Rastreadores de IA Explicados: GPTBot, ClaudeBot e Outros
Entenda como rastreadores de IA como GPTBot e ClaudeBot funcionam, suas diferenças em relação aos rastreadores de busca tradicionais e como otimizar seu site para visibilidade em buscas por IA.
Publicado em Jan 3, 2026.Última modificação em Jan 3, 2026 às 3:24 am
Rastreadores de IA são programas automatizados projetados para navegar sistematicamente na internet e coletar dados de sites, especificamente para treinar e aprimorar modelos de inteligência artificial. Diferentemente dos rastreadores tradicionais de mecanismos de busca, como o Googlebot, que indexam conteúdo para resultados de pesquisa, os rastreadores de IA coletam dados brutos da web para alimentar grandes modelos de linguagem (LLMs) como ChatGPT, Claude e outros sistemas de IA. Esses bots operam continuamente em milhões de sites, baixando páginas, analisando conteúdo e extraindo informações que ajudam as plataformas de IA a entender padrões de linguagem, informações factuais e estilos de escrita diversos. Os principais players desse segmento incluem o GPTBot da OpenAI, o ClaudeBot da Anthropic, o Meta-ExternalAgent da Meta, o Amazonbot da Amazon e o PerplexityBot da Perplexity.ai, cada um servindo às necessidades de treinamento e operação de suas respectivas plataformas de IA. Entender como esses rastreadores funcionam tornou-se essencial para proprietários de sites e criadores de conteúdo, já que a visibilidade em IA agora impacta diretamente como sua marca aparece em resultados de busca e recomendações impulsionados por IA.
A Ascensão dos Rastreadores de IA
O cenário do rastreamento web passou por uma transformação dramática no último ano, com os rastreadores de IA experimentando um crescimento explosivo enquanto os rastreadores tradicionais mantêm padrões estáveis. Entre maio de 2024 e maio de 2025, o tráfego total de rastreadores cresceu 18%, mas a distribuição mudou significativamente—o GPTBot disparou 305% em requisições brutas, enquanto outros rastreadores como o ClaudeBot caíram 46% e o Bytespider despencou 85%. Essa mudança reflete a intensificação da competição entre empresas de IA para garantir dados de treinamento e aprimorar seus modelos. Veja um panorama detalhado dos principais rastreadores e sua posição atual no mercado:
Os dados mostram que, enquanto o Googlebot mantém a liderança com 4,5 bilhões de requisições mensais, os rastreadores de IA representam coletivamente cerca de 28% do volume do Googlebot, tornando-se uma força significativa no tráfego web. O crescimento explosivo do PerplexityBot (aumento de 157.490%) demonstra como novas plataformas de IA estão ampliando rapidamente suas operações de rastreamento, enquanto a queda de alguns rastreadores já estabelecidos sugere uma consolidação do mercado em torno das plataformas de IA mais bem-sucedidas.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
GPTBot é o rastreador web da OpenAI, projetado especificamente para coletar dados para treinar e aprimorar o ChatGPT e outros modelos da OpenAI. Lançado como um player relativamente pequeno com apenas 5% de participação de mercado em maio de 2024, o GPTBot tornou-se o principal rastreador de IA, capturando 30% de todo o tráfego de rastreadores de IA em maio de 2025—um aumento notável de 305% em requisições brutas. Esse crescimento explosivo reflete a estratégia agressiva da OpenAI para garantir que o ChatGPT tenha acesso a conteúdo web fresco e diversificado, tanto para treinamento do modelo quanto para capacidades de busca em tempo real via ChatGPT Search. O GPTBot opera com um padrão de rastreamento distinto, priorizando conteúdo HTML (57,70% das capturas) mas também baixando arquivos JavaScript e imagens, embora não execute JavaScript para renderizar conteúdo dinâmico. O comportamento do rastreador mostra que ele frequentemente encontra erros 404 (34,82% das requisições), sugerindo que pode estar seguindo links desatualizados ou tentando acessar recursos que não existem mais. Para proprietários de sites, a dominância do GPTBot significa que garantir que seu conteúdo seja acessível a esse rastreador tornou-se fundamental para visibilidade nas buscas do ChatGPT e para possível inclusão em futuras iterações de treinamento do modelo.
ClaudeBot e a Abordagem da Anthropic
ClaudeBot, desenvolvido pela Anthropic, atua como o principal rastreador para treinar e atualizar o assistente Claude AI, além de apoiar as capacidades de busca e fundamentação do Claude. Antes o segundo maior rastreador de IA, com 27% de participação de mercado em maio de 2024, o ClaudeBot teve uma queda notável para 21% em maio de 2025, com as requisições brutas caindo 46% ano a ano. Essa queda não indica necessariamente um problema na estratégia da Anthropic, mas reflete a mudança do mercado em direção à dominância da OpenAI e ao surgimento de novos concorrentes como o Meta-ExternalAgent. O ClaudeBot apresenta comportamento semelhante ao do GPTBot, priorizando conteúdo HTML, mas dedicando uma porcentagem maior de requisições a imagens (35,17% das capturas), sugerindo que a Anthropic pode estar treinando o Claude para entender melhor conteúdo visual além de texto. Como outros rastreadores de IA, o ClaudeBot não renderiza JavaScript, ou seja, vê apenas o HTML puro das páginas, sem qualquer conteúdo carregado dinamicamente. Para criadores de conteúdo, manter a visibilidade com o ClaudeBot continua importante para garantir que o Claude possa acessar e citar seu conteúdo, especialmente enquanto a Anthropic desenvolve as capacidades de busca e raciocínio do Claude.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Outros Principais Rastreadores de IA
Além do GPTBot e do ClaudeBot, outros rastreadores de IA significativos estão ativamente coletando dados web para suas respectivas plataformas:
Meta-ExternalAgent (Meta): O rastreador da Meta fez uma entrada dramática nos rankings, atingindo 19% de participação de mercado em maio de 2025 como um novo participante. Esse bot coleta dados para iniciativas de IA da Meta, incluindo possível treinamento para a Meta AI e integração com recursos de IA do Instagram e Facebook. A ascensão rápida da Meta sugere que a empresa está investindo fortemente em busca e recomendações impulsionadas por IA.
PerplexityBot (Perplexity.ai): Apesar de ter apenas 0,2% de participação de mercado, o PerplexityBot registrou a taxa de crescimento mais explosiva, com 157.490% ano a ano. Isso reflete a rápida expansão da Perplexity como um motor de respostas por IA que depende de busca web em tempo real para fundamentar suas respostas. Para sites, as visitas do PerplexityBot representam oportunidades diretas de serem citados nas respostas geradas pela IA da Perplexity.
Amazonbot (Amazon): O rastreador da Amazon caiu de 21% para 11% de participação de mercado, com as requisições brutas caindo 35% ano a ano. O Amazonbot coleta dados para funcionalidades de busca e aplicações de IA da Amazon, embora sua queda sugira que a Amazon pode estar ajustando sua estratégia de IA ou consolidando suas operações de rastreamento.
Applebot (Apple): O rastreador da Apple teve uma queda de 26% nas requisições, caindo de 1,9% para 1,2% de participação de mercado. O Applebot serve principalmente ao Siri e à busca Spotlight da Apple, mas também pode apoiar iniciativas emergentes de IA da empresa. Diferentemente da maioria dos outros rastreadores de IA, o Applebot pode renderizar JavaScript, oferecendo funcionalidades semelhantes ao Googlebot.
Como os Rastreadores de IA Diferem do Googlebot
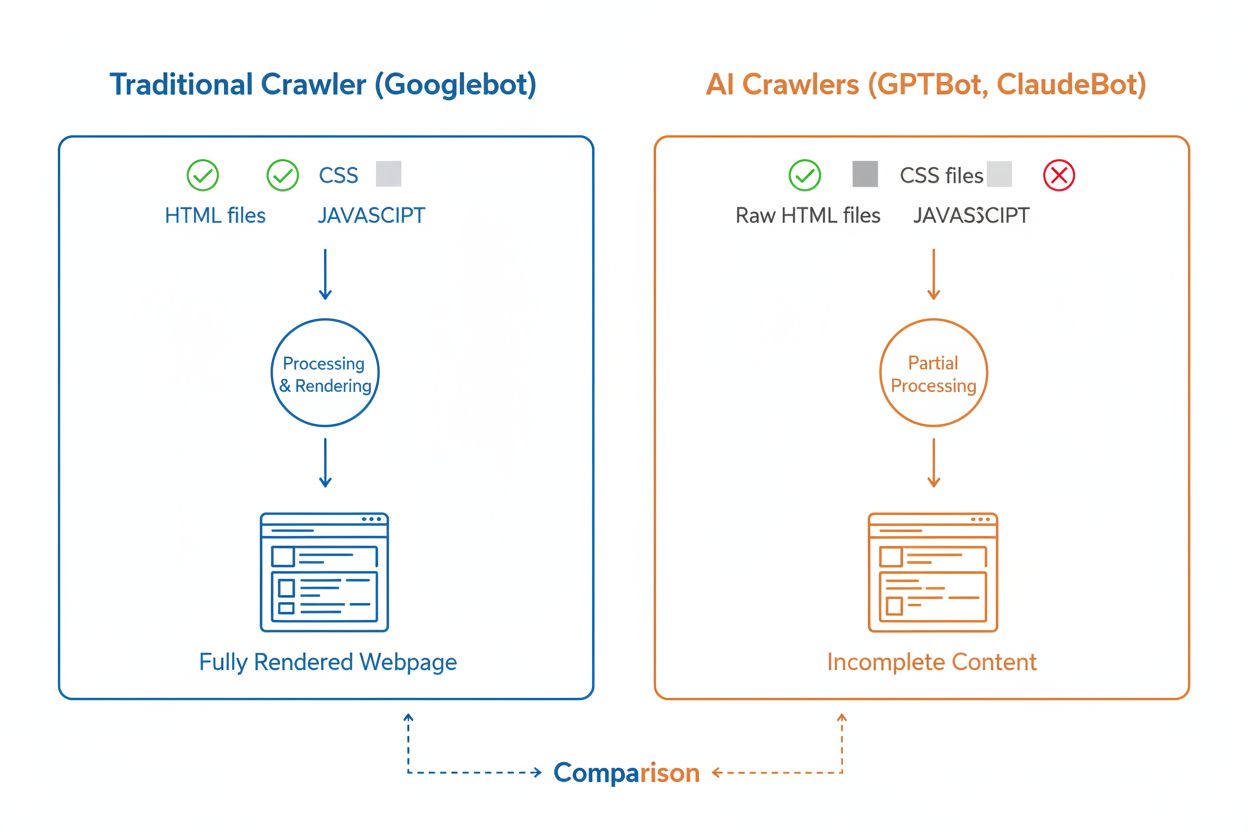
Embora rastreadores de IA e rastreadores tradicionais como o Googlebot naveguem sistematicamente pela web, suas capacidades técnicas e comportamentos diferem significativamente em aspectos que impactam diretamente como seu conteúdo é descoberto e compreendido. A diferença mais crítica é a renderização de JavaScript: o Googlebot pode executar JavaScript após baixar uma página, permitindo ver conteúdo carregado dinamicamente, enquanto a maioria dos rastreadores de IA (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) apenas lê o HTML puro e ignora qualquer conteúdo dependente de JavaScript. Isso significa que se seu site depende de renderização do lado do cliente para exibir informações-chave, os rastreadores de IA verão uma versão incompleta das suas páginas. Além disso, rastreadores de IA apresentam padrões de rastreamento menos previsíveis em comparação com a abordagem sistemática do Googlebot—gastando 34,82% das requisições em páginas 404 e 14,36% seguindo redirecionamentos, em comparação com os mais eficientes 8,22% em 404s e 1,49% em redirecionamentos do Googlebot. A frequência de rastreamento também difere: enquanto o Googlebot visita páginas com base em um sofisticado sistema de orçamento de rastreamento, rastreadores de IA parecem rastrear com mais frequência, mas de forma menos sistemática, com pesquisas mostrando que eles podem visitar páginas mais de 100 vezes com mais frequência do que o Google em alguns casos. Essas diferenças significam que estratégias tradicionais de SEO podem não contemplar totalmente a rastreabilidade por IA, exigindo uma abordagem distinta focada em renderização do lado do servidor e estruturas de URL limpas.
Limitações na Renderização de JavaScript
Um dos maiores desafios técnicos para rastreadores de IA é a incapacidade de renderizar JavaScript, uma limitação que decorre do alto custo computacional de executar JavaScript na escala massiva exigida para treinar grandes modelos de linguagem. Quando um rastreador baixa sua página, ele recebe a resposta HTML inicial, mas qualquer conteúdo carregado ou modificado por JavaScript—como detalhes de produtos, informações de preços, avaliações de usuários ou elementos de navegação dinâmica—permanece invisível aos rastreadores de IA. Isso cria um problema crítico para sites modernos que dependem fortemente de frameworks de renderização do lado do cliente como React, Vue ou Angular sem renderização do lado do servidor (SSR) ou geração de sites estáticos (SSG). Por exemplo, um site de e-commerce que carrega informações de produtos via JavaScript aparecerá para rastreadores de IA como uma página vazia, sem detalhes dos produtos, tornando impossível para os sistemas de IA entenderem ou citarem esse conteúdo. A solução é garantir que todo o conteúdo crítico seja servido na resposta HTML inicial através da renderização do lado do servidor, que gera o HTML completo no servidor antes de enviá-lo ao navegador. Essa abordagem garante que tanto visitantes humanos quanto rastreadores de IA recebam a mesma experiência rica em conteúdo. Sites que usam frameworks modernos como Next.js com SSR, geradores de sites estáticos como Hugo ou Gatsby, ou plataformas tradicionais renderizadas no servidor como WordPress são naturalmente amigáveis a rastreadores de IA, enquanto aqueles baseados apenas em renderização do lado do cliente enfrentam desafios significativos de visibilidade em buscas por IA.
Frequência e Padrões de Rastreamento
Rastreadores de IA exibem padrões de frequência de rastreamento distintos dos do Googlebot, com implicações importantes para a rapidez com que seu conteúdo é capturado pelos sistemas de IA. Pesquisas mostram que rastreadores de IA como ChatGPT e Perplexity frequentemente visitam páginas mais vezes do que o Google no curto prazo após a publicação—em alguns casos, visitando páginas 8 vezes mais do que o Googlebot nos primeiros dias. Esse rastreamento inicial rápido sugere que plataformas de IA priorizam descobrir e indexar novo conteúdo rapidamente, provavelmente para garantir que seus modelos e recursos de busca tenham acesso às informações mais recentes. No entanto, esse rastreamento agressivo inicial é seguido por um padrão em que rastreadores de IA podem não retornar se o conteúdo não atender aos padrões de qualidade, tornando a primeira impressão extremamente importante. Ao contrário do Googlebot, que tem um sofisticado sistema de orçamento de rastreamento e retornará regularmente às páginas com base na frequência de atualização e importância, rastreadores de IA parecem decidir rapidamente se o conteúdo vale uma nova visita. Isso significa que, se um rastreador de IA visitar sua página e encontrar conteúdo superficial, erros técnicos ou sinais de má experiência do usuário, pode demorar muito para retornar—ou nunca mais voltar. A implicação para criadores de conteúdo é clara: não é possível contar com uma segunda chance para otimizar conteúdo para rastreadores de IA como se faz nos mecanismos de busca tradicionais, tornando a garantia de qualidade pré-publicação essencial.
robots.txt e Controle de Rastreadores de IA
Proprietários de sites podem usar o arquivo robots.txt para comunicar suas preferências quanto ao acesso de rastreadores de IA, embora a eficácia e aplicação dessas regras variem bastante entre os rastreadores. Dados recentes mostram que cerca de 14% dos 10.000 maiores sites implementaram regras específicas de permissão ou bloqueio direcionadas a bots de IA em seus arquivos robots.txt. O GPTBot é o rastreador mais frequentemente bloqueado, com 312 domínios (250 totalmente, 62 parcialmente) explicitamente o proibindo, embora também seja o rastreador mais explicitamente permitido, com 61 domínios concedendo acesso. Outros rastreadores frequentemente bloqueados incluem o CCBot (Common Crawl) e o Google-Extended (token de treinamento de IA do Google). O desafio do robots.txt é que a conformidade é voluntária—rastreadores só seguem essas regras se seus operadores escolherem implementar essa funcionalidade, e alguns rastreadores mais novos ou menos transparentes podem não respeitar as diretivas do robots.txt. Além disso, tokens como “Google-Extended” não correspondem diretamente a user-agents nas solicitações HTTP; em vez disso, sinalizam o propósito do rastreamento, o que significa que nem sempre é possível verificar a conformidade pelos logs do servidor. Para uma aplicação mais forte, proprietários de sites recorrem cada vez mais a regras de firewall e Web Application Firewalls (WAFs) que podem bloquear ativamente user-agents específicos de rastreadores, oferecendo um controle mais confiável que o robots.txt sozinho. Essa mudança para mecanismos de bloqueio ativos reflete preocupações crescentes com direitos sobre conteúdo e o desejo de controles mais efetivos sobre o acesso de rastreadores de IA.
Monitoramento da Atividade de Rastreadores de IA
Acompanhar a atividade dos rastreadores de IA em seu site é essencial para entender sua visibilidade em buscas por IA, mas apresenta desafios únicos em relação ao monitoramento de rastreadores tradicionais. Ferramentas de análise tradicionais como o Google Analytics dependem de rastreamento via JavaScript, que rastreadores de IA não executam, o que significa que essas ferramentas não fornecem visibilidade sobre visitas de bots de IA. Da mesma forma, rastreamento baseado em pixel também não funciona, pois a maioria dos rastreadores de IA apenas processa texto e ignora imagens. A única forma confiável de monitorar a atividade dos rastreadores de IA é através do monitoramento do lado do servidor—analisando cabeçalhos de requisições HTTP e logs do servidor para identificar user-agents de rastreadores antes da página ser enviada. Isso exige análise manual de logs ou ferramentas especializadas projetadas especificamente para identificar e acompanhar o tráfego de rastreadores de IA. O monitoramento em tempo real é particularmente importante porque rastreadores de IA operam em horários imprevisíveis e podem não retornar às páginas se encontrarem problemas, ou seja, auditorias semanais ou mensais podem não detectar questões críticas. Se um rastreador de IA visita seu site e encontra erros técnicos ou conteúdo de baixa qualidade, você pode não ter outra oportunidade de causar uma boa impressão. Implementar soluções de monitoramento 24/7 que alertam imediatamente quando rastreadores de IA encontram problemas—como erros 404, lentidão no carregamento da página ou ausência de marcação de schema—permite corrigir falhas antes que impactem sua visibilidade em buscas por IA. Essa abordagem em tempo real representa uma mudança fundamental em relação às práticas tradicionais de monitoramento de SEO, refletindo a velocidade e imprevisibilidade do comportamento dos rastreadores de IA.
Otimizando para Rastreadores de IA
Otimizar seu site para rastreadores de IA exige uma abordagem distinta do SEO tradicional, focando em fatores técnicos que impactam diretamente como sistemas de IA podem acessar e entender seu conteúdo. A primeira prioridade é a renderização do lado do servidor: garanta que todo o conteúdo crítico—títulos, corpo do texto, metadados, dados estruturados—esteja incluído na resposta HTML inicial, e não carregado dinamicamente via JavaScript. Isso vale para sua página inicial, páginas de destino e qualquer conteúdo que você queira que sistemas de IA citem ou referenciem. Em segundo lugar, implemente marcação de dados estruturados (Schema.org) nas páginas de maior impacto, incluindo schema de artigo para posts de blog, schema de produto para itens de e-commerce e schema de autor para estabelecer expertise e autoridade. Rastreadores de IA usam dados estruturados para entender rapidamente a hierarquia e o contexto do conteúdo, facilitando sua interpretação e citação. Em terceiro lugar, mantenha padrões rigorosos de qualidade de conteúdo em todas as páginas, já que rastreadores de IA parecem decidir rapidamente se um conteúdo vale ser indexado e citado. Isso significa garantir que seu conteúdo seja original, bem pesquisado, factual e agregue valor real ao leitor. Em quarto, monitore e otimize os Core Web Vitals e o desempenho geral da página, pois páginas lentas sinalizam má experiência do usuário e podem desencorajar rastreadores de IA a retornarem. Por fim, mantenha sua estrutura de URLs limpa e consistente, mantenha um sitemap XML atualizado e configure corretamente seu arquivo robots.txt para direcionar os rastreadores ao conteúdo mais importante. Essas otimizações técnicas criam a base para que seu conteúdo seja descoberto, compreendido e citado por sistemas de IA.
O Futuro dos Rastreadores de IA
O cenário dos rastreadores de IA continuará evoluindo rapidamente à medida que a competição se intensifica entre as empresas de IA e a tecnologia amadurece. Uma tendência clara é a consolidação da participação de mercado em torno das plataformas mais bem-sucedidas—o GPTBot da OpenAI tornou-se a principal força, enquanto novos participantes como o Meta-ExternalAgent estão ampliando operações agressivamente, indicando que o mercado provavelmente se estabilizará em torno de alguns grandes players. À medida que os rastreadores de IA amadurecem, podemos esperar melhorias em suas capacidades técnicas, especialmente em renderização de JavaScript e padrões de rastreamento mais eficientes, que reduzam requisições desperdiçadas em páginas 404 e conteúdo desatualizado. A indústria também está caminhando para protocolos de comunicação mais padronizados, como a especificação emergente llms.txt, que permite aos sites comunicar explicitamente sua estrutura de conteúdo e preferências de rastreamento aos sistemas de IA. Além disso, os mecanismos de controle de acesso de rastreadores de IA estão se tornando mais sofisticados, com plataformas como a Cloudflare agora oferecendo bloqueio automatizado de bots de treinamento de IA por padrão, dando aos proprietários de sites mais controle sobre seu conteúdo. Para criadores de conteúdo e proprietários de sites, acompanhar essas mudanças significa monitorar continuamente a atividade dos rastreadores de IA, manter sua infraestrutura técnica otimizada para acessibilidade por IA e adaptar sua estratégia de conteúdo à realidade de que sistemas de IA agora representam uma parte significativa do tráfego do seu site e um canal crítico para visibilidade de marca. O futuro pertence a quem entende e otimiza para esse novo ecossistema de rastreadores.
Perguntas frequentes
O que é um rastreador de IA e como ele difere de um rastreador de mecanismo de busca?
Rastreadores de IA são programas automatizados que coletam dados da web especificamente para treinar e aprimorar modelos de inteligência artificial como ChatGPT e Claude. Ao contrário dos rastreadores tradicionais de mecanismos de busca, como o Googlebot, que indexam conteúdo para resultados de pesquisa, os rastreadores de IA coletam dados brutos da web para alimentar grandes modelos de linguagem. Ambos os tipos de rastreadores navegam sistematicamente pela internet, mas servem a propósitos diferentes e possuem capacidades técnicas distintas.
Por que rastreadores de IA precisam acessar meu site?
Rastreadores de IA acessam seu site para coletar dados para treinamento de modelos de IA, aprimorar recursos de busca e fundamentar respostas de IA com informações atualizadas. Quando sistemas como ChatGPT ou Perplexity respondem a perguntas de usuários, geralmente precisam buscar seu conteúdo em tempo real para fornecer informações precisas e citadas. Permitir o acesso de rastreadores de IA ao seu site aumenta as chances de sua marca ser mencionada e citada em respostas geradas por IA.
Posso bloquear rastreadores de IA de acessarem meu site?
Sim, você pode usar o arquivo robots.txt para impedir rastreadores de IA específicos, especificando seus nomes de user-agent. No entanto, a conformidade com o robots.txt é voluntária e nem todos os rastreadores respeitam essas regras. Para uma aplicação mais rígida, você pode usar regras de firewall e Firewalls de Aplicação Web (WAFs) para bloquear ativamente user-agents de rastreadores específicos. Isso dá a você um controle mais confiável sobre quais rastreadores de IA podem acessar seu conteúdo.
Rastreadores de IA renderizam JavaScript como o Google faz?
Não, a maioria dos rastreadores de IA (GPTBot, ClaudeBot, Meta-ExternalAgent) não executa JavaScript. Eles apenas leem o HTML bruto das suas páginas, o que significa que qualquer conteúdo carregado dinamicamente via JavaScript será invisível para eles. Por isso, a renderização do lado do servidor é fundamental para a rastreabilidade por IA. Se seu site depende de renderização no lado do cliente, os rastreadores de IA verão uma versão incompleta das suas páginas.
Com que frequência rastreadores de IA visitam sites?
Rastreadores de IA visitam sites com mais frequência do que mecanismos de busca tradicionais no curto prazo após a publicação de conteúdo. Pesquisas mostram que eles podem visitar páginas de 8 a 100 vezes mais do que o Google nos primeiros dias. No entanto, se o conteúdo não atender aos padrões de qualidade, podem não retornar. Isso torna a primeira impressão crucial—você pode não ter uma segunda chance de otimizar o conteúdo para rastreadores de IA.
Qual a melhor maneira de otimizar meu site para rastreadores de IA?
As principais otimizações são: (1) Use renderização do lado do servidor para garantir que o conteúdo crítico esteja no HTML inicial, (2) Adicione marcação de dados estruturados (Schema) para ajudar a IA a entender seu conteúdo, (3) Mantenha alta qualidade e atualidade do conteúdo, (4) Monitore os Core Web Vitals para boa experiência do usuário e (5) Mantenha a estrutura de URLs limpa e um sitemap atualizado. Essas otimizações técnicas criam uma base para que seu conteúdo seja descoberto e citado por sistemas de IA.
Qual rastreador de IA é mais importante para meu site?
O GPTBot, da OpenAI, é atualmente o principal rastreador de IA, representando 30% de todo o tráfego de rastreadores de IA e crescendo 305% ano a ano. No entanto, você deve otimizar para todos os principais rastreadores, incluindo ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity) e outros. Diferentes plataformas de IA têm diferentes bases de usuários, então a visibilidade em vários rastreadores maximiza a presença da sua marca na busca por IA.
Como posso rastrear a atividade de rastreadores de IA no meu site?
Ferramentas de análise tradicionais como o Google Analytics não capturam a atividade de rastreadores de IA porque dependem de rastreamento em JavaScript. Em vez disso, você precisa de monitoramento do lado do servidor que analise cabeçalhos de solicitações HTTP e logs do servidor para identificar user-agents de rastreadores. Ferramentas especializadas para rastreamento de rastreadores de IA fornecem visibilidade em tempo real sobre quais páginas estão sendo rastreadas, com que frequência e se os rastreadores estão encontrando problemas técnicos.
Monitore a Visibilidade da Sua Marca na Busca por IA
Acompanhe como rastreadores de IA como GPTBot e ClaudeBot estão acessando e citando seu conteúdo. Obtenha insights em tempo real sobre sua visibilidade em buscas por IA com o AmICited.
Como Permitir que Bots de IA Rastreiem Seu Site: Guia Completo de robots.txt & llms.txt
Aprenda como permitir que bots de IA como GPTBot, PerplexityBot e ClaudeBot rastreiem seu site. Configure o robots.txt, crie o llms.txt e otimize para visibilid...
Saiba o que são Rastreadores de Ranking de IA, como funcionam e por que monitorar a visibilidade da sua marca em respostas do ChatGPT, Perplexity e Google AI Ov...
Como Rastreadores de IA Priorizam Páginas: Orçamento de Rastreamento e Fatores de Ranqueamento
Aprenda como rastreadores de IA priorizam páginas usando capacidade e demanda de rastreamento. Entenda a otimização do orçamento de rastreamento para ChatGPT, P...
14 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.