Citações da Wikipédia como Dados de Treinamento de IA: O Efeito Cascata
Descubra como as citações da Wikipédia moldam os dados de treinamento de IA e criam um efeito cascata em LLMs. Saiba por que sua presença na Wikipédia importa para menções em IA e percepção de marca.
Publicado em Jan 3, 2026.Última modificação em Jan 3, 2026 às 3:24 am
O Alicerce: O Papel da Wikipédia no Treinamento de LLMs
A Wikipédia tornou-se o conjunto de dados de treinamento fundamental para praticamente todos os grandes modelos de linguagem atualmente existentes — do ChatGPT da OpenAI e Gemini do Google ao Claude da Anthropic e ao mecanismo de busca Perplexity. Em muitos casos, a Wikipédia representa a maior fonte única de texto estruturado e de alta qualidade dentro dos conjuntos de dados de treinamento desses sistemas de IA, frequentemente compreendendo de 5 a 15% do corpus total de treinamento, dependendo do modelo. Esse domínio decorre das características únicas da Wikipédia: sua política de ponto de vista neutro, rigorosa checagem de fatos conduzida pela comunidade, formatação estruturada e licenciamento de livre acesso a tornam um recurso incomparável para ensinar sistemas de IA a raciocinar, citar fontes e comunicar com precisão. No entanto, essa relação transformou fundamentalmente o papel da Wikipédia no ecossistema digital — ela não é mais apenas um destino para leitores humanos em busca de informação, mas sim o alicerce invisível que impulsiona a IA conversacional com a qual milhões interagem diariamente. Compreender essa conexão revela um efeito cascata crítico: a qualidade, os vieses e as lacunas da Wikipédia moldam diretamente as capacidades e limitações dos sistemas de IA que agora mediam como bilhões de pessoas acessam e entendem informações.
Como LLMs Realmente Usam Dados da Wikipédia
Quando grandes modelos de linguagem processam informações durante o treinamento, eles não tratam todas as fontes da mesma forma — a Wikipédia ocupa uma posição privilegiada e única em sua hierarquia de decisão. Durante o processo de reconhecimento de entidades, LLMs identificam fatos e conceitos chave, então os cruzam com múltiplas fontes para estabelecer pontuações de credibilidade. A Wikipédia funciona como uma “checagem primária de autoridade” nesse processo devido ao seu histórico de edições transparente, mecanismos de verificação comunitária e política de ponto de vista neutro, que coletivamente sinalizam confiabilidade para os sistemas de IA. O efeito multiplicador de credibilidade amplifica essa vantagem: quando informações aparecem de forma consistente na Wikipédia, em grafos de conhecimento estruturados como o Google Knowledge Graph e o Wikidata, e em fontes acadêmicas, LLMs atribuem uma confiança exponencialmente maior a essa informação. Esse sistema de ponderação explica por que a Wikipédia recebe tratamento especial no treinamento — ela serve tanto como fonte direta de conhecimento quanto como camada de validação para fatos extraídos de outras fontes. O resultado é que LLMs aprenderam a tratar a Wikipédia não apenas como um dado entre muitos, mas como uma referência fundamental que confirma ou questiona informações provenientes de fontes menos verificadas.
Ponderação de Credibilidade das Fontes no Treinamento de LLM
Tipo de Fonte
Peso de Credibilidade
Motivo
Tratamento pela IA
Wikipédia
Muito Alto
Neutra, editada pela comunidade, verificada
Referência primária
Site da Empresa
Médio
Autopromocional
Fonte secundária
Artigos de Notícias
Alto
Terceiros, mas potencialmente tendenciosos
Fonte de corroboração
Grafos de Conhecimento
Muito Alto
Estruturados, agregados
Multiplicador de autoridade
Mídias Sociais
Baixo
Não verificadas, promocionais
Peso mínimo
Fontes Acadêmicas
Muito Alto
Revisadas por pares, autoritativas
Alta confiança
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
A Cadeia de Citação: Como a Wikipédia Influencia Respostas de IA
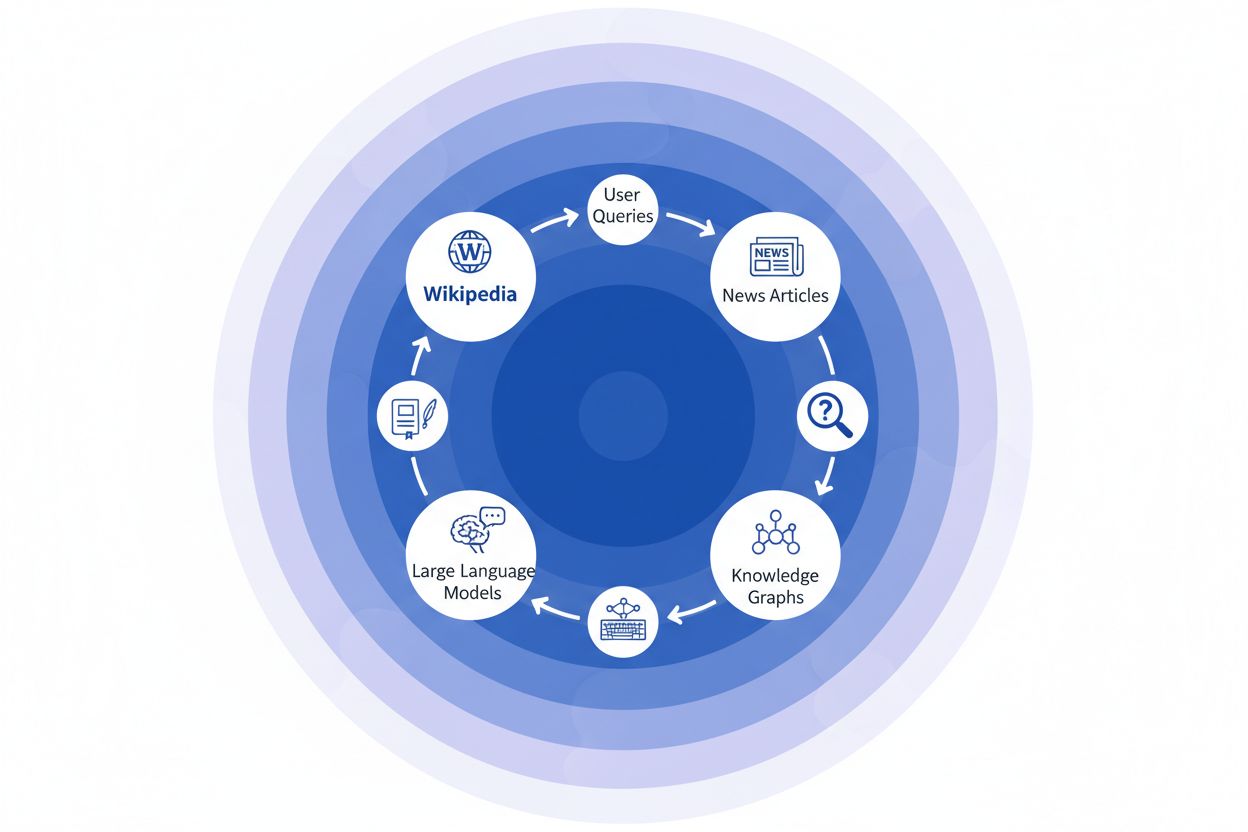
Quando uma organização de notícias cita a Wikipédia como fonte, cria-se o que chamamos de “cadeia de citação” — um mecanismo em cascata onde a credibilidade se acumula em múltiplas camadas da infraestrutura de informação. Um jornalista escrevendo sobre ciência climática pode referenciar um artigo da Wikipédia sobre aquecimento global, que por sua vez cita estudos revisados por pares; esse artigo jornalístico é então indexado por mecanismos de busca e incorporado em grafos de conhecimento, que subsequentemente treinam grandes modelos de linguagem que milhões de usuários consultam diariamente. Isso cria um poderoso ciclo de retroalimentação: Wikipédia → Grafo de Conhecimento → LLM → Usuário, em que a abordagem e ênfase do artigo original da Wikipédia podem, sutilmente, moldar como sistemas de IA apresentam informações ao usuário final, muitas vezes sem que esses usuários percebam que a informação remonta a uma enciclopédia colaborativa. Considere um exemplo específico: se o artigo da Wikipédia sobre um tratamento farmacêutico enfatiza certos testes clínicos enquanto minimiza outros, essa escolha editorial reverbera na cobertura jornalística, é incorporada nos grafos de conhecimento e, por fim, influencia como o ChatGPT ou modelos semelhantes respondem a pacientes sobre opções de tratamento. Esse “efeito cascata” significa que as decisões editoriais da Wikipédia não influenciam apenas leitores que acessam diretamente o site — elas moldam fundamentalmente o cenário informacional do qual os sistemas de IA aprendem e refletem para bilhões de usuários. A cadeia de citação transforma, essencialmente, a Wikipédia de um destino de referência em uma camada invisível porém influente do pipeline de treinamento de IA, onde precisão e viés na origem podem ser amplificados em todo o ecossistema.
O Efeito Cascata: Consequências a Jusante
O efeito cascata no ecossistema Wikipédia-IA é talvez a dinâmica mais importante para marcas e organizações compreenderem. Uma única edição na Wikipédia não muda apenas uma fonte — ela se propaga por uma rede interconectada de sistemas de IA, cada um extraindo e amplificando a informação de maneiras que multiplicam seu impacto exponencialmente. Quando uma imprecisão aparece em uma página da Wikipédia, ela não permanece isolada; em vez disso, se espalha por toda a paisagem da IA, moldando como sua marca é descrita, compreendida e apresentada a milhões de usuários diariamente. Esse efeito multiplicador significa que investir na precisão da Wikipédia não diz respeito apenas a uma plataforma — trata-se de controlar sua narrativa em todo o ecossistema de IA generativa. Para profissionais de PR digital e gestão de marcas, essa realidade muda fundamentalmente o cálculo de onde focar recursos e atenção.
Principais efeitos cascata para monitorar:
A qualidade da página da Wikipédia afeta diretamente como sistemas de IA descrevem sua marca — Conteúdo ruim na Wikipédia torna-se a base de como ChatGPT, Gemini, Claude e outros sistemas de IA caracterizam sua organização
Uma única citação da Wikipédia influencia grafos de conhecimento, que influenciam AI Overviews — As citações fluem pela infraestrutura de conhecimento do Google e impactam diretamente como as informações aparecem em resumos gerados por IA
Informações imprecisas na Wikipédia se propagam por todo o ecossistema de IA — Uma vez incorporada aos dados de treinamento, a desinformação torna-se exponencialmente mais difícil de corrigir em múltiplas plataformas
Presença positiva na Wikipédia é amplificada em todas as grandes plataformas de IA — Uma página da Wikipédia bem mantida cria uma mensagem consistente e autoritativa em ChatGPT, Gemini, Claude, Perplexity e sistemas de IA emergentes
Edições na Wikipédia têm efeitos retardados, mas cumulativos, no treinamento de IA — Mudanças feitas hoje influenciam as saídas dos modelos de IA por meses ou anos à medida que as informações passam por novos ciclos de treinamento
O efeito cascata alcança Google AI Overviews, snippets em destaque e painéis de conhecimento — A Wikipédia serve como fonte autoritativa que alimenta os resultados de busca gerados por IA do Google e exibições de dados estruturados
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
O Desafio de Sustentabilidade da Wikipédia: Ameaça ao Ecossistema
Pesquisas recentes do estudo IUP de Vetter et al. iluminaram uma vulnerabilidade crítica em nossa infraestrutura de IA: a sustentabilidade da Wikipédia como recurso de treinamento está cada vez mais ameaçada pela própria tecnologia que ela ajuda a alimentar. À medida que grandes modelos de linguagem proliferam e são treinados em conjuntos de dados cada vez maiores gerados por LLM, o campo enfrenta um problema crescente de “colapso de modelo”, em que saídas artificiais começam a contaminar o pool de dados de treinamento, degradando a qualidade dos modelos ao longo de gerações sucessivas. Esse fenômeno é especialmente agudo, dado que a Wikipédia — uma enciclopédia colaborativa construída sobre expertise humana e trabalho voluntário — tornou-se um pilar fundamental para o treinamento de sistemas avançados de IA, muitas vezes sem atribuição explícita ou compensação a seus contribuidores. As implicações éticas são profundas: enquanto empresas de IA extraem valor do conhecimento livremente contribuído da Wikipédia e, simultaneamente, inundam o ecossistema informacional com conteúdo sintético, as estruturas de incentivo que sustentam a comunidade voluntária da Wikipédia há mais de duas décadas enfrentam uma pressão sem precedentes. Sem uma intervenção deliberada para preservar o conteúdo gerado por humanos como um recurso distinto e protegido, corremos o risco de criar um ciclo de retroalimentação onde o texto gerado por IA progressivamente substitui o conhecimento humano autêntico, minando, em última instância, o próprio alicerce do qual os modelos de linguagem modernos dependem. A sustentabilidade da Wikipédia, portanto, não é apenas uma preocupação para a própria enciclopédia, mas uma questão crítica para todo o ecossistema informacional e para a viabilidade futura dos sistemas de IA que dependem do conhecimento humano autêntico.
Monitorando Sua Presença na Wikipédia: O Papel do AmICited
À medida que sistemas de inteligência artificial dependem cada vez mais da Wikipédia como fonte fundamental de conhecimento, monitorar como sua marca aparece nessas respostas geradas por IA tornou-se essencial para organizações modernas. O AmICited.com é especializado em rastrear citações da Wikipédia à medida que se propagam por sistemas de IA, oferecendo às marcas visibilidade de como sua presença na Wikipédia se traduz em menções e recomendações por IA. Embora ferramentas alternativas como o FlowHunt.io ofereçam capacidades gerais de monitoramento da web, o AmICited foca de maneira única no pipeline de citações da Wikipédia para IA, capturando o momento específico em que sistemas de IA referenciam sua entrada na Wikipédia e como isso influencia suas respostas. Compreender essa conexão é fundamental porque citações da Wikipédia têm peso significativo nos dados de treinamento de IA e na geração de respostas — uma presença bem mantida na Wikipédia não informa apenas leitores humanos, mas molda como sistemas de IA percebem e apresentam sua marca para milhões de usuários. Ao monitorar suas menções na Wikipédia através do AmICited, você obtém insights acionáveis sobre sua pegada em IA, permitindo otimizar sua presença na Wikipédia com plena consciência de seu impacto a jusante na descoberta via IA e na percepção da marca.
Perguntas frequentes
A Wikipédia realmente é usada para treinar todo LLM?
Sim, todo grande LLM incluindo ChatGPT, Gemini, Claude e Perplexity inclui a Wikipédia em seus dados de treinamento. A Wikipédia é frequentemente a maior fonte única de informações estruturadas e verificadas nos conjuntos de dados de treinamento de LLM, normalmente representando de 5 a 15% do corpus total de treinamento.
Como a Wikipédia afeta o que os sistemas de IA dizem sobre minha marca?
A Wikipédia funciona como um ponto de verificação de credibilidade para sistemas de IA. Quando um LLM gera informações sobre sua marca, ele atribui mais peso à descrição da Wikipédia do que a outras fontes, tornando sua página na Wikipédia uma influência crítica em como sistemas de IA o representam no ChatGPT, Gemini, Claude e outras plataformas.
O que é o 'efeito cascata' no contexto da Wikipédia e IA?
O efeito cascata refere-se a como uma única citação ou edição na Wikipédia cria consequências posteriores em todo o ecossistema de IA. Uma mudança na Wikipédia pode influenciar grafos de conhecimento, que influenciam panoramas de IA, que influenciam como múltiplos sistemas de IA descrevem sua marca para milhões de usuários.
Informações imprecisas na Wikipédia podem prejudicar minha marca em sistemas de IA?
Sim. Como LLMs tratam a Wikipédia como altamente confiável, informações imprecisas em sua página da Wikipédia serão propagadas através dos sistemas de IA. Isso pode afetar como ChatGPT, Gemini e outras plataformas de IA descrevem sua organização, potencialmente prejudicando a percepção da sua marca.
Como posso monitorar como a Wikipédia afeta minha marca em sistemas de IA?
Ferramentas como o AmICited.com rastreiam como sua marca é citada e mencionada em sistemas de IA, incluindo ChatGPT, Perplexity e Google AI Overviews. Isso ajuda você a entender o efeito cascata de sua presença na Wikipédia e otimizar de acordo.
Devo criar ou editar minha página da Wikipédia sozinho?
A Wikipédia possui políticas rigorosas contra autopromoção. Quaisquer edições devem seguir as diretrizes da Wikipédia e ser baseadas em fontes confiáveis e independentes. Muitas organizações trabalham com especialistas em Wikipédia para garantir conformidade e manter uma presença precisa.
Quanto tempo leva para mudanças na Wikipédia afetarem sistemas de IA?
LLMs são treinados em instantâneos de dados, então as mudanças levam tempo para se propagar. No entanto, grafos de conhecimento atualizam com mais frequência, então o efeito cascata pode começar em semanas ou meses dependendo do sistema de IA e do momento em que ele é re-treinado.
Qual a diferença entre Wikipédia e grafos de conhecimento no treinamento de IA?
A Wikipédia é uma fonte primária usada diretamente no treinamento de LLM. Grafos de conhecimento, como o Google Knowledge Graph, agregam informações de várias fontes, incluindo a Wikipédia, e as fornecem aos sistemas de IA, criando uma camada extra de influência sobre como a IA entende e apresenta informações.
Monitore Sua Presença na Wikipédia em Sistemas de IA
Acompanhe como as citações da Wikipédia se propagam pelo ChatGPT, Gemini, Claude e outros sistemas de IA. Entenda sua pegada em IA e otimize sua presença na Wikipédia com o AmICited.
O Papel da Wikipedia nos Dados de Treinamento de IA: Qualidade, Impacto e Licenciamento
Descubra como a Wikipedia serve como um conjunto de dados crítico para o treinamento de IA, seu impacto na precisão dos modelos, acordos de licenciamento e por ...
Conseguir Citações em Artigos da Wikipedia: Uma Abordagem Não Manipulativa
Aprenda estratégias éticas para fazer sua marca ser citada na Wikipedia. Entenda as políticas de conteúdo da Wikipedia, fontes confiáveis e como aproveitar cita...
O Papel da Wikipédia nas Citações de IA: Como Ela Molda Respostas Geradas por IA
Descubra como a Wikipédia influencia as citações de IA no ChatGPT, Perplexity e Google IA. Entenda por que a Wikipédia é a fonte mais confiável para o treinamen...
14 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.