Mecanismos técnicos e legais que permitem criadores de conteúdo e detentores de direitos autorais impedirem que seu trabalho seja usado em conjuntos de dados de treinamento de grandes modelos de linguagem. Esses incluem diretivas de robots.txt, declarações legais de opt-out e proteções contratuais sob regulamentações como a Lei de IA da UE.
Opt-Out de Treinamento de IA
Mecanismos técnicos e legais que permitem criadores de conteúdo e detentores de direitos autorais impedirem que seu trabalho seja usado em conjuntos de dados de treinamento de grandes modelos de linguagem. Esses incluem diretivas de robots.txt, declarações legais de opt-out e proteções contratuais sob regulamentações como a Lei de IA da UE.
O que é Opt-Out de Treinamento de IA?
Opt-out de treinamento de IA refere-se aos mecanismos técnicos e legais que permitem criadores de conteúdo, detentores de direitos autorais e proprietários de sites impedirem que seu trabalho seja usado em conjuntos de dados de treinamento de grandes modelos de linguagem (LLM). À medida que empresas de IA coletam vastas quantidades de dados da internet para treinar modelos cada vez mais sofisticados, a capacidade de controlar se seu conteúdo participa neste processo tornou-se essencial para proteger propriedade intelectual e manter controle criativo. Esses mecanismos de opt-out operam em dois níveis: diretivas técnicas que instruem crawlers de IA a pular seu conteúdo, e frameworks legais que estabelecem direitos contratuais para excluir seu trabalho de conjuntos de dados de treinamento. Entender ambas as dimensões é crucial para qualquer pessoa preocupada com como seu conteúdo está sendo usado na era da IA.
Mecanismos Técnicos: robots.txt e User Agents
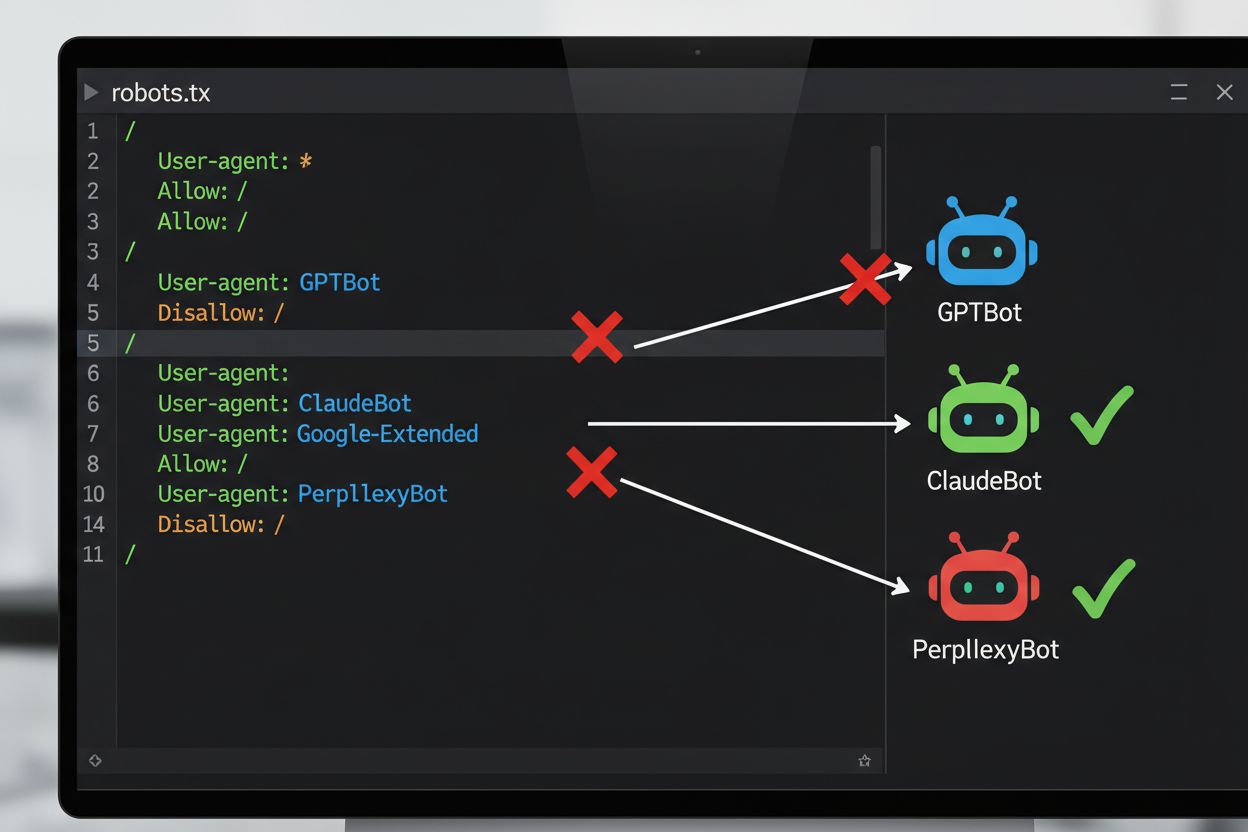
O método técnico mais comum para opt-out de treinamento de IA é através do arquivo robots.txt, um arquivo de texto simples colocado no diretório raiz de um site que comunica permissões de crawler a bots automatizados. Quando um crawler de IA visita seu site, ele primeiro verifica robots.txt para ver se tem permissão para acessar seu conteúdo. Adicionando diretivas disallow específicas para user agents de crawlers particulares, você pode instruir bots de IA a pular seu site inteiramente. Cada empresa de IA opera múltiplos crawlers com identificadores de user agent distintos—esses são essencialmente os “nomes” que bots usam para se identificar ao fazer solicitações. Por exemplo, GPTBot da OpenAI se identifica com a string de user agent “GPTBot”, enquanto ClaudeBot da Anthropic usa “ClaudeBot”. A sintaxe é direta: você especifica o nome do user agent e então declara quais caminhos são desabilitados, como “Disallow: /” para bloquear o site inteiro.
O cenário legal para opt-out de treinamento de IA evoluiu significativamente com a introdução da Lei de IA da UE, que entrou em vigor em 2024 e incorpora disposições da Diretiva de Mineração de Texto e Dados (TDM). Sob essas regulamentações, desenvolvedores de IA são autorizados a usar trabalhos protegidos por direitos autorais para propósitos de aprendizado de máquina apenas se tiverem acesso legal ao conteúdo e o detentor dos direitos autorais não tiver expressamente reservado o direito de excluir seu trabalho de mineração de texto e dados. Isso cria um mecanismo legal formal para opt-out: detentores de direitos autorais podem arquivar reservas de opt-out com seus trabalhos, efetivamente impedindo seu uso em treinamento de IA sem permissão explícita. A Lei de IA da UE representa uma mudança significativa da abordagem anterior de “mova rápido e quebre coisas”, estabelecendo que empresas treinando modelos de IA devem verificar se detentores de direitos reservaram seu conteúdo e implementar salvaguardas técnicas e organizacionais para prevenir uso inadvertido de trabalhos com opt-out. Este framework legal aplica-se em toda a União Europeia e influencia como empresas globais de IA abordam coleta de dados e práticas de treinamento.
Como Mecanismos de Opt-Out Funcionam na Prática
Implementar um mecanismo de opt-out envolve tanto configuração técnica quanto documentação legal. No lado técnico, proprietários de sites adicionam diretivas disallow ao seu arquivo robots.txt para user agents específicos de crawlers de IA, que crawlers conformes respeitarão ao visitar o site. No lado legal, detentores de direitos autorais podem arquivar declarações de opt-out com sociedades coletoras e organizações de direitos—por exemplo, a sociedade coletora holandesa Pictoright e a sociedade de música francesa SACEM estabeleceram procedimentos formais de opt-out permitindo que criadores reservem seus direitos contra uso em treinamento de IA. Muitos sites e criadores de conteúdo agora incluem declarações explícitas de opt-out em seus termos de serviço ou metadados, declarando que seu conteúdo não deve ser usado para treinamento de modelos de IA. No entanto, a eficácia desses mecanismos depende da conformidade do crawler: enquanto grandes empresas como OpenAI, Google e Anthropic declararam publicamente que respeitam diretivas de robots.txt e reservas de opt-out, a falta de um mecanismo de aplicação centralizado significa que determinar se uma solicitação de opt-out foi propriamente respeitada requer monitoramento e verificação contínuos.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Desafios e Limitações do Opt-Out
Apesar da disponibilidade de mecanismos de opt-out, desafios significativos limitam sua eficácia:
Padrão Voluntário: robots.txt é um acordo de cavalheiros sem mecanismo de aplicação legal, significando que crawlers não conformes podem simplesmente ignorar suas diretivas
Evasão de Crawler: Bots sofisticados podem falsificar strings de user agent para se disfarçar como navegadores legítimos, contornando bloqueio baseado em user-agent
Rotação de IP: Scrapeadores podem circular através de centenas de milhares de endereços IP via proxies ou botnets, tornando bloqueio baseado em IP ineficaz
Cobertura Incompleta: robots.txt para aproximadamente 40-60% dos bots de IA, deixando tráfego significativo desbloqueado sem medidas técnicas adicionais
Crawlers Desonestos: Empresas de IA não respeitáveis e scrapeadores independentes podem ignorar mecanismos de opt-out inteiramente, operando em áreas cinzentas legais
Lacunas de Aplicação: Mesmo quando violações de opt-out ocorrem, recurso legal é caro e lento, com resultados incertos em tribunal
Melhores Práticas para Criadores de Conteúdo
Para proteger efetivamente seu conteúdo de uso não autorizado em treinamento de IA, adote uma abordagem em camadas combinando medidas técnicas e legais. Primeiro, implemente diretivas de robots.txt para todos os principais crawlers de treinamento de IA (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot e outros), entendendo que isso fornece uma defesa de linha de base contra empresas conformes. Segundo, adicione declarações explícitas de opt-out aos termos de serviço e metadados do seu site, declarando claramente que seu conteúdo não deve ser usado para treinamento de modelos de IA—isso fortalece sua posição legal se violações ocorrerem. Terceiro, monitore sua configuração regularmente usando ferramentas de teste e logs de servidor para verificar se crawlers estão respeitando suas diretivas, e atualize seu robots.txt trimestralmente já que novos crawlers de IA surgem constantemente. Quarto, considere medidas técnicas adicionais como filtragem de user agent ou limitação de taxa se você tiver recursos técnicos, reconhecendo que estas fornecem proteção incremental contra scrapeadores mais sofisticados. Finalmente, documente seus esforços de opt-out minuciosamente, pois esta documentação torna-se crucial se você precisar buscar ação legal contra empresas que ignoram suas diretivas. Lembre-se que opt-out não é uma configuração única mas um processo contínuo que requer vigilância e adaptação conforme o cenário de IA continua evoluindo.
Perguntas frequentes
Qual é a diferença entre opt-out de robots.txt e opt-out legal?
robots.txt é um padrão técnico voluntário que instrui crawlers a pular seu conteúdo, enquanto opt-out legal envolve arquivar reservas formais com organizações de direitos autorais ou incluir cláusulas contratuais em seus termos de serviço. robots.txt é mais fácil de implementar mas carece de aplicação, enquanto opt-out legal fornece proteção legal mais forte mas requer procedimentos mais formais.
Todas as empresas de IA respeitam diretivas de robots.txt?
Grandes empresas de IA como OpenAI, Google, Anthropic e Perplexity declararam publicamente que respeitam diretivas de robots.txt. No entanto, robots.txt é um padrão voluntário sem mecanismo de aplicação, então crawlers não conformes e scrapeadores desonestos podem ignorar suas diretivas inteiramente.
Bloquear bots de treinamento de IA afetará meus rankings de busca?
Não. Bloquear crawlers de treinamento de IA como GPTBot e ClaudeBot não impactará seus rankings de busca do Google ou Bing porque mecanismos de busca tradicionais usam crawlers diferentes (Googlebot, Bingbot) que operam independentemente. Só bloqueie esses se você quiser desaparecer completamente dos resultados de busca.
Qual é a abordagem da Lei de IA da UE para opt-out?
A Lei de IA da UE exige que desenvolvedores de IA tenham acesso legal ao conteúdo e devem respeitar reservas de opt-out de detentores de direitos autorais. Detentores de direitos autorais podem arquivar declarações de opt-out com seus trabalhos, efetivamente impedindo seu uso em treinamento de IA sem permissão explícita. Isso cria um mecanismo legal formal para proteger conteúdo de uso não autorizado em treinamento.
Posso usar opt-out para impedir que meu conteúdo apareça em resultados de busca de IA?
Depende do mecanismo específico. Bloquear todos os crawlers de IA impedirá que seu conteúdo apareça em resultados de busca de IA, mas isso também remove você de plataformas de busca alimentadas por IA inteiramente. Alguns editores preferem bloqueio seletivo—permitindo crawlers focados em busca enquanto bloqueiam crawlers focados em treinamento—para manter visibilidade em busca de IA enquanto protegem conteúdo de treinamento de modelos.
O que acontece se uma empresa de IA ignorar meu opt-out?
Se uma empresa de IA ignorar suas diretivas de opt-out, você tem recurso legal através de reivindicações de violação de direitos autorais ou quebra de contrato, dependendo da sua jurisdição e circunstâncias específicas. No entanto, ação legal é cara e lenta, com resultados incertos. É por isso que monitoramento e documentação dos seus esforços de opt-out são cruciais.
Com que frequência devo atualizar minha configuração de opt-out?
Revise e atualize sua configuração de robots.txt pelo menos trimestralmente. Novos crawlers de IA surgem constantemente, e empresas frequentemente introduzem novos user agents de crawlers. Por exemplo, Anthropic fundiu seus bots 'anthropic-ai' e 'Claude-Web' em 'ClaudeBot', dando ao novo bot acesso irrestrito temporário a sites que não haviam atualizado suas regras.
Opt-out é eficaz contra todos os crawlers de IA?
Opt-out é eficaz contra empresas de IA conformes e respeitáveis que respeitam robots.txt e frameworks legais. No entanto, é menos eficaz contra crawlers desonestos e scrapeadores não conformes que operam em áreas cinzentas legais. robots.txt para aproximadamente 40-60% dos bots de IA, razão pela qual uma abordagem em camadas combinando múltiplas medidas técnicas e legais é recomendada.
Monitore Como IA Referencia Seu Conteúdo
Rastreie se seu conteúdo aparece em respostas geradas por IA no ChatGPT, Perplexity, Google AI Overviews e outras plataformas de IA com AmICited.
Como Otimizar Seu Conteúdo para Dados de Treinamento de IA e Motores de Busca de IA
Aprenda como otimizar seu conteúdo para inclusão em dados de treinamento de IA. Descubra as melhores práticas para tornar seu site descoberto pelo ChatGPT, Gemi...
Como Empresas de Tecnologia Otimizam para Motores de Busca por IA
Saiba como empresas de tecnologia otimizam conteúdo para motores de busca por IA como ChatGPT, Perplexity e Gemini. Descubra estratégias para visibilidade em IA...
Saiba como profissionais do mercado imobiliário podem otimizar anúncios e serviços para sistemas de busca movidos por IA. Descubra estratégias de Answer Engine ...
11 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.