenia polityki oraz podejmować decyzje oparte na danych, dotyczące dopuszczania lub blokowania poszczególnych botów.
Przyszłość crawlerów AI
Krajobraz crawlerów AI ewoluuje bardzo szybko — pojawiają się nowi gracze, a istniejące boty rozbudowują możliwości w nieoczekiwanych kierunkach. Nowe crawlery od firm takich jak xAI (Grok), Mistral i DeepSeek zaczynają gromadzić dane na dużą skalę, a każda nowa firma AI prawdopodobnie stworzy własnego crawlera do trenowania modeli i funkcji produktów. Przeglądarki agentowe to nowa granica technologii crawlerów — systemy takie jak ChatGPT Operator i Comet potrafią wchodzić w interakcje ze stronami jak ludzie: klikać, wypełniać formularze czy poruszać się po interfejsach; tego typu boty są trudniejsze do rozpoznania i zablokowania tradycyjnymi metodami. Wyzwanie z agentami przeglądarkowymi polega na tym, że mogą nie ujawniać się w user-agencie i omijać blokady IP przez użycie proxy rezydencyjnych lub infrastruktury rozproszonej. Nowe crawlery pojawiają się często bez ostrzeżenia, więc kluczowe jest śledzenie trendów w AI i elastyczne dostosowywanie polityk. Trend wskazuje na dalszy wzrost ruchu crawlerów — Cloudflare raportuje 18% ogólny wzrost ruchu botów od maja 2024 do maja 2025, a tempo to prawdopodobnie się zwiększy wraz z popularyzacją aplikacji AI. Właściciele stron i wydawcy muszą zachować czujność, regularnie przeglądać politykę wobec crawlerów i śledzić nowości, by ich strategie pozostały skuteczne w tym dynamicznym środowisku.
Monitoruj swoją markę w odpowiedziach AI
Zarządzanie dostępem crawlerów do Twojej strony jest ważne, ale równie istotne jest zrozumienie, jak Twoje treści są wykorzystywane i cytowane w odpowiedziach generowanych przez AI. AmICited.com to wyspecjalizowana platforma zaprojektowana do rozwiązywania tego problemu, śledząc, jak crawlery AI zbierają Twoje treści i monitorując, czy Twoja marka i treści są odpowiednio cytowane w aplikacjach opartych na AI. Platforma pozwala dowiedzieć się, które systemy AI korzystają z Twoich treści, jak często Twoje informacje pojawiają się w odpowiedziach AI oraz czy oryginalne źródła są prawidłowo oznaczane. Dla wydawców i twórców treści AmICited.com dostarcza cennych informacji o widoczności w ekosystemie AI, pomagając zmierzyć efekt decyzji o blokowaniu lub dopuszczeniu crawlerów oraz zrozumieć rzeczywistą wartość, jaką otrzymujesz dzięki odkrywaniu treści przez AI. Monitorując cytowania na wielu platformach AI, możesz podejmować bardziej świadome decyzje dotyczące polityki crawlerów, identyfikować szanse na zwiększenie widoczności treści w odpowiedziach AI i upewnić się, że Twoja własność intelektualna jest właściwie przypisywana. Jeśli poważnie podchodzisz do obecności swojej marki w sieci napędzanej AI, AmICited.com zapewnia transparentność i narzędzia monitoringu, których potrzebujesz, by być na bieżąco i chronić wartość swoich treści w nowej erze odkrywania opartego o AI.
Najczęściej zadawane pytania
Jaka jest różnica między crawlerami treningowymi a crawlerami wyszukiwarki?
Crawlery treningowe, takie jak GPTBot i ClaudeBot, zbierają treści w celu tworzenia zbiorów danych do rozwoju dużych modeli językowych, stając się częścią bazy wiedzy AI. Crawlery wyszukiwarki, takie jak OAI-SearchBot i PerplexityBot, indeksują treści na potrzeby wyszukiwania AI i mogą kierować ruch z powrotem do wydawców poprzez cytaty.
Czy powinienem blokować wszystkie crawlery AI czy tylko treningowe?
To zależy od priorytetów Twojego biznesu. Blokowanie crawlerów treningowych chroni Twoje treści przed wykorzystaniem w modelach AI. Blokowanie crawlerów wyszukiwarki może ograniczyć Twoją widoczność w platformach odkrywania treści opartych na AI, takich jak wyszukiwarka ChatGPT czy Perplexity. Wielu wydawców wybiera selektywne blokowanie, które obejmuje crawlery treningowe, pozwalając na dostęp crawlerom wyszukiwarki i cytującym.
Jak zweryfikować, czy dany crawler jest autentyczny, a nie podszywany?
Najbardziej wiarygodną metodą weryfikacji jest sprawdzenie adresu IP żądania względem oficjalnie opublikowanych zakresów IP operatorów crawlerów. Główne firmy, takie jak OpenAI, Anthropic i Amazon, publikują adresy IP swoich crawlerów. Możesz także wykorzystać reguły zapory sieciowej, aby dopuszczać tylko zweryfikowane adresy IP i blokować żądania z niezweryfikowanych źródeł podszywających się pod crawlery AI.
Czy blokowanie Google-Extended wpłynie na moje pozycje w wyszukiwarce?
Google oficjalnie podaje, że blokowanie Google-Extended nie wpływa na pozycje w wyszukiwarce ani na obecność w AI Overviews. Jednak niektórzy webmasterzy zgłaszali obawy, dlatego monitoruj swoje wyniki wyszukiwania po wdrożeniu blokad. AI Overviews w Google Search podlegają standardowym regułom Googlebota, a nie Google-Extended.
Jak często powinienem aktualizować swoją listę blokowanych crawlerów AI?
Nowe crawlery AI pojawiają się regularnie, dlatego przeglądaj i aktualizuj swoją listę blokad co najmniej raz na kwartał. Śledź zasoby takie jak projekt ai.robots.txt na GitHubie dla list tworzonych przez społeczność. Sprawdzaj logi serwera co miesiąc, by zidentyfikować nowe crawlery odwiedzające Twoją stronę, które nie są objęte aktualną konfiguracją.
Czy crawlery AI mogą ignorować dyrektywy robots.txt?
Tak, robots.txt ma charakter doradczy, a nie egzekwowalny. Crawlery renomowanych firm zazwyczaj respektują dyrektywy robots.txt, ale niektóre je ignorują. Dla silniejszej ochrony wdrażaj blokowanie na poziomie serwera poprzez .htaccess lub reguły zapory, a także weryfikuj autentyczność crawlerów na podstawie opublikowanych zakresów adresów IP.
Jaki jest wpływ crawlerów AI na przepustowość mojej strony?
Crawlery AI mogą generować znaczne obciążenie serwera i zużycie przepustowości. Niektóre projekty infrastrukturalne odnotowały, że blokowanie crawlerów AI zmniejszyło zużycie przepustowości z 800 GB do 200 GB dziennie, co pozwoliło zaoszczędzić około 1500 dolarów miesięcznie. Wydawcy o dużym ruchu mogą odczuć realne oszczędności dzięki selektywnemu blokowaniu.
Jak mogę monitorować, które crawlery AI odwiedzają moją stronę?
Sprawdzaj logi serwera (zwykle w /var/log/apache2/access.log na Linuksie) pod kątem ciągów user-agent pasujących do znanych crawlerów. Wykorzystuj platformy analityczne, takie jak Google Analytics lub Cloudflare Radar, aby osobno śledzić ruch botów. Ustaw powiadomienia o nietypowej aktywności crawlerów i przeprowadzaj kwartalne przeglądy polityki wobec crawlerów.
Monitoruj swoją markę w odpowiedziach AI
Śledź, jak platformy AI takie jak ChatGPT, Perplexity i Google AI Overviews odnoszą się do Twoich treści. Otrzymuj powiadomienia w czasie rzeczywistym, gdy Twoja marka zostaje wspomniana w odpowiedziach generowanych przez AI.
Jak zidentyfikować crawlery AI w logach serwera: Kompletny przewodnik po wykrywaniu
Dowiedz się, jak identyfikować i monitorować crawlery AI takie jak GPTBot, PerplexityBot i ClaudeBot w logach serwera. Poznaj ciągi user-agent, metody weryfikac...
Dowiedz się, jak działają AI crawlers takie jak GPTBot i ClaudeBot, czym różnią się od tradycyjnych crawlerów wyszukiwarek oraz jak zoptymalizować swoją stronę ...
Jakim Crawlerom AI Pozwolić na Dostęp? Kompletny Przewodnik na 2025
Dowiedz się, którym crawlerom AI pozwolić, a które zablokować w swoim pliku robots.txt. Kompleksowy przewodnik obejmujący GPTBot, ClaudeBot, PerplexityBot oraz ...
10 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.