Query Fanout
Saiba como funciona o Query Fanout em sistemas de busca por IA. Descubra como a IA expande consultas únicas em múltiplas subconsultas para melhorar a precisão d...
12 min de leitura
Descubra como sistemas modernos de IA como o Google AI Mode e o ChatGPT decompõem uma única consulta em múltiplas buscas. Aprenda os mecanismos de fanout de consulta, implicações para visibilidade em IA e otimização de estratégia de conteúdo.
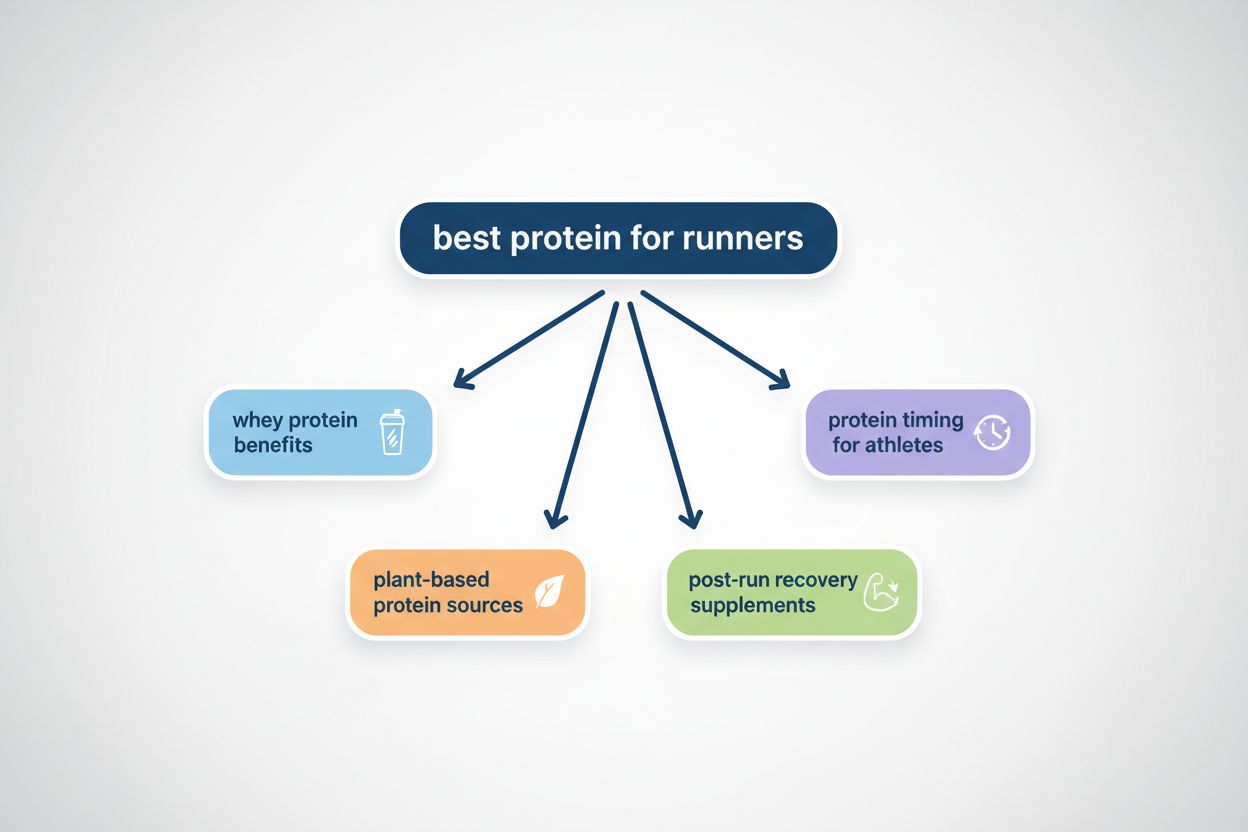
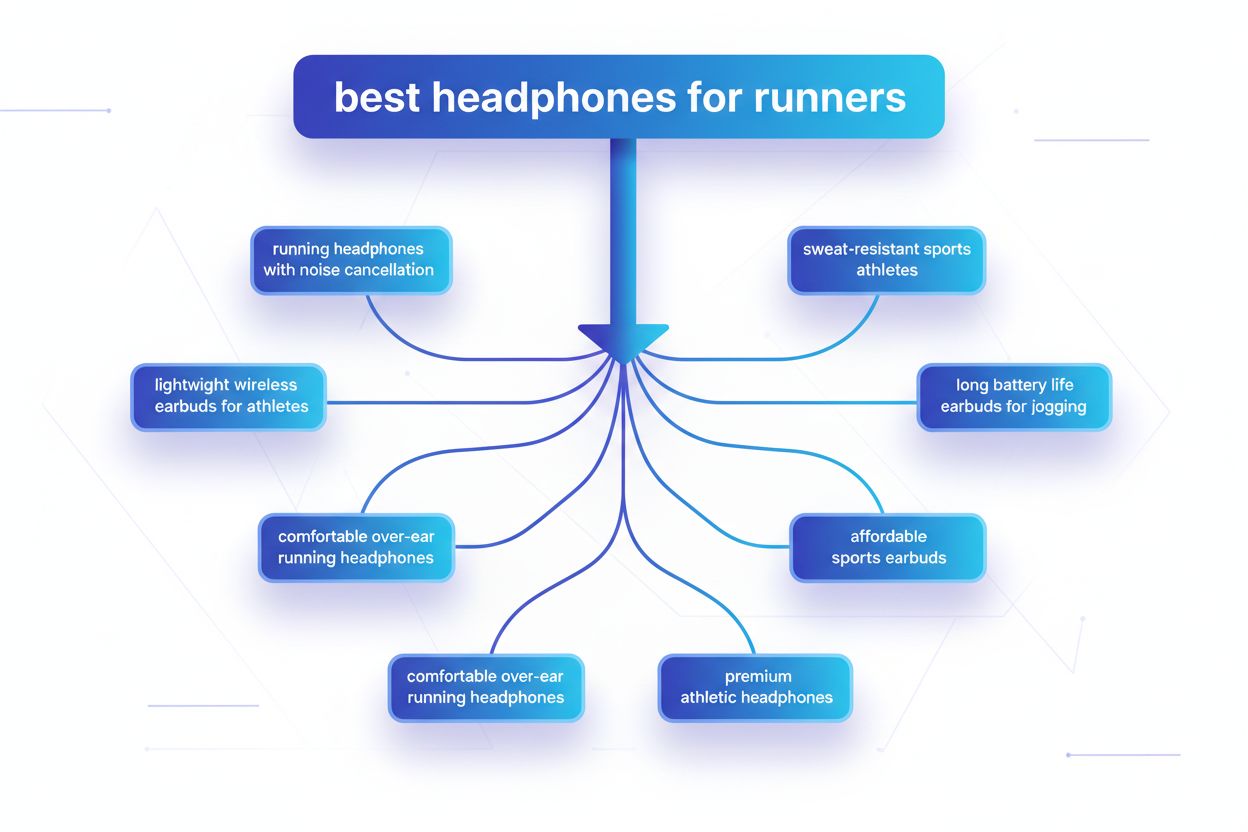
Fanout de consulta é o processo pelo qual grandes modelos de linguagem dividem automaticamente uma única consulta do usuário em múltiplas subconsultas para coletar informações mais abrangentes de fontes diversas. Em vez de executar uma única busca, sistemas modernos de IA decompõem a intenção do usuário em 5 a 15 consultas relacionadas que capturam diferentes ângulos, interpretações e aspectos do pedido original. Por exemplo, quando um usuário busca “melhores fones de ouvido para corredores” no AI Mode do Google, o sistema gera aproximadamente 8 buscas diferentes, incluindo variações como “fones de ouvido para corrida com cancelamento de ruído”, “fones de ouvido sem fio leves para atletas”, “fones de ouvido esportivos resistentes ao suor” e “fones de ouvido com bateria longa para corrida”. Isso representa uma mudança fundamental em relação à busca tradicional, onde uma única string de consulta é comparada a um índice. As principais características do fanout de consulta incluem:
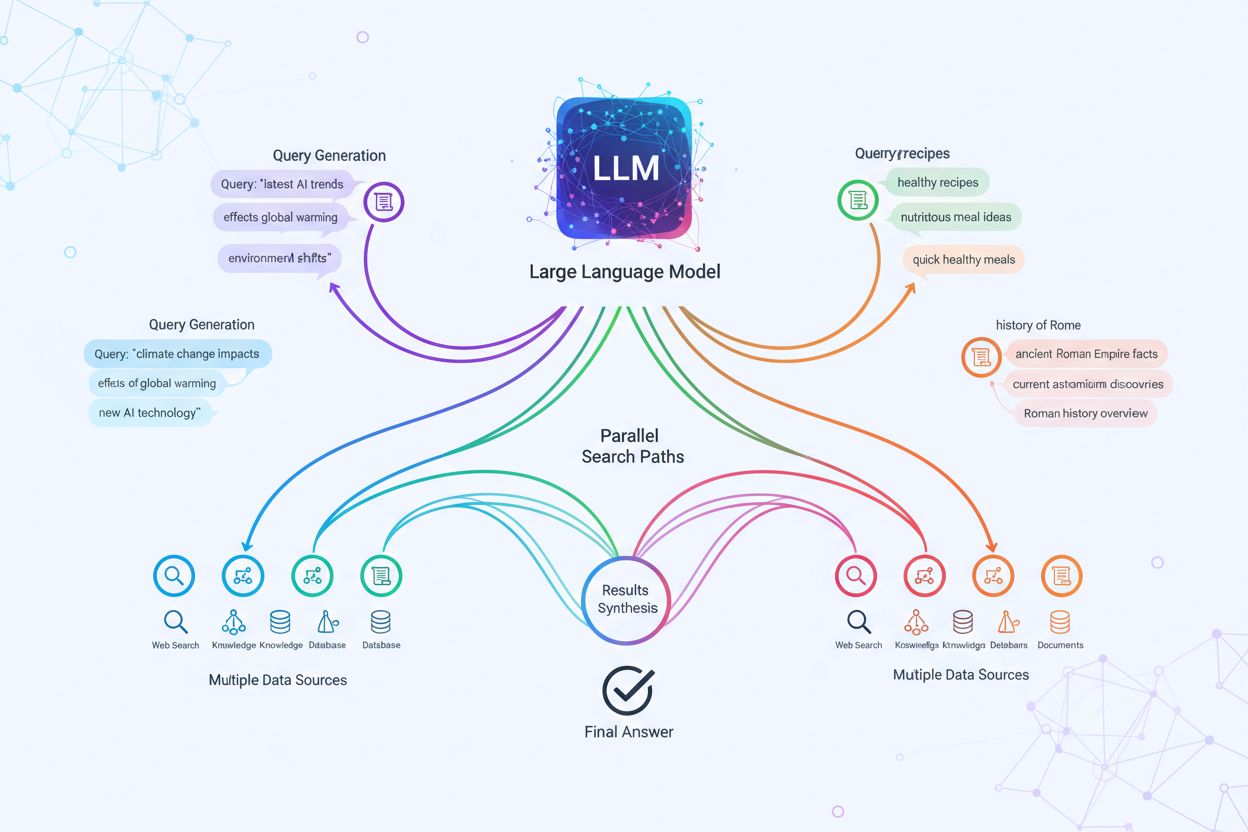
A implementação técnica do fanout de consulta depende de algoritmos avançados de PLN que analisam a complexidade da consulta e geram variantes semanticamente relevantes. LLMs produzem oito tipos principais de variantes: consultas equivalentes (reformulações com significado idêntico), consultas de acompanhamento (explorando temas relacionados), consultas de generalização (ampliando o escopo), consultas de especificação (afunilando o foco), consultas de canonização (padronizando termos), consultas de tradução (convertendo entre domínios), consultas de implicação (explorando consequências lógicas) e consultas de esclarecimento (desambiguando termos ambíguos). O sistema utiliza modelos neurais de linguagem para avaliar a complexidade da consulta—medindo fatores como quantidade de entidades, densidade de relações e ambiguidade semântica—para determinar quantas subconsultas gerar. Uma vez geradas, essas consultas são executadas em paralelo em múltiplos sistemas de recuperação, incluindo crawlers web, grafos de conhecimento (como o Knowledge Graph do Google), bancos de dados estruturados e índices vetoriais de similaridade. Diferentes plataformas implementam essa arquitetura com níveis variados de transparência e sofisticação:
| Plataforma | Mecanismo | Transparência | Nº de Consultas | Método de Ranqueamento |
|---|---|---|---|---|
| Google AI Mode | Fanout explícito com consultas visíveis | Alta | 8-12 consultas | Ranqueamento em múltiplas etapas |
| Microsoft Copilot | Orquestrador Bing iterativo | Média | 5-8 consultas | Pontuação de relevância |
| Perplexity | Recuperação híbrida com ranqueamento em múltiplas etapas | Alta | 6-10 consultas | Baseado em citação |
| ChatGPT | Geração implícita de consultas | Baixa | Desconhecido | Ponderação interna |
Consultas complexas passam por decomposição sofisticada, onde o sistema as divide em entidades, atributos e relações antes de gerar variantes. Ao processar uma consulta como “fones de ouvido Bluetooth com design confortável over-ear e bateria de longa duração para corredores”, o sistema realiza um entendimento centrado em entidades, identificando entidades-chave (fones de ouvido Bluetooth, corredores) e extraindo atributos críticos (confortável, over-ear, bateria longa). O processo de decomposição utiliza grafos de conhecimento para entender como essas entidades se relacionam e quais variações semânticas existem—reconhecendo que “fones de ouvido over-ear” e “fones circumaurais” são equivalentes, ou que “bateria de longa duração” pode significar 8+ horas, 24+ horas ou autonomia de vários dias, dependendo do contexto. O sistema identifica conceitos relacionados por medidas de similaridade semântica, entendendo que consultas sobre “resistência ao suor” e “resistência à água” são relacionadas, mas distintas, e que “corredores” também podem se interessar por “ciclistas”, “frequentadores de academia” ou “atletas ao ar livre”. Essa decomposição permite gerar subconsultas direcionadas que capturam diferentes facetas da intenção do usuário, em vez de apenas reformular o pedido original.
O fanout de consulta fortalece fundamentalmente o componente de recuperação nos frameworks de Retrieval-Augmented Generation (RAG), permitindo uma coleta de evidências mais rica e diversa antes da geração. Em pipelines RAG tradicionais, uma única consulta é embutida e comparada a um banco vetorial, podendo perder informações relevantes que usam terminologias ou conceitos diferentes. O fanout de consulta resolve essa limitação executando múltiplas operações de recuperação em paralelo, cada uma otimizada para uma variante específica, reunindo evidências de vários ângulos e fontes. Essa estratégia de recuperação paralela reduz fortemente o risco de alucinações ao fundamentar as respostas dos LLMs em múltiplas fontes independentes—quando o sistema recupera informações sobre “fones over-ear”, “designs circumaurais” e “fones de tamanho completo” separadamente, pode cruzar e validar afirmações entre esses resultados diversos. A arquitetura incorpora chunking semântico e recuperação baseada em passagens, onde documentos são divididos em unidades semânticas significativas em vez de blocos de tamanho fixo, permitindo recuperar os trechos mais relevantes independentemente da estrutura do documento. Ao combinar evidências de múltiplas subconsultas, sistemas RAG produzem respostas mais abrangentes, fundamentadas e menos propensas a respostas confiantes, porém incorretas, comuns em abordagens de consulta única.
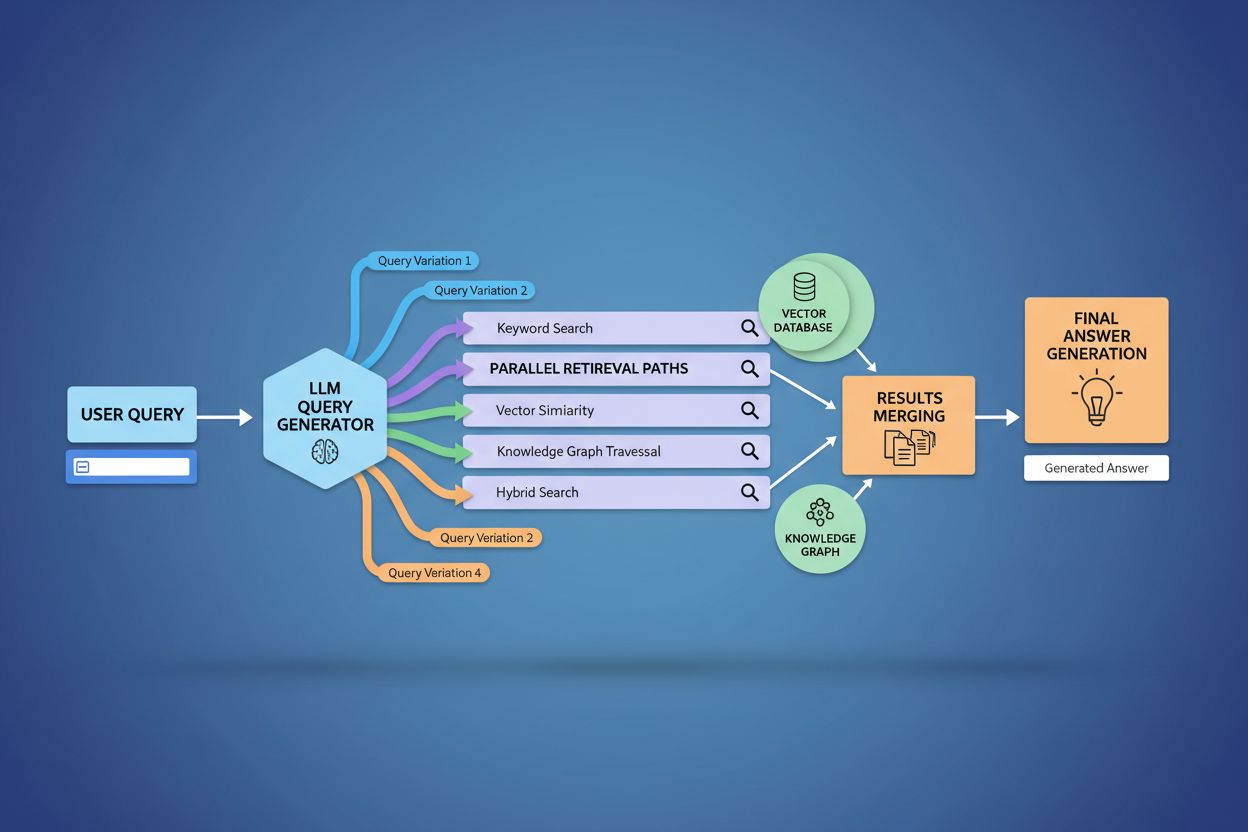
O contexto do usuário e sinais de personalização moldam dinamicamente como o fanout de consulta expande pedidos individuais, criando caminhos de recuperação que podem divergir significativamente de um usuário para outro. O sistema incorpora múltiplas dimensões de personalização, incluindo atributos do usuário (localização geográfica, perfil demográfico, papel profissional), padrões de histórico de busca (consultas anteriores e resultados clicados), sinais temporais (hora do dia, estação, eventos atuais) e contexto da tarefa (se o usuário está pesquisando, comprando ou aprendendo). Por exemplo, uma consulta sobre “melhores fones para corredores” se expande de modo diferente para um atleta de ultramaratona de 22 anos no Quênia versus um corredor recreativo de 45 anos em Minnesota—a expansão do primeiro pode enfatizar durabilidade e resistência ao calor, enquanto a do segundo enfatiza conforto e acessibilidade. Contudo, essa personalização introduz o problema da “transformação em dois pontos”, onde o sistema trata consultas atuais como variações de padrões históricos, podendo restringir a exploração e reforçar preferências pré-existentes. A personalização pode criar bolhas de filtro, onde a expansão sistematicamente favorece fontes e perspectivas alinhadas ao histórico do usuário, limitando a exposição a pontos de vista alternativos ou informações emergentes. Compreender esses mecanismos é fundamental para criadores de conteúdo, já que o mesmo material pode ou não ser recuperado dependendo do perfil e histórico do usuário.
Grandes plataformas de IA implementam o fanout de consulta com arquiteturas, níveis de transparência e abordagens estratégicas muito diferentes, refletindo suas infraestruturas e filosofias de design. O AI Mode do Google emprega fanout explícito e visível, onde usuários podem ver as 8-12 subconsultas geradas exibidas junto aos resultados, disparando centenas de buscas individuais no índice do Google para reunir evidências abrangentes. O Microsoft Copilot usa uma abordagem iterativa, alimentada pelo Bing Orchestrator, que gera 5-8 consultas sequencialmente, refinando o conjunto com base em resultados intermediários antes da fase final de recuperação. O Perplexity implementa uma estratégia híbrida, gerando 6-10 consultas e as executando tanto em fontes web quanto em seu próprio índice, depois aplicando algoritmos sofisticados para destacar os trechos mais relevantes. A abordagem do ChatGPT permanece amplamente opaca ao usuário, com a geração de consultas ocorrendo implicitamente no processamento interno do modelo, tornando difícil saber quantas consultas são geradas ou como são executadas. Essas diferenças arquiteturais têm implicações importantes para transparência, reprodutibilidade e a capacidade de criadores de conteúdo otimizarem para cada plataforma:
| Aspecto | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Visibilidade das Consultas | Totalmente visível ao usuário | Parcialmente visível | Visível nas citações | Oculta |
| Modelo de Execução | Lote paralelo | Iterativo sequencial | Paralelo com ranqueamento | Interno/implícito |
| Diversidade de Fontes | Apenas índice do Google | Bing + proprietário | Web + índice proprietário | Dados de treino + plugins |
| Transparência de Citações | Alta | Média | Muito alta | Baixa |
| Opções de Customização | Limitada | Média | Alta | Média |
O fanout de consulta introduz desafios técnicos e semânticos que podem levar o sistema a divergir da intenção real do usuário, recuperando informações relacionadas mas não úteis. O desvio semântico ocorre na expansão generativa quando o LLM cria variantes que, embora semanticamente próximas, deslocam gradualmente o significado—uma consulta por “melhores fones para corredores” pode expandir para “fones atléticos”, depois “equipamentos esportivos”, depois “acessórios fitness”, afastando-se da intenção original. O sistema deve distinguir entre intenção latente (o que o usuário poderia querer se soubesse mais) e intenção explícita (o que ele realmente pediu), e uma expansão agressiva pode confundir essas categorias, recuperando informações sobre produtos que o usuário nunca quis considerar. O desvio por expansão iterativa ocorre quando cada consulta gera subconsultas adicionais, criando uma árvore de buscas cada vez mais tangenciais que coletivamente recuperam informações muito distantes do pedido inicial. Bolhas de filtro e viés de personalização significam que dois usuários fazendo perguntas idênticas recebem expansões sistematicamente diferentes com base em seus perfis, potencialmente criando câmaras de eco onde cada expansão reforça preferências existentes. Exemplos práticos ilustram essas armadilhas: um usuário buscando “fones acessíveis” pode ter sua consulta expandida para incluir marcas de luxo com base em seu histórico de navegação, ou uma busca por “fones para deficientes auditivos” pode ser expandida para produtos de acessibilidade geral, diluindo a especificidade da intenção original.
A ascensão do fanout de consulta muda fundamentalmente a estratégia de conteúdo da otimização por ranking de palavras-chave para visibilidade por citações, exigindo uma reestruturação de como a informação é apresentada. O SEO tradicional focava em ranquear para palavras-chave específicas; a busca por IA prioriza ser citado como fonte autorizada em múltiplas variantes e contextos. Criadores de conteúdo devem adotar estratégias atômicas e ricas em entidades, estruturando a informação em torno de entidades específicas (produtos, conceitos, pessoas) com marcação semântica que permita aos sistemas de IA extrair e citar trechos relevantes. Clusterização de tópicos e autoridade topical tornam-se ainda mais importantes—em vez de artigos isolados para cada palavra-chave, o conteúdo bem-sucedido cobre áreas temáticas de forma abrangente, aumentando a chance de ser recuperado nas diversas variantes geradas pelo fanout. Implementação de schema e dados estruturados permite que sistemas de IA entendam a estrutura do conteúdo e extraiam informações com mais eficácia, aumentando as chances de citação. As métricas de sucesso passam a ser a frequência de citações, monitoradas por ferramentas como o AmICited.com, que acompanha quantas vezes marcas e conteúdos aparecem em respostas de IA. Boas práticas incluem: criar conteúdos completos e bem fundamentados que abordem vários ângulos de um tema; implementar marcação de schema rica (Organization, Product, Article schemas); construir autoridade tópica com conteúdos interconectados; e auditar regularmente como seu conteúdo aparece em respostas de IA em diferentes plataformas e segmentos de usuários.
O fanout de consulta representa a mudança arquitetural mais significativa na busca desde o index mobile-first, reestruturando fundamentalmente como a informação é descoberta e apresentada aos usuários. A evolução rumo à infraestrutura semântica significa que sistemas de busca operarão cada vez mais com base no significado, não em palavras-chave, com o fanout tornando-se padrão na recuperação de informações. Métricas de citação tornam-se tão importantes quanto backlinks na definição de visibilidade e autoridade—um conteúdo citado em 50 respostas de IA diferentes tem mais peso do que um que ranqueia em primeiro para uma palavra-chave. Essa mudança traz desafios e oportunidades: ferramentas tradicionais de SEO que acompanham rankings perdem relevância, exigindo novas métricas focadas em frequência de citação, diversidade de fontes e presença em diferentes variantes. Por outro lado, abre-se espaço para marcas otimizarem especificamente para busca em IA, criando conteúdo autoritativo e bem estruturado que sirva como fonte confiável em múltiplas interpretações de consulta. O futuro provavelmente trará mais transparência sobre mecanismos de fanout, com plataformas competindo por clareza ao mostrar ao usuário o raciocínio por trás da abordagem multi-consulta, e criadores de conteúdo desenvolvendo estratégias especializadas para maximizar a visibilidade nos diversos caminhos de recuperação que o fanout proporciona.
Fanout de consulta é o processo automatizado em que sistemas de IA decompõem uma única consulta do usuário em múltiplas subconsultas e as executam em paralelo, enquanto expansão de consulta tradicionalmente refere-se a adicionar termos relacionados a uma única consulta. O fanout de consulta é mais sofisticado, gerando variantes semanticamente diversas que capturam diferentes ângulos e interpretações da intenção original.
O fanout de consulta impacta significativamente a visibilidade porque seu conteúdo precisa ser encontrável em múltiplas variantes de consulta, não apenas na consulta exata do usuário. Conteúdos que abordam diferentes ângulos, usam terminologias variadas e são bem estruturados com marcação de schema têm mais chances de serem recuperados e citados nas diversas subconsultas geradas pelo fanout.
Todas as principais plataformas de busca por IA usam mecanismos de fanout de consulta: o Google AI Mode usa fanout explícito e visível (8-12 consultas); o Microsoft Copilot usa fanout iterativo via Bing Orchestrator; o Perplexity implementa recuperação híbrida com ranqueamento em múltiplas etapas; e o ChatGPT usa geração implícita de consultas. Cada plataforma implementa de forma diferente, mas todas decompõem consultas complexas em múltiplas buscas.
Sim. Otimize criando conteúdo atômico, rico em entidades e estruturado em torno de conceitos específicos; implementando marcação de schema abrangente; construindo autoridade tópica através de conteúdos interconectados; usando terminologia clara e variada; e abordando múltiplos ângulos de um tema. Ferramentas como o AmICited.com ajudam você a monitorar como seu conteúdo aparece em diferentes decomposições de consulta.
O fanout de consulta aumenta a latência porque múltiplas consultas são executadas em paralelo, mas sistemas modernos mitigam isso por meio de processamento paralelo. Enquanto uma única consulta pode levar 200ms, executar 8 consultas em paralelo normalmente adiciona apenas 300-500ms de latência total devido à execução concorrente. O equilíbrio compensa pela melhora na qualidade das respostas.
Fanout de consulta fortalece o Retrieval-Augmented Generation (RAG) ao permitir uma coleta de evidências mais rica. Em vez de recuperar documentos para uma única consulta, o fanout recupera evidências para múltiplas variantes em paralelo, fornecendo ao LLM um contexto mais diverso e abrangente para gerar respostas precisas e reduzir o risco de alucinações.
A personalização molda como as consultas são decompostas com base em atributos do usuário (localização, histórico, demografia), sinais temporais e contexto da tarefa. A mesma consulta se expande de forma diferente para usuários distintos, criando caminhos de recuperação personalizados. Isso pode aumentar a relevância, mas também criar bolhas de filtro onde usuários veem resultados sistematicamente diferentes baseados em seus perfis.
O fanout de consulta representa a mudança mais significativa na busca desde o index mobile-first. Métricas tradicionais de ranqueamento de palavras-chave tornam-se menos relevantes, já que a mesma consulta se expande de modo diferente para cada usuário. Profissionais de SEO devem focar menos em rankings e mais em visibilidade por citações, estrutura de conteúdo e otimização de entidades para ter sucesso na busca orientada por IA.
Entenda como sua marca aparece nas plataformas de busca por IA quando as consultas são expandidas e decompostas. Acompanhe citações e menções em respostas geradas por IA.
Saiba como funciona o Query Fanout em sistemas de busca por IA. Descubra como a IA expande consultas únicas em múltiplas subconsultas para melhorar a precisão d...
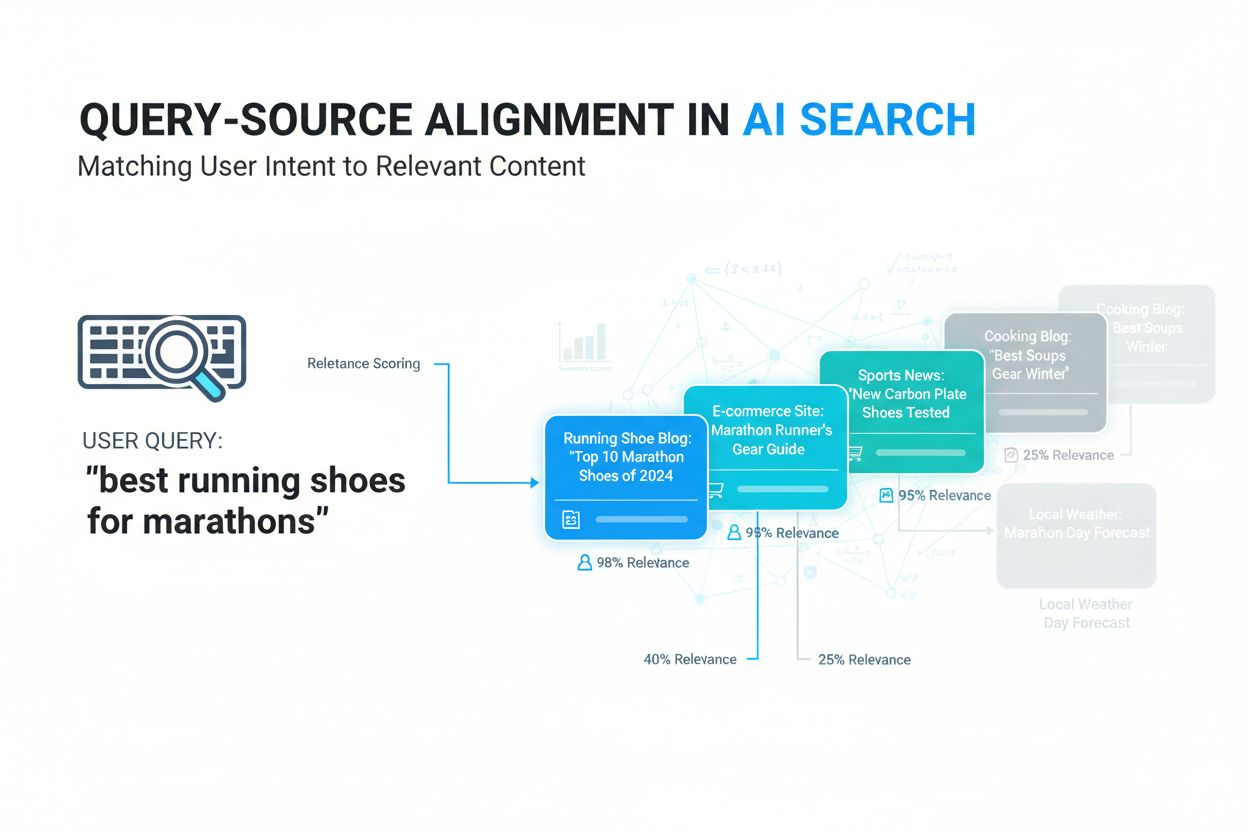
Saiba o que é alinhamento consulta-fonte, como sistemas de IA conectam consultas dos usuários a fontes relevantes e por que isso é importante para a visibilidad...
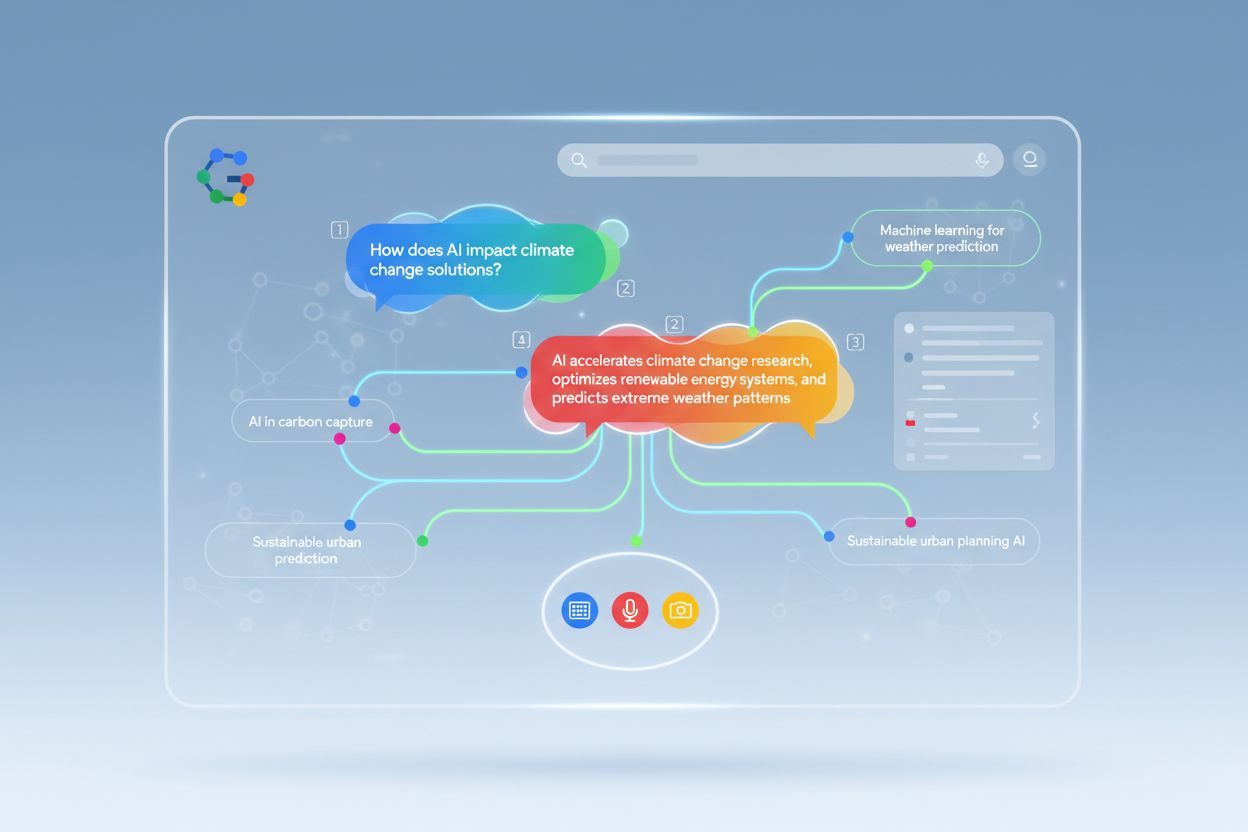
Descubra como o Modo de IA do Google está transformando os resultados de busca, impactando o tráfego de sites e o que você precisa fazer para manter a visibilid...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.