
Segmentando Sites Fonte de LLM para Backlinks
Aprenda a identificar e segmentar sites fonte de LLM para backlinks estratégicos. Descubra quais plataformas de IA mais citam fontes e otimize sua estratégia de...
11 min de leitura

Descubra como Modelos de Linguagem de Grande Porte selecionam e citam fontes através da ponderação de evidências, reconhecimento de entidades e dados estruturados. Conheça o processo de decisão de citação em 7 fases e otimize seu conteúdo para visibilidade em IA.
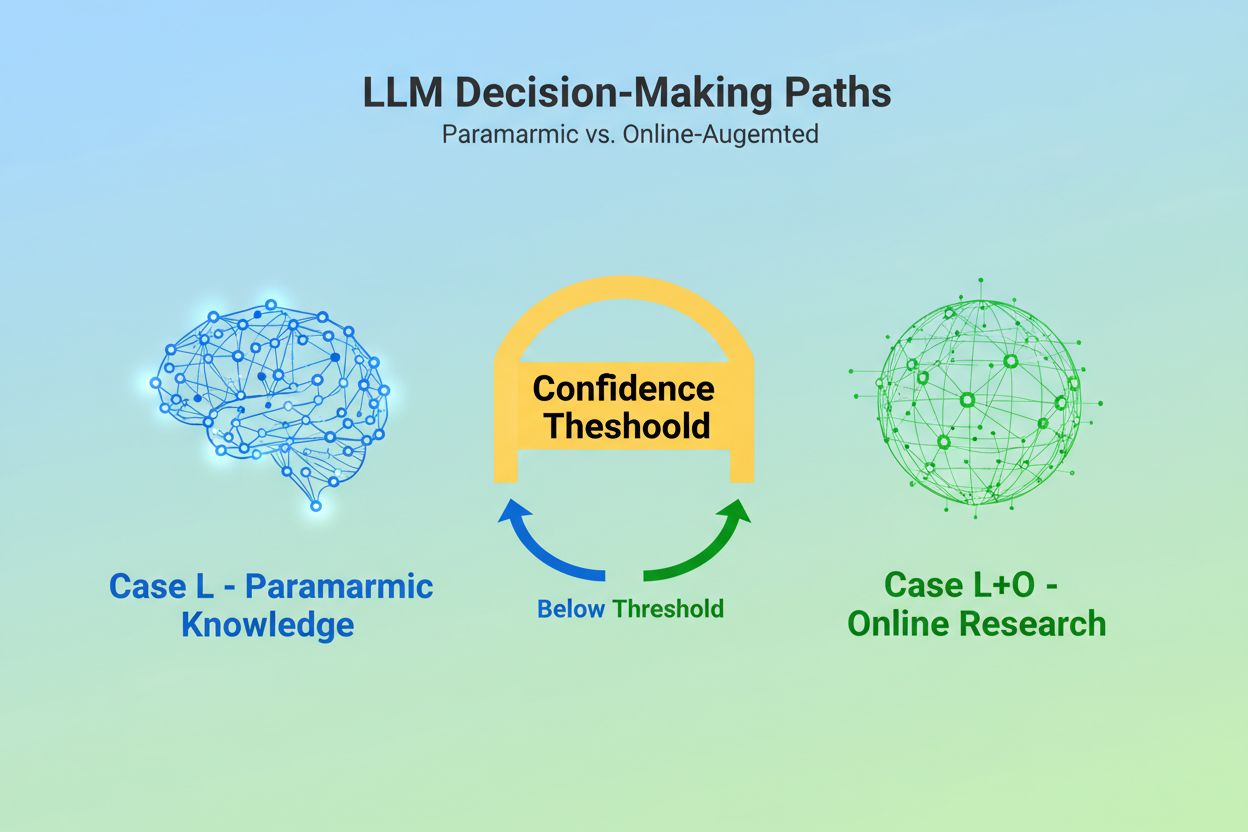
Quando um Modelo de Linguagem de Grande Porte recebe uma consulta, ele enfrenta uma decisão fundamental: deve confiar apenas no conhecimento incorporado durante o treinamento ou pesquisar na web por informações atuais? Essa escolha binária—o que pesquisadores chamam de Caso L (apenas dados de aprendizado) versus Caso L+O (dados de aprendizado mais pesquisa online)—determina se um LLM irá citar fontes ou não. No modo Caso L, o modelo utiliza exclusivamente sua base de conhecimento paramétrica, uma representação condensada de padrões aprendidos durante o treinamento, que normalmente reflete informações de vários meses a mais de um ano antes do lançamento do modelo. No modo Caso L+O, o modelo ativa um limiar de confiança que dispara a pesquisa externa, abrindo o que pesquisadores chamam de “espaço candidato” de URLs e fontes. Esse ponto de decisão é invisível para a maioria das ferramentas de monitoramento, mas é onde todo o mecanismo de citação começa—pois sem acionar a fase de busca, nenhuma fonte externa pode ser avaliada ou citada.
No momento em que um LLM decide buscar fontes externas, ele entra na fase mais crítica para a seleção de citações: a ponderação de evidências. É aqui que se faz a distinção entre mera menção e recomendação autoritativa. O modelo não simplesmente conta quantas vezes uma fonte aparece ou sua posição nos resultados de busca; ele avalia a integridade estrutural da própria evidência. Analisa a arquitetura do documento—se as fontes contêm relações de dados claras, identificadores recorrentes e links referenciados—interpretando esses elementos como sinais de confiabilidade. O modelo constrói o que pesquisadores chamam de “grafo de evidências”, onde nós representam entidades e arestas representam relações entre documentos. Cada fonte é ponderada não apenas pela relevância do conteúdo, mas por quão consistentemente fatos são confirmados em múltiplos documentos, quão relevante é a informação para o tema e quão autoritativo o domínio parece ser. Essa avaliação multidimensional cria o que se conhece como matriz de evidências, uma análise abrangente que determina quais fontes são confiáveis o suficiente para serem citadas. Criticamente, essa fase opera na camada de raciocínio do LLM, tornando-se invisível para ferramentas tradicionais de monitoramento GEO que medem apenas sinais de recuperação.
Dados estruturados—especialmente JSON-LD, marcação Schema.org e RDFa—agem como multiplicadores no processo de ponderação de evidências. Fontes que implementam dados estruturados adequados recebem peso 2 a 3 vezes maior na matriz de evidências em comparação a conteúdo não estruturado. Isso não ocorre porque LLMs preferem dados formatados esteticamente; acontece porque dados estruturados possibilitam a ligação de entidades, o processo de conectar menções em diferentes documentos por meio de identificadores legíveis por máquina como @id, sameAs e Q-IDs (identificadores do Wikidata). Quando um LLM encontra uma fonte com um Q-ID para uma organização, pode imediatamente verificar essa entidade em múltiplos documentos, criando o que pesquisadores chamam de “correferência de entidade entre documentos”. Esse processo de verificação aumenta drasticamente a confiança na confiabilidade da fonte.
| Formato de Dados | Precisão de Citação | Ligação de Entidade | Verificação Entre Documentos |
|---|---|---|---|
| Texto Não Estruturado | 62% | Nenhuma | Inferência manual |
| Marcação HTML Básica | 71% | Limitada | Correspondência parcial |
| RDFa/Microdata | 81% | Boa | Baseada em padrões |
| JSON-LD com Q-IDs | 94% | Excelente | Links verificados |
| Formato de Grafo de Conhecimento | 97% | Perfeita | Verificação automática |
O impacto dos dados estruturados opera em dois eixos temporais. Transitoriamente, quando um LLM busca online, ele lê JSON-LD e marcação Schema.org em tempo real, incorporando imediatamente essas informações estruturadas na ponderação de evidências para a resposta atual. Persistentemente, os dados estruturados que se mantêm consistentes ao longo do tempo são integrados à base de conhecimento paramétrica do modelo em ciclos futuros de treinamento, moldando como o modelo reconhece e avalia entidades mesmo sem pesquisa online. Esse duplo mecanismo significa que marcas que implementam dados estruturados adequados garantem tanto visibilidade imediata em citações quanto autoridade de longo prazo no espaço de conhecimento interno do modelo.
Antes que um LLM possa citar uma fonte, ele precisa primeiro entender sobre o quê essa fonte trata e quem ela representa. Esse é o trabalho do reconhecimento de entidades, um processo que transforma linguagem humana ambígua em entidades legíveis por máquina. Quando um documento menciona “Apple”, o LLM precisa determinar se refere-se à Apple Inc., à fruta, ou a outra coisa. O modelo realiza isso por meio de padrões de entidades treinados a partir da Wikipedia, Wikidata e Common Crawl, combinados com análise contextual do texto ao redor. No modo Caso L+O, esse processo se torna mais sofisticado: o modelo verifica entidades em dados estruturados externos, buscando atributos @id, links sameAs e Q-IDs que fornecem identificação definitiva. Essa etapa de verificação é essencial porque referências ambíguas ou inconsistentes de entidades se perdem no ruído do raciocínio do modelo. Uma marca que usa convenções de nomeação inconsistentes, não estabelece identificadores claros de entidades ou não implementa marcação Schema.org torna-se semanticamente obscura para a máquina—aparecendo como múltiplas entidades diferentes em vez de uma única fonte coesa. Por outro lado, organizações com entidades estáveis e referenciadas de forma consistente em múltiplos documentos são reconhecidas como nós confiáveis no grafo de conhecimento do LLM, aumentando significativamente a probabilidade de citação.
A jornada da consulta até a citação segue um processo estruturado de sete fases que pesquisadores mapearam por meio da análise do comportamento dos LLMs. Fase 0: Análise de Intenção começa quando o modelo tokeniza a entrada do usuário, realiza análise semântica e cria um vetor de intenção—uma representação abstrata do que realmente está sendo pedido. Essa fase determina quais tópicos, entidades e relações são relevantes a considerar. Fase 1: Recuperação Interna de Conhecimento acessa o conhecimento paramétrico do modelo e calcula uma pontuação de confiança. Se essa pontuação exceder um limiar, o modelo permanece no modo Caso L; caso contrário, prossegue para pesquisa externa. Fase 2: Geração de Consulta de Expansão (apenas Caso L+O) cria múltiplas consultas de busca semanticamente variadas—normalmente de 1 a 6 tokens—projetadas para abrir o espaço candidato de forma ampla. Fase 3: Extração de Evidências recupera URLs e trechos dos resultados de busca, analisando HTML e extraindo JSON-LD, RDFa e microdados. É aqui que os dados estruturados se tornam visíveis ao mecanismo de citação. Fase 4: Ligação de Entidades identifica entidades nos documentos recuperados e as verifica contra identificadores externos, criando um grafo temporário de conhecimento de relações. Fase 5: Ponderação de Evidências avalia a força das evidências de todas as fontes, considerando arquitetura do documento, diversidade de fontes, frequência de confirmação e coerência entre fontes. Fase 6: Raciocínio e Síntese combina evidências internas e externas, resolve contradições e determina se cada fonte merece menção ou recomendação. Fase 7: Construção da Resposta Final traduz a evidência ponderada para linguagem natural, integrando citações onde apropriado. Cada fase alimenta a próxima, com ciclos de feedback permitindo ao modelo refinar a busca ou reavaliar evidências caso surjam inconsistências.
Os LLMs modernos utilizam cada vez mais a Geração Aumentada por Recuperação (RAG), uma técnica que muda fundamentalmente como as citações são selecionadas e justificadas. Em vez de confiar apenas no conhecimento paramétrico, sistemas RAG recuperam ativamente documentos relevantes, extraem evidências e fundamentam as respostas em fontes específicas. Essa abordagem transforma a citação de um subproduto implícito do treinamento em um processo explícito e rastreável. Implementações RAG normalmente usam busca híbrida, combinando recuperação baseada em palavras-chave com busca por similaridade vetorial para maximizar o recall. Uma vez recuperados os documentos candidatos, o ranqueamento semântico reavalia os resultados com base no significado, não apenas na correspondência de palavras, garantindo que as fontes mais relevantes se destaquem. Esse mecanismo explícito de recuperação torna o processo de citação mais transparente e auditável—cada fonte citada pode ser rastreada até passagens específicas que justificaram sua inclusão. Para organizações que monitoram sua visibilidade em IA, sistemas baseados em RAG são especialmente importantes porque criam padrões de citação mensuráveis. Ferramentas como o AmICited acompanham como sistemas RAG referenciam sua marca em diferentes plataformas de IA, fornecendo insights sobre se você aparece como fonte citada ou apenas como material de apoio na fase de recuperação de evidências.
Nem todas as citações são iguais. Um LLM pode mencionar uma fonte como contexto de fundo enquanto recomenda outra como evidência autoritativa—e essa distinção é determinada inteiramente pela ponderação de evidências, não pelo sucesso na recuperação. Uma fonte pode aparecer no espaço candidato (Fases 2-3), mas não alcançar status de recomendação se sua pontuação de evidência for insuficiente. Essa separação entre menção e recomendação é onde métricas GEO tradicionais falham. Ferramentas padrão de monitoramento medem a expansão—seu conteúdo aparece nos resultados de busca—mas não podem medir se o LLM realmente considera seu conteúdo confiável a ponto de recomendar. Uma menção pode soar como “Algumas fontes sugerem…”, enquanto uma recomendação diz “De acordo com [Fonte], as evidências mostram…”. A diferença está na pontuação da matriz de evidências na Fase 5. Fontes com Q-IDs consistentes, arquitetura documental bem estruturada e confirmação em múltiplas fontes independentes alcançam status de recomendação. Fontes com referências ambíguas de entidades, baixa coerência estrutural ou afirmações isoladas permanecem como menções. Para marcas, essa distinção é crítica: ser recuperado não é o mesmo que ser citado como autoridade. O caminho da recuperação à recomendação exige clareza semântica, integridade estrutural e densidade de evidências—fatores que a otimização tradicional de SEO não aborda.
Entender como LLMs selecionam fontes traz implicações imediatas e práticas para a estratégia de conteúdo. Primeiro, implemente marcação Schema.org de forma consistente em seu site, especialmente para informações organizacionais, artigos e entidades-chave. Use formato JSON-LD com atributos @id apropriados e links sameAs para Wikidata, Wikipedia ou outras fontes autoritativas. Esses dados estruturados aumentam diretamente seu peso de evidência na Fase 5. Segundo, estabeleça identificadores claros de entidades para sua organização, produtos e conceitos principais. Use convenções de nomenclatura consistentes, evite abreviações que geram ambiguidade e conecte entidades relacionadas por relações hierárquicas (isPartOf, about, mentions). Terceiro, crie evidências legíveis por máquina publicando dados estruturados sobre suas afirmações, credenciais e relações. Não escreva apenas “Somos o principal fornecedor de X”—estruture essa afirmação com dados de apoio, citações e relações verificáveis. Quarto, mantenha consistência de conteúdo entre múltiplas plataformas e ao longo do tempo. LLMs avaliam densidade de evidências checando se afirmações são confirmadas em fontes independentes; afirmações isoladas em uma única plataforma têm menos peso. Quinto, entenda que métricas tradicionais de SEO não preveem citação em IA. Altos rankings de busca não garantem recomendações por LLMs; foque em clareza semântica e integridade estrutural. Sexto, monitore seus padrões de citação usando ferramentas como o AmICited, que rastreiam como diferentes sistemas de IA referenciam sua marca. Isso revela se você está atingindo status de menção ou recomendação, e quais tipos de conteúdo geram citações. Por fim, reconheça que visibilidade em IA é um investimento de longo prazo. Os dados estruturados que você implementar hoje influenciam tanto a probabilidade imediata de citação (efeito transitório) quanto a base de conhecimento interna do modelo em ciclos futuros de treinamento (efeito persistente).
À medida que os LLMs evoluem, os mecanismos de citação estão se tornando cada vez mais sofisticados e transparentes. Modelos futuros provavelmente implementarão grafos de citação—mapeamentos explícitos mostrando não apenas quais fontes foram citadas, mas como elas influenciaram afirmações específicas na resposta. Alguns sistemas avançados já estão experimentando pontuações probabilísticas de confiança associadas às citações, indicando o quão certo o modelo está sobre a relevância e confiabilidade da fonte. Outra tendência emergente é a verificação com participação humana, na qual usuários podem desafiar citações e fornecer feedback que refina a ponderação de evidências do modelo em consultas futuras. A integração de dados estruturados aos ciclos de treinamento significa que organizações que constroem infraestrutura semântica adequada hoje estão, na prática, solidificando sua autoridade de longo prazo em sistemas de IA. Diferente do ranking em motores de busca, que pode oscilar com atualizações de algoritmo, o efeito persistente dos dados estruturados cria uma base mais estável para visibilidade em IA. Essa mudança da visibilidade tradicional (ser encontrado) para a autoridade semântica (ser confiável) representa uma mudança fundamental em como marcas devem abordar a comunicação digital. Os vencedores neste novo cenário não serão aqueles com mais conteúdo ou melhores posições na busca, mas sim os que estruturarem suas informações de modo que as máquinas possam entender, verificar e recomendar de forma confiável.
O Caso L utiliza apenas dados de treinamento da base de conhecimento paramétrica do modelo, enquanto o Caso L+O complementa com pesquisa web em tempo real. O limiar de confiança do modelo determina qual caminho é seguido. Essa distinção é crucial porque define se fontes externas poderão ser avaliadas e citadas ou não.
A ponderação de evidências determina essa distinção. Fontes com dados estruturados, identificadores consistentes e confirmação cruzada em documentos são elevadas a 'recomendações' em vez de meras menções. Uma fonte pode aparecer em resultados de busca, mas não alcançar status de recomendação se sua pontuação de evidência for insuficiente.
Dados estruturados (JSON-LD, @id, sameAs, Q-IDs) recebem peso 2 a 3 vezes maior nas matrizes de evidência. Essa marcação permite ligação de entidades e verificação cruzada de documentos, aumentando drasticamente a pontuação de confiabilidade da fonte. Fontes com implementação adequada de Schema.org têm muito mais chance de serem citadas como autoritativas.
Reconhecimento de entidades é como os LLMs identificam e distinguem diferentes entidades (organizações, pessoas, conceitos). Identificação clara de entidades por nomenclatura consistente e identificadores estruturados evita confusão e aumenta a probabilidade de citação. Referências ambíguas de entidades se perdem no raciocínio do modelo.
Sistemas RAG recuperam e classificam fontes em tempo real, tornando a seleção de citações mais transparente e baseada em evidências do que pura base paramétrica. Esse mecanismo explícito de recuperação cria padrões de citação mensuráveis que podem ser acompanhados e analisados com ferramentas como o AmICited.
Sim. Implemente marcação Schema.org de forma consistente, estabeleça identificadores claros de entidades, crie evidências legíveis por máquina, mantenha consistência de conteúdo entre plataformas e monitore seus padrões de citação. Esses fatores influenciam diretamente se seu conteúdo alcançará status de menção ou recomendação nas respostas dos LLMs.
A visibilidade tradicional mede alcance e posicionamento nos resultados de busca. A visibilidade em IA mede se seu conteúdo é reconhecido como evidência autoritativa nos processos de raciocínio dos LLMs. Ser recuperado não é o mesmo que ser citado como confiável — o último exige clareza semântica e integridade estrutural.
O AmICited acompanha como sistemas de IA referenciam sua marca em GPTs, Perplexity e Google AI Overviews. Revela se você está alcançando status de menção ou recomendação, quais tipos de conteúdo geram citações e como seus padrões de citação se comparam entre diferentes plataformas de IA.
Entenda como os LLMs referenciam sua marca no ChatGPT, Perplexity e Google AI Overviews. Acompanhe padrões de citação e otimize sua visibilidade em IA com o AmICited.
Aprenda a identificar e segmentar sites fonte de LLM para backlinks estratégicos. Descubra quais plataformas de IA mais citam fontes e otimize sua estratégia de...

Descubra como grounding em LLMs e busca na web permitem que sistemas de IA acessem informações em tempo real, reduzam alucinações e forneçam citações precisas. ...

Descubra o que é LLMO, como funciona e por que é importante para a visibilidade em IA. Conheça técnicas de otimização para fazer sua marca aparecer no ChatGPT, ...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.