
Jak RAG zmienia cytowania AI
Dowiedz się, jak Retrieval-Augmented Generation zmienia cytowania AI, umożliwiając precyzyjne przypisywanie źródeł i ugruntowane odpowiedzi w ChatGPT, Perplexit...
7 min czytania

Dowiedz się, jak uziemienie LLM i wyszukiwanie w sieci umożliwiają systemom AI dostęp do informacji w czasie rzeczywistym, ograniczają halucynacje i zapewniają poprawne cytowania. Poznaj RAG, strategie wdrożeniowe i najlepsze praktyki dla firm.
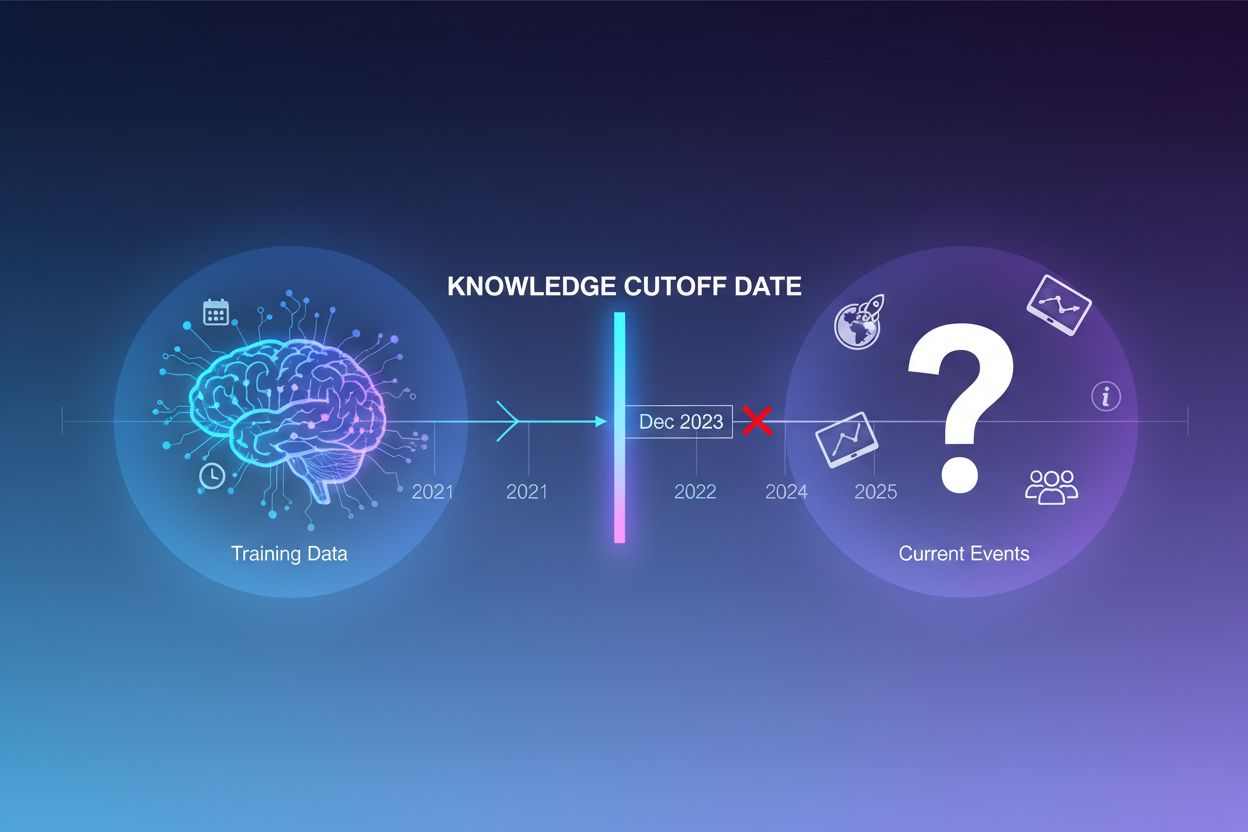
Duże modele językowe są trenowane na ogromnych zbiorach tekstu, jednak proces ten ma istotne ograniczenie: obejmuje wyłącznie informacje dostępne do określonego momentu, zwanego datą odcięcia wiedzy. Na przykład, jeśli LLM był trenowany na danych do grudnia 2023 roku, nie ma on żadnej wiedzy o wydarzeniach, odkryciach czy nowościach, które pojawiły się po tej dacie. Gdy użytkownicy pytają o bieżące wydarzenia, nowe produkty lub pilne wiadomości, model nie ma dostępu do tych informacji w swoich danych treningowych. Zamiast przyznać się do niewiedzy, LLM-y często generują odpowiedzi brzmiące wiarygodnie, lecz niezgodne z faktami—zjawisko to określa się mianem halucynacji. Taka tendencja staje się szczególnie problematyczna w zastosowaniach, gdzie kluczowa jest precyzja, jak obsługa klienta, doradztwo finansowe czy informacje medyczne, gdzie nieaktualne lub zmyślone dane mogą mieć poważne konsekwencje.
Uziemienie to proces wzbogacania wiedzy wytrenowanego LLM o zewnętrzne, kontekstowe informacje w czasie generowania odpowiedzi. Zamiast polegać wyłącznie na wzorcach poznanych podczas treningu, uziemienie łączy model z rzeczywistymi źródłami danych—czy to stronami internetowymi, dokumentami wewnętrznymi, bazami danych, czy API. Koncepcja ta wywodzi się z psychologii poznawczej, w szczególności z teorii uczenia osadzonego w kontekście (situated cognition), która zakłada, że wiedza jest najskuteczniej wykorzystywana, gdy jest osadzona w konkretnym kontekście użycia. W praktyce uziemienie zmienia problem z „wygeneruj odpowiedź z pamięci” na „zsyntetyzuj odpowiedź z dostarczonych informacji”. Według ścisłej definicji z najnowszych badań, LLM powinien wykorzystać całą istotną wiedzę z dostarczonego kontekstu i nie wykraczać poza jego zakres, nie halucynując dodatkowych informacji.
| Aspekt | Odpowiedź nieuziemiona | Odpowiedź uziemiona |
|---|---|---|
| Źródło informacji | Tylko wiedza wytrenowana | Wiedza wytrenowana + dane zewnętrzne |
| Dokładność dla nowych wydarzeń | Niska (ograniczenie datą odcięcia) | Wysoka (dostęp do bieżących danych) |
| Ryzyko halucynacji | Wysokie (model zgaduje) | Niskie (ograniczone kontekstem) |
| Możliwość cytowania | Ograniczona lub brak | Pełna śledzność do źródeł |
| Skalowalność | Stała (rozmiar modelu) | Elastyczna (możliwość dodania nowych źródeł) |
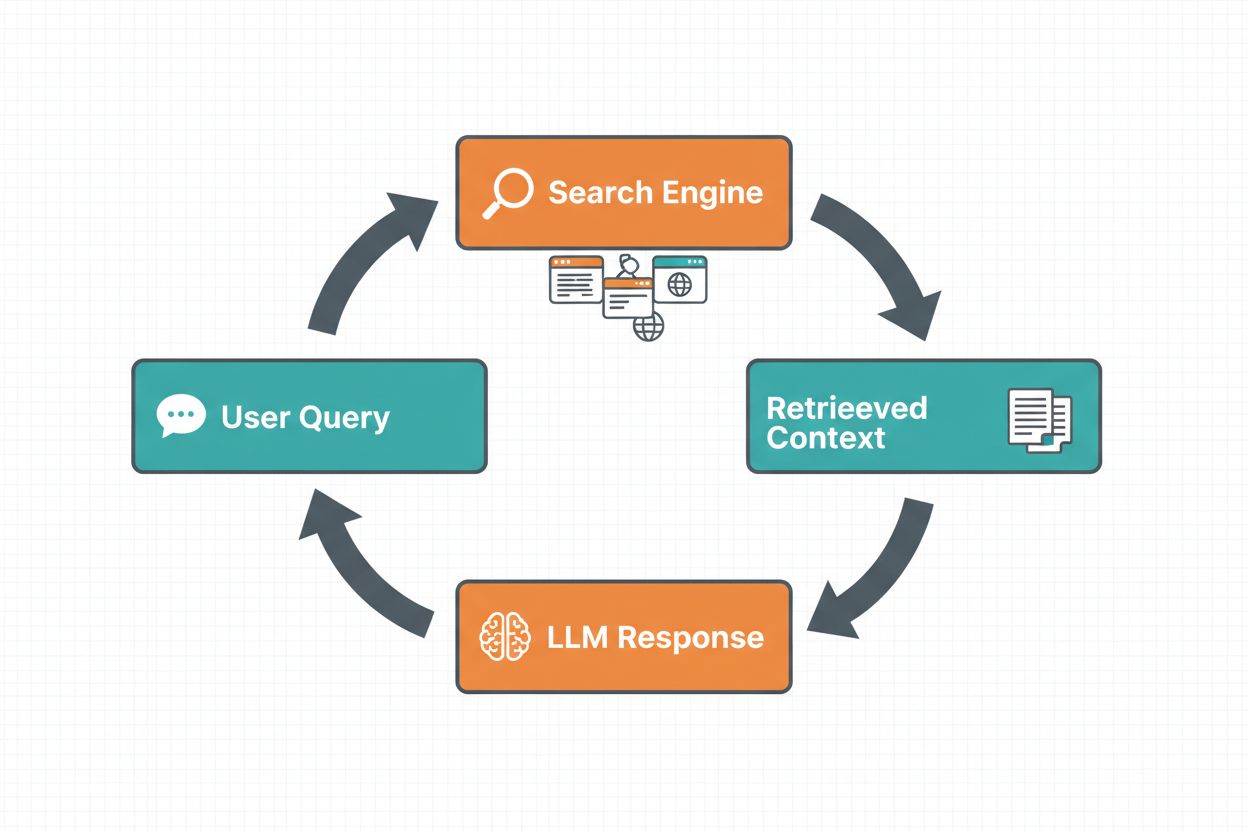
Uziemienie przez wyszukiwanie w sieci pozwala LLM-om uzyskiwać informacje w czasie rzeczywistym poprzez automatyczne przeszukiwanie internetu i włączanie wyników do procesu generowania odpowiedzi. Przepływ pracy obejmuje uporządkowaną sekwencję: najpierw system analizuje prompt użytkownika, by ustalić, czy wyszukiwanie w sieci poprawi odpowiedź; następnie generuje jedno lub więcej zoptymalizowanych zapytań wyszukiwawczych; potem wykonuje zapytania w wyszukiwarce (np. Google Search lub DuckDuckGo); dalej przetwarza wyniki i wydobywa istotne treści; wreszcie przekazuje ten kontekst do LLM jako część promptu, umożliwiając modelowi wygenerowanie uziemionej odpowiedzi. System zwraca również metadane uziemienia—uporządkowane informacje o tym, jakie zapytania zostały wykonane, jakie źródła pobrano i które fragmenty odpowiedzi są przez nie poparte. Te metadane są kluczowe dla budowania zaufania i umożliwienia weryfikacji odpowiedzi przez użytkownika.
Schemat pracy uziemienia przez wyszukiwanie w sieci:
Retrieval Augmented Generation (RAG) to obecnie dominująca technika uziemienia, łącząca dorobek badań nad wyszukiwaniem informacji z nowoczesnymi możliwościami LLM. RAG działa poprzez pobranie najpierw istotnych dokumentów lub fragmentów z zewnętrznego źródła wiedzy (zwykle zaindeksowanego w bazie wektorowej), a następnie przekazuje pobrane elementy jako kontekst do LLM. Proces pobierania zwykle obejmuje dwa etapy: retriever stosuje wydajne algorytmy (np. BM25 lub wyszukiwanie semantyczne na embeddingach), by wyłonić kandydatów, a ranker wykorzystuje bardziej zaawansowane modele neuronowe do ponownego uporządkowania według trafności. Pobrany kontekst trafia do promptu, co pozwala LLM-owi syntetyzować odpowiedzi oparte na autorytatywnych informacjach. RAG oferuje kluczowe przewagi nad dostrajaniem: jest tańszy (brak potrzeby ponownego trenowania), bardziej skalowalny (wystarczy dodać nowe dokumenty do bazy wiedzy) i łatwiejszy w utrzymaniu (aktualizacje bez trenowania). Przykładowy prompt RAG może wyglądać tak:
Użyj poniższych dokumentów, aby odpowiedzieć na pytanie.
[Pytanie]
Jaka jest stolica Kanady?
[Dokument 1]
Ottawa jest stolicą Kanady, położoną w Ontario...
[Dokument 2]
Kanada to kraj w Ameryce Północnej z dziesięcioma prowincjami...
Jedną z największych zalet uziemienia przez wyszukiwanie w sieci jest możliwość włączania bieżących informacji do odpowiedzi generowanych przez LLM. Jest to szczególnie cenne w aplikacjach wymagających aktualnych danych—analiza wiadomości, badania rynku, informacje o wydarzeniach czy dostępności produktów. Poza samym dostępem do świeżych danych, uziemienie zapewnia również cytowania i atrybucję źródeł, co jest kluczowe dla budowania zaufania użytkowników i umożliwienia weryfikacji. Gdy LLM generuje uziemioną odpowiedź, zwraca uporządkowane metadane, które mapują konkretne stwierdzenia do dokumentów źródłowych, umożliwiając cytowanie w stylu “[1] source.com” bezpośrednio w tekście. Funkcjonalność ta jest ściśle powiązana z misją platform takich jak AmICited.com, które monitorują, jak systemy AI odnoszą się do źródeł i cytują je na różnych platformach. Możliwość śledzenia, z jakich źródeł korzysta system AI i jak przypisuje informacje, zyskuje na znaczeniu w monitorowaniu marki, atrybucji treści i odpowiedzialnym wdrażaniu AI.
Halucynacje pojawiają się, ponieważ LLM-y mają za zadanie przewidywać kolejny token na podstawie poprzednich oraz poznanych wzorców, bez wrodzonej świadomości granic własnej wiedzy. Gdy napotkają pytania spoza danych treningowych, generują dalej tekst brzmiący prawdopodobnie, zamiast przyznać się do niepewności. Uziemienie rozwiązuje ten problem, zasadniczo zmieniając zadanie modelu: zamiast generować z pamięci, model syntetyzuje odpowiedź na bazie dostarczonych informacji. Od strony technicznej, gdy do promptu dołączony jest istotny zewnętrzny kontekst, przesuwa to rozkład prawdopodobieństwa tokenów w stronę odpowiedzi opartych na tym kontekście, co czyni halucynacje mniej prawdopodobnymi. Badania pokazują, że uziemienie może ograniczyć halucynacje o 30-50% w zależności od zadania i implementacji. Na przykład, zapytany „Kto wygrał Euro 2024?” bez uziemienia starszy model może podać błędną odpowiedź; z uziemieniem przez wyniki wyszukiwania prawidłowo wskaże Hiszpanię jako zwycięzcę wraz ze szczegółami meczu. Mechanizm ten działa, ponieważ mechanizmy uwagi modelu skupiają się na dostarczonym kontekście zamiast na niepełnych lub sprzecznych wzorcach z treningu.
Wdrożenie uziemienia przez wyszukiwanie w sieci wymaga integracji kilku komponentów: API wyszukiwarki (np. Google Search, DuckDuckGo przez Serp API lub Bing Search), logiki decydującej, kiedy uziemienie jest potrzebne, oraz prompt engineeringu skutecznie włączającego wyniki wyszukiwania. Praktyczna implementacja zwykle zaczyna się od oceny, czy zapytanie użytkownika wymaga aktualnych danych—można to zrobić, pytając samego LLM-a, czy prompt potrzebuje informacji nowszych niż jego knowledge cutoff. Jeśli uziemienie jest konieczne, system wykonuje wyszukiwanie w sieci, przetwarza wyniki, wyodrębniając odpowiednie fragmenty, i buduje prompt zawierający zarówno oryginalne pytanie, jak i kontekst wyszukiwania. Ważnym aspektem są koszty: każde wyszukiwanie to koszt API, więc wdrożenie dynamicznego uziemienia (wyszukiwanie tylko gdy potrzebne) istotnie ogranicza wydatki. Przykładowo, pytanie „Dlaczego niebo jest niebieskie?” raczej nie wymaga wyszukiwania, natomiast „Kto jest obecnym prezydentem?” zdecydowanie tak. Zaawansowane wdrożenia używają mniejszych, szybszych modeli do decyzji o uziemieniu, obniżając opóźnienia i koszty, rezerwując większe modele do generowania finalnej odpowiedzi.
Choć uziemienie jest potężnym narzędziem, wprowadza szereg wyzwań, które trzeba starannie kontrolować. Trafność danych jest kluczowa—jeśli pobrane informacje nie odpowiadają faktycznie na pytanie użytkownika, uziemienie nie pomoże, a może nawet wprowadzić nieistotny kontekst. Ilość danych to paradoks: choć więcej informacji wydaje się korzystne, badania pokazują, że wydajność LLM często spada przy nadmiarze wejścia—zjawisko to określa się jako bias „lost in the middle”, gdzie modele mają trudności z odnalezieniem i użyciem informacji umieszczonych w środku długiego kontekstu. Efektywność tokenowa staje się problemem, bo każdy fragment pobranego kontekstu zużywa tokeny, zwiększając opóźnienia i koszty. Zasadę „mniej znaczy więcej” warto stosować: pobierać tylko top-k najistotniejszych wyników (zwykle 3-5), pracować na mniejszych fragmentach tekstu zamiast całych dokumentów i rozważać ekstrakcję kluczowych zdań z dłuższych ustępów.
| Wyzwanie | Skutek | Rozwiązanie |
|---|---|---|
| Trafność danych | Nieistotny kontekst dezorientuje model | Semantyczne wyszukiwanie + rankery; testowanie jakości pobierania |
| Bias „lost in the middle” | Model pomija istotne info w środku | Minimalizacja wejścia; kluczowe info na początku/końcu |
| Efektywność tokenowa | Wysokie opóźnienia i koszty | Pobierać mniej wyników; używać mniejszych fragmentów |
| Nieaktualne informacje | Przestarzały kontekst w bazie wiedzy | Polityki odświeżania; wersjonowanie |
| Opóźnienia | Wolne odpowiedzi przez wyszukiwanie + inferencję | Operacje asynchroniczne; cache dla popularnych zapytań |
Wdrażanie systemów uziemienia w środowiskach produkcyjnych wymaga szczególnej dbałości o zarządzanie, bezpieczeństwo i kwestie operacyjne. Zapewnienie jakości danych jest podstawą—informacje używane do uziemienia muszą być dokładne, aktualne i istotne dla zastosowania. Kontrola dostępu staje się kluczowa przy uziemieniu na dokumentach zastrzeżonych lub wrażliwych; należy zapewnić, by LLM korzystał tylko z informacji odpowiednich dla danego użytkownika zgodnie z jego uprawnieniami. Zarządzanie aktualizacjami i driftem wymaga określenia polityk częstotliwości odświeżania baz wiedzy i sposobu radzenia sobie ze sprzecznymi informacjami ze źródeł. Logi audytowe są niezbędne dla zgodności i debugowania—warto rejestrować, które dokumenty pobrano, jak je uporządkowano i jaki kontekst przekazano modelowi. Dodatkowo:
Obszar uziemienia LLM dynamicznie rozwija się poza proste pobieranie tekstu. Pojawia się uziemienie multimodalne, gdzie systemy mogą opierać odpowiedzi także na obrazach, wideo czy danych strukturalnych—szczególnie ważne w takich dziedzinach jak analiza dokumentów prawnych, obrazowanie medyczne czy dokumentacja techniczna. Na RAG nakładana jest automatyczna dedukcja, umożliwiająca agentom nie tylko pobieranie informacji, ale i syntezę z wielu źródeł, logiczne wnioskowanie i wyjaśnianie procesu rozumowania. Guardrails są integrowane z uziemieniem, aby mimo dostępu do zewnętrznych danych modele zachowywały bezpieczeństwo i zgodność z politykami. Kolejną ścieżką są aktualizacje modelu na miejscu—zamiast całkowicie polegać na zewnętrznym pobieraniu, badacze szukają sposobów na bezpośrednie aktualizowanie wag modeli nowymi informacjami, co może ograniczyć potrzebę rozbudowanych zewnętrznych baz wiedzy. Te innowacje sugerują, że przyszłe systemy uziemienia będą inteligentniejsze, wydajniejsze i lepiej radzące sobie z złożonym, wieloetapowym rozumowaniem przy zachowaniu dokładności faktograficznej i śledzności.
Uziemienie wzbogaca LLM o zewnętrzne informacje w czasie generowania odpowiedzi bez zmiany samego modelu, podczas gdy dostrajanie polega na ponownym trenowaniu modelu na nowych danych. Uziemienie jest tańsze, szybsze we wdrożeniu i łatwiejsze do aktualizacji wraz z nowymi informacjami. Dostrajanie sprawdza się lepiej, gdy trzeba zasadniczo zmienić sposób działania modelu lub nauczyć go specyficznych wzorców branżowych.
Uziemienie ogranicza halucynacje, dostarczając LLM-owi kontekst faktograficzny zamiast polegania wyłącznie na danych treningowych. Gdy do promptu dołączone są istotne zewnętrzne informacje, rozkład prawdopodobieństwa tokenów przesuwa się w kierunku odpowiedzi opartych na tym kontekście, co zmniejsza prawdopodobieństwo zmyślonych danych. Badania pokazują, że uziemienie może ograniczyć halucynacje nawet o 30-50%.
Retrieval Augmented Generation (RAG) to technika uziemienia, która pobiera istotne dokumenty z zewnętrznego źródła wiedzy i dostarcza je jako kontekst do LLM. RAG jest ważny, ponieważ jest skalowalny, opłacalny i pozwala aktualizować informacje bez ponownego trenowania modelu. Stał się standardem branżowym przy budowie aplikacji AI z uziemieniem.
Wdróż uziemienie oparte na wyszukiwaniu w sieci, gdy Twoja aplikacja potrzebuje dostępu do aktualnych informacji (wiadomości, wydarzenia, najnowsze dane), gdy kluczowa jest dokładność i cytowania lub gdy ograniczeniem jest knowledge cutoff LLM-a. Stosuj dynamiczne uziemienie, aby wyszukiwać tylko w razie potrzeby, ograniczając koszty i opóźnienia dla zapytań, które nie wymagają nowych informacji.
Kluczowe wyzwania to zapewnienie trafności danych (pobrane informacje muszą rzeczywiście odpowiadać na pytanie), zarządzanie ilością danych (więcej nie zawsze znaczy lepiej), radzenie sobie z biasem 'lost in the middle', gdzie modele pomijają informacje w środku długiego kontekstu, oraz optymalizacja efektywności tokenów. Rozwiązania to m.in. semantyczne wyszukiwanie z rankerami, pobieranie mniej, ale bardziej wartościowych wyników oraz umieszczanie kluczowych informacji na początku lub końcu kontekstu.
Uziemienie jest bezpośrednio związane z monitorowaniem odpowiedzi AI, ponieważ umożliwia systemom podawanie cytowań i atrybucji źródeł. Platformy takie jak AmICited śledzą, jak systemy AI odnoszą się do źródeł, co jest możliwe tylko przy poprawnie wdrożonym uziemieniu. Pomaga to zapewnić odpowiedzialne wdrażanie AI i atrybucję marki w różnych ekosystemach AI.
Bias 'lost in the middle' to zjawisko, w którym LLM-y gorzej radzą sobie, gdy istotne informacje znajdują się w środku długiego kontekstu, niż gdy są one na początku lub końcu. Wynika to z tendencji modeli do 'przeglądania' dużych ilości tekstu. Rozwiązaniem jest minimalizacja rozmiaru wejścia, umieszczanie kluczowych informacji w preferowanych miejscach oraz stosowanie mniejszych fragmentów tekstu.
Pod wdrożenie produkcyjne postaw na zapewnienie jakości danych, wdrożenie kontroli dostępu do wrażliwych informacji, ustalenie polityk aktualizacji i odświeżania, włączenie logów audytowych dla zgodności oraz tworzenie pętli feedbacku użytkowników w celu wykrywania błędów. Monitoruj zużycie tokenów dla optymalizacji kosztów, stosuj wersjonowanie baz wiedzy i śledź zachowanie modelu pod kątem dryfu.
AmICited śledzi, jak GPT, Perplexity i Google AI Overviews cytują i odnoszą się do Twoich treści. Uzyskaj wgląd w monitorowanie odpowiedzi AI i atrybucję marki w czasie rzeczywistym.
Dowiedz się, jak Retrieval-Augmented Generation zmienia cytowania AI, umożliwiając precyzyjne przypisywanie źródeł i ugruntowane odpowiedzi w ChatGPT, Perplexit...

Dowiedz się, jak halucynacje AI zagrażają bezpieczeństwu marki w Google AI Overviews, ChatGPT i Perplexity. Poznaj strategie monitorowania, techniki wzmacniania...

Dowiedz się, czym jest halucynacja AI, dlaczego występuje w ChatGPT, Claude i Perplexity oraz jak wykrywać fałszywe informacje generowane przez AI w wynikach wy...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.