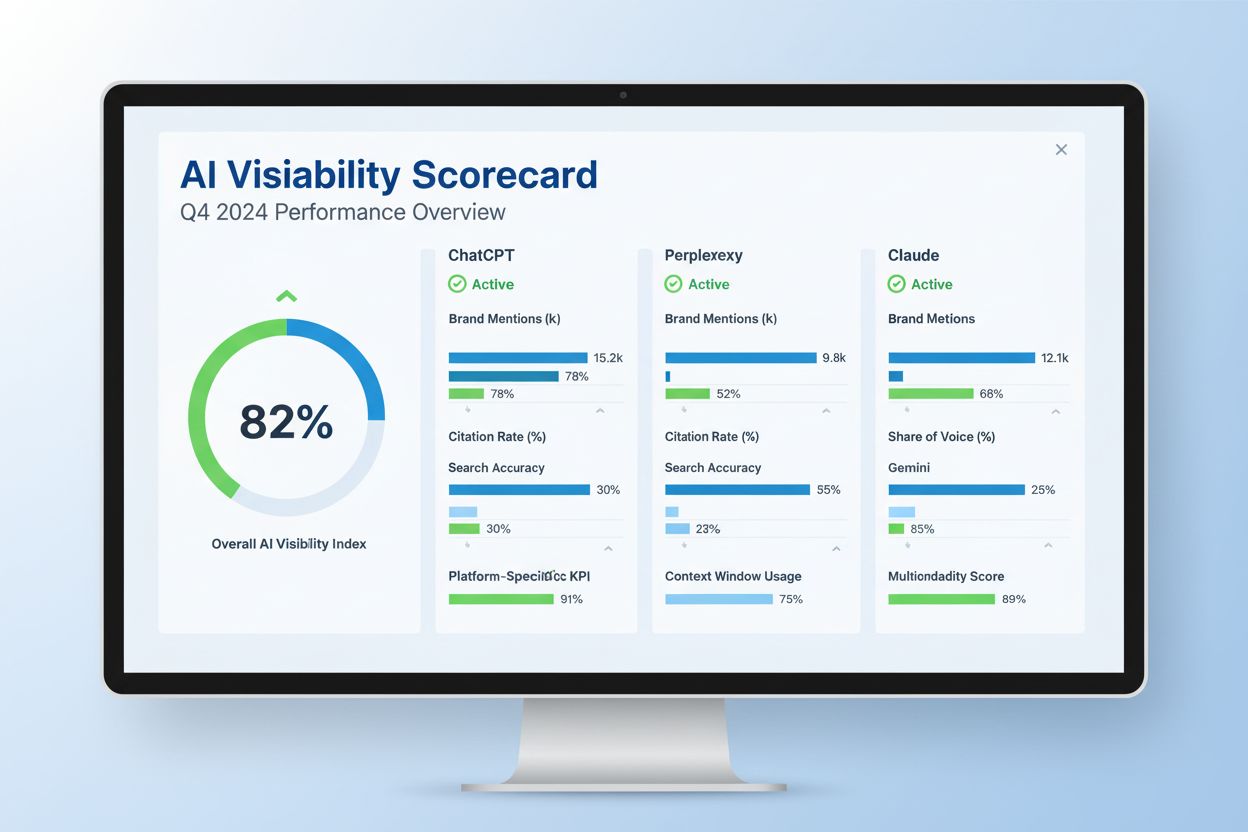
Pontuação de Visibilidade em IA
Descubra o que é uma Pontuação de Visibilidade em IA e como ela mede a presença da sua marca no ChatGPT, Perplexity, Claude e outras plataformas de IA. Métrica ...
16 min de leitura

Pontuação de Recuperação por IA é o processo de quantificar a relevância e qualidade de documentos ou trechos recuperados em relação a uma consulta do usuário. Utiliza algoritmos sofisticados para avaliar o significado semântico, a adequação contextual e a qualidade da informação, determinando quais fontes são passadas para modelos de linguagem para geração de respostas em sistemas RAG.
Pontuação de Recuperação por IA é o processo de quantificar a relevância e qualidade de documentos ou trechos recuperados em relação a uma consulta do usuário. Utiliza algoritmos sofisticados para avaliar o significado semântico, a adequação contextual e a qualidade da informação, determinando quais fontes são passadas para modelos de linguagem para geração de respostas em sistemas RAG.
Pontuação de Recuperação por IA é o processo de quantificar a relevância e qualidade de documentos ou trechos recuperados em relação a uma consulta ou tarefa do usuário. Diferente da simples correspondência de palavras-chave, que apenas identifica a sobreposição superficial de termos, a pontuação de recuperação utiliza algoritmos sofisticados para avaliar significado semântico, adequação contextual e qualidade da informação. Esse mecanismo de pontuação é fundamental para sistemas de Geração Aumentada por Recuperação (RAG), onde determina quais fontes são passadas para modelos de linguagem gerarem respostas. Em aplicações modernas de LLM, a pontuação de recuperação impacta diretamente a precisão das respostas, a redução de alucinações e a satisfação do usuário, ao garantir que apenas as informações mais relevantes cheguem à etapa de geração. A qualidade da pontuação de recuperação é, portanto, um componente crítico para o desempenho e a confiabilidade geral do sistema.
A pontuação de recuperação emprega múltiplas abordagens algorítmicas, cada uma com pontos fortes distintos para diferentes casos de uso. A pontuação por similaridade semântica utiliza modelos de embeddings para medir o alinhamento conceitual entre consultas e documentos no espaço vetorial, capturando significados além das palavras-chave superficiais. O BM25 (Best Matching 25) é uma função probabilística de ranqueamento que considera frequência de termos, frequência inversa de documentos e normalização pelo tamanho do documento, sendo altamente eficaz para recuperação de texto tradicional. O TF-IDF (Term Frequency-Inverse Document Frequency) pondera termos com base em sua importância nos documentos e nas coleções, embora não compreenda semântica. Abordagens híbridas combinam múltiplos métodos—como a junção de pontuações de BM25 e semântica—para aproveitar sinais lexicais e semânticos. Além dos métodos de pontuação, métricas de avaliação como Precision@k (porcentagem de resultados relevantes entre os top-k), Recall@k (porcentagem de todos os documentos relevantes encontrados nos top-k), NDCG (Normalized Discounted Cumulative Gain, que considera a posição no ranqueamento) e MRR (Mean Reciprocal Rank) fornecem medidas quantitativas de qualidade de recuperação. Entender os pontos fortes e fracos de cada abordagem—como a eficiência do BM25 versus a compreensão profunda da pontuação semântica—é essencial para selecionar métodos adequados para aplicações específicas.
| Método de Pontuação | Como Funciona | Melhor Para | Vantagem Chave |
|---|---|---|---|
| Similaridade Semântica | Compara embeddings usando similaridade cosseno ou outras métricas de distância | Significado conceitual, sinônimos, paráfrases | Captura relações semânticas além das palavras-chave |
| BM25 | Ranqueamento probabilístico considerando frequência de termos e tamanho do documento | Correspondência exata de frases, consultas por palavras-chave | Rápido, eficiente, comprovado em produção |
| TF-IDF | Pondera termos pela frequência no documento e raridade na coleção | Recuperação de informações tradicional | Simples, interpretável, leve |
| Pontuação Híbrida | Combina abordagens semânticas e por palavras-chave com fusão ponderada | Recuperação geral, consultas complexas | Aproveita os pontos fortes de vários métodos |
| Pontuação baseada em LLM | Usa modelos de linguagem para julgar relevância com prompts personalizados | Avaliação de contexto complexo, tarefas específicas de domínio | Captura relações semânticas sutis |
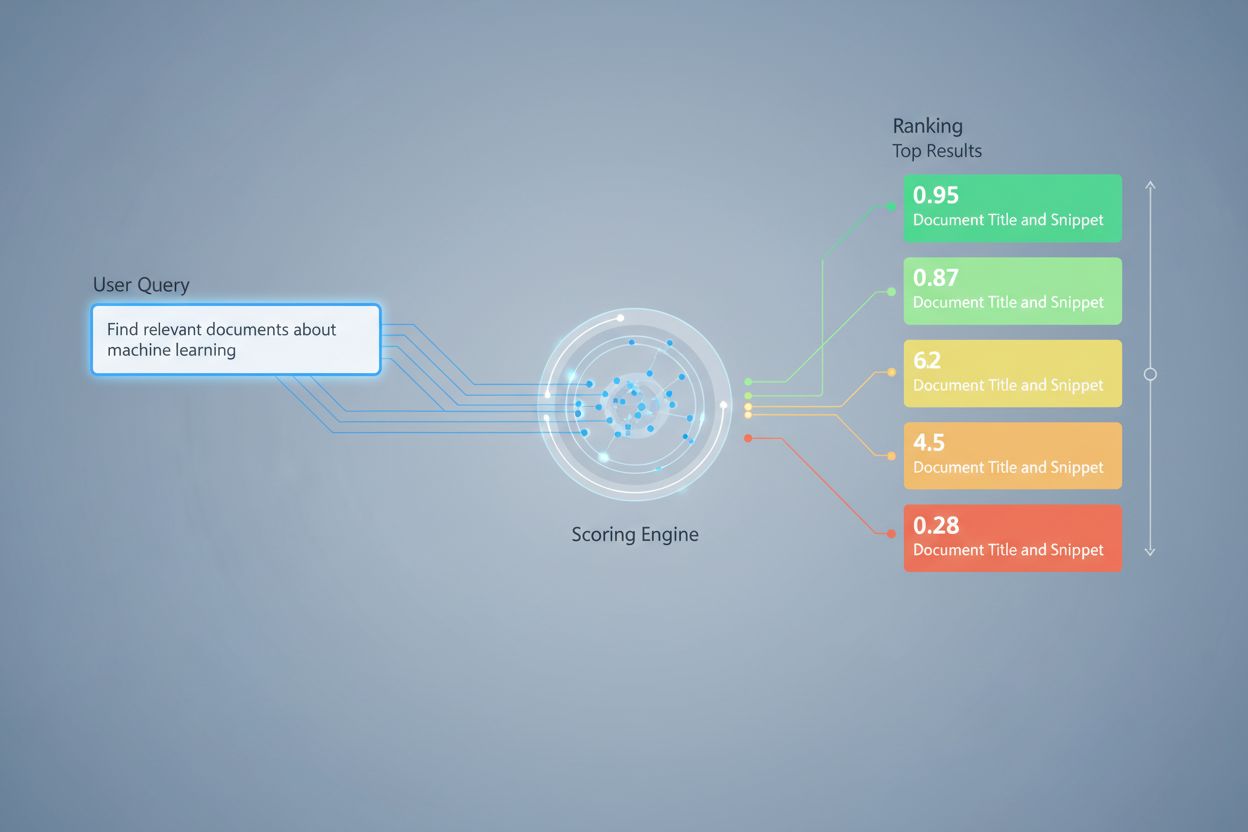
Em sistemas RAG, a pontuação de recuperação opera em múltiplos níveis para assegurar a qualidade da geração. Tipicamente, o sistema pontua trechos individuais dentro de documentos, permitindo uma avaliação de relevância mais granular do que tratar documentos inteiros como unidades atômicas. Essa pontuação de relevância por trecho permite ao sistema extrair apenas os segmentos de informação mais pertinentes, reduzindo o ruído e o contexto irrelevante que poderia confundir o modelo de linguagem. Sistemas RAG frequentemente implementam limiares de pontuação ou mecanismos de corte que filtram resultados com baixa pontuação antes que cheguem à etapa de geração, impedindo que fontes de baixa qualidade influenciem a resposta final. A qualidade do contexto recuperado correlaciona-se diretamente com a qualidade da geração—trechos relevantes e bem pontuados levam a respostas mais precisas e fundamentadas, enquanto recuperações de baixa qualidade introduzem alucinações e erros factuais. Monitorar as pontuações de recuperação fornece sinais de alerta precoce para degradação do sistema, tornando-se uma métrica chave para monitoramento de respostas de IA e garantia de qualidade em sistemas de produção.
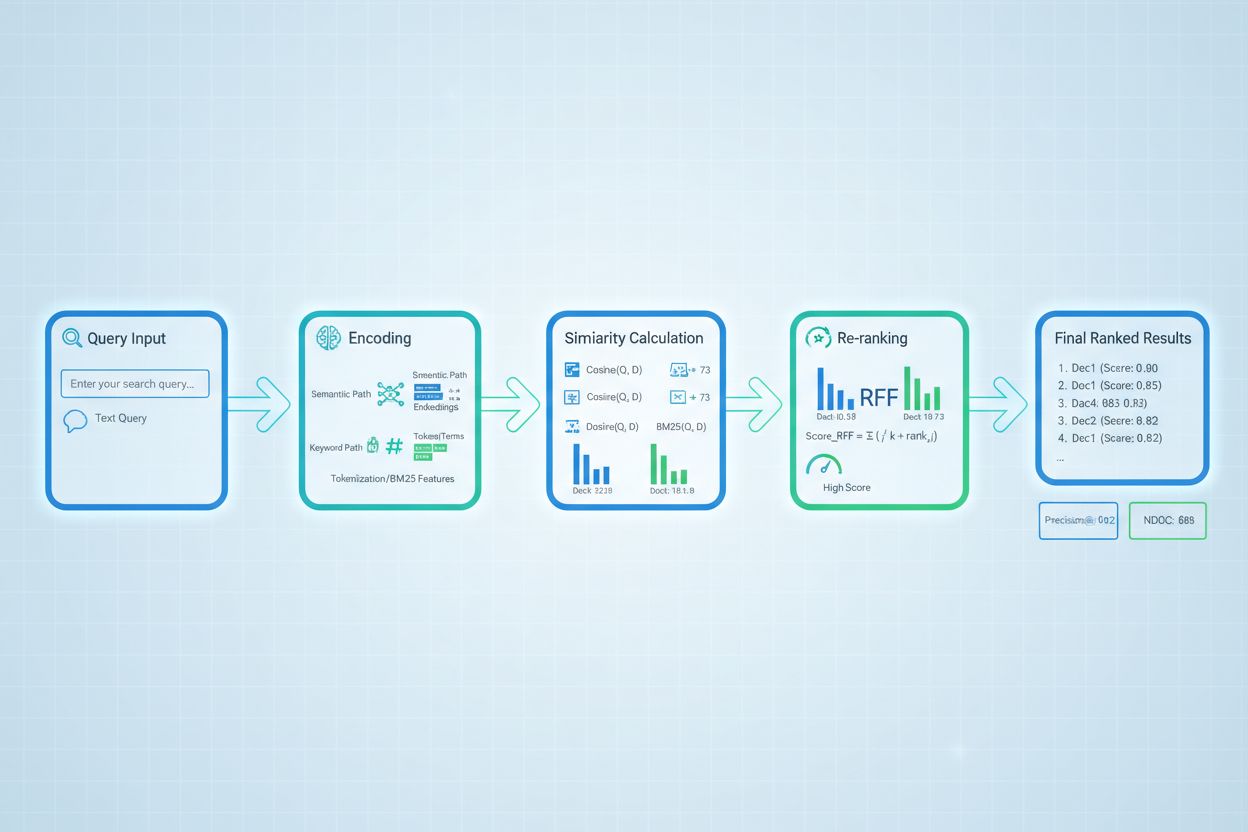
O re-ranqueamento atua como um mecanismo de filtragem de segunda passagem que refina os resultados iniciais da recuperação, frequentemente melhorando significativamente a precisão do ranqueamento. Após um recuperador inicial gerar resultados candidatos com pontuações preliminares, um re-ranqueador aplica uma lógica de pontuação mais sofisticada para reordenar ou filtrar esses candidatos, normalmente usando modelos mais caros computacionalmente que podem realizar análises mais profundas. O Reciprocal Rank Fusion (RRF) é uma técnica popular que combina ranqueamentos de múltiplos recuperadores, atribuindo pontuações com base na posição do resultado e fundindo essas pontuações para produzir um ranqueamento unificado, muitas vezes superando recuperadores individuais. A normalização das pontuações torna-se crítica ao combinar resultados de diferentes métodos de recuperação, pois pontuações brutas de BM25, similaridade semântica e outros métodos operam em escalas distintas e devem ser calibradas para faixas comparáveis. Abordagens ensemble de recuperadores utilizam múltiplas estratégias de recuperação simultaneamente, com o re-ranqueamento determinando a ordem final com base nas evidências combinadas. Essa abordagem de múltiplos estágios melhora significativamente a precisão e a robustez do ranqueamento em comparação com a recuperação de estágio único, especialmente em domínios complexos onde diferentes métodos capturam sinais complementares de relevância.
Precision@k: Mede a proporção de documentos relevantes entre os top-k resultados; útil para avaliar se os resultados recuperados são confiáveis (ex: Precision@5 = 4/5 significa 80% dos 5 primeiros resultados são relevantes)
Recall@k: Calcula o percentual de todos os documentos relevantes encontrados entre os top-k resultados; importante para garantir cobertura abrangente das informações relevantes disponíveis
Hit Rate: Métrica binária que indica se pelo menos um documento relevante aparece entre os top-k resultados; útil para verificações rápidas de qualidade em sistemas de produção
NDCG (Normalized Discounted Cumulative Gain): Considera a posição no ranqueamento, atribuindo maior valor a documentos relevantes que aparecem antes; varia de 0 a 1 e é ideal para avaliar a qualidade do ranqueamento
MRR (Mean Reciprocal Rank): Mede a posição média do primeiro resultado relevante em múltiplas consultas; útil especialmente para avaliar se o documento mais relevante está bem posicionado
F1 Score: Média harmônica de precisão e recall; fornece avaliação equilibrada quando falsos positivos e negativos têm igual importância
MAP (Mean Average Precision): Faz a média das precisões em cada posição onde um documento relevante é encontrado; métrica abrangente para a qualidade geral do ranqueamento em múltiplas consultas
A pontuação de relevância baseada em LLM utiliza os próprios modelos de linguagem como juízes de relevância dos documentos, oferecendo uma alternativa flexível aos métodos algorítmicos tradicionais. Nesse paradigma, prompts cuidadosamente elaborados instruem um LLM a avaliar se um trecho recuperado responde a uma determinada consulta, produzindo pontuações binárias de relevância (relevante/não relevante) ou pontuações numéricas (ex: escala de 1 a 5 indicando o grau de relevância). Essa abordagem captura relações semânticas sutis e relevância específica de domínio que algoritmos tradicionais podem não identificar, especialmente para consultas complexas que exigem compreensão profunda. No entanto, a pontuação baseada em LLM traz desafios como custo computacional (inferência de LLM é cara em comparação com similaridade de embeddings), possível inconsistência entre diferentes prompts e modelos, e a necessidade de calibração com rótulos humanos para garantir que as pontuações correspondam à relevância real. Apesar dessas limitações, a pontuação por LLM tem se mostrado valiosa para avaliar a qualidade de sistemas RAG e criar dados de treinamento para modelos especializados de pontuação, tornando-se uma ferramenta importante no monitoramento de IA para avaliação da qualidade das respostas.
Implementar uma pontuação de recuperação eficaz requer consideração cuidadosa de vários fatores práticos. A escolha do método depende dos requisitos do caso de uso: a pontuação semântica é excelente para captar significado, mas exige modelos de embeddings, enquanto o BM25 oferece velocidade e eficiência para correspondência lexical. O equilíbrio entre velocidade e precisão é crucial—a pontuação baseada em embeddings proporciona melhor compreensão de relevância, porém com custos de latência, enquanto BM25 e TF-IDF são mais rápidos, mas menos sofisticados semanticamente. As considerações de custo computacional incluem tempo de inferência do modelo, requisitos de memória e necessidades de escalabilidade da infraestrutura, especialmente importantes para sistemas de produção de alto volume. O ajuste de parâmetros envolve calibrar limiares, pesos em abordagens híbridas e cortes de re-ranqueamento para otimizar o desempenho em domínios e casos de uso específicos. O monitoramento contínuo do desempenho da pontuação por meio de métricas como NDCG e Precision@k ajuda a identificar degradação ao longo do tempo, permitindo melhorias proativas no sistema e garantindo qualidade consistente das respostas em sistemas RAG de produção.
Técnicas avançadas de pontuação de recuperação vão além da avaliação básica de relevância para capturar relações contextuais complexas. A reescrita de consultas pode melhorar a pontuação ao reformular consultas do usuário em múltiplas formas semanticamente equivalentes, permitindo ao recuperador encontrar documentos relevantes que poderiam ser ignorados pela correspondência literal. Embeddings de Documentos Hipotéticos (HyDE) geram documentos sintéticos relevantes a partir das consultas e usam esses hipotéticos para melhorar a pontuação de recuperação ao encontrar documentos reais semelhantes ao conteúdo idealizado. Abordagens de múltiplas consultas submetem várias variações da consulta aos recuperadores e agregam suas pontuações, aumentando a robustez e abrangência em comparação à recuperação com uma única consulta. Modelos de pontuação específicos de domínio, treinados com dados rotulados de setores ou áreas de conhecimento particulares, podem alcançar desempenho superior em relação a modelos generalistas, sendo especialmente valiosos para aplicações especializadas como sistemas de IA médicos ou jurídicos. Ajustes contextuais de pontuação levam em conta fatores como atualidade do documento, autoridade da fonte e contexto do usuário, permitindo avaliações de relevância mais sofisticadas que vão além da similaridade semântica pura para incorporar fatores de relevância do mundo real críticos para sistemas de IA em produção.
A pontuação de recuperação atribui valores numéricos de relevância aos documentos com base em sua relação com uma consulta, enquanto o ranqueamento ordena os documentos com base nessas pontuações. A pontuação é o processo de avaliação, o ranqueamento é o resultado da ordenação. Ambos são essenciais para sistemas RAG entregarem respostas precisas.
A pontuação de recuperação determina quais fontes chegam ao modelo de linguagem para geração de respostas. Uma pontuação de alta qualidade garante a seleção de informações relevantes, reduzindo alucinações e melhorando a precisão das respostas. Uma pontuação ruim leva a contextos irrelevantes e respostas de IA não confiáveis.
A pontuação semântica usa embeddings para entender o significado conceitual e captura sinônimos e conceitos relacionados. A pontuação baseada em palavras-chave (como BM25) corresponde termos e frases exatas. A pontuação semântica é melhor para compreender a intenção, enquanto a pontuação por palavras-chave se destaca em encontrar informações específicas.
Métricas-chave incluem Precision@k (precisão dos melhores resultados), Recall@k (abrangência de documentos relevantes), NDCG (qualidade do ranqueamento) e MRR (posição do primeiro resultado relevante). Escolha as métricas de acordo com seu caso de uso: Precision@k para sistemas focados em qualidade, Recall@k para cobertura abrangente.
Sim, a pontuação baseada em LLM utiliza modelos de linguagem como juízes para avaliar a relevância. Essa abordagem captura relações semânticas sutis, mas é computacionalmente cara. É valiosa para avaliar a qualidade de RAG e criar dados de treinamento, embora exija calibração com rótulos humanos.
O re-ranqueamento aplica uma filtragem de segunda passagem usando modelos mais sofisticados para refinar os resultados iniciais. Técnicas como Reciprocal Rank Fusion combinam múltiplos métodos de recuperação, melhorando a precisão e robustez. O re-ranqueamento supera significativamente a recuperação em estágio único em domínios complexos.
BM25 e TF-IDF são rápidos e leves, adequados para sistemas em tempo real. A pontuação semântica requer inferência de modelos de embeddings, adicionando latência. A pontuação baseada em LLM é a mais cara. Escolha de acordo com seus requisitos de latência e recursos computacionais disponíveis.
Considere suas prioridades: pontuação semântica para tarefas focadas em significado, BM25 para velocidade e eficiência, abordagens híbridas para desempenho equilibrado. Avalie em seu domínio específico usando métricas como NDCG e Precision@k. Teste múltiplos métodos e meça seu impacto na qualidade final das respostas.
Acompanhe como sistemas de IA como ChatGPT, Perplexity e Google AI referenciam sua marca e avalie a qualidade de sua recuperação e classificação de fontes. Garanta que seu conteúdo seja devidamente citado e ranqueado pelos sistemas de IA.
Descubra o que é uma Pontuação de Visibilidade em IA e como ela mede a presença da sua marca no ChatGPT, Perplexity, Claude e outras plataformas de IA. Métrica ...

Saiba como a pontuação de relevância de conteúdo usa algoritmos de IA para medir o quão bem o conteúdo corresponde às consultas e intenções do usuário. Entenda ...
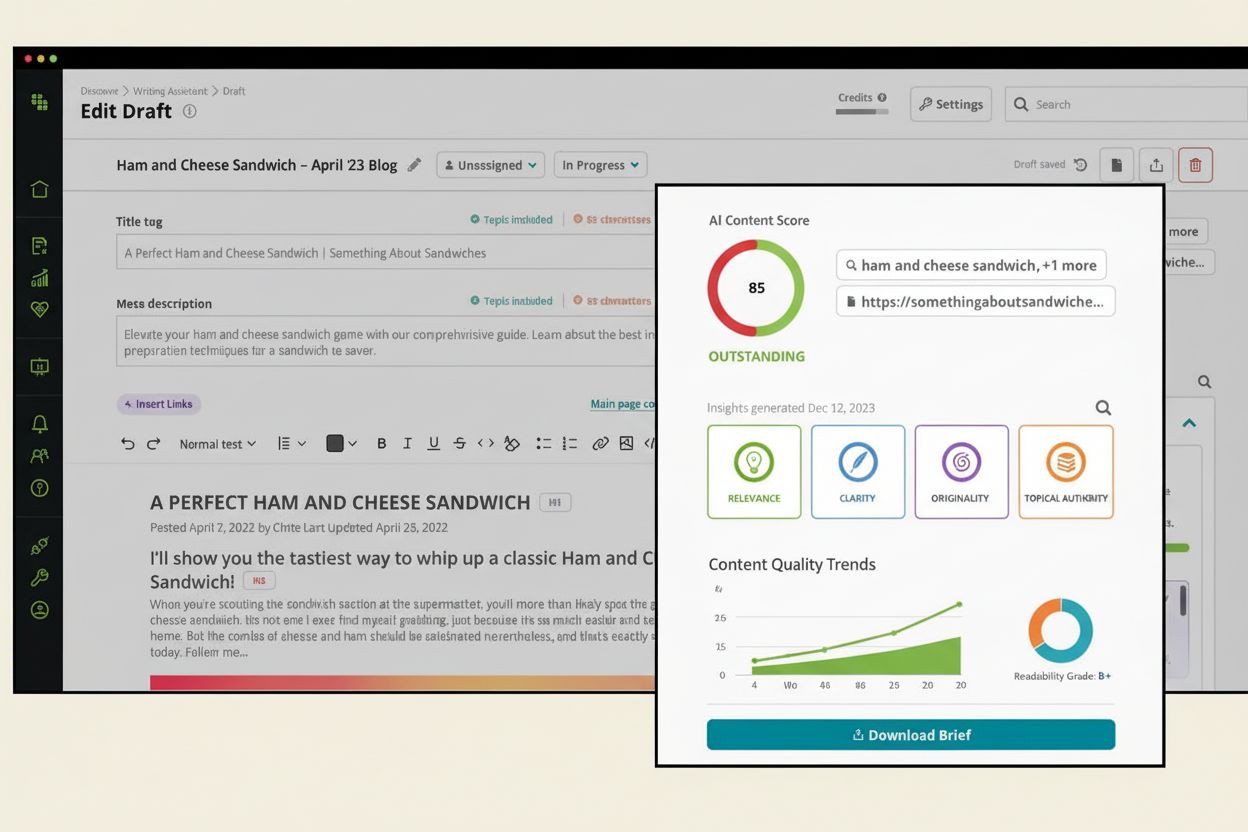
Descubra o que é a Pontuação de Conteúdo de IA, como ela avalia a qualidade do conteúdo para sistemas de IA e por que é importante para a visibilidade no ChatGP...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.