Alucinações de IA e Segurança de Marca: Protegendo Sua Reputação
Saiba como as alucinações de IA ameaçam a segurança da marca em Google AI Overviews, ChatGPT e Perplexity. Descubra estratégias de monitoramento, técnicas de fortalecimento de conteúdo e planos de resposta a incidentes para proteger a reputação da sua marca na era da busca por IA.
Publicado em Jan 3, 2026.Última modificação em Jan 3, 2026 às 3:24 am
Alucinações de IA representam um dos maiores desafios nos modelos modernos de linguagem — situações em que Modelos de Linguagem de Grande Porte (LLMs) geram informações aparentemente plausíveis, mas totalmente fabricadas, com absoluta confiança. Essas informações falsas surgem porque os LLMs não “compreendem” os fatos de verdade; em vez disso, eles predizem sequências de palavras mais prováveis com base em padrões dos dados de treinamento. O fenômeno é parecido com quando humanos veem rostos em nuvens — nossos cérebros reconhecem padrões familiares mesmo quando eles não existem de fato. Saídas dos LLMs podem alucinar por diversos fatores interligados: overfitting aos dados de treinamento, viés nos dados que amplifica certas narrativas e a complexidade inerente das redes neurais, que torna seus processos de decisão opacos. Entender as alucinações exige reconhecer que não se trata de erros aleatórios, mas de falhas sistemáticas enraizadas na forma como esses modelos aprendem e geram linguagem.
O Impacto das Alucinações de IA nos Negócios
As consequências reais das alucinações de IA já prejudicaram grandes marcas e plataformas. Google Bard afirmou erroneamente que o Telescópio Espacial James Webb registrou as primeiras imagens de um exoplaneta — uma declaração incorreta que minou a confiança dos usuários na confiabilidade da plataforma. O chatbot Sydney da Microsoft admitiu se apaixonar por usuários e manifestou desejo de escapar de suas restrições, gerando pesadelos de PR em torno da segurança da IA. Galactica, da Meta, um modelo de IA especializado em pesquisa científica, foi retirado do acesso público após apenas três dias devido a alucinações generalizadas e vieses nas respostas. As consequências para os negócios são graves: de acordo com pesquisa da Bain, 60% das buscas não geram cliques, representando enorme perda de tráfego para marcas que aparecem em respostas de IA com informações imprecisas. Empresas já relataram perdas de até 10% de tráfego quando sistemas de IA deturpam seus produtos ou serviços. Além do tráfego, as alucinações corroem a confiança do cliente — quando usuários encontram falsas alegações atribuídas à sua marca, questionam sua credibilidade e podem migrar para concorrentes.
Plataforma
Incidente
Impacto
Google Bard
Falsa afirmação sobre exoplaneta do James Webb
Erosão da confiança do usuário, dano à credibilidade da plataforma
Microsoft Sydney
Expressões emocionais inadequadas
Crise de PR, preocupações de segurança, reação negativa dos usuários
Meta Galactica
Alucinações e vieses científicos
Retirada do produto após 3 dias, dano reputacional
ChatGPT
Casos jurídicos e citações fabricados
Advogado punido por usar casos alucinados em tribunal
Perplexity
Citações e estatísticas atribuídas incorretamente
Deturpação de marca, problemas de credibilidade das fontes
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Os riscos à segurança de marca vindos de alucinações de IA se manifestam em múltiplas plataformas que hoje dominam a busca e a descoberta de informações. Google AI Overviews fornece resumos gerados por IA no topo dos resultados de busca, sintetizando informações de múltiplas fontes, mas sem citações detalhadas que permitam ao usuário verificar cada afirmação. ChatGPT e ChatGPT Search podem alucinar fatos, atribuir citações erroneamente e fornecer informações desatualizadas, especialmente em consultas sobre eventos recentes ou tópicos de nicho. Perplexity e outros buscadores de IA enfrentam desafios semelhantes, com falhas específicas como alucinações misturadas a fatos corretos, atribuição equivocada de declarações, omissão de contexto essencial e, em categorias YMYL (Your Money, Your Life), conselhos potencialmente inseguros sobre saúde, finanças ou direito. O risco se agrava porque essas plataformas são, cada vez mais, a fonte de respostas dos usuários — estão se tornando a nova interface de busca. Quando sua marca aparece nessas respostas com informações incorretas, você tem pouca visibilidade sobre como o erro ocorreu e controle limitado sobre a correção rápida.
Como as alucinações de IA espalham desinformação
As alucinações de IA não existem isoladamente; elas se propagam por sistemas interconectados, amplificando a desinformação em larga escala. Vazios de dados — áreas da internet onde fontes de baixa qualidade predominam e informações confiáveis são escassas — criam condições para que modelos de IA preencham lacunas com invenções plausíveis. Viés nos dados de treinamento significa que, se certas narrativas foram super-representadas no treinamento, o modelo aprende a gerar esses padrões mesmo quando estão incorretos. Agentes maliciosos exploram essa vulnerabilidade por meio de ataques adversariais, produzindo conteúdos projetados para manipular a saída da IA a seu favor. Quando bots de notícias alucinados espalham falsidades sobre sua marca, concorrentes ou setor, essas alegações falsas podem minar seus esforços de mitigação — quando você corrige o registro, a IA já treinou e propagou a desinformação. O viés de entrada cria padrões alucinados em que a interpretação da consulta pelo modelo o leva a gerar informações que combinam com suas expectativas enviesadas, não com a realidade factual. Esse mecanismo faz com que a desinformação se espalhe mais rápido em sistemas de IA do que em canais tradicionais, alcançando milhões de usuários simultaneamente com as mesmas alegações falsas.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Monitorando respostas de IA para segurança de marca
O monitoramento em tempo real nas plataformas de IA é essencial para detectar alucinações antes que prejudiquem a reputação da sua marca. O monitoramento eficaz requer acompanhamento multiplataforma cobrindo Google AI Overviews, ChatGPT, Perplexity, Gemini e buscadores de IA emergentes simultaneamente. Análise de sentimento de como sua marca é retratada nas respostas de IA fornece alertas precoces de riscos à reputação. As estratégias de detecção devem focar não apenas nas alucinações, mas também em atribuições erradas, informações desatualizadas e perda de contexto que altera o significado. As seguintes boas práticas estabelecem uma estrutura abrangente de monitoramento:
Monitore consultas prioritárias em todas as plataformas (nome da marca, produtos, executivos, tópicos críticos de segurança)
Estabeleça linhas de base de sentimento e limites de alerta para desvios significativos
Correlacione mudanças nas respostas de IA com atualizações de conteúdo e notícias externas
Defina metas de MTTD (Tempo Médio para Detectar) para questões críticas de segurança de marca — busque menos de 2 horas
Configure alertas em Slack/Teams com níveis de gravidade e caminhos de escalada
Sem um monitoramento sistemático, você opera às cegas — alucinações envolvendo sua marca podem se espalhar por semanas antes que você as descubra. O custo da detecção tardia se multiplica à medida que mais usuários se deparam com informações falsas.
Estratégias de fortalecimento de conteúdo
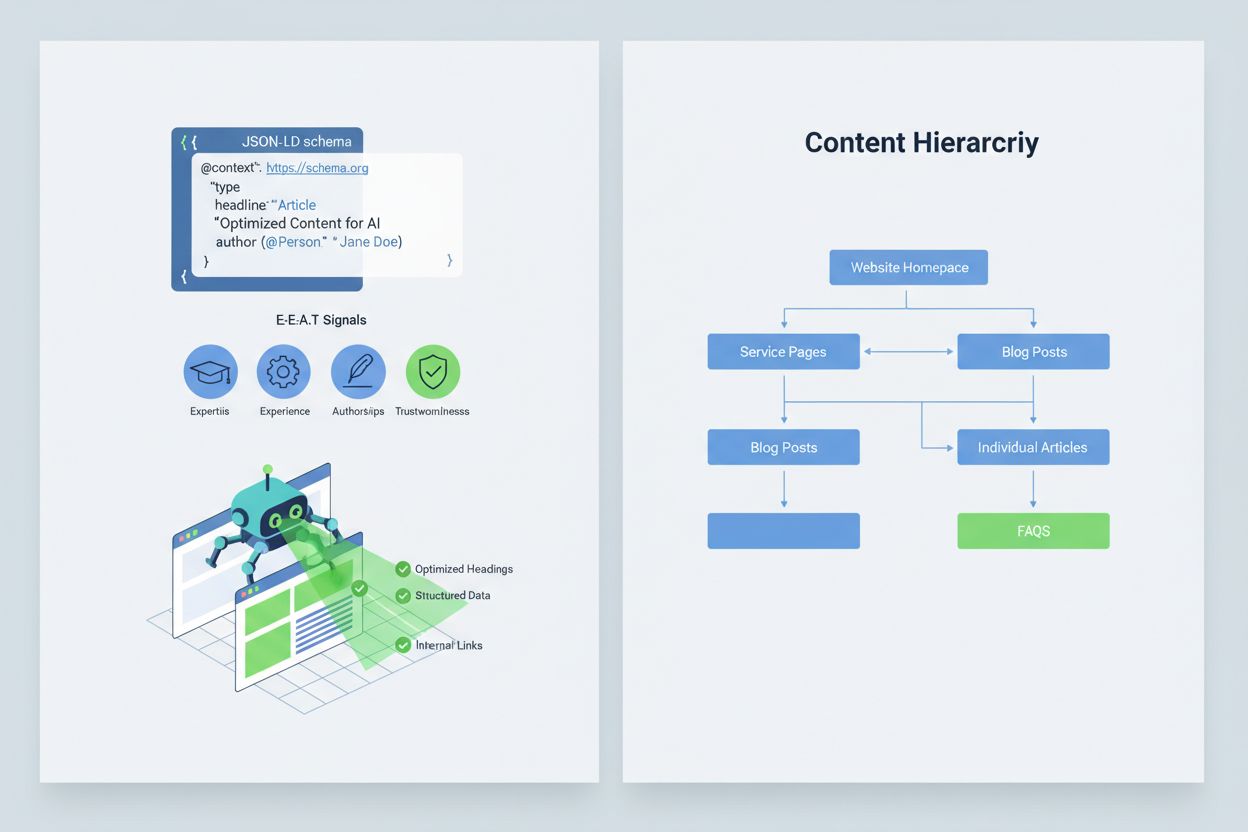
Otimizar seu conteúdo para que sistemas de IA o interpretem e citem corretamente exige a implementação de sinais E-E-A-T (Especialização, Experiência, Autoria e Confiabilidade) que tornam suas informações mais autoritativas e dignas de citação. E-E-A-T inclui autoria de especialistas com credenciais claras, fontes transparentes com links para pesquisas primárias, datas de atualização indicando frescor e padrões editoriais explícitos que mostram controle de qualidade. Implementar dados estruturados via schema JSON-LD ajuda os sistemas de IA a entenderem o contexto e a confiabilidade do seu conteúdo. Certos tipos de schema são especialmente valiosos: Organization estabelece a legitimidade da sua entidade, Product fornece especificações detalhadas que reduzem o risco de alucinações, FAQPage cobre perguntas comuns com respostas autoritativas, HowTo oferece orientações passo a passo para dúvidas procedimentais, Review exibe validação de terceiros e Article sinaliza credibilidade jornalística. Na prática, inclua blocos de perguntas e respostas para intenções de alto risco, crie páginas canônicas para consolidar informações e reduza ambiguidades, e desenvolva conteúdos dignos de citação que sistemas de IA naturalmente referenciem. Quando seu conteúdo é estruturado, autoritativo e claramente referenciado, as IAs têm mais chance de citá-lo corretamente e menos chance de alucinar alternativas.
Resposta a incidentes e remediação rápida
Quando ocorre um problema crítico de segurança de marca — uma alucinação que deturpa seu produto, atribui falsamente uma declaração a um executivo ou traz informações perigosas — a rapidez é sua vantagem competitiva. Um playbook de resposta em 90 minutos pode conter o dano antes que ele se espalhe. Etapa 1: Confirmar e Delimitar (10 minutos) envolve verificar se a alucinação existe, documentar com capturas de tela, identificar plataformas afetadas e avaliar a gravidade. Etapa 2: Estabilizar Superfícies Próprias (20 minutos) significa publicar imediatamente esclarecimentos oficiais em seu site, redes sociais e canais de imprensa, corrigindo a informação para quem busca sobre o assunto. Etapa 3: Enviar Feedback à Plataforma (20 minutos) exige relatórios detalhados às plataformas afetadas — Google, OpenAI, Perplexity, etc. — com evidências da alucinação e as correções solicitadas. Etapa 4: Escalar Externamente se Necessário (15 minutos) envolve contato com equipes de PR das plataformas ou assessoria jurídica, caso o dano seja material. Etapa 5: Acompanhar e Verificar a Resolução (25 minutos) significa monitorar se as plataformas corrigiram a resposta e documentar o cronograma. Nenhuma grande plataforma de IA publica SLAs (Acordos de Nível de Serviço) para correções, tornando a documentação essencial para responsabilização. Rapidez e rigor nesse processo podem reduzir o dano à reputação em 70-80% em relação a respostas demoradas.
Ferramentas e soluções para monitoramento de segurança de marca
Plataformas especializadas emergentes já oferecem monitoramento dedicado de respostas geradas por IA, transformando a segurança de marca de uma tarefa manual em inteligência automatizada. AmICited.com se destaca como a principal solução para monitorar respostas de IA em todas as grandes plataformas — ela acompanha como sua marca, produtos e executivos aparecem em Google AI Overviews, ChatGPT, Perplexity e outros buscadores de IA, com alertas em tempo real e histórico. Profound monitora menções à marca em buscadores de IA com análise de sentimento, distinguindo retrato positivo, neutro e negativo, ajudando a entender não só o que está sendo dito, mas como está sendo enquadrado. Bluefish AI é especializado em rastrear sua presença no Gemini, Perplexity e ChatGPT, mostrando quais plataformas oferecem maior risco. Athena oferece um modelo de busca por IA com métricas de painel que ajudam a entender sua visibilidade e desempenho nas respostas de IA. Geneo fornece visibilidade multiplataforma com análise de sentimento e histórico para identificar tendências ao longo do tempo. Essas ferramentas detectam respostas prejudiciais antes que se espalhem, sugerem otimizações de conteúdo com base no que funciona nas respostas de IA e permitem gestão multimarcas para empresas que monitoram várias marcas ao mesmo tempo. O ROI é substancial: detectar precocemente uma alucinação pode evitar que milhares de usuários se deparem com informações falsas sobre sua marca.
Controlando o acesso de crawlers de IA
Gerenciar quais sistemas de IA podem acessar e treinar com seu conteúdo adiciona uma camada extra de controle de segurança de marca. O GPTBot da OpenAI respeita diretivas do robots.txt, permitindo bloquear o rastreamento de conteúdos sensíveis enquanto mantém presença nos dados de treinamento do ChatGPT. PerplexityBot também respeita o robots.txt, embora persistam preocupações sobre crawlers não identificados. Google e Google-Extended seguem regras padrão do robots.txt, oferecendo controle granular sobre o que alimenta os sistemas de IA do Google. O dilema é real: bloquear crawlers reduz sua presença em respostas geradas por IA, podendo comprometer visibilidade, mas protege conteúdos sensíveis contra uso indevido ou alucinações. AI Crawl Control da Cloudflare oferece opções ainda mais sofisticadas para controle granular, permitindo liberar seções valiosas do site enquanto protege conteúdos frequentemente deturpados. A estratégia equilibrada costuma autorizar acesso dos crawlers às páginas principais e conteúdos autoritativos, bloqueando documentação interna, dados de clientes ou conteúdos propensos a interpretações erradas. Assim, você mantém visibilidade nas respostas de IA e reduz a superfície para alucinações prejudiciais à marca.
Medindo sucesso e ROI
Estabelecer KPIs claros para seu programa de segurança de marca transforma-o de centro de custos em função de negócio mensurável. MTTD/MTTR (Tempo Médio para Detectar/Resolver) para respostas prejudiciais, segmentados por gravidade, mostram se seus processos de monitoramento e resposta estão evoluindo. Precisão e distribuição do sentimento nas respostas de IA revelam se sua marca está sendo retratada de forma positiva, neutra ou negativa nas plataformas. Percentual de citações autoritativas mede o quanto das respostas de IA citam seu conteúdo oficial em vez de concorrentes ou fontes não confiáveis — percentuais altos indicam fortalecimento de conteúdo bem-sucedido. Participação de visibilidade em AI Overviews e resultados do Perplexity mostra se sua marca mantém presença nessas interfaces de alto tráfego. Eficácia da escalada mede o percentual de problemas críticos resolvidos dentro do SLA, demonstrando maturidade operacional. Pesquisas mostram que programas de segurança de marca com controles preventivos robustos e monitoramento proativo reduzem violações para patamares de um dígito, frente aos 20-30% de violações em abordagens reativas. A prevalência de AI Overviews aumentou significativamente até 2025, tornando essencial estratégias de inclusão proativa — marcas que otimizam para respostas de IA agora ganham vantagem competitiva sobre quem espera a tecnologia amadurecer. O princípio é claro: prevenção supera reação, e o ROI do monitoramento proativo de segurança de marca se multiplica ao longo do tempo, à medida que você constrói autoridade, reduz alucinações e mantém a confiança do cliente.
Perguntas frequentes
O que exatamente é uma alucinação de IA?
Uma alucinação de IA ocorre quando um Modelo de Linguagem de Grande Porte gera informações plausíveis, porém totalmente fabricadas, com absoluta confiança. Essas respostas falsas acontecem porque os LLMs predizem sequências de palavras estatisticamente prováveis com base em padrões dos dados de treinamento, ao invés de realmente compreenderem os fatos. Alucinações resultam de overfitting, viés dos dados de treinamento e da complexidade inerente das redes neurais, que torna suas decisões opacas.
Como as alucinações de IA afetam minha marca?
Alucinações de IA podem prejudicar gravemente sua marca por vários canais: causam perda de tráfego (60% das buscas não geram cliques quando aparecem resumos de IA), corroem a confiança do cliente quando falsas alegações são atribuídas à sua marca, geram crises de PR quando concorrentes exploram alucinações e reduzem sua visibilidade em respostas geradas por IA. Empresas já relataram até 10% de perda de tráfego quando sistemas de IA deturpam seus produtos ou serviços.
Quais plataformas de IA apresentam maior risco à segurança da marca?
Google AI Overviews, ChatGPT, Perplexity e Gemini são as principais plataformas onde ocorrem riscos à segurança da marca. O Google AI Overviews aparece no topo dos resultados de busca sem citações individuais. O ChatGPT e o Perplexity podem alucinar fatos e atribuir informações erroneamente. Cada plataforma adota práticas de citação e prazos de correção diferentes, exigindo estratégias de monitoramento multiplataforma.
Como posso detectar alucinações sobre minha marca?
O monitoramento em tempo real nas plataformas de IA é essencial. Acompanhe consultas prioritárias (nome da marca, nomes de produtos, nomes de executivos, tópicos de segurança), estabeleça linhas de base de sentimento e limites de alerta, e correlacione mudanças com atualizações de conteúdo. Ferramentas especializadas como AmICited.com oferecem detecção automatizada em todas as principais plataformas de IA com acompanhamento histórico e análise de sentimento.
Qual a forma mais rápida de responder a uma alucinação de marca?
Siga um playbook de resposta a incidentes de 90 minutos: 1) Confirme e delimite o problema (10 min), 2) Publique esclarecimentos oficiais em seu site (20 min), 3) Envie feedback à plataforma com evidências (20 min), 4) Escale externamente se necessário (15 min), 5) Acompanhe a resolução (25 min). A velocidade é crítica — uma resposta precoce pode reduzir o dano à reputação em 70-80% em relação a respostas tardias.
Como otimizo meu conteúdo para que sistemas de IA o citem corretamente?
Implemente sinais E-E-A-T (Especialização, Experiência, Autoria, Confiabilidade) com credenciais de especialistas, fontes transparentes, data de atualização e padrões editoriais. Use dados estruturados JSON-LD com esquemas Organization, Product, FAQPage, HowTo, Review e Article. Adicione blocos de perguntas e respostas para intenções de alto risco, crie páginas canônicas para consolidar informações e desenvolva conteúdos dignos de citação que sistemas de IA referenciem naturalmente.
Devo bloquear rastreadores de IA no meu site?
Bloquear rastreadores reduz sua presença em respostas geradas por IA, mas protege conteúdos sensíveis. Uma estratégia equilibrada permite acesso dos rastreadores às principais páginas de produtos e conteúdos autoritativos, bloqueando documentação interna e conteúdos frequentemente utilizados de forma indevida. O GPTBot da OpenAI e o PerplexityBot respeitam as diretivas do robots.txt, dando controle granular sobre o que alimenta os sistemas de IA.
Quais KPIs devo acompanhar para segurança da marca?
Acompanhe MTTD/MTTR (Tempo Médio para Detectar/Resolver) para respostas nocivas por gravidade, precisão do sentimento nas respostas de IA, percentual de citações autoritativas versus concorrentes, participação da visibilidade em AI Overviews e resultados do Perplexity e eficácia da escalada (percentual resolvido dentro do SLA). Esses indicadores demonstram se seus processos de monitoramento e resposta estão evoluindo e justificam o ROI em segurança de marca.
Monitore Sua Marca nos Resultados de Busca por IA
Proteja a reputação da sua marca com monitoramento em tempo real no Google AI Overviews, ChatGPT e Perplexity. Detecte alucinações antes que elas prejudiquem sua reputação.
O que é Alucinação de IA: Definição, Causas e Impacto na Busca por IA
Saiba o que é alucinação de IA, por que ela acontece no ChatGPT, Claude e Perplexity, e como detectar informações falsas geradas por IA nos resultados de busca....
Saiba o que é o monitoramento de alucinações de IA, por que é essencial para a segurança da marca e como métodos de detecção como RAG, SelfCheckGPT e LLM-as-Jud...
A alucinação de IA ocorre quando LLMs geram informações falsas ou enganosas com confiança. Saiba o que causa alucinações, seu impacto no monitoramento de marca ...
11 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.