
Gerenciamento de Crawlers de IA
Aprenda como gerenciar o acesso de crawlers de IA ao conteúdo do seu site. Entenda a diferença entre crawlers de treinamento e de busca, implemente controles vi...
8 min de leitura
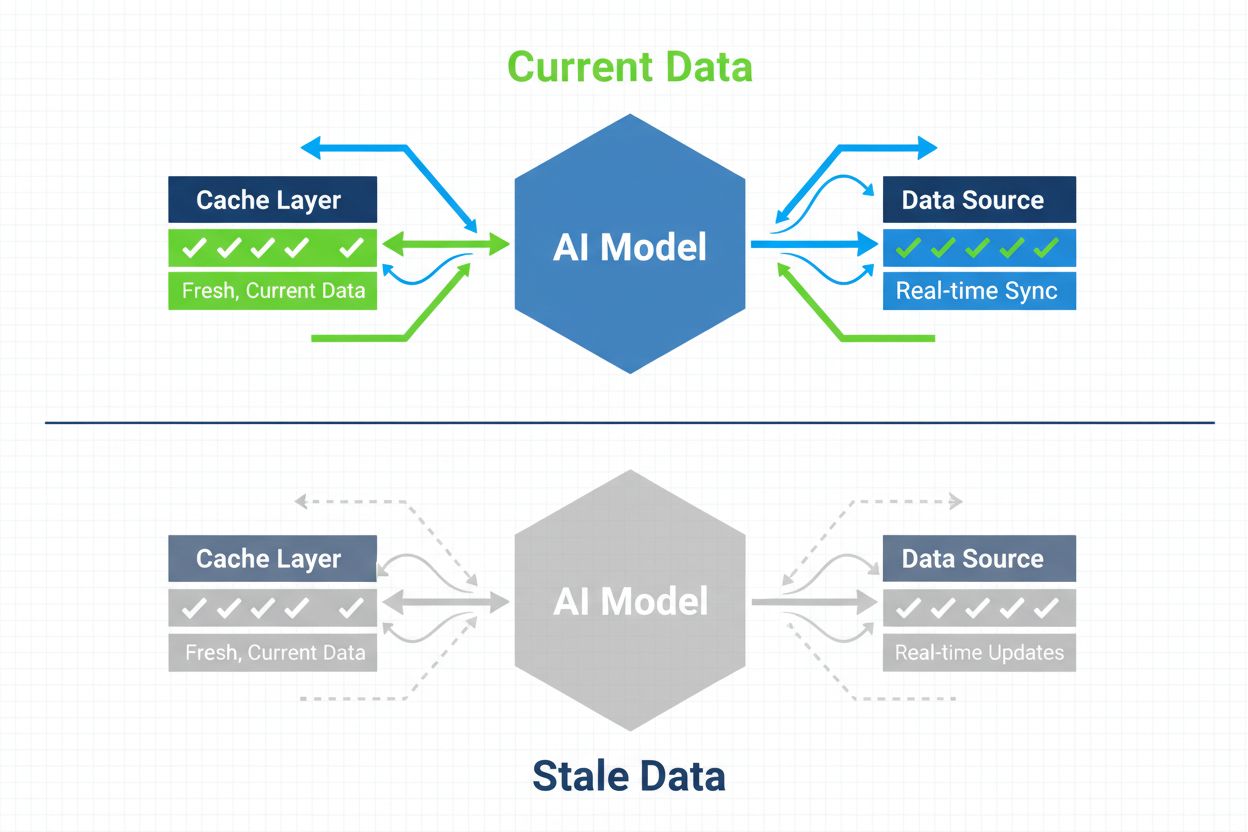
Estratégias para garantir que sistemas de IA tenham acesso a conteúdo atualizado, evitando versões obsoletas armazenadas em cache. O gerenciamento de cache equilibra os benefícios de desempenho do cache com o risco de fornecer informações desatualizadas, utilizando estratégias de invalidação e monitoramento para manter a atualidade dos dados enquanto reduz latência e custos.
Estratégias para garantir que sistemas de IA tenham acesso a conteúdo atualizado, evitando versões obsoletas armazenadas em cache. O gerenciamento de cache equilibra os benefícios de desempenho do cache com o risco de fornecer informações desatualizadas, utilizando estratégias de invalidação e monitoramento para manter a atualidade dos dados enquanto reduz latência e custos.
Gerenciamento de cache em IA refere-se à abordagem sistemática de armazenar e recuperar resultados previamente computados, saídas de modelos ou respostas de APIs para evitar processamento redundante e reduzir a latência em sistemas de inteligência artificial. O desafio central está em equilibrar os benefícios de desempenho do cache com o risco de fornecer informações obsoletas ou desatualizadas que não refletem mais o estado atual do sistema ou as necessidades do usuário. Isso se torna especialmente crítico em grandes modelos de linguagem (LLMs) e aplicações de IA, onde os custos de inferência são substanciais e o tempo de resposta impacta diretamente a experiência do usuário. Sistemas de gerenciamento de cache devem determinar de forma inteligente quando os resultados em cache permanecem válidos e quando é necessário um novo processamento, tornando-se um elemento fundamental na arquitetura de implantações de IA em produção.
O impacto de um gerenciamento de cache eficaz no desempenho de sistemas de IA é substancial e mensurável em múltiplas dimensões. Implementar estratégias de cache pode reduzir a latência das respostas em 80-90% para consultas repetidas, ao mesmo tempo em que corta custos de API em 50-90%, dependendo das taxas de acerto do cache e da arquitetura do sistema. Além dos indicadores de desempenho, o gerenciamento de cache influencia diretamente a consistência da precisão e a confiabilidade do sistema, pois caches corretamente invalidados garantem que os usuários recebam informações atuais, enquanto caches mal gerenciados introduzem problemas de obsolescência de dados. Essas melhorias tornam-se cada vez mais importantes à medida que sistemas de IA escalam para lidar com milhões de solicitações, onde o efeito cumulativo da eficiência do cache determina diretamente os custos de infraestrutura e a satisfação do usuário.
| Aspecto | Sistemas com Cache | Sistemas sem Cache |
|---|---|---|
| Tempo de Resposta | 80-90% mais rápido | Referência |
| Custos de API | Redução de 50-90% | Custo total |
| Precisão | Consistente | Variável |
| Escalabilidade | Alta | Limitada |
As estratégias de invalidação de cache determinam como e quando os dados em cache são atualizados ou removidos do armazenamento, representando uma das decisões mais críticas no design da arquitetura de cache. Diferentes abordagens de invalidação oferecem compensações distintas entre a atualidade dos dados e o desempenho do sistema:
A escolha da estratégia de invalidação depende fundamentalmente das necessidades da aplicação: sistemas que priorizam precisão dos dados podem aceitar custos maiores de latência através de invalidação agressiva, enquanto aplicações críticas em desempenho podem tolerar dados levemente obsoletos para manter tempos de resposta abaixo de milissegundos.
O cache de prompts em grandes modelos de linguagem representa uma aplicação especializada de gerenciamento de cache que armazena estados intermediários do modelo e sequências de tokens para evitar o reprocessamento de entradas idênticas ou semelhantes. LLMs suportam duas abordagens principais de cache: o cache exato corresponde a prompts idênticos caractere por caractere, enquanto o cache semântico identifica prompts funcionalmente equivalentes mesmo com redação diferente. A OpenAI implementa cache automático de prompts com redução de 50% no custo dos tokens em cache, exigindo segmentos mínimos de 1024 tokens para ativar os benefícios do cache. A Anthropic oferece cache manual de prompts com reduções de custo mais agressivas de até 90%, mas exige que desenvolvedores gerenciem explicitamente as chaves e durações do cache, com requisitos mínimos de cache de 1024-2048 tokens dependendo da configuração do modelo. A duração do cache em sistemas LLM geralmente varia de minutos a horas, equilibrando a economia computacional do reaproveitamento de estados em cache com o risco de fornecer saídas desatualizadas do modelo para aplicações sensíveis ao tempo.
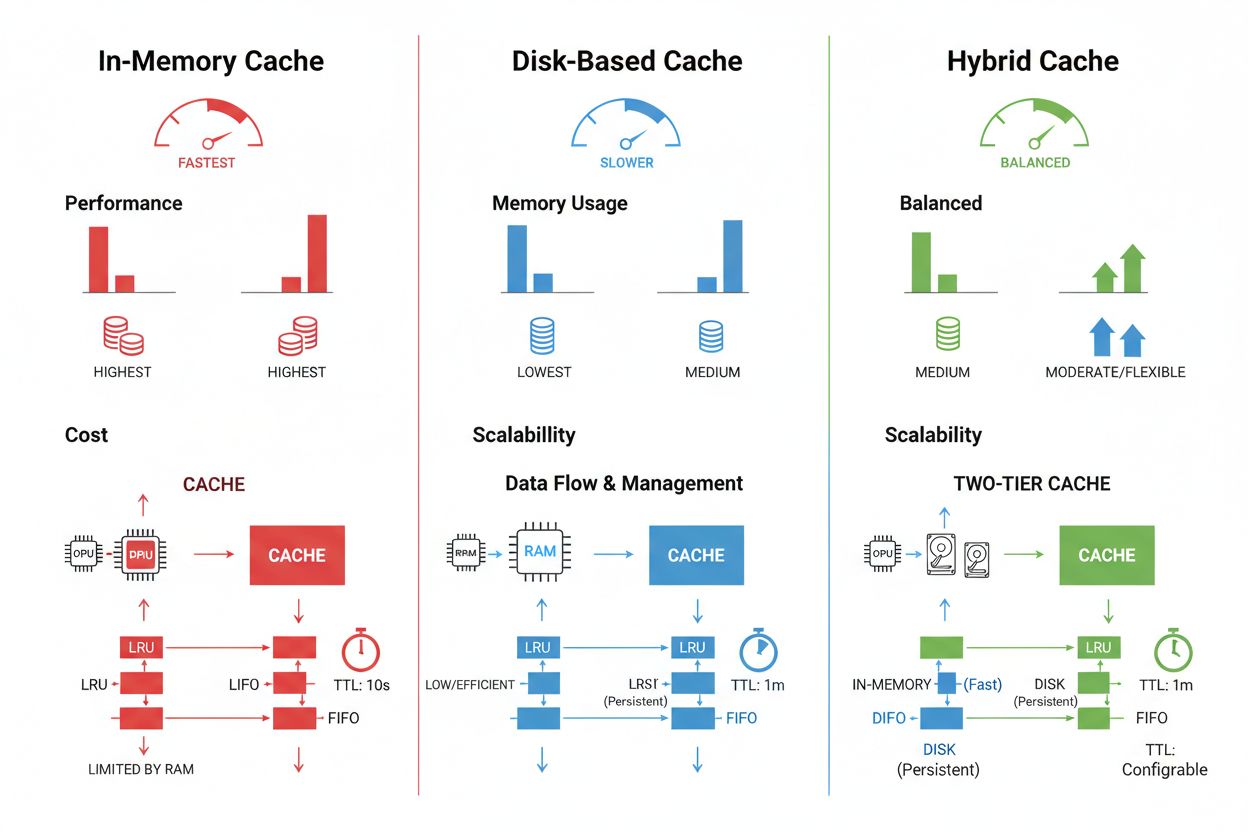
As técnicas de armazenamento e gerenciamento de cache variam significativamente conforme os requisitos de desempenho, volume de dados e restrições de infraestrutura, com cada abordagem oferecendo vantagens e limitações distintas. Soluções de cache em memória como Redis oferecem velocidades de acesso em microssegundos, ideais para consultas de alta frequência, mas consomem muita RAM e exigem gestão cuidadosa de memória. O cache baseado em disco comporta conjuntos de dados maiores e persiste entre reinicializações do sistema, mas introduz latência em milissegundos em comparação com alternativas em memória. Abordagens híbridas combinam ambos os tipos de armazenamento, direcionando dados frequentemente acessados para a memória enquanto mantêm grandes volumes em disco:
| Tipo de Armazenamento | Melhor Uso | Desempenho | Uso de Memória |
|---|---|---|---|
| Em Memória (Redis) | Consultas frequentes | Mais rápido | Maior |
| Baseado em Disco | Grandes volumes de dados | Moderado | Menor |
| Híbrido | Cargas de trabalho mistas | Balanceado | Balanceado |
O gerenciamento de cache eficaz exige configurar definições de TTL apropriadas que reflitam a volatilidade dos dados—TTLs curtos (minutos) para dados que mudam rapidamente versus TTLs mais longos (horas/dias) para conteúdo estável—combinados com monitoramento contínuo das taxas de acerto do cache, padrões de remoção e uso de memória para identificar oportunidades de otimização.
Aplicações reais de IA demonstram tanto o potencial transformador quanto a complexidade operacional do gerenciamento de cache em diferentes cenários. Chatbots de atendimento ao cliente usam cache para fornecer respostas consistentes a perguntas frequentes enquanto reduzem custos de inferência em 60-70%, permitindo escalabilidade econômica para milhares de usuários simultâneos. Assistentes de programação armazenam em cache padrões comuns de código e trechos de documentação, permitindo que desenvolvedores recebam sugestões de autocompletar com latências abaixo de 100ms mesmo em períodos de uso intenso. Sistemas de processamento de documentos armazenam em cache embeddings e representações semânticas de documentos frequentemente analisados, acelerando drasticamente buscas por similaridade e tarefas de classificação. No entanto, o gerenciamento de cache em produção impõe desafios significativos: a complexidade da invalidação cresce exponencialmente em sistemas distribuídos, onde a consistência do cache precisa ser mantida entre múltiplos servidores; restrições de recursos forçam escolhas difíceis entre tamanho e cobertura do cache; riscos de segurança emergem quando dados sensíveis em cache exigem criptografia e controles de acesso; e a coordenação de atualizações de cache entre microsserviços pode gerar condições de corrida e inconsistências nos dados. Soluções abrangentes de monitoramento que acompanham a atualidade do cache, taxas de acerto e eventos de invalidação tornam-se essenciais para manter a confiabilidade do sistema e identificar quando as estratégias de cache precisam ser ajustadas conforme os padrões de dados e o comportamento dos usuários mudam.
A invalidação de cache remove ou atualiza dados obsoletos quando ocorrem alterações, proporcionando atualização imediata, mas exigindo gatilhos orientados a eventos. A expiração de cache define um limite de tempo (TTL) para quanto tempo os dados permanecem em cache, oferecendo implementação mais simples, mas podendo servir dados desatualizados se o TTL for muito longo. Muitos sistemas combinam ambas as abordagens para desempenho ideal.
Um gerenciamento de cache eficaz pode reduzir custos de API em 50-90%, dependendo das taxas de acerto de cache e da arquitetura do sistema. O cache de prompts da OpenAI oferece 50% de redução de custos em tokens em cache, enquanto a Anthropic oferece até 90% de redução. As economias reais dependem dos padrões de consulta e de quanto dado pode ser efetivamente armazenado em cache.
O cache de prompts armazena estados intermediários do modelo e sequências de tokens para evitar o reprocessamento de entradas idênticas ou semelhantes em grandes modelos de linguagem. Ele suporta cache exato (correspondências caracter por caracter) e cache semântico (prompts funcionalmente equivalentes com redação diferente). Isso reduz a latência em 80% e os custos em 50-90% para consultas repetidas.
As principais estratégias são: Expiração Baseada em Tempo (TTL) para remoção automática após tempo definido, Invalidação Baseada em Eventos para atualizações imediatas quando os dados mudam, Invalidação Semântica para consultas semelhantes com base no significado e Abordagens Híbridas combinando múltiplas estratégias. A escolha depende da volatilidade dos dados e das necessidades de atualização.
O cache em memória (como Redis) oferece velocidades de acesso em microssegundos, ideal para consultas frequentes, mas consome muita RAM. O cache baseado em disco comporta conjuntos de dados maiores e persiste após reinicializações, mas introduz latência em milissegundos. Abordagens híbridas combinam ambos, direcionando dados frequentemente acessados para a memória enquanto mantêm grandes volumes em disco.
TTL é um temporizador regressivo que determina quanto tempo os dados em cache permanecem válidos antes da expiração. TTLs curtos (minutos) servem para dados que mudam rapidamente, enquanto TTLs longos (horas/dias) funcionam para conteúdo estável. Configurar o TTL adequadamente equilibra a atualidade dos dados com a necessidade de evitar atualizações desnecessárias de cache e sobrecarga nos servidores.
Um gerenciamento de cache eficaz permite que sistemas de IA lidem com muito mais solicitações sem expansão proporcional da infraestrutura. Ao reduzir a carga computacional por solicitação por meio do cache, sistemas podem atender milhões de usuários de forma mais econômica. As taxas de acerto do cache determinam diretamente os custos de infraestrutura e a satisfação dos usuários em ambientes de produção.
O cache de dados sensíveis introduz vulnerabilidades de segurança se não for devidamente criptografado e controlado o acesso. Os riscos incluem acesso não autorizado às informações em cache, exposição de dados durante a invalidação do cache e armazenamento inadvertido de conteúdo confidencial. Criptografia abrangente, controles de acesso e monitoramento são essenciais para proteger dados sensíveis armazenados em cache.
O AmICited acompanha como os sistemas de IA referenciam sua marca e garante que seu conteúdo permaneça atualizado nos caches de IA. Obtenha visibilidade sobre o gerenciamento de cache de IA e a atualidade do conteúdo em GPTs, Perplexity e Google AI Overviews.
Aprenda como gerenciar o acesso de crawlers de IA ao conteúdo do seu site. Entenda a diferença entre crawlers de treinamento e de busca, implemente controles vi...

Saiba mais sobre governança de conteúdo de IA – as políticas, processos e estruturas que as organizações usam para gerenciar a estratégia de conteúdo em platafo...

Saiba como detectar, responder e prevenir crises geradas por IA que ameaçam a reputação da marca. Descubra estratégias de monitoramento em tempo real, playbooks...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.