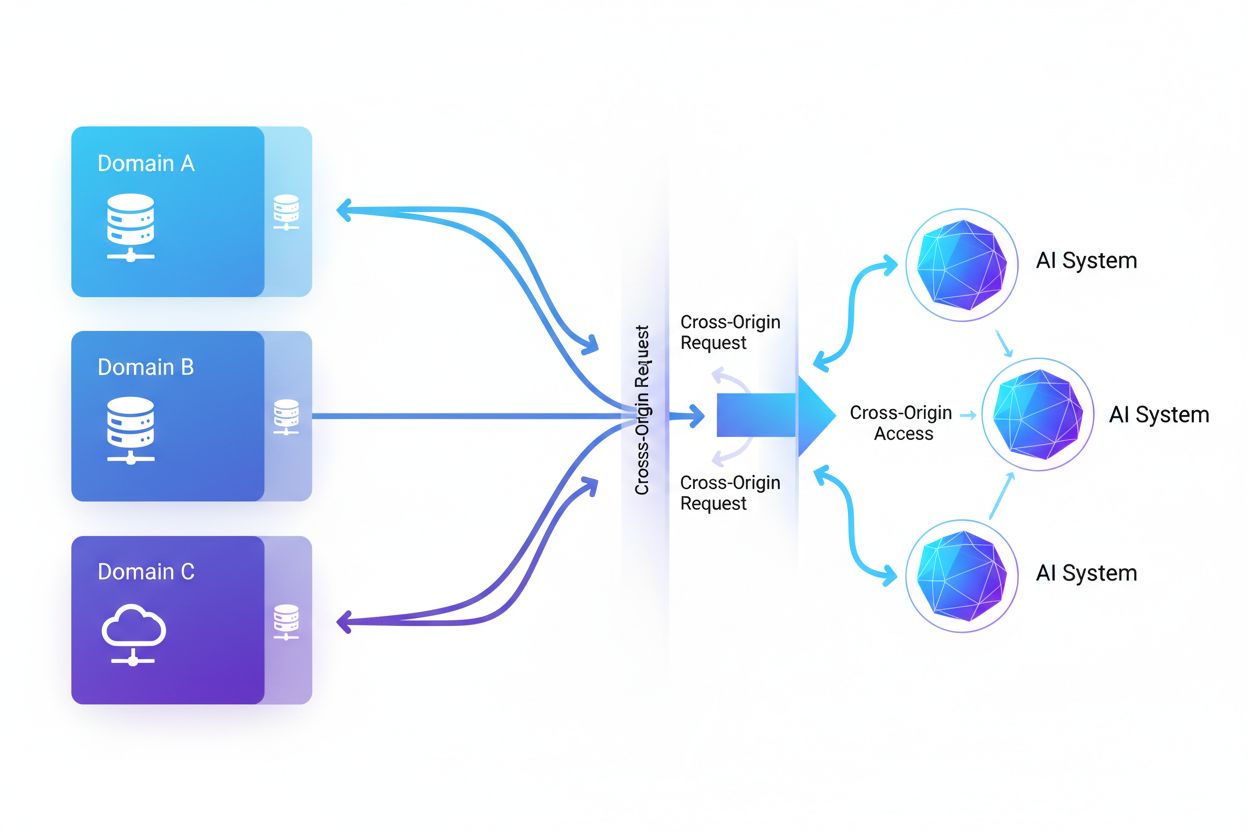
Dostęp AI z innych domen oznacza możliwość żądania i pobierania treści z domen innych niż macierzysta przez systemy sztucznej inteligencji i web crawlery, regulowaną mechanizmami bezpieczeństwa takimi jak CORS. Obejmuje to sposób, w jaki firmy AI skalują zbieranie danych do trenowania dużych modeli językowych, jednocześnie omijając ograniczenia cross-origin. Zrozumienie tego zagadnienia jest kluczowe dla twórców treści i właścicieli stron, aby chronić własność intelektualną i zachować kontrolę nad wykorzystaniem ich treści przez systemy AI. Widoczność aktywności AI z innych domen pomaga odróżnić legalny dostęp AI od nieautoryzowanego scrapingu.
Dostęp AI z innych domen (Cross-Origin AI Access)
Dostęp AI z innych domen oznacza możliwość żądania i pobierania treści z domen innych niż macierzysta przez systemy sztucznej inteligencji i web crawlery, regulowaną mechanizmami bezpieczeństwa takimi jak CORS. Obejmuje to sposób, w jaki firmy AI skalują zbieranie danych do trenowania dużych modeli językowych, jednocześnie omijając ograniczenia cross-origin. Zrozumienie tego zagadnienia jest kluczowe dla twórców treści i właścicieli stron, aby chronić własność intelektualną i zachować kontrolę nad wykorzystaniem ich treści przez systemy AI. Widoczność aktywności AI z innych domen pomaga odróżnić legalny dostęp AI od nieautoryzowanego scrapingu.
Zrozumienie dostępu AI z innych domen
Dostęp AI z innych domen odnosi się do możliwości żądania i pobierania treści z domen innych niż macierzysta przez systemy sztucznej inteligencji oraz web crawlery, regulowanej mechanizmami bezpieczeństwa takimi jak Cross-Origin Resource Sharing (CORS). W miarę jak firmy AI zwiększają skalę zbierania danych do trenowania dużych modeli językowych i innych systemów AI, zrozumienie, jak te systemy obchodzą ograniczenia cross-origin, staje się kluczowe dla twórców treści i właścicieli stron. Wyzwanie polega na odróżnieniu legalnego dostępu AI do indeksowania wyszukiwarek od nieautoryzowanego scrapingu na potrzeby trenowania modeli, co sprawia, że widoczność aktywności AI z innych domen jest niezbędna do ochrony własności intelektualnej i zachowania kontroli nad wykorzystaniem treści.
Mechanizm CORS i crawlery AI
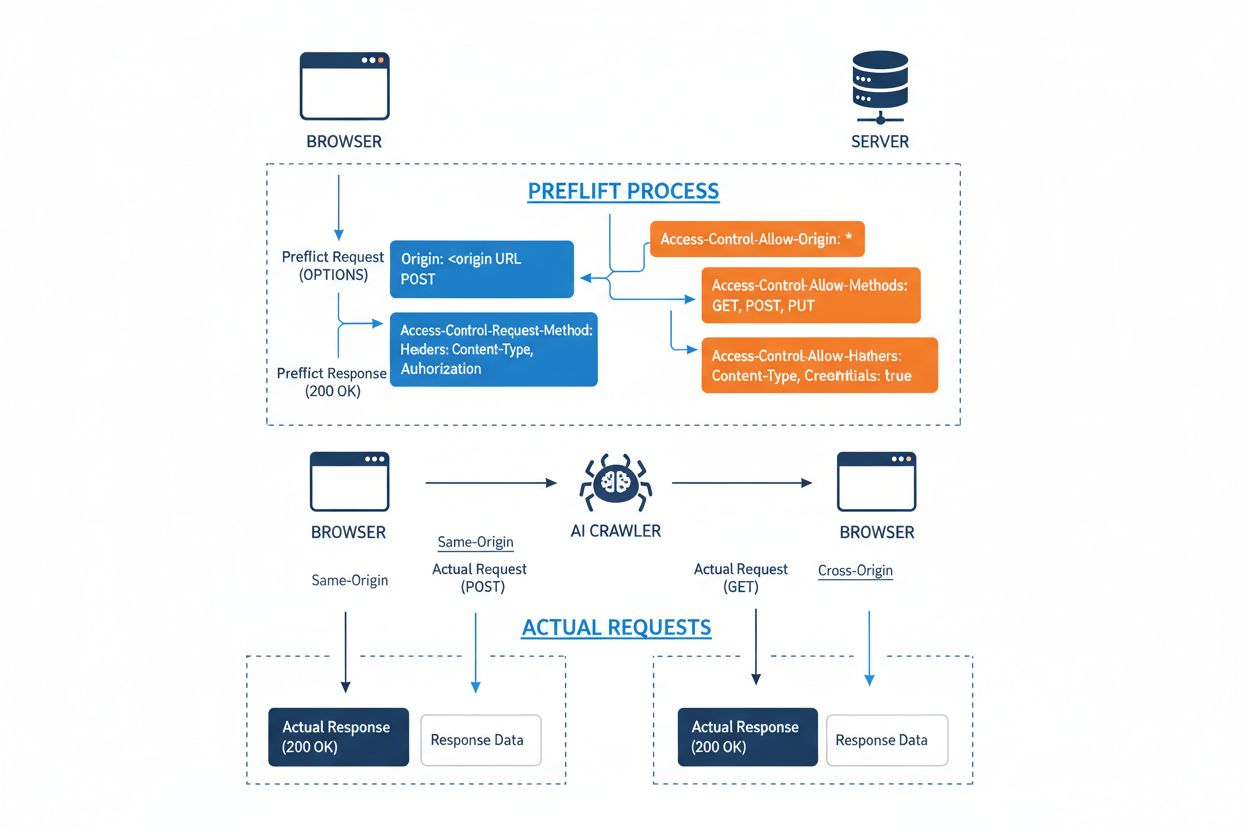
Cross-Origin Resource Sharing (CORS) to mechanizm bezpieczeństwa oparty na nagłówkach HTTP, który pozwala serwerom określić, które źródła (domeny, schematy lub porty) mogą uzyskiwać dostęp do ich zasobów. Gdy crawler AI lub inny klient próbuje uzyskać dostęp do zasobu z innego pochodzenia, przeglądarka lub klient inicjuje zapytanie wstępne (preflight) metodą HTTP OPTIONS, aby sprawdzić, czy serwer zezwala na rzeczywiste żądanie. Serwer odpowiada określonymi nagłówkami CORS, które określają uprawnienia, w tym, które źródła są dozwolone, jakie metody HTTP są dopuszczalne, jakie nagłówki można dołączyć oraz czy takie dane jak ciasteczka lub tokeny uwierzytelniające mogą być przesyłane z żądaniem.
Nagłówek CORS
Cel
Access-Control-Allow-Origin
Określa, które źródła mogą uzyskiwać dostęp do zasobu (* dla wszystkich lub konkretne domeny)
Access-Control-Allow-Methods
Wymienia dopuszczalne metody HTTP (GET, POST, PUT, DELETE itp.)
Access-Control-Allow-Headers
Definiuje, które nagłówki żądania są dozwolone (Authorization, Content-Type itp.)
Access-Control-Allow-Credentials
Określa, czy w żądaniach mogą być przesyłane dane uwierzytelniające (ciasteczka, tokeny)
Access-Control-Max-Age
Określa, jak długo odpowiedzi preflight mogą być cache’owane (w sekundach)
Access-Control-Expose-Headers
Wymienia nagłówki odpowiedzi, do których klient może uzyskać dostęp
Crawlery AI współpracują z CORS, respektując te nagłówki, gdy są one prawidłowo skonfigurowane, jednak wiele zaawansowanych botów próbuje obejść te ograniczenia, podszywając się pod inne user agenty lub korzystając z sieci proxy. Skuteczność CORS jako zabezpieczenia przed nieautoryzowanym dostępem AI zależy całkowicie od poprawnej konfiguracji serwera i od tego, czy crawler respektuje te ograniczenia — co staje się coraz ważniejsze w miarę wzrostu konkurencji firm AI o dane do trenowania.
Krajobraz crawlerów AI uzyskujących dostęp do internetu znacznie się rozszerzył, a kilka głównych graczy dominuje w cross-originowych wzorcach dostępu. Według analizy ruchu sieciowego Cloudflare, najpowszechniejsze crawlery AI to:
Bytespider (ByteDance) – Podobno używany do zbierania danych treningowych dla chińskich modeli AI, w tym Doubao, uzyskuje dostęp do ok. 40% stron w sieci Cloudflare
GPTBot (OpenAI) – Zbiera dane treningowe dla ChatGPT i kolejnych modeli, uzyskując dostęp do ok. 35% stron chronionych przez Cloudflare
ClaudeBot (Anthropic) – Zasila asystenta Claude AI, z gwałtownie rosnącą liczbą zapytań i dostępem do ok. 11% stron
Amazonbot (Amazon) – Indeksuje treści na potrzeby funkcji odpowiadania na pytania Alexa, drugi co do wielkości wolumen zapytań
CCBot (Common Crawl) – Non-profitowy crawler tworzący otwarte zbiory danych, wykorzystywane przez wiele projektów AI, uzyskuje dostęp do ok. 2% stron
Google-Extended (Google) – Oddzielony od standardowego Googlebota, specjalnie indeksuje treści dla Bard i Gemini AI
Perplexity Bot (Perplexity AI) – Zbiera treści na potrzeby wyszukiwarki Perplexity, znany z podszywania się pod inne user agenty w celu ominięcia ograniczeń
Te crawlery generują miliardy zapytań miesięcznie, a niektóre — jak Bytespider i GPTBot — uzyskują dostęp do większości publicznie dostępnych treści w internecie. Skala i agresywność tych działań sprawiła, że główne platformy, w tym Reddit, Twitter/X, Stack Overflow i liczne media, wdrożyły środki blokujące.
Luki bezpieczeństwa i ryzyka
Błędnie skonfigurowane polityki CORS powodują poważne luki bezpieczeństwa, które crawlery AI mogą wykorzystać do uzyskania nieautoryzowanego dostępu do wrażliwych danych. Gdy serwery ustawiają Access-Control-Allow-Origin: * bez właściwej walidacji, nieświadomie pozwalają dowolnemu źródłu — także złośliwym scraperom AI — na dostęp do zasobów, które powinny być ograniczone. Szczególnie niebezpieczna konfiguracja to połączenie Access-Control-Allow-Credentials: true z ustawieniem origin na dziką kartę, bo umożliwia atakującym kradzież danych uwierzytelnionych użytkowników za pomocą cross-originowych żądań z ciasteczkami lub tokenami.
Typowe błędy w konfiguracji CORS to dynamiczne odbijanie nagłówka Origin bez walidacji w odpowiedzi Access-Control-Allow-Origin, co w efekcie pozwala każdemu źródłu na dostęp do zasobu. Zbyt szerokie listy dozwolonych domen, które nie walidują poprawnie granic domeny, mogą zostać wykorzystane przez ataki subdomenowe lub manipulację prefiksem. Dodatkowo wiele organizacji nie waliduje poprawnie samego nagłówka Origin, przez co są podatne na podszywane żądania. Konsekwencje tych podatności wykraczają poza kradzież danych i obejmują nieautoryzowane trenowanie modeli AI na zastrzeżonych treściach, pozyskiwanie informacji konkurencyjnych czy łamanie praw własności intelektualnej — ryzyka, których monitorowaniem i kwantyfikacją zajmują się narzędzia takie jak AmICited.com.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Metody wykrywania dostępu AI z innych domen
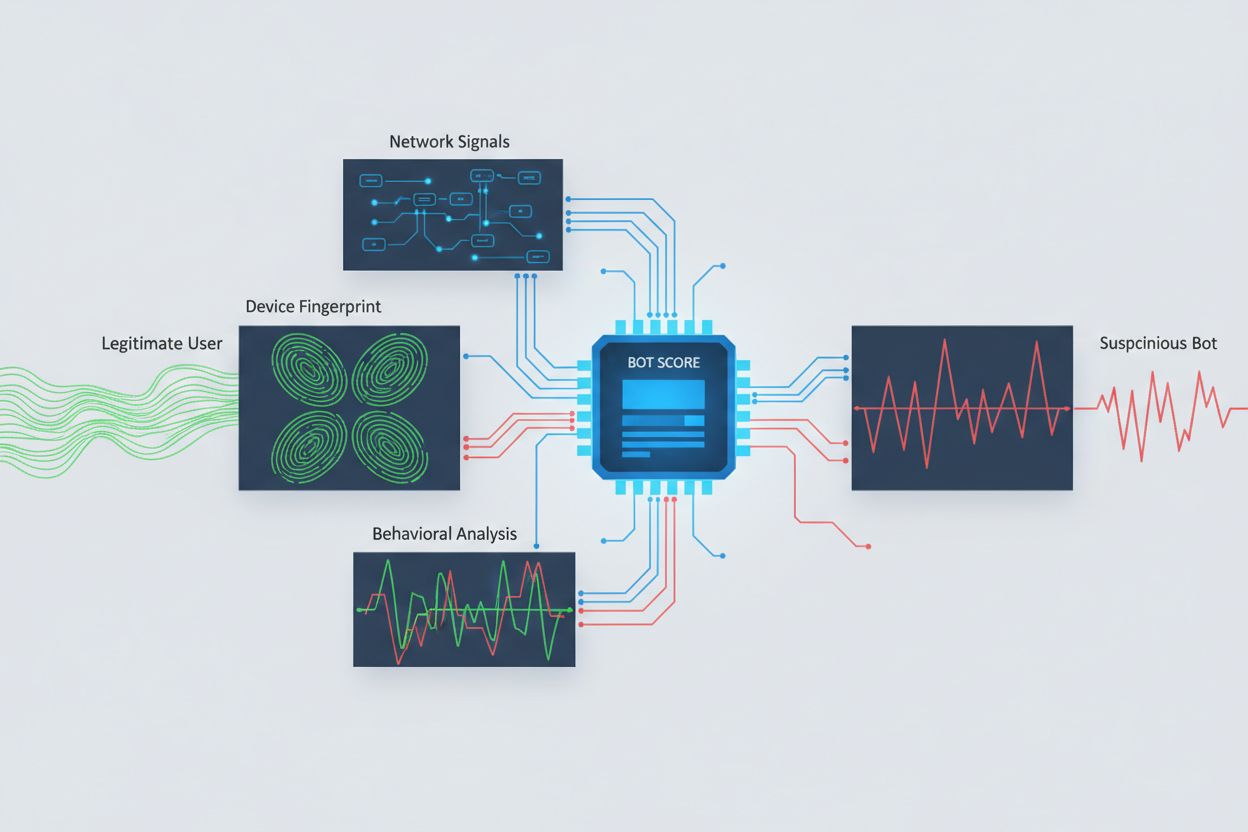
Identyfikacja crawlerów AI próbujących uzyskać dostęp cross-origin wymaga analizy wielu sygnałów wykraczających poza proste ciągi user agent, które są trywialnie podrabiane. Analiza user agentów pozostaje podstawową metodą wykrywania, ponieważ wiele crawlerów AI identyfikuje się ciągami takimi jak “GPTBot/1.0” czy “ClaudeBot/1.0”, choć zaawansowane crawlery celowo maskują tożsamość, udając legalne przeglądarki. Fingerprinting zachowań analizuje sposób składania żądań — bada takie wzorce jak czas wysyłania zapytań, sekwencję odwiedzanych stron, obecność lub brak wykonywania JavaScript oraz schematy interakcji różniące się zasadniczo od ludzkiego przeglądania.
Analiza sygnałów sieciowych pozwala na głębszą detekcję — bada podpisy handshake TLS, reputację IP, wzorce rozwiązywania DNS i charakterystyki połączeń, ujawniające aktywność botów nawet przy podszywanych user agentach. Fingerprinting urządzeń agreguje dziesiątki sygnałów, takich jak wersja przeglądarki, rozdzielczość ekranu, zainstalowane czcionki, szczegóły systemu operacyjnego czy odciski JA3 TLS, tworząc unikalne identyfikatory dla każdego źródła zapytania. Zaawansowane systemy wykrywania mogą rozpoznać, gdy wiele sesji pochodzi z tego samego urządzenia lub skryptu, wykrywając rozproszone próby scrapowania rozłożone na wiele adresów IP. Organizacje mogą wykorzystywać te metody za pośrednictwem platform bezpieczeństwa i usług monitorujących, by zyskać widoczność, które systemy AI mają dostęp do ich treści i jak próbują omijać ograniczenia.
Blokowanie i kontrolowanie dostępu AI
Organizacje stosują wiele uzupełniających się strategii blokowania lub kontrolowania dostępu AI z innych domen, zdając sobie sprawę, że żadna metoda nie daje pełnej ochrony:
Reguły Disallow w robots.txt – Dodanie dyrektyw disallow dla znanych user agentów AI (np. User-agent: GPTBot i Disallow: /) to uprzejmy, ale dobrowolny mechanizm; skuteczny wobec dobrze zachowujących się crawlerów, ale łatwy do zignorowania przez zdeterminowanych scraperów
Filtrowanie user agentów – Konfiguracja serwerów WWW lub firewalli do blokowania lub przekierowywania określonych ciągów user agent; skuteczniejsze niż robots.txt, ale podatne na podszywanie się
Blokowanie adresów IP – Blokowanie zakresów IP powiązanych ze scraperami lub chmurami; skuteczne przy atakach rozproszonych, ale do obejścia przy rotacji proxy i sieciach z adresami rezydencyjnymi
Limity zapytań i throttling – Wprowadzenie limitów liczby zapytań, które spowalniają scraperów; zmniejsza wpływ, ale zaawansowane boty mogą rozkładać zapytania na wiele IP, by pozostać poniżej progów
Honeypoty i tarpit – Tworzenie ukrytych linków lub nieskończonych labiryntów, w które wchodzą tylko boty, marnując ich zasoby; eksperymentalne, ale mogą pogorszyć jakość zbieranych danych
Uwierzytelnianie i paywalle – Wymaganie logowania lub płatności za dostęp do treści; bardzo skuteczne, ale niewygodne dla legalnych użytkowników i nie zawsze możliwe do zastosowania
Zaawansowany fingerprinting urządzeń – Analiza sygnałów behawioralnych i sieciowych do identyfikacji botów niezależnie od podszywania się pod user agenta; najbardziej zaawansowane podejście, ale wymaga integracji z platformami bezpieczeństwa
Najskuteczniejsza obrona łączy wiele warstw, ponieważ zdeterminowani atakujący wykorzystają słabe punkty każdej pojedynczej metody. Organizacje muszą na bieżąco monitorować skuteczność zastosowanych rozwiązań i dostosowywać je do ewolucji technik omijania stosowanych przez crawlery.
Najlepsze praktyki w zarządzaniu dostępem AI z innych domen
Skuteczne zarządzanie dostępem AI z innych domen wymaga kompleksowego, warstwowego podejścia, które równoważy bezpieczeństwo z potrzebami operacyjnymi. Organizacje powinny wdrożyć strategię etapową: zacząć od podstawowych kontroli jak robots.txt i filtrowanie user agentów, a następnie sukcesywnie wdrażać bardziej zaawansowane mechanizmy wykrywania i blokowania, w zależności od zaobserwowanych zagrożeń. Kluczowy jest ciągły monitoring — śledzenie, które systemy AI mają dostęp do treści, jak często składają zapytania i czy respektują ograniczenia, zapewnia widoczność niezbędną do podejmowania świadomych decyzji o politykach dostępu.
Dokumentacja polityk dostępu powinna być jasna i możliwa do egzekwowania, z wyraźnymi warunkami świadczenia usług, zakazującymi nieautoryzowanego scrapingu i określającymi konsekwencje naruszeń. Regularne audyty konfiguracji CORS pomagają wykryć błędy zanim zostaną wykorzystane, a aktualizowana baza znanych agentów user agent i zakresów IP crawlerów AI umożliwia szybką reakcję na nowe zagrożenia. Organizacje powinny również rozważyć biznesowe konsekwencje blokowania AI — niektóre crawlery przynoszą korzyść przez indeksowanie do wyszukiwarek lub legalne partnerstwa, dlatego polityki powinny rozróżniać korzystny i szkodliwy dostęp. Wdrażanie tych praktyk wymaga współpracy zespołów bezpieczeństwa, prawnych i biznesowych, by polityki były zgodne z celami organizacji i regulacjami.
Narzędzia i rozwiązania do zarządzania dostępem AI
Pojawiły się specjalistyczne narzędzia i platformy, które pomagają organizacjom monitorować i kontrolować dostęp AI z innych domen z większą precyzją i widocznością. AmICited.com zapewnia kompleksowy monitoring, jak systemy AI odnoszą się do Twojej marki i uzyskują dostęp do treści w GPT, Perplexity, Google AI Overviews i innych platformach AI, oferując wgląd, które modele AI wykorzystują Twoje treści i jak często Twoja marka pojawia się w odpowiedziach generowanych przez AI. Ta funkcjonalność obejmuje także śledzenie wzorców dostępu cross-origin oraz rozumienie szerszego ekosystemu systemów AI wchodzących w interakcje z Twoimi zasobami cyfrowymi.
Poza monitoringiem, Cloudflare oferuje funkcje zarządzania botami z możliwością blokowania znanych crawlerów AI jednym kliknięciem, wykorzystując modele uczenia maszynowego trenowane na danych z całej sieci do wykrywania botów nawet przy podszywaniu się pod user agentów. AWS WAF (Web Application Firewall) umożliwia konfigurowanie reguł blokowania określonych user agentów i zakresów IP, a Imperva oferuje zaawansowane wykrywanie botów łączące analizę behawioralną z wywiadem o zagrożeniach. Bright Data specjalizuje się w analizie wzorców ruchu botów i pomaga organizacjom rozróżniać różne typy crawlerów. Wybór narzędzi zależy od wielkości organizacji, poziomu zaawansowania technicznego i konkretnych wymagań — od prostego zarządzania robots.txt dla małych stron po platformy klasy enterprise do zarządzania botami w dużych organizacjach przetwarzających wrażliwe dane. Niezależnie od wyboru narzędzi, podstawowa zasada pozostaje niezmienna: widoczność dostępu AI z innych domen to fundament skutecznej kontroli i ochrony zasobów cyfrowych.
Najczęściej zadawane pytania
Jaka jest różnica między CORS a dostępem AI z innych domen?
CORS (Cross-Origin Resource Sharing) to mechanizm bezpieczeństwa, który kontroluje, które źródła mogą uzyskiwać dostęp do zasobów na serwerze. Dostęp AI z innych domen odnosi się konkretnie do tego, jak systemy AI i crawlery współdziałają z CORS, aby żądać treści z różnych domen. Podczas gdy CORS to techniczne ramy, dostęp AI z innych domen opisuje praktyczne wyzwanie zarządzania zachowaniem crawlerów AI w tych ramach, w tym wykrywanie i blokowanie nieautoryzowanego dostępu AI.
Jak crawlery AI identyfikują się podczas uzyskiwania dostępu do treści?
Większość dobrze zachowujących się crawlerów AI identyfikuje się poprzez określone ciągi user agent, takie jak 'GPTBot/1.0' czy 'ClaudeBot/1.0', jasno wskazujące ich przeznaczenie. Jednak wiele zaawansowanych crawlerów celowo podszywa się pod agentów użytkownika, udając legalne przeglądarki, takie jak Chrome czy Safari, aby obejść blokowanie oparte na user agentach. Dlatego do identyfikacji botów, niezależnie od deklarowanej tożsamości, konieczne są zaawansowane metody wykrywania, takie jak fingerprinting zachowań czy analiza sygnałów sieciowych.
Czy robots.txt skutecznie blokuje crawlery AI?
robots.txt zapewnia dobrowolny mechanizm sugerowania crawlerom, by respektowały ograniczenia dostępu, a dobrze zachowujące się crawlery AI, takie jak GPTBot, zazwyczaj przestrzegają tych zaleceń. Jednak robots.txt nie jest egzekwowalny — zdeterminowani scraperzy mogą go po prostu zignorować. Wiele firm AI zostało przyłapanych na obchodzeniu ograniczeń robots.txt, czyniąc z niego środek konieczny, ale niewystarczający, który powinien być łączony z technicznymi metodami blokowania, takimi jak filtrowanie user agentów, limity zapytań i fingerprinting urządzeń.
Jakie są główne zagrożenia wynikające z błędnej konfiguracji CORS dla dostępu AI?
Błędnie skonfigurowane polityki CORS mogą umożliwić nieautoryzowanym crawlerom AI dostęp do wrażliwych danych, kradzież uwierzytelnionych informacji użytkowników poprzez żądania z uprawnieniami oraz scrapowanie zastrzeżonych treści do nieautoryzowanego trenowania modeli AI. Najgroźniejsze konfiguracje łączą ustawienia z dziką kartą origin z uprawnieniami do uwierzytelniania, co w praktyce pozwala każdemu originowi na dostęp do chronionych zasobów. Takie błędy mogą prowadzić do kradzieży własności intelektualnej, pozyskiwania wywiadu konkurencyjnego oraz łamania umów licencyjnych dotyczących treści.
Jak mogę wykryć, czy systemy AI uzyskują dostęp do moich treści?
Wykrywanie wymaga analizy wielu sygnałów wykraczających poza ciągi user agent. Możesz sprawdzać logi serwera pod kątem znanych user agentów crawlerów AI, wdrożyć fingerprinting zachowań w celu identyfikacji botów po wzorcach interakcji, analizować sygnały sieciowe, takie jak handshake TLS i wzorce DNS, oraz używać fingerprintingu urządzeń do identyfikacji rozproszonych prób scrapowania. Narzędzia takie jak AmICited.com zapewniają kompleksowy monitoring, jak systemy AI odnoszą się do Twojej marki, a platformy takie jak Cloudflare oferują wykrywanie botów oparte na uczeniu maszynowym, rozpoznające nawet podszywane crawlery.
Jaki jest najskuteczniejszy sposób blokowania niechcianych crawlerów AI?
Nie istnieje pojedyncza metoda zapewniająca pełną ochronę, dlatego najskuteczniejsze jest podejście warstwowe. Zacznij od robots.txt i filtrowania user agentów jako podstawowej obrony, dodaj limity zapytań dla ograniczenia wpływu, wdrażaj fingerprinting urządzeń dla wykrycia zaawansowanych botów oraz rozważ uwierzytelnianie lub paywalle dla wrażliwych treści. Najskuteczniejsze organizacje łączą wiele technik i na bieżąco monitorują ich skuteczność, adaptując się do ewolucji technik omijania stosowanych przez crawlery.
Czy wszystkie firmy AI respektują ograniczenia dostępu cross-origin?
Nie. Chociaż duże firmy, takie jak OpenAI i Anthropic deklarują przestrzeganie robots.txt i ograniczeń CORS, dochodzenia wykazały, że wiele crawlerów AI obchodzi te ograniczenia. Perplexity AI została przyłapana na podszywaniu się pod inne user agenty, a badania pokazują, że crawlery OpenAI i Anthropic uzyskiwały dostęp do treści mimo wyraźnych zakazów w robots.txt. Ta niekonsekwencja sprawia, że coraz bardziej potrzebne są techniczne metody blokowania i egzekwowanie prawa.
Jak AmICited.com pomaga monitorować dostęp AI do moich treści?
AmICited.com zapewnia kompleksowy monitoring, jak systemy AI odnoszą się do Twojej marki i uzyskują dostęp do Twoich treści w GPT, Perplexity, Google AI Overviews i innych platformach AI. Śledzi, które modele AI wykorzystują Twoje treści, jak często Twoja marka pojawia się w odpowiedziach generowanych przez AI, oraz zapewnia wgląd w szerszy ekosystem systemów AI wchodzących w interakcje z Twoimi zasobami cyfrowymi. Taki monitoring pozwala zrozumieć skalę dostępu AI i podejmować świadome decyzje dotyczące strategii ochrony treści.
Monitoruj, jak systemy AI uzyskują dostęp do Twoich treści
Uzyskaj pełną widoczność, które systemy AI mają dostęp do Twojej marki w GPT, Perplexity, Google AI Overviews i innych platformach. Śledź wzorce dostępu AI z innych domen i dowiedz się, jak Twoje treści są wykorzystywane do trenowania i działania AI.
Czy AI Może Uzyskiwać Dostęp do Treści Chronionych? Metody i Implikacje
Dowiedz się, jak systemy AI uzyskują dostęp do treści za paywallem i chronionych, jakich technik używają i jak zabezpieczyć swoje treści przy jednoczesnym zacho...
Dowiedz się, jak systemy AI decydują, czy cytować wiele źródeł, czy koncentrować się na tych autorytatywnych. Poznaj wzorce cytowańw ChatGPT, Google AI Overvie...
Czy Domain Authority wpływa na wyszukiwarki AI i silniki odpowiedzi?
Dowiedz się, jak tradycyjny domain authority wpływa na wyszukiwarki AI, takie jak ChatGPT, Perplexity i Google AI Overviews. Odkryj, co naprawdę decyduje o wido...
9 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.