Rastreie a Atividade de Crawlers de IA: Guia Completo de Monitoramento
Aprenda como rastrear e monitorar a atividade de crawlers de IA em seu site usando logs de servidor, ferramentas e melhores práticas. Identifique GPTBot, ClaudeBot e outros bots de IA.
Publicado em Jan 3, 2026.Última modificação em Jan 3, 2026 às 3:24 am
Bots de inteligência artificial já respondem por mais de 51% do tráfego global da internet, mas a maioria dos proprietários de sites não faz ideia de que eles estão acessando seu conteúdo. Ferramentas tradicionais de análise, como o Google Analytics, não detectam esses visitantes porque crawlers de IA evitam acionar códigos de rastreamento baseados em JavaScript. Os logs do servidor capturam 100% das requisições de bots, tornando-se a única fonte confiável para entender como sistemas de IA interagem com seu site. Compreender o comportamento dos bots é fundamental para a visibilidade em IA, pois se os crawlers de IA não acessarem seu conteúdo corretamente, ele não aparecerá em respostas geradas por IA quando potenciais clientes fizerem perguntas relevantes.
Entendendo os Diferentes Tipos de Crawlers de IA
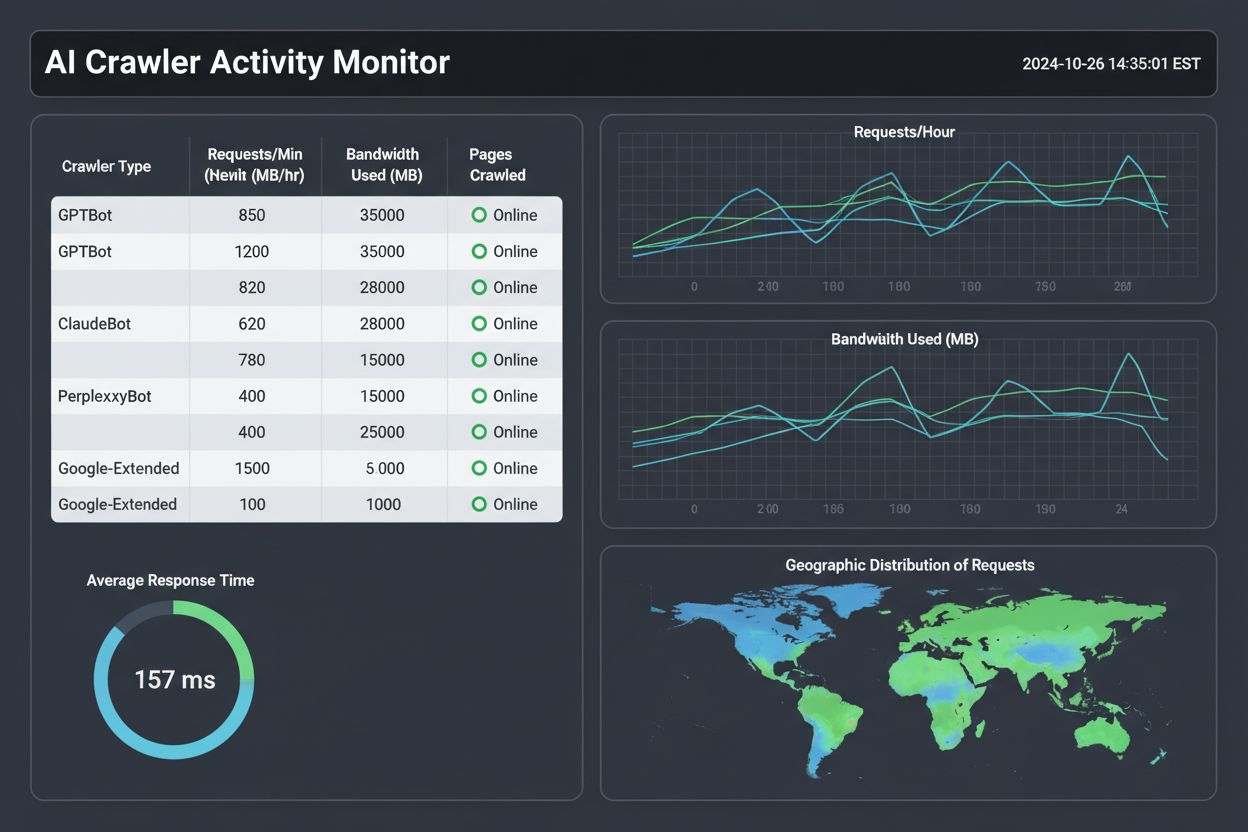
Crawlers de IA se comportam de maneira fundamentalmente diferente dos bots tradicionais de mecanismos de busca. Enquanto o Googlebot segue seu sitemap XML, respeita as regras do robots.txt e rastreia regularmente para atualizar os índices de pesquisa, bots de IA podem ignorar protocolos padrão, visitar páginas para treinar modelos de linguagem e usar identificadores personalizados. Os principais crawlers de IA incluem GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (bot de treinamento de IA do Google), Bingbot-AI (Microsoft) e Applebot-Extended (Apple). Esses bots focam em conteúdo que auxilia a responder perguntas dos usuários, e não apenas em sinais de ranqueamento, tornando seus padrões de rastreamento imprevisíveis e frequentemente agressivos. Entender quais bots visitam seu site e como se comportam é essencial para otimizar sua estratégia de conteúdo na era da IA.
Tipo de Crawler
RPS Típico
Comportamento
Finalidade
Googlebot
1-5
Constante, respeita crawl-delay
Indexação de busca
GPTBot
5-50
Padrões em rajada, alto volume
Treinamento de modelo de IA
ClaudeBot
3-30
Acesso direcionado a conteúdo
Treinamento de IA
PerplexityBot
2-20
Rastreamento seletivo
Busca com IA
Google-Extended
5-40
Agressivo, focado em IA
Treinamento de IA do Google
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Seu servidor web (Apache, Nginx ou IIS) gera automaticamente logs que registram todas as requisições ao seu site, incluindo as de bots de IA. Esses logs contêm informações cruciais: endereços IP mostrando a origem das requisições, user agents identificando o software que faz as requisições, timestamps registrando quando as requisições ocorreram, URLs requisitadas mostrando o conteúdo acessado e códigos de resposta indicando as respostas do servidor. Você pode acessar os logs via FTP ou SSH conectando-se ao seu servidor de hospedagem e navegando até o diretório de logs (tipicamente /var/log/apache2/ para Apache ou /var/log/nginx/ para Nginx). Cada entrada de log segue um formato padrão que revela exatamente o que aconteceu em cada requisição.
Veja um exemplo de entrada de log com explicação dos campos:
192.168.1.100 - - [01/Jan/2025:12:00:00 +0000] "GET /blog/ai-crawlers HTTP/1.1" 200 5432 "-" "Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot)"
Endereço IP: 192.168.1.100
User Agent: GPTBot/1.0 (identifica o bot)
Timestamp: 01/Jan/2025:12:00:00
Requisição: GET /blog/ai-crawlers (página acessada)
Código de Status: 200 (requisição bem-sucedida)
Tamanho da Resposta: 5432 bytes
Identificando Bots de IA em Seus Logs
A forma mais direta de identificar bots de IA é buscar por strings conhecidas de user agent em seus logs. Assinaturas comuns de user agent para bots de IA incluem “GPTBot” para o crawler da OpenAI, “ClaudeBot” para o da Anthropic, “PerplexityBot” para a Perplexity AI, “Google-Extended” para o bot de treinamento de IA do Google e “Bingbot-AI” para o crawler de IA da Microsoft. Porém, alguns bots de IA não se identificam claramente, dificultando a detecção apenas com buscas simples por user agent. Você pode usar ferramentas de linha de comando como grep para encontrar rapidamente bots específicos: grep "GPTBot" access.log | wc -l conta todas as requisições do GPTBot, enquanto grep "GPTBot" access.log > gptbot_requests.log cria um arquivo dedicado para análise.
User agents de bots de IA conhecidos para monitorar:
Para bots que não se identificam claramente, use verificação de reputação de IP cruzando endereços IP com faixas publicadas por grandes empresas de IA.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Principais Métricas para Rastrear
Monitorar as métricas corretas revela as intenções dos bots e ajuda a otimizar seu site adequadamente. Taxa de requisições (medida em requisições por segundo ou RPS) mostra o quão agressivamente um bot rastreia seu site—crawlers saudáveis mantêm 1-5 RPS enquanto bots de IA agressivos podem atingir mais de 50 RPS. O consumo de recursos importa porque um único bot de IA pode consumir mais banda em um dia do que toda sua base de usuários humanos combinada. A distribuição dos códigos de status HTTP revela como seu servidor responde às requisições dos bots: altas porcentagens de respostas 200 (OK) indicam rastreamento bem-sucedido, enquanto muitos 404 sugerem que o bot está seguindo links quebrados ou sondando recursos ocultos. A frequência e os padrões de rastreamento mostram se os bots são visitantes constantes ou do tipo “rajada e pausa”, enquanto o rastreamento de origem geográfica revela se as requisições vêm de infraestrutura legítima das empresas ou de locais suspeitos.
Métrica
O Que Significa
Faixa Saudável
Alertas
Requisições/Hora
Intensidade da atividade do bot
100-1000
5000+
Banda (MB/hora)
Consumo de recursos
50-500
5000+
Códigos 200
Requisições bem-sucedidas
70-90%
<50%
Códigos 404
Links quebrados acessados
<10%
>30%
Frequência de Rastreamento
Com que frequência o bot visita
Diário-Semanal
Várias vezes/hora
Concentração Geográfica
Origem da requisição
Data centers conhecidos
ISPs residenciais
Ferramentas para Monitoramento de Crawlers de IA
Você tem várias opções para monitorar a atividade de crawlers de IA, desde ferramentas gratuitas de linha de comando até plataformas empresariais. Ferramentas de linha de comando como grep, awk e sed são gratuitas e poderosas para sites pequenos e médios, permitindo extrair padrões dos logs em segundos. Plataformas comerciais como Botify, Conductor e seoClarity oferecem recursos sofisticados, incluindo identificação automatizada de bots, dashboards visuais e correlação com dados de ranking e tráfego. Ferramentas de análise de logs como Screaming Frog Log File Analyser e OnCrawl oferecem recursos especializados para processar grandes arquivos de log e identificar padrões de rastreamento. Plataformas de análise orientadas por IA usam machine learning para identificar automaticamente novos tipos de bots, prever comportamentos e detectar anomalias sem configuração manual.
Ferramenta
Custo
Recursos
Melhor Para
grep/awk/sed
Grátis
Correspondência de padrões por linha de comando
Usuários técnicos, sites pequenos
Botify
Empresarial
Rastreamento de bots de IA, correlação de desempenho
Sites grandes, análise detalhada
Conductor
Empresarial
Monitoramento em tempo real, atividade de crawler de IA
Estabelecer padrões básicos de rastreamento é o primeiro passo para um monitoramento eficaz. Colete pelo menos duas semanas de dados de log (idealmente um mês) para entender o comportamento normal dos bots antes de tirar conclusões sobre anomalias. Configure monitoramento automatizado criando scripts que rodem diariamente para analisar logs e gerar relatórios, usando ferramentas como Python com a biblioteca pandas ou scripts bash simples. Crie alertas para atividades incomuns como picos súbitos na taxa de requisições, aparecimento de novos tipos de bots ou bots acessando recursos restritos. Agende revisões regulares dos logs—semanalmente para sites de alto tráfego para detectar problemas cedo, mensalmente para sites menores para identificar tendências.
Aqui está um script bash simples para monitoramento contínuo:
#!/bin/bash
# Relatório diário de atividade de bots de IALOG_FILE="/var/log/nginx/access.log"REPORT_FILE="/reports/bot_activity_$(date +%Y%m%d).txt"echo "=== Relatório de Atividade de Bots de IA ===" > $REPORT_FILE
echo "Data: $(date)" >> $REPORT_FILE
echo "" >> $REPORT_FILE
echo "Requisições do GPTBot:" >> $REPORT_FILE
grep "GPTBot" $LOG_FILE | wc -l >> $REPORT_FILE
echo "Requisições do ClaudeBot:" >> $REPORT_FILE
grep "ClaudeBot" $LOG_FILE | wc -l >> $REPORT_FILE
echo "Requisições do PerplexityBot:" >> $REPORT_FILE
grep "PerplexityBot" $LOG_FILE | wc -l >> $REPORT_FILE
# Envia alerta se atividade incomum for detectadaGPTBOT_COUNT=$(grep "GPTBot" $LOG_FILE | wc -l)if[ $GPTBOT_COUNT -gt 10000]; then echo "ALERTA: Atividade incomum do GPTBot detectada!" | mail -s "Alerta de Bot" admin@example.com
fi
Gerenciando o Acesso de Crawlers de IA
Seu arquivo robots.txt é a primeira linha de defesa para controlar o acesso de bots de IA, e as principais empresas de IA respeitam diretivas específicas para seus bots de treinamento. Você pode criar regras separadas para diferentes tipos de bots—permitindo acesso total ao Googlebot enquanto restringe o GPTBot a seções específicas, ou definindo valores de crawl-delay para limitar a taxa de requisições. O rate limiting garante que bots não sobrecarreguem sua infraestrutura, implementando limites em múltiplos níveis: por endereço IP, por user agent e por tipo de recurso. Quando um bot excede os limites, retorne um 429 (Too Many Requests) com um cabeçalho Retry-After; bots bem-comportados respeitarão isso e desacelerarão, enquanto scrapers ignorarão e devem ser bloqueados por IP.
Veja exemplos de robots.txt para gerenciar o acesso de crawlers de IA:
# Permitir motores de busca, limitar bots de treinamento de IA
User-agent: Googlebot
Allow: /
User-agent: GPTBot
Disallow: /private/
Disallow: /proprietary-content/
Crawl-delay: 1
User-agent: ClaudeBot
Disallow: /admin/
Crawl-delay: 2
User-agent: *
Disallow: /
O padrão emergente LLMs.txt fornece controle adicional, permitindo comunicar preferências a crawlers de IA em formato estruturado, semelhante ao robots.txt, mas projetado para aplicações de IA.
Otimizando Seu Site para Crawlers de IA
Tornar seu site amigável a crawlers de IA melhora como seu conteúdo aparece em respostas geradas por IA e garante que bots possam acessar suas páginas mais valiosas. Estrutura clara de site com navegação consistente, forte interligação interna e organização lógica de conteúdo ajuda bots de IA a entender e navegar por seu conteúdo de forma eficiente. Implemente schema markup usando formato JSON-LD para esclarecer tipo de conteúdo, informações-chave, relações entre conteúdos e detalhes do negócio—isso ajuda sistemas de IA a interpretar e referenciar seu conteúdo com precisão. Garanta tempos rápidos de carregamento para evitar timeouts dos bots, mantenha design responsivo que funcione para todos os tipos de bots e crie conteúdo original e de alta qualidade que sistemas de IA possam citar corretamente.
Melhores práticas para otimização de crawlers de IA:
Implemente dados estruturados (schema.org markup) para todo conteúdo importante
Mantenha tempos de carregamento rápidos (menos de 3 segundos)
Use títulos e descrições meta descritivos e únicos
Crie ligação interna clara entre conteúdos relacionados
Garanta responsividade e design adaptativo
Evite conteúdo excessivamente baseado em JavaScript que bots têm dificuldade para renderizar
Use HTML semântico com hierarquia adequada de headings
Inclua informações sobre autor e datas de publicação
Forneça informações claras de contato e do negócio
Erros Comuns e Como Evitá-los
Muitos proprietários de sites cometem erros críticos ao gerenciar o acesso de crawlers de IA que prejudicam sua estratégia de visibilidade em IA. Identificar erroneamente o tráfego de bots confiando apenas em user agents ignora bots sofisticados que se passam por navegadores—use análise comportamental incluindo frequência de requisições, preferências de conteúdo e distribuição geográfica para identificação precisa. Análise de logs incompleta que foca apenas em user agents sem considerar outros dados ignora atividades importantes de bots; o rastreamento deve ser abrangente, incluindo frequência, preferências de conteúdo, distribuição geográfica e métricas de desempenho. Bloquear demais através de robots.txt excessivamente restritivos impede bots legítimos de IA de acessar conteúdo valioso que poderia gerar visibilidade em respostas geradas por IA.
Erros comuns a evitar:
Erro: Analisar apenas user agents sem padrões comportamentais
Solução: Combine análise de user agent com frequência de requisições, horários e padrões de acesso a conteúdo
Erro: Bloquear todos os bots de IA para evitar roubo de conteúdo
Solução: Permita acesso ao conteúdo público enquanto restringe informações proprietárias; monitore o impacto na visibilidade em IA
Erro: Ignorar o impacto de bots no desempenho
Solução: Implemente rate limiting e monitore recursos do servidor; ajuste limites conforme capacidade
Erro: Não atualizar regras de monitoramento conforme novos bots surgem
Solução: Revise logs mensalmente e atualize regras de identificação de bots trimestralmente
Futuro do Monitoramento de Crawlers de IA
O ecossistema de bots de IA está evoluindo rapidamente e suas práticas de monitoramento precisam acompanhar. Bots de IA estão ficando mais sofisticados, executando JavaScript, interagindo com formulários e navegando em arquiteturas de sites complexas—tornando métodos tradicionais de detecção menos confiáveis. Espere que padrões emergentes forneçam formas estruturadas de comunicar suas preferências a bots de IA, semelhante ao robots.txt, mas com controle mais granular. Mudanças regulatórias estão a caminho, já que jurisdições consideram leis que exigem que empresas de IA divulguem fontes de dados de treinamento e compensem criadores de conteúdo, tornando seus arquivos de log potenciais evidências legais de atividade de bots. Serviços de corretagem de bots provavelmente surgirão para negociar acesso entre criadores de conteúdo e empresas de IA, lidando com permissões, compensação e implementação técnica automaticamente.
A indústria caminha para a padronização com novos protocolos e extensões ao robots.txt que permitem comunicação estruturada com bots de IA. O machine learning cada vez mais impulsionará ferramentas de análise de logs, identificando automaticamente novos padrões de bots e recomendando mudanças de políticas sem intervenção manual. Sites que dominarem o monitoramento de crawlers de IA agora terão vantagens significativas no controle de seu conteúdo, infraestrutura e modelo de negócios à medida que sistemas de IA se tornam parte integral do fluxo de informações na web.
Pronto para monitorar como sistemas de IA citam e referenciam sua marca? O AmICited.com complementa a análise de logs do servidor rastreando menções reais da marca e citações em respostas geradas por IA no ChatGPT, Perplexity, Google AI Overviews e outras plataformas de IA. Enquanto os logs do servidor mostram quais bots estão rastreando seu site, o AmICited mostra o impacto real—como seu conteúdo está sendo usado e citado em respostas de IA. Comece a rastrear sua visibilidade em IA hoje mesmo.
Perguntas frequentes
O que é um crawler de IA e como ele é diferente de um bot de mecanismo de busca?
Crawlers de IA são bots usados por empresas de IA para treinar modelos de linguagem e alimentar aplicações de IA. Diferentemente dos bots de busca que constroem índices para ranqueamento, crawlers de IA focam em coletar conteúdo diversificado para treinar modelos de IA. Eles costumam rastrear de forma mais agressiva e podem ignorar regras tradicionais do robots.txt.
Como posso saber se bots de IA estão acessando meu site?
Verifique os logs do seu servidor em busca de strings de user agent conhecidas de bots de IA como 'GPTBot', 'ClaudeBot' ou 'PerplexityBot'. Use ferramentas de linha de comando como grep para procurar esses identificadores. Você também pode usar ferramentas de análise de logs como Botify ou Conductor, que identificam e categorizam automaticamente a atividade de crawlers de IA.
Devo bloquear crawlers de IA do acesso ao meu site?
Depende dos objetivos do seu negócio. Bloquear crawlers de IA impede que seu conteúdo apareça em respostas geradas por IA, o que pode reduzir sua visibilidade. Porém, se você está preocupado com roubo de conteúdo ou consumo de recursos, pode usar o robots.txt para limitar o acesso. Considere permitir acesso ao conteúdo público enquanto restringe informações proprietárias.
Quais métricas devo monitorar para a atividade de crawlers de IA?
Acompanhe taxa de requisições (requisições por segundo), consumo de banda, códigos de status HTTP, frequência de rastreamento e origem geográfica das requisições. Monitore quais páginas os bots acessam com mais frequência e quanto tempo passam em seu site. Essas métricas revelam as intenções dos bots e ajudam a otimizar seu site adequadamente.
Quais ferramentas posso usar para monitorar a atividade de crawlers de IA?
Opções gratuitas incluem ferramentas de linha de comando (grep, awk) e analisadores de logs de código aberto. Plataformas comerciais como Botify, Conductor e seoClarity oferecem recursos avançados, incluindo identificação automatizada de bots e correlação de desempenho. Escolha com base em seu nível técnico e orçamento.
Como otimizo meu site para crawlers de IA?
Garanta tempos rápidos de carregamento de página, use dados estruturados (schema markup), mantenha uma arquitetura de site clara e facilite o acesso ao conteúdo. Implemente cabeçalhos HTTP adequados e regras no robots.txt. Crie conteúdo original e de alta qualidade que sistemas de IA possam referenciar e citar com precisão.
Bots de IA podem prejudicar meu site ou servidor?
Sim, crawlers de IA agressivos podem consumir muita banda e recursos do servidor, causando lentidão ou aumento nos custos de hospedagem. Monitore a atividade dos crawlers e implemente limitação de taxa para evitar exaustão de recursos. Use robots.txt e cabeçalhos HTTP para controlar o acesso, se necessário.
O que é o padrão LLMs.txt e devo implementá-lo?
LLMs.txt é um padrão emergente que permite aos sites comunicar preferências para crawlers de IA em formato estruturado. Embora nem todos os bots o suportem ainda, implementá-lo fornece controle adicional sobre como sistemas de IA acessam seu conteúdo. É semelhante ao robots.txt, mas projetado especificamente para aplicações de IA.
Monitore Sua Marca em Respostas de IA
Acompanhe como sistemas de IA citam e referenciam seu conteúdo no ChatGPT, Perplexity, Google AI Overviews e outras plataformas de IA. Entenda sua visibilidade em IA e otimize sua estratégia de conteúdo.
Auditoria de Acesso de Crawlers de IA: Os Bots Certos Estão Vendo Seu Conteúdo?
Aprenda como auditar o acesso de crawlers de IA ao seu site. Descubra quais bots podem ver seu conteúdo e corrija bloqueios que impedem a visibilidade em IA com...
Como Identificar Rastreadores de IA nos Seus Logs de Servidor
Aprenda a identificar e monitorar rastreadores de IA como GPTBot, ClaudeBot e PerplexityBot nos seus logs de servidor. Guia completo com strings de user-agent, ...
Como Identificar Crawlers de IA em Logs de Servidor: Guia Completo de Detecção
Aprenda como identificar e monitorar crawlers de IA como GPTBot, PerplexityBot e ClaudeBot em seus logs de servidor. Descubra strings de user-agent, métodos de ...
9 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.