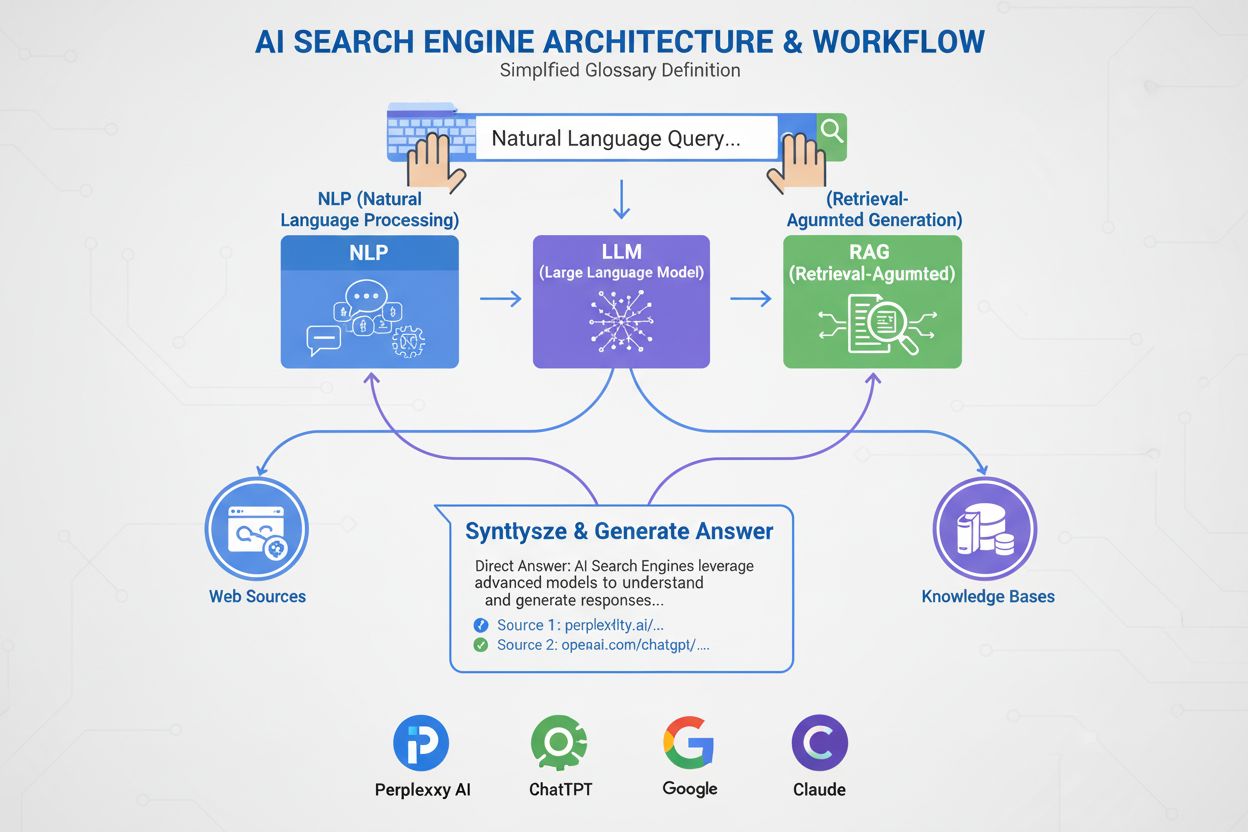
Wyszukiwarka AI
Dowiedz się, czym są wyszukiwarki AI, czym różnią się od tradycyjnych wyszukiwarek oraz jaki mają wpływ na widoczność marki. Poznaj platformy takie jak Perplexi...
11 min czytania
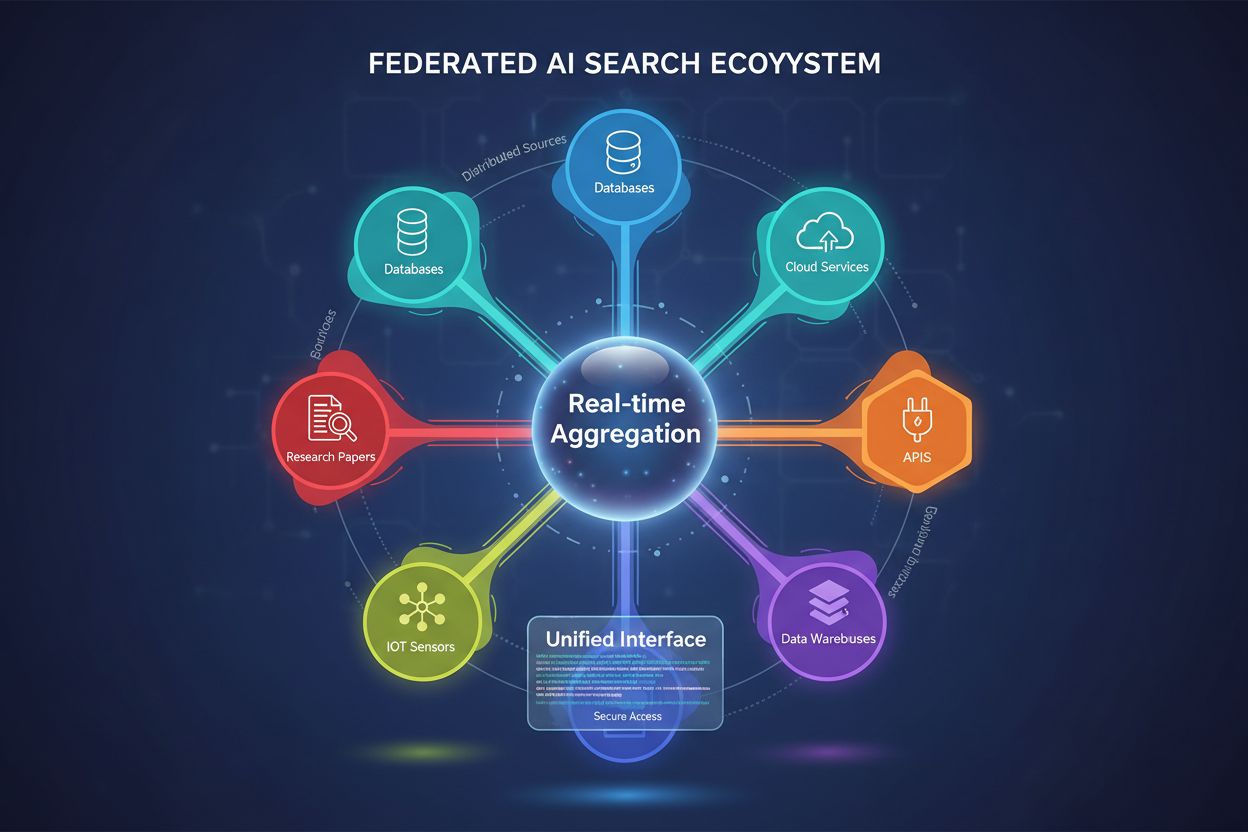
Federacyjna Wyszukiwarka AI to system, który jednocześnie przeszukuje wiele niezależnych źródeł danych za pomocą pojedynczego zapytania i agreguje wyniki w czasie rzeczywistym bez przenoszenia lub duplikowania danych. Umożliwia organizacjom dostęp do rozproszonej informacji w różnych bazach danych, API i usługach chmurowych, zachowując bezpieczeństwo i zgodność danych. W przeciwieństwie do tradycyjnych scentralizowanych wyszukiwarek, systemy federacyjne zachowują autonomię źródeł danych, zapewniając jednocześnie zintegrowane odkrywanie informacji. To podejście jest szczególnie cenne dla firm zarządzających różnorodnymi źródłami danych w różnych działach, lokalizacjach lub organizacjach.
Federacyjna Wyszukiwarka AI to system, który jednocześnie przeszukuje wiele niezależnych źródeł danych za pomocą pojedynczego zapytania i agreguje wyniki w czasie rzeczywistym bez przenoszenia lub duplikowania danych. Umożliwia organizacjom dostęp do rozproszonej informacji w różnych bazach danych, API i usługach chmurowych, zachowując bezpieczeństwo i zgodność danych. W przeciwieństwie do tradycyjnych scentralizowanych wyszukiwarek, systemy federacyjne zachowują autonomię źródeł danych, zapewniając jednocześnie zintegrowane odkrywanie informacji. To podejście jest szczególnie cenne dla firm zarządzających różnorodnymi źródłami danych w różnych działach, lokalizacjach lub organizacjach.
Federacyjna Wyszukiwarka AI to rozproszony system wyszukiwania informacji, który jednocześnie przeszukuje wiele heterogenicznych źródeł danych i inteligentnie agreguje wyniki z wykorzystaniem technik sztucznej inteligencji. W przeciwieństwie do tradycyjnych scentralizowanych wyszukiwarek, które utrzymują jeden zindeksowany zbiór danych, federacyjna wyszukiwarka AI działa w zdecentralizowanych sieciach niezależnych baz danych, baz wiedzy i systemów informacyjnych – bez konieczności konsolidowania danych czy centralnego indeksowania.
Podstawową zasadą federacyjnej wyszukiwarki AI jest źródło-agnostyczne wyszukiwanie, w którym pojedyncze zapytanie użytkownika jest inteligentnie kierowane do odpowiednich źródeł, przetwarzane niezależnie przez każde z nich, a następnie syntetyzowane do zintegrowanego zestawu wyników. Takie podejście zachowuje autonomię danych, umożliwiając jednocześnie pełne odkrywanie informacji ponad granicami organizacyjnymi i technologicznymi.
Do najważniejszych cech systemów federacyjnego wyszukiwania AI należą:
Architektura rozproszona: Dane pozostają w oryginalnych lokalizacjach w wielu repozytoriach, eliminując potrzebę migracji lub scentralizowanego przechowywania. Każde źródło samodzielnie zarządza indeksowaniem, kontrolą dostępu i mechanizmami aktualizacji.
Inteligentne kierowanie zapytań: Algorytmy AI analizują trafiające zapytania, aby określić, które źródła najprawdopodobniej zawierają istotne informacje, optymalizując efektywność wyszukiwania i ograniczając zbędne zapytania do nieistotnych baz.
Agregacja i ranking wyników: Modele uczenia maszynowego syntetyzują wyniki z wielu źródeł, stosując zaawansowane algorytmy rankingowe uwzględniające wiarygodność źródła, trafność, świeżość i kontekst użytkownika.
Obsługa heterogenicznych źródeł: Systemy federacyjne obsługują różnorodne formaty danych, schematy, języki zapytań i protokoły dostępu – w tym bazy relacyjne, repozytoria dokumentów, grafy wiedzy, API i niestrukturalne zbiory tekstowe.
Integracja w czasie rzeczywistym: W przeciwieństwie do podejść hurtowni danych opartych na wsadowym przetwarzaniu, federacyjne wyszukiwanie zapewnia niemal natychmiastowy dostęp do aktualnych danych we wszystkich podłączonych źródłach.
Rozumienie semantyczne: Nowoczesne federacyjne wyszukiwarki AI wykorzystują przetwarzanie języka naturalnego i analizę semantyczną, by zrozumieć intencję zapytania wykraczającą poza dopasowanie słów kluczowych, co umożliwia trafniejsze wybory źródeł i interpretację wyników.
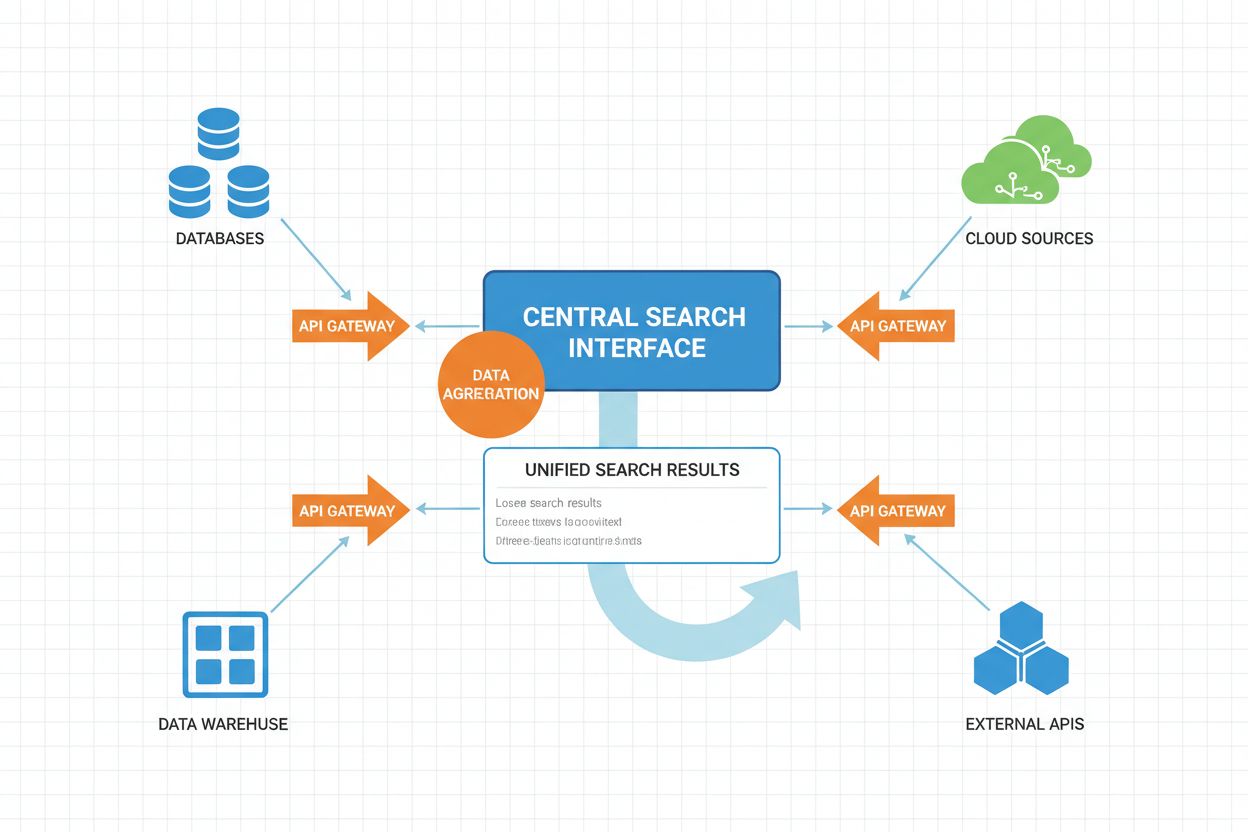
Proces działania federacyjnej wyszukiwarki AI obejmuje wiele skoordynowanych etapów, z których każdy jest wspomagany przez sztuczną inteligencję w celu optymalizacji wydajności i jakości wyników.
| Etap | Proces | Komponent AI | Wyjście |
|---|---|---|---|
| Analiza zapytania | Zapytanie użytkownika jest parsowane i analizowane pod kątem intencji, encji i kontekstu | NLP, rozpoznawanie nazwanych encji, klasyfikacja intencji | Ustrukturyzowana reprezentacja zapytania, zidentyfikowane encje, sygnały intencji |
| Wybór źródeł | System określa, które źródła są najistotniejsze dla zapytania | Modele rankingowe ML, klasyfikatory trafności źródeł | Priorytetowa lista źródeł, wskaźniki pewności |
| Tłumaczenie zapytania | Zapytanie tłumaczone jest na formaty i języki specyficzne dla źródeł | Mapowanie schematów, modele tłumaczenia zapytań, dopasowanie semantyczne | Zapytania specyficzne dla źródeł (SQL, SPARQL, wywołania API itp.) |
| Wykonanie rozproszone | Zapytania wykonywane są równolegle w wybranych źródłach | Równoważenie obciążenia, zarządzanie timeoutami, przetwarzanie równoległe | Surowe wyniki z każdego źródła, metadane wykonania |
| Normalizacja wyników | Wyniki z różnych źródeł są konwertowane do wspólnego formatu | Wyrównanie schematów, konwersja typów danych, standaryzacja formatów | Znormalizowany zbiór wyników o spójnej strukturze |
| Wzbogacenie semantyczne | Wyniki są wzbogacane o dodatkowy kontekst i metadane | Linkowanie encji, tagowanie semantyczne, integracja grafu wiedzy | Wzbogacone wyniki z adnotacjami semantycznymi |
| Ranking i deduplikacja | Wyniki są sortowane według trafności, usuwane są duplikaty | Modele learning-to-rank, wykrywanie podobieństw, scoring trafności | Odsiane, posortowane wyniki |
| Personalizacja | Wyniki są dostosowywane do profilu i preferencji użytkownika | Filtrowanie kolaboracyjne, modelowanie użytkownika, świadomość kontekstu | Personalizowana kolejność wyników |
| Prezentacja | Wyniki są formatowane do prezentacji użytkownikowi | Generowanie języka naturalnego, podsumowanie wyników | Prezentacja wyników dla użytkownika |
Proces ten opiera się na wykonaniu równoległym – wiele źródeł jest przeszukiwanych jednocześnie, a nie sekwencyjnie. To drastycznie redukuje całkowite opóźnienie zapytania pomimo narzutu związanego z koordynacją. Zaawansowane systemy federacyjne wdrażają adaptacyjne planowanie zapytań, ucząc się na podstawie historii zapytań, by optymalizować wybór źródeł i strategię wykonania.
Mechanizmy timeoutów i awaryjne są kluczowe dla niezawodności – gdy któreś ze źródeł odpowiada wolno lub nie działa, system może czekać adaptacyjnie lub kontynuować z dostępnymi wynikami, pogarszając kompletność, ale nie powodując całkowitej porażki zapytania.
Systemy federacyjnego wyszukiwania AI można sklasyfikować według różnych kryteriów:
Według modelu architektury:
Według typu źródła danych:
Według zakresu i skali:
Według poziomu inteligencji:
Autonomia i zarządzanie danymi: Organizacje zachowują kontrolę nad swoimi danymi, eliminując potrzebę przesyłania wrażliwych informacji do centralnych repozytoriów. Pozwala to respektować polityki zarządzania, wymogi zgodności i kontrole bezpieczeństwa na poziomie źródła.
Skalowalność bez konsolidacji: Systemy federacyjne skalują się przez dodawanie nowych źródeł bez migracji danych czy przebudowy hurtowni – umożliwia to stopniową integrację nowych źródeł wraz z rozwojem biznesu.
Dostęp do informacji w czasie rzeczywistym: Bezpośrednie zapytania do źródeł zapewniają aktualność danych bez opóźnień typowych dla hurtowni danych.
Efektywność kosztowa: Eliminacja kosztów budowy i utrzymania scentralizowanych hurtowni danych – brak duplikowania danych, redundantnego przechowywania i złożonych procesów ETL.
Redukcja redundancji danych: W przeciwieństwie do hurtowni, federacyjne wyszukiwanie utrzymuje pojedyncze źródła prawdy, redukując koszty przechowywania i zapewniając spójność.
Elastyczność i adaptacyjność: Nowe źródła można integrować bez modyfikacji istniejącej infrastruktury czy przeindeksowania repozytoriów.
Poprawa jakości danych: Bezpośrednie zapytania do źródeł autorytatywnych ograniczają problemy ze starymi lub niespójnymi danymi wynikłymi z okresowej synchronizacji hurtowni.
Zwiększone bezpieczeństwo: Wrażliwe dane nigdy nie opuszczają oryginalnej lokalizacji, co ogranicza ryzyko wycieku i nieautoryzowanego dostępu.
Obsługa heterogenicznych źródeł: Systemy federacyjne obsługują technologie, formaty i protokoły bez wymogu standaryzacji lub migracji.
Inteligentna synteza wyników: Ranking i agregacja wspierana AI daje wyższą jakość wyników niż proste łączenie, biorąc pod uwagę wiarygodność źródeł, trafność i kontekst użytkownika.
Nowoczesne federacyjne wyszukiwarki AI składają się z szeregu powiązanych komponentów technicznych, współpracujących w celu zapewnienia zintegrowanych możliwości wyszukiwania.
Silnik przetwarzania zapytań: Centralny komponent odbierający zapytania użytkownika i orkiestrujący cały federacyjny workflow. Zawiera moduły parsowania, analizy semantycznej i rozpoznawania intencji. Zaawansowane rozwiązania wykorzystują modele językowe transformerowe do zrozumienia złożonych zapytań i ukrytych intencji.
Rejestr źródeł i zarządzanie metadanymi: Utrzymuje metadane o dostępnych źródłach: schematy, charakterystyka treści, częstotliwość aktualizacji, dostępność i metryki wydajności. Umożliwia to inteligentny wybór źródeł oraz optymalizację zapytań. Modele ML analizują historyczne wzorce zapytań, by przewidywać trafność źródeł.
Inteligentny moduł wyboru źródeł: Klasyfikatory ML określają, które źródła najpewniej zawierają istotne informacje dla danego zapytania. Uwzględniają zasięg treści, skuteczność historyczną, dostępność i szacowany czas odpowiedzi. Zaawansowane systemy stosują uczenie przez wzmacnianie do ciągłej optymalizacji.
Warstwa tłumaczenia i adaptacji zapytań: Przekształca zapytania użytkownika na formaty i języki specyficzne dla źródeł (SQL, SPARQL, REST API, język naturalny dla niestrukturalnych systemów). Mapowanie semantyczne dba o zachowanie intencji zapytania.
Koordynator wykonania rozproszonego: Zarządza równoległym wykonaniem zapytań, timeoutami, równoważeniem obciążenia i odzyskiwaniem po błędach. Implementuje adaptacyjne strategie timeoutów w zależności od obciążenia i wzorców odpowiedzi.
Silnik normalizacji wyników: Konwertuje wyniki z różnych źródeł do wspólnego formatu, w tym wyrównanie schematów, konwersję typów i standaryzację. Obsługuje brakujące pola, konflikty typów i różnice strukturalne.
Moduł wzbogacenia semantycznego: Dodaje kontekst i informacje semantyczne – linkowanie encji do baz wiedzy, tagowanie semantyczne, wydobywanie relacji z tekstów. Podnosi to trafność rankingu i zrozumiałość wyników.
Model rankingowy Learning-to-Rank: Model ML uczony na historycznych parach zapytań i wyników, przewidujący trafność. Uwzględnia setki cech: wiarygodność źródła, świeżość treści, dopasowanie do profilu użytkownika, semantyczne podobieństwo.
Silnik deduplikacji: Wykrywa i usuwa duplikaty oraz bliskie duplikaty z różnych źródeł, stosując metryki podobieństwa (dopasowanie dokładne, rozmyte, semantyczne).
Silnik personalizacji: Dostosowuje kolejność wyników na podstawie profilu użytkownika, preferencji i kontekstu – wykorzystuje filtrowanie kolaboracyjne i rekomendacje treści.
Warstwa buforowania i optymalizacji: Inteligentne strategie buforowania ograniczające zbędne zapytania – cache wyników, metadanych źródeł, wzorców zapytań.
Moduł monitoringu i analityki: Śledzi wydajność systemu, niezawodność źródeł, wzorce zapytań i jakość wyników. Dane te zasilają optymalizację systemu.
Ochrona zdrowia i badania medyczne: Integracja dokumentacji pacjentów, baz badawczych, rejestrów badań klinicznych i literatury medycznej. Lekarze mogą przeszukiwać historię pacjentów w wielu placówkach bez centralizacji danych, a naukowcy mają dostęp do rozproszonych danych klinicznych w zgodzie z RODO/HIPAA.
Usługi finansowe: Banki i firmy inwestycyjne przeszukują dane transakcyjne, informacje rynkowe, bazy regulacyjne i wewnętrzne rejestry równocześnie. Umożliwia to ocenę ryzyka, monitoring zgodności i analizę rynków w czasie rzeczywistym bez konsolidacji wrażliwych danych.
Prawo i zgodność: Kancelarie i działy prawne przeszukują bazy orzecznictwa, rejestry regulacyjne, systemy dokumentacji i bazy umów. Pozwala to na kompleksowe badania prawne z zachowaniem poufności.
E-commerce i handel detaliczny: Integracja katalogów produktów z wielu magazynów, systemów dostawców i platform marketplace. Zapewnia zintegrowane wyszukiwanie produktów przy zachowaniu niezależnych systemów magazynowych i polityk cenowych.
Administracja publiczna: Przeszukiwanie rozproszonych baz – danych spisowych, podatkowych, ewidencji pozwoleń i rejestrów publicznych bez centralizacji wrażliwych informacji obywateli.
Przemysł i łańcuch dostaw: Integracja baz dostawców, systemów magazynowych, rejestrów produkcji i logistyki. Zapewnia widoczność łańcucha dostaw przy zachowaniu autonomii partnerów.
Edukacja i nauka: Uczelnie przeszukują repozytoria instytucjonalne, biblioteki, bazy badawcze i publikacje open-access. Pozwala to na pełne odkrywanie naukowe przy zachowaniu autonomii instytucji i praw własności intelektualnej.
Telekomunikacja: Operatorzy przeszukują bazy klientów, rejestry infrastruktury, systemy bilingowe i katalogi usług – zintegrowana obsługa klienta przy zachowaniu rozdzielności systemów.
Energetyka i usługi użyteczności publicznej: Przeszukiwanie danych z elektrowni, sieci dystrybucji, baz klientów i systemów zgodności regulacyjnej. Zapewnia widoczność operacyjną przy zachowaniu autonomii regionalnych operatorów.
Media i wydawnictwa: Przeszukiwanie repozytoriów treści, archiwów, systemów zarządzania prawami i platform dystrybucyjnych. Pozwala na pełne odkrywanie treści z zachowaniem własności i licencji.
Heterogeniczność źródeł i złożoność integracji: Integracja różnorodnych źródeł o różnych schematach, językach zapytań i protokołach wymaga znacznego nakładu inżynierskiego. Mapowanie schematów i wyrównanie semantyczne są szczególnie trudne przy różnych reprezentacjach tych samych pojęć.
Opóźnienia zapytań i wydajność: Federacyjne wyszukiwanie oznacza konieczność zapytań do wielu źródeł, co generuje opóźnienia. Wolne lub niedostępne źródła mogą pogarszać wydajność. Zarządzanie timeoutami wymaga precyzyjnej kalibracji.
Niezawodność i dostępność źródeł: Systemy federacyjne zależą od dostępności i responsywności źródeł – awarie sieci, przerwy techniczne czy spadek wydajności wpływają bezpośrednio na jakość wyszukiwania.
Jakość wyników i trafność rankingu: Agregacja wyników z różnych źródeł o odmiennych poziomach jakości, zasięgu i kryteriach trafności to wyzwanie – ranking musi uwzględniać wiarygodność źródeł i unikać faworyzowania.
Świeżość i spójność danych: Federacyjne systemy mają dostęp do aktualnych danych źródłowych, ale źródła mogą różnić się częstotliwością aktualizacji i gwarancjami spójności. Rozstrzyganie konfliktów wymaga zaawansowanych strategii.
Ograniczenia skalowalności: Wraz ze wzrostem liczby źródeł rośnie narzut koordynacji zapytań. Wybór istotnych źródeł z tysięcy dostępnych staje się kosztowny obliczeniowo.
Bezpieczeństwo i kontrola dostępu: Federacyjne systemy muszą egzekwować kontrole dostępu na poziomie źródeł przy zapewnieniu zintegrowanego interfejsu – szczególnie trudne w środowiskach wielodzierżawczych.
Prywatność i ochrona danych: Federacyjne wyszukiwanie musi być zgodne z regulacjami, np. RODO, CCPA, wymogami branżowymi. Zapobieganie wyciekom danych przez agregację wyników czy analizę metadanych wymaga starannego projektu.
Odkrywanie i zarządzanie źródłami: Identyfikacja, katalogowanie, utrzymanie metadanych i zarządzanie cyklem życia źródeł to ciągłe wyzwanie operacyjne.
Interoperacyjność semantyczna: Osiągnięcie interoperacyjności semantycznej pomiędzy źródłami o różnych ontologiach i modelach danych jest trudne – automatyczne mapowanie schematów i rozpoznawanie encji mają swoje ograniczenia.
Koszt koordynacji: Choć federacyjne wyszukiwanie eliminuje koszty konsolidacji danych, wprowadza narzut na koordynację – zarządzanie wykonaniem rozproszonym i optymalizacja trasowania zapytań wymagają zaawansowanej infrastruktury.
Ograniczona standaryzacja: Brak uniwersalnych standardów protokołów federacyjnych utrudnia integrację i zwiększa ryzyko uzależnienia od dostawcy.
Federacyjna Wyszukiwarka AI a hurtownie danych: Hurtownie danych konsolidują dane z wielu źródeł w centralnym repozytorium, umożliwiając szybkie zapytania, ale wymagając kosztownego ETL i wprowadzając opóźnienia. Federacyjne wyszukiwanie zapytuje źródła bezpośrednio, zapewniając dostęp w czasie rzeczywistym, choć z większym opóźnieniem. Hurtownie sprawdzają się w analizach historycznych, federacja w odkrywaniu aktualnych informacji.
Federacyjna Wyszukiwarka AI a jeziora danych: Jeziora danych przechowują surowe dane z wielu źródeł centralnie, minimalnie je przetwarzając – to daje elastyczność, ale generuje koszty magazynowania i zarządzania. Federacyjne wyszukiwanie całkowicie unika konsolidacji, zachowując autonomię źródeł, ale wymaga bardziej zaawansowanego przetwarzania zapytań.
Federacyjna Wyszukiwarka AI a API i mikrousługi: API zapewniają programistyczny dostęp do pojedynczych usług, lecz wymagają znajomości interfejsów. Federacyjne wyszukiwanie abstrahuje szczegóły źródeł, umożliwiając zintegrowane zapytania – API służą integracji aplikacji, federacja – odkrywaniu informacji między usługami.
Federacyjna Wyszukiwarka AI a grafy wiedzy: Grafy wiedzy reprezentują informacje jako powiązane encje i relacje, umożliwiając wnioskowanie semantyczne. Federacyjne wyszukiwanie może przeszukiwać rozproszone grafy wiedzy, ale nie wymaga ich centralnej konstrukcji.
Federacyjna Wyszukiwarka AI a wyszukiwarki: Tradycyjne wyszukiwarki tworzą scentralizowane indeksy treści. Federacyjne wyszukiwanie zapytuje źródła bezpośrednio bez indeksowania. Wyszukiwarki zapewniają szeroki zasięg treści publicznych, federacja – integrację źródeł prywatnych i specjalistycznych.
Federacyjna Wyszukiwarka AI a Master Data Management (MDM): Systemy MDM konsolidują dane w postaci rekordów głównych – federacyjne wyszukiwanie zapytuje źródła niezależnie, nie tworząc rekordów master. MDM służy zarządzaniu danymi i spójności, federacyjne wyszukiwanie – autonomii i dostępowi w czasie rzeczywistym.
Federacyjna Wyszukiwarka AI a wyszukiwanie korporacyjne: Wyszukiwanie korporacyjne indeksuje wewnętrzne dokumenty i bazy centralnie – federacyjne wyszukiwanie zapytuje źródła bezpośrednio. Wyszukiwanie korporacyjne zapewnia szybkie wyszukiwanie pełnotekstowe, federacyjne obsługuje różnorodne źródła i aktualizacje w czasie rzeczywistym.
Federacyjna Wyszukiwarka AI a blockchain i rozproszone rejestry: Blockchain utrzymuje rozproszoną zgodność i niezmienność – federacyjne wyszukiwanie koordynuje zapytania bez konsensusu. Blockchain służy zaufaniu i weryfikacji, federacyjne wyszukiwanie – odkrywaniu informacji.
Kompleksowa ocena źródeł: Przed integracją przeprowadź szczegółową analizę jakości danych, częstotliwości aktualizacji, dostępności
Tradycyjne scentralizowane wyszukiwanie konsoliduje wszystkie dane w jednym indeksowanym repozytorium, co wymaga migracji danych i wprowadza opóźnienia. Federacyjna wyszukiwarka AI przeszukuje wiele niezależnych źródeł bezpośrednio w czasie rzeczywistym, bez przenoszenia czy duplikowania danych, zachowując autonomię źródeł i zapewniając zintegrowany dostęp. Dzięki temu federacyjne wyszukiwanie jest idealne dla organizacji z rozproszonymi źródłami danych i wymaganiami dotyczącymi ścisłego zarządzania danymi.
Federacyjna wyszukiwarka AI przechowuje dane w ich oryginalnych lokalizacjach i respektuje kontrole dostępu oraz polityki bezpieczeństwa każdego źródła. Użytkownicy mają dostęp tylko do informacji, do których są uprawnieni, a wrażliwe dane nigdy nie opuszczają systemu źródłowego. Takie podejście upraszcza zgodność z regulacjami, takimi jak RODO czy HIPAA, eliminując ryzyka związane z centralizacją wrażliwych informacji.
Kluczowe wyzwania to zarządzanie heterogenicznymi źródłami danych o różnych schematach i formatach, radzenie sobie z opóźnieniami zapytań z wielu źródeł, zapewnienie spójnego rankingu wyników oraz utrzymanie niezawodności systemu przy niedostępności źródeł. Organizacje muszą także inwestować w solidne zarządzanie metadanymi i inteligentne algorytmy wyboru źródeł w celu optymalizacji wydajności.
Tak, federacyjna wyszukiwarka AI skalowalnie dodaje nowe źródła bez konieczności migracji danych czy przebudowy hurtowni. Jednak wraz ze wzrostem liczby źródeł rośnie narzut związany z koordynacją zapytań. Nowoczesne systemy wykorzystują uczenie maszynowe do inteligentnego wyboru źródeł i wdrażają strategie buforowania w celu utrzymania wydajności na dużą skalę.
Hurtownie danych konsolidują dane w scentralizowanym repozytorium, co umożliwia szybkie zapytania, ale wymaga znacznego nakładu ETL i wprowadza opóźnienia. Federacyjne wyszukiwanie zapytuje źródła bezpośrednio, zapewniając dostęp w czasie rzeczywistym, choć z większym opóźnieniem zapytań. Hurtownie sprawdzają się w analizie historycznej i raportowaniu, podczas gdy federacyjne wyszukiwanie wyróżnia się w odkrywaniu bieżących informacji w rozproszonych źródłach.
Federacyjne wyszukiwanie przynosi znaczące korzyści sektorom ochrony zdrowia, finansom, e-commerce, administracji publicznej i instytucjom naukowym. Ochrona zdrowia wykorzystuje je do integracji dokumentacji pacjentów, finanse do zgodności i oceny ryzyka, e-commerce do zintegrowanego wyszukiwania produktów, a organizacje badawcze do przeszukiwania rozproszonych baz akademickich.
AI usprawnia federacyjne wyszukiwanie dzięki przetwarzaniu języka naturalnego do zrozumienia zapytań, uczeniu maszynowemu do wyboru źródeł, analizie semantycznej dla lepszego rankingu wyników i automatycznemu usuwaniu duplikatów. Modele AI uczą się na wzorcach zapytań, aby nieustannie optymalizować wybór źródeł i agregację wyników, poprawiając wydajność systemu z czasem.
Rozumienie semantyczne pozwala systemom federacyjnym zrozumieć intencję zapytania poza dopasowaniem słów kluczowych, trafniej identyfikować odpowiednie źródła i rankować wyniki na podstawie znaczenia, a nie tylko pokrycia słów. Obejmuje to rozpoznawanie encji, wydobywanie relacji i integrację grafów wiedzy, co skutkuje trafniejszymi i kontekstowo odpowiednimi wynikami wyszukiwania.
AmICited śledzi, jak systemy AI, takie jak ChatGPT, Perplexity i Google AI Overviews cytują i odnoszą się do Twojej marki. Dowiedz się, jaka jest Twoja widoczność w AI i zoptymalizuj swoją obecność w odpowiedziach generowanych przez AI.
Dowiedz się, czym są wyszukiwarki AI, czym różnią się od tradycyjnych wyszukiwarek oraz jaki mają wpływ na widoczność marki. Poznaj platformy takie jak Perplexi...

Dowiedz się, jak firmy technologiczne optymalizują treści pod kątem wyszukiwarek AI, takich jak ChatGPT, Perplexity i Gemini. Poznaj strategie zwiększania widoc...
Dowiedz się, czym jest intencja informacyjna wyszukiwania dla systemów AI, jak AI rozpoznaje te zapytania i dlaczego zrozumienie tej intencji jest ważne dla wid...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.