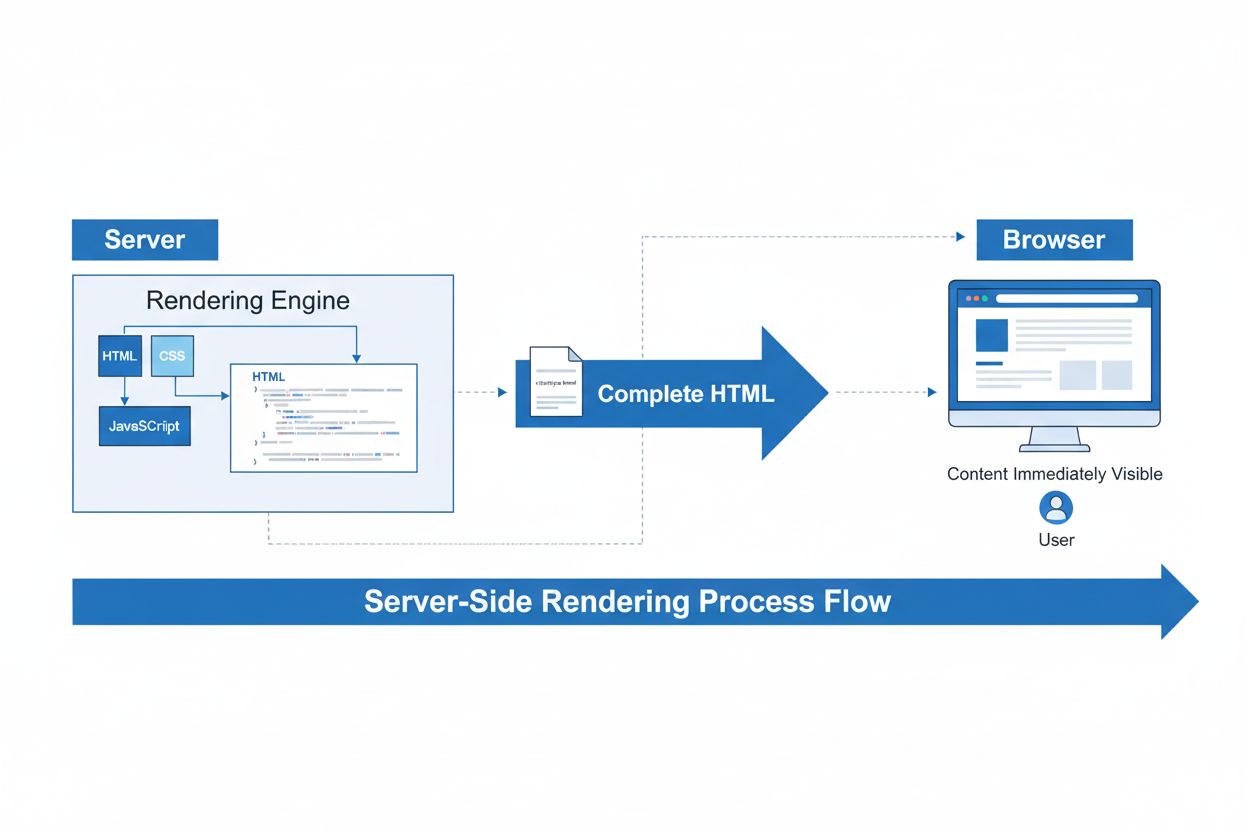
Renderização do Lado do Servidor (SSR)
A Renderização do Lado do Servidor (SSR) é uma técnica web em que os servidores renderizam páginas HTML completas antes de enviá-las aos navegadores. Saiba como...
13 min de leitura

Saiba como a renderização do lado do servidor permite processamento eficiente de IA, implantação de modelos e inferência em tempo real para aplicações impulsionadas por IA e cargas de trabalho de LLM.
Renderização do lado do servidor para IA é uma abordagem arquitetural onde modelos de inteligência artificial e o processamento de inferências ocorrem no servidor em vez de nos dispositivos do cliente. Isso permite lidar eficientemente com tarefas de IA computacionalmente intensivas, garante desempenho consistente para todos os usuários e simplifica a implantação e atualização dos modelos.
Renderização do lado do servidor para IA refere-se a um padrão arquitetural no qual modelos de inteligência artificial, processamento de inferência e tarefas computacionais são executados em servidores de backend em vez de em dispositivos do cliente como navegadores ou celulares. Essa abordagem difere fundamentalmente da renderização tradicional do lado do cliente, onde o JavaScript roda no navegador do usuário para gerar conteúdo. Em aplicações de IA, renderização do lado do servidor significa que grandes modelos de linguagem (LLMs), inferência de aprendizado de máquina e geração de conteúdo por IA acontecem centralmente numa infraestrutura de servidores potentes antes de os resultados serem enviados aos usuários. Essa mudança arquitetural tornou-se cada vez mais importante à medida que as capacidades de IA se tornaram mais exigentes em termos computacionais e centrais para aplicações web modernas.
O conceito surgiu do reconhecimento de uma incompatibilidade crítica entre o que aplicações modernas de IA requerem e o que dispositivos do cliente podem realisticamente fornecer. Frameworks tradicionais de desenvolvimento web como React, Angular e Vue.js popularizaram a renderização do lado do cliente ao longo da década de 2010, mas essa abordagem cria desafios significativos quando aplicada a cargas de trabalho intensivas de IA. A renderização do lado do servidor para IA endereça esses desafios aproveitando hardware especializado, gerenciamento centralizado de modelos e infraestrutura otimizada que dispositivos do cliente simplesmente não conseguem igualar. Isso representa uma mudança de paradigma fundamental em como desenvolvedores arquitetam aplicações com IA.
Os requisitos computacionais dos sistemas de IA modernos tornam a renderização do lado do servidor não apenas benéfica, mas muitas vezes necessária. Dispositivos do cliente, especialmente smartphones e notebooks de entrada, não têm poder de processamento suficiente para lidar com inferências de IA em tempo real de maneira eficiente. Quando modelos de IA rodam em dispositivos do cliente, os usuários experimentam atrasos perceptíveis, maior consumo de bateria e desempenho inconsistente dependendo da capacidade de hardware. A renderização do lado do servidor elimina esses problemas ao centralizar o processamento de IA em uma infraestrutura equipada com GPUs, TPUs e aceleradores de IA especializados que oferecem desempenho muito superior ao de dispositivos de consumo.
Além do desempenho bruto, a renderização do lado do servidor para IA oferece vantagens críticas em gerenciamento de modelos, segurança e consistência. Quando modelos de IA rodam em servidores, desenvolvedores podem atualizar, ajustar e implantar novas versões instantaneamente sem exigir que os usuários façam downloads ou gerenciem diferentes versões do modelo localmente. Isso é especialmente importante para grandes modelos de linguagem e sistemas de aprendizado de máquina que evoluem rapidamente com melhorias e correções de segurança frequentes. Adicionalmente, manter modelos de IA nos servidores previne acessos não autorizados, extração de modelos e roubo de propriedade intelectual que se tornam possíveis quando os modelos são distribuídos para dispositivos do cliente.
| Aspecto | IA no Lado do Cliente | IA no Lado do Servidor |
|---|---|---|
| Local de Processamento | Navegador ou dispositivo do usuário | Servidores de backend |
| Requisitos de Hardware | Limitado à capacidade do dispositivo | GPUs, TPUs e aceleradores de IA especializados |
| Desempenho | Variável, dependente do dispositivo | Consistente, otimizado |
| Atualizações de Modelo | Requer downloads do usuário | Implantação instantânea |
| Segurança | Modelos expostos à extração | Modelos protegidos nos servidores |
| Latência | Depende da potência do dispositivo | Infraestrutura otimizada |
| Escalabilidade | Limitada por dispositivo | Altamente escalável entre usuários |
| Complexidade de Desenvolvimento | Alta (fragmentação de dispositivos) | Menor (gerenciamento centralizado) |
Sobrecarga e Latência de Rede representam desafios significativos em aplicações de IA. Sistemas modernos de IA exigem comunicação constante com servidores para atualizações de modelos, recuperação de dados de treinamento e cenários híbridos de processamento. A renderização do lado do cliente, ironicamente, aumenta as requisições de rede em comparação com aplicações tradicionais, reduzindo os benefícios de desempenho que o processamento do lado do cliente deveria proporcionar. A renderização do lado do servidor consolida essas comunicações, reduzindo atrasos e permitindo que funcionalidades de IA em tempo real como tradução ao vivo, geração de conteúdo e processamento de visão computacional funcionem sem as penalidades de latência da inferência no cliente.
Complexidade de Sincronização surge quando aplicações de IA precisam manter a consistência de estado entre múltiplos serviços de IA simultaneamente. Aplicações modernas frequentemente utilizam serviços de embeddings, modelos de completion, modelos ajustados e motores de inferência especializados que precisam coordenar entre si. Gerenciar esse estado distribuído em dispositivos do cliente introduz grande complexidade e cria potencial para inconsistências de dados, especialmente em recursos colaborativos de IA em tempo real. A renderização do lado do servidor centraliza esse gerenciamento de estado, garantindo que todos os usuários vejam resultados consistentes e eliminando o esforço de engenharia necessário para manter complexa sincronização de estado no cliente.
Fragmentação de Dispositivos cria grandes desafios de desenvolvimento para IA do lado do cliente. Dispositivos diferentes têm capacidades variadas de IA, incluindo Unidades de Processamento Neural, aceleração por GPU, suporte a WebGL e restrições de memória. Criar experiências de IA consistentes nesse cenário fragmentado exige grande esforço de engenharia, estratégias de degradação suave e múltiplos caminhos de código para diferentes capacidades de dispositivo. A renderização do lado do servidor elimina totalmente essa fragmentação ao garantir que todos os usuários acessem a mesma infraestrutura otimizada de processamento de IA, independentemente das especificações do seu dispositivo.
A renderização do lado do servidor possibilita arquiteturas de aplicações de IA mais simples e fáceis de manter ao centralizar funcionalidades críticas. Em vez de distribuir modelos de IA e lógica de inferência por milhares de dispositivos do cliente, desenvolvedores mantêm uma única implementação otimizada nos servidores. Essa centralização proporciona benefícios imediatos como ciclos de implantação mais rápidos, depuração facilitada e otimização de desempenho mais direta. Quando um modelo de IA precisa de melhorias ou um bug é encontrado, os desenvolvedores corrigem uma única vez no servidor, ao invés de tentar distribuir atualizações para milhões de clientes com diferentes taxas de adoção.
A eficiência de recursos melhora dramaticamente com a renderização do lado do servidor. A infraestrutura de servidores permite compartilhamento eficiente de recursos entre todos os usuários, com pooling de conexões, estratégias de cache e balanceamento de carga otimizando o uso do hardware. Uma única GPU em um servidor pode processar requisições de inferência de milhares de usuários sequencialmente, enquanto distribuir essa mesma capacidade para dispositivos do cliente exigiria milhões de GPUs. Essa eficiência se traduz em menores custos operacionais, menor impacto ambiental e melhor escalabilidade à medida que as aplicações crescem.
Segurança e proteção de propriedade intelectual tornam-se significativamente mais fáceis com a renderização do lado do servidor. Modelos de IA representam grandes investimentos em pesquisa, dados de treinamento e recursos computacionais. Manter os modelos nos servidores previne ataques de extração de modelos, acessos não autorizados e roubo de propriedade intelectual que se tornam possíveis quando os modelos são distribuídos para dispositivos do cliente. Além disso, o processamento do lado do servidor permite controle de acesso granular, registro de auditoria e monitoramento de conformidade que seriam impossíveis de impor em dispositivos do cliente distribuídos.
Frameworks modernos evoluíram para suportar renderização do lado do servidor para cargas de trabalho de IA de forma eficaz. O Next.js lidera essa evolução com Server Actions que permitem processamento de IA diretamente a partir de componentes do servidor. Desenvolvedores podem chamar APIs de IA, processar grandes modelos de linguagem e transmitir respostas de volta aos clientes com pouco código boilerplate. O framework gerencia a complexidade da comunicação servidor-cliente, permitindo que desenvolvedores foquem na lógica de IA em vez de preocupações de infraestrutura.
O SvelteKit oferece uma abordagem orientada à performance para renderização de IA no servidor com suas funções de carregamento que executam no servidor antes da renderização. Isso possibilita pré-processamento de dados de IA, geração de recomendações e preparação de conteúdo aprimorado por IA antes de enviar o HTML ao cliente. As aplicações resultantes têm footprint mínimo de JavaScript mantendo todas as capacidades de IA, criando experiências de usuário excepcionalmente rápidas.
Ferramentas especializadas como o Vercel AI SDK abstraem a complexidade de streaming de respostas de IA, gerenciamento de contagem de tokens e manipulação de diferentes APIs de provedores de IA. Essas ferramentas permitem que desenvolvedores criem aplicações sofisticadas de IA sem profundo conhecimento de infraestrutura. Opções de infraestrutura incluindo Vercel Edge Functions, Cloudflare Workers e AWS Lambda fornecem processamento de IA no servidor distribuído globalmente, reduzindo latência ao processar requisições mais próximas dos usuários enquanto mantém o gerenciamento centralizado dos modelos.
Uma renderização de IA eficiente no lado do servidor requer estratégias sofisticadas de cache para gerenciar custos computacionais e latência. O cache Redis armazena respostas de IA frequentemente requisitadas e sessões de usuários, eliminando processamento redundante para consultas semelhantes. O cache CDN distribui globalmente conteúdo estático gerado por IA, garantindo que os usuários recebam respostas de servidores geograficamente próximos. Estratégias de cache na borda distribuem conteúdo processado por IA em redes de edge, proporcionando respostas com latência ultra-baixa enquanto mantêm o gerenciamento centralizado dos modelos.
Essas abordagens de cache trabalham juntas para criar sistemas de IA eficientes que escalam para milhões de usuários sem aumentos proporcionais nos custos computacionais. Ao armazenar respostas de IA em múltiplos níveis de cache, as aplicações podem atender a grande maioria das requisições a partir do cache, computando novas respostas apenas para consultas realmente inéditas. Isso reduz drasticamente os custos de infraestrutura ao mesmo tempo em que melhora a experiência do usuário com tempos de resposta mais rápidos.
A evolução em direção à renderização do lado do servidor representa uma maturidade das práticas de desenvolvimento web em resposta aos requisitos da IA. À medida que a IA se torna central em aplicações web, as realidades computacionais exigem arquiteturas centradas no servidor. O futuro envolve abordagens híbridas sofisticadas que decidem automaticamente onde renderizar com base no tipo de conteúdo, capacidades do dispositivo, condições de rede e requisitos de processamento de IA. Os frameworks irão aprimorar progressivamente as aplicações com capacidades de IA, garantindo que a funcionalidade principal funcione de forma universal, ao mesmo tempo que aprimoram a experiência sempre que possível.
Essa mudança de paradigma incorpora lições da era das Single Page Applications enquanto endereça desafios de aplicações nativas de IA. As ferramentas e frameworks já estão prontos para que desenvolvedores aproveitem os benefícios da renderização do lado do servidor na era da IA, viabilizando a próxima geração de aplicações web inteligentes, responsivas e eficientes.
Acompanhe como seu domínio e marca aparecem em respostas geradas por IA em ChatGPT, Perplexity e outros buscadores de IA. Obtenha insights em tempo real sobre sua visibilidade em IA.
A Renderização do Lado do Servidor (SSR) é uma técnica web em que os servidores renderizam páginas HTML completas antes de enviá-las aos navegadores. Saiba como...
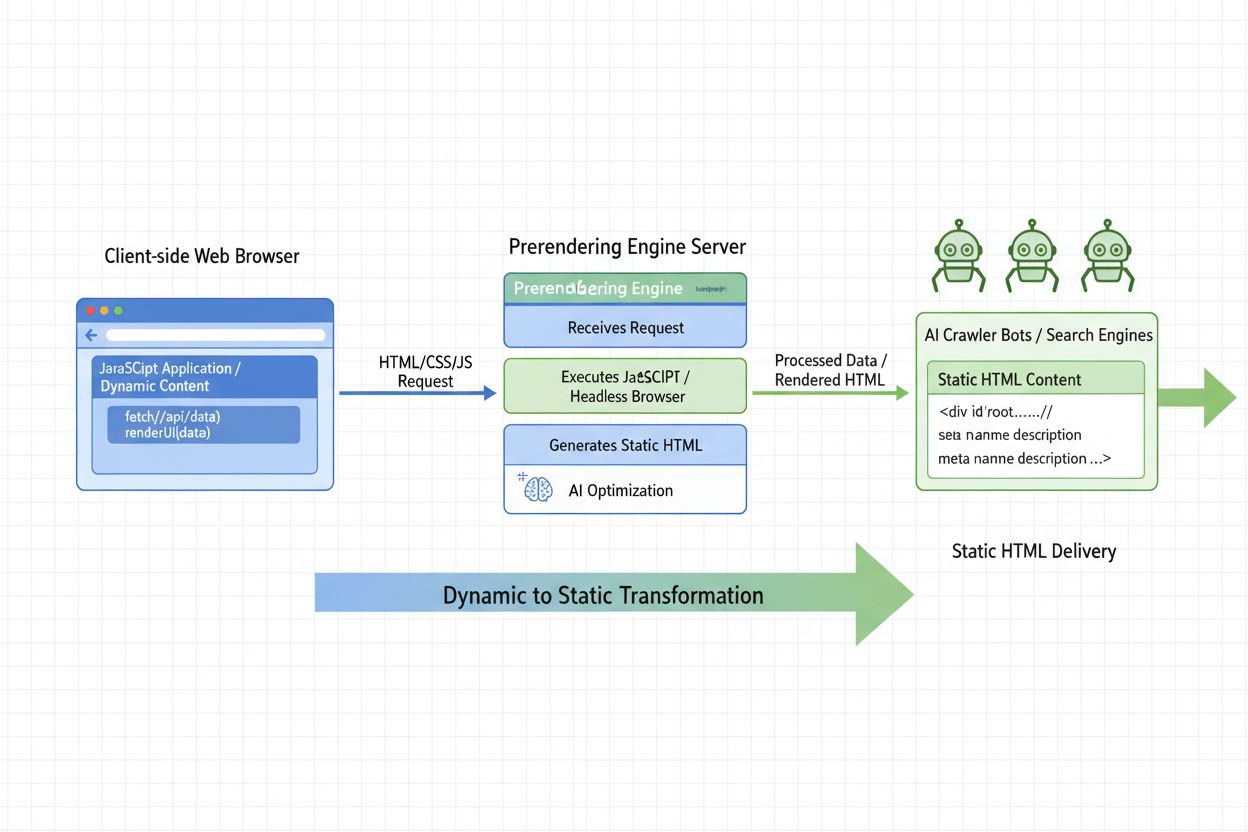
Saiba o que é Pré-renderização de IA e como estratégias de renderização do lado do servidor otimizam seu site para visibilidade de crawlers de IA. Descubra estr...

Saiba como a renderização dinâmica impacta rastreadores de IA, ChatGPT, Perplexity e Claude. Descubra por que sistemas de IA não conseguem renderizar JavaScript...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.