O que é Burstiness em Conteúdo de IA e Como Isso Afeta a Detecção
Saiba o que significa burstiness em conteúdo gerado por IA, como difere dos padrões de escrita humana e por que é importante para a detecção de IA e autenticida...
9 min de leitura
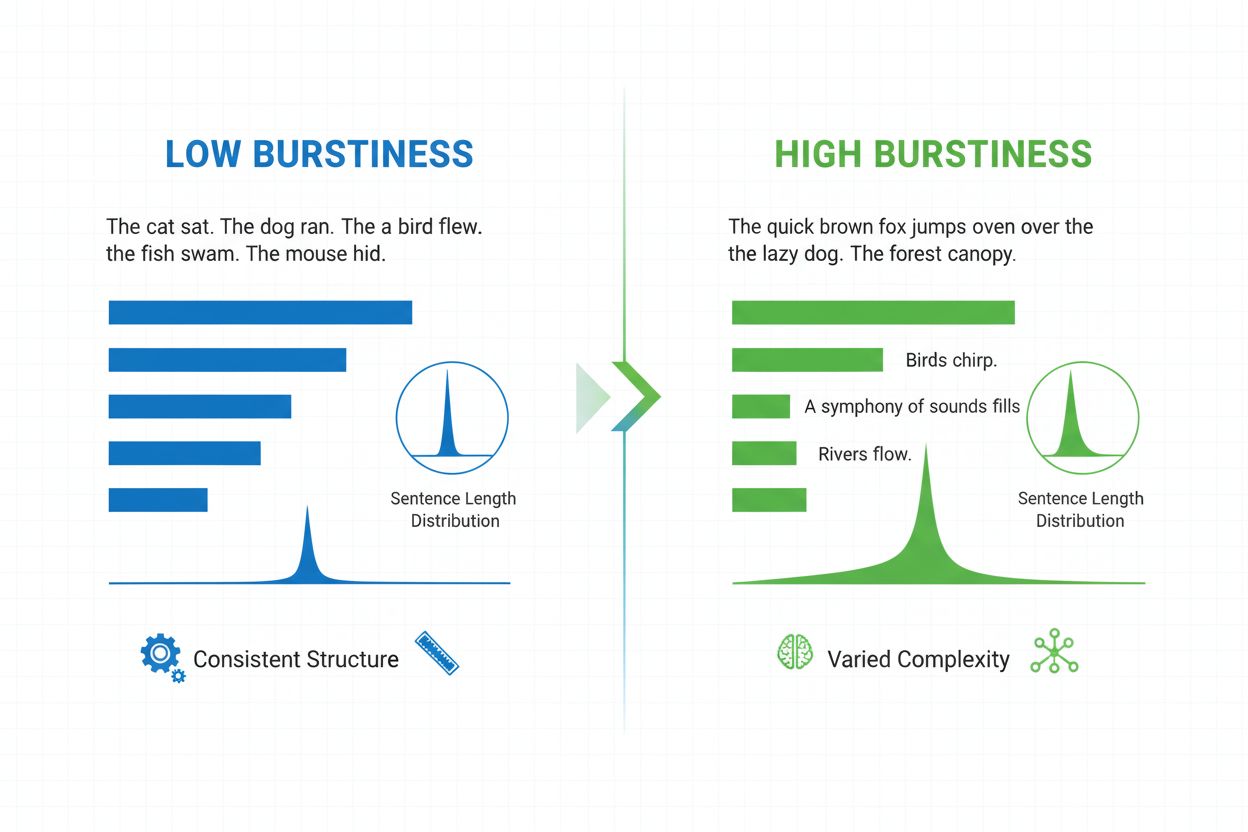
Burstiness é uma métrica linguística que mede a variabilidade do comprimento, estrutura e complexidade das frases ao longo de um documento. Ela quantifica o quanto o escritor alterna entre frases curtas e impactantes e frases mais longas e complexas, servindo como um indicador-chave na detecção de conteúdo gerado por IA e na análise de linguagem natural.
Burstiness é uma métrica linguística que mede a variabilidade do comprimento, estrutura e complexidade das frases ao longo de um documento. Ela quantifica o quanto o escritor alterna entre frases curtas e impactantes e frases mais longas e complexas, servindo como um indicador-chave na detecção de conteúdo gerado por IA e na análise de linguagem natural.
Burstiness é uma métrica linguística quantificável que mede a variabilidade e flutuação do comprimento, estrutura e complexidade das frases ao longo de um documento escrito ou trecho textual. O termo origina-se do conceito de “explosões” de padrões variados de frases — alternando entre frases curtas e concisas e outras mais longas e intrincadas. No contexto do processamento de linguagem natural e detecção de conteúdo por IA, burstiness serve como um indicador crítico para identificar se o texto foi escrito por um humano ou gerado por um sistema de inteligência artificial. Escritores humanos naturalmente produzem textos com alta burstiness porque variam instintivamente a construção das frases com base em ênfase, ritmo e intenção estilística. Por outro lado, textos gerados por IA geralmente apresentam baixa burstiness porque os modelos de linguagem são treinados com padrões estatísticos que favorecem a consistência e previsibilidade. Compreender burstiness é essencial para criadores de conteúdo, educadores, pesquisadores e organizações que monitoram conteúdo gerado por IA em plataformas como ChatGPT, Perplexity, Google AI Overviews e Claude.
O conceito de burstiness surgiu de pesquisas em linguística computacional e teoria da informação, nas quais cientistas buscavam quantificar as propriedades estatísticas da linguagem natural. Trabalhos iniciais em estilometria — a análise estatística do estilo de escrita — identificaram que a escrita humana exibe padrões de variação distintos que diferem fundamentalmente do texto produzido por máquinas. À medida que grandes modelos de linguagem (LLMs) tornaram-se mais sofisticados no início da década de 2020, pesquisadores reconheceram que burstiness, combinada com perplexidade (uma medida de previsibilidade das palavras), poderia servir como indicador confiável de conteúdo gerado por IA. De acordo com pesquisas da QuillBot e instituições acadêmicas, aproximadamente 78% das empresas agora utilizam ferramentas de monitoramento de conteúdo baseadas em IA que incorporam análise de burstiness como parte de seus algoritmos de detecção. O estudo de Stanford de 2023 sobre redações do TOEFL demonstrou que métodos de detecção baseados em burstiness, embora úteis, apresentam limitações significativas — especialmente em relação a falsos positivos na escrita de falantes não nativos de inglês. Essa pesquisa impulsionou o desenvolvimento de sistemas de detecção de IA mais sofisticados e em múltiplas camadas, que consideram burstiness junto a outros marcadores linguísticos, coerência semântica e adequação contextual.
Burstiness é calculada analisando a distribuição estatística dos comprimentos das frases e padrões estruturais dentro de um texto. A métrica quantifica a variância — essencialmente medindo o quanto frases individuais se desviam do comprimento médio das frases em um documento. Um texto com alta burstiness contém frases que variam significativamente em comprimento; por exemplo, um escritor pode seguir uma frase de três palavras (“Entendeu?”) com outra de vinte e cinco palavras contendo múltiplas orações e frases subordinadas. Por outro lado, baixa burstiness indica que a maioria das frases gira em torno de um comprimento semelhante, tipicamente entre doze e dezoito palavras, criando um ritmo monótono. O cálculo envolve várias etapas: primeiro, o sistema mede o comprimento de cada frase em palavras; em seguida, calcula a média do comprimento das frases; por fim, determina o desvio padrão para saber o quanto as frases individuais se afastam dessa média. Um desvio padrão mais alto indica maior variação e, portanto, maior burstiness. Detectores modernos de IA como o Winston AI e o Pangram utilizam algoritmos sofisticados que não apenas contam palavras, mas também analisam a complexidade sintática — o arranjo estrutural de orações, frases e elementos gramaticais. Essa análise mais profunda revela que escritores humanos utilizam diversas estruturas frasais (simples, compostas, complexas e compostas-complexas) em padrões imprevisíveis, enquanto modelos de IA tendem a favorecer determinados templates estruturais que aparecem com frequência em seus dados de treinamento.
| Métrica | Burstiness | Perplexidade | Foco da Medição |
|---|---|---|---|
| Definição | Variação no comprimento e estrutura das frases | Previsibilidade das palavras individuais | Nível da frase vs. nível da palavra |
| Escrita Humana | Alta (estruturas variadas) | Alta (palavras imprevisíveis) | Ritmo natural e vocabulário |
| Texto Gerado por IA | Baixa (estruturas uniformes) | Baixa (palavras previsíveis) | Consistência estatística |
| Aplicação na Detecção | Identifica monotonia estrutural | Identifica padrões de escolha de palavras | Métodos de detecção complementares |
| Risco de Falso Positivo | Maior para escritores ESL | Maior para textos técnicos/acadêmicos | Ambos possuem limitações |
| Método de Cálculo | Desvio padrão do comprimento das frases | Análise de distribuição de probabilidade | Abordagens matemáticas distintas |
| Confiabilidade Isolada | Insuficiente para detecção definitiva | Insuficiente para detecção definitiva | Mais eficaz quando combinado |
Grandes modelos de linguagem como ChatGPT, Claude e Google Gemini são treinados por meio de um processo chamado previsão do próximo token, no qual o modelo aprende a prever a palavra estatisticamente mais provável que deve seguir uma sequência dada. Durante o treinamento, esses modelos são explicitamente otimizados para minimizar a perplexidade em seus conjuntos de dados, o que inadvertidamente gera baixa burstiness como efeito colateral. Quando um modelo encontra repetidamente determinada estrutura frasal em seus dados de treinamento, ele aprende a reproduzi-la com alta probabilidade, resultando em comprimentos de frases consistentes e previsíveis. Pesquisas da Netus AI e Winston AI revelam que modelos de IA exibem uma impressão digital estilométrica distinta caracterizada por construção frasal uniforme, uso excessivo de frases de transição (como “Além disso”, “Portanto”, “Adicionalmente”) e preferência pela voz passiva em vez da ativa. A dependência dos modelos em distribuições de probabilidade faz com que gravitem para os padrões mais comuns nos dados de treinamento, em vez de explorar todo o espectro de construções frasais possíveis. Isso cria uma situação paradoxal: quanto mais dados um modelo é treinado, mais ele aprende a reproduzir padrões comuns e, assim, menor se torna sua burstiness. Além disso, modelos de IA carecem de espontaneidade e variação emocional que caracterizam a escrita humana — eles não escrevem de forma diferente quando estão entusiasmados, frustrados ou enfatizando um ponto específico. Em vez disso, mantêm uma linha de base estilística consistente que reflete o centro estatístico da distribuição de treinamento.
Plataformas de detecção de IA incorporaram a análise de burstiness como um componente central de seus algoritmos, embora com diferentes níveis de sofisticação. Sistemas de detecção iniciais dependiam fortemente de burstiness e perplexidade como métricas primárias, mas pesquisas revelaram limitações significativas nessa abordagem. Segundo a Pangram Labs, detectores baseados em perplexidade e burstiness produzem falsos positivos ao analisar textos dos próprios conjuntos de treinamento dos modelos de linguagem — notavelmente, a Declaração de Independência frequentemente é sinalizada como gerada por IA porque aparece tantas vezes nos dados de treinamento que o modelo lhe atribui perplexidade uniformemente baixa. Sistemas modernos como Winston AI e Pangram agora empregam abordagens híbridas que combinam análise de burstiness com modelos de aprendizado profundo treinados em amostras diversas de textos humanos e gerados por IA. Esses sistemas analisam múltiplas dimensões linguísticas simultaneamente: variação estrutural das frases, diversidade lexical (riqueza de vocabulário), padrões de pontuação, coerência contextual e alinhamento semântico. A integração de burstiness em frameworks de detecção mais amplos aumentou significativamente a precisão — Winston AI reporta 99,98% de acurácia ao distinguir conteúdo gerado por IA do escrito por humanos ao analisar múltiplos marcadores em vez de depender apenas de burstiness. No entanto, a métrica permanece valiosa como um componente de uma estratégia abrangente de detecção, especialmente quando combinada com análise de perplexidade, padrões estilométricos e consistência semântica.
A relação entre burstiness e legibilidade está bem estabelecida na pesquisa linguística. Os índices Flesch Reading Ease e Flesch-Kincaid Grade Level, que medem a acessibilidade do texto, correlacionam-se fortemente com padrões de burstiness. Textos com burstiness mais alta tendem a alcançar melhores índices de legibilidade porque a variação do comprimento das frases previne a fadiga cognitiva e mantém a atenção do leitor. Quando leitores encontram um ritmo consistente de frases de tamanho semelhante, seus cérebros se adaptam ao padrão previsível, o que pode levar ao desinteresse e à redução da compreensão. Por outro lado, alta burstiness cria um efeito de maré que mantém os leitores mentalmente engajados ao variar a carga cognitiva — frases curtas fornecem informações rápidas e digeríveis, enquanto frases mais longas permitem o desenvolvimento de ideias complexas e nuances. Pesquisas da Metrics Masters indicam que alta burstiness gera aproximadamente 15-20% melhor retenção de memória em comparação com textos de baixa burstiness, pois o ritmo variado ajuda a codificar informações de maneira mais eficaz na memória de longo prazo. Esse princípio se aplica a todos os tipos de conteúdo: posts de blog, artigos acadêmicos, textos de marketing e documentação técnica se beneficiam do uso estratégico de burstiness. No entanto, a relação não é linear — burstiness excessiva, que prioriza a variação em detrimento da clareza, pode tornar o texto fragmentado e difícil de acompanhar. A abordagem ideal envolve variação intencional, onde as escolhas de estrutura servem ao significado do conteúdo e à intenção comunicativa do autor, e não apenas ao aumento de uma métrica.
Apesar de sua ampla adoção em sistemas de detecção de IA, a detecção baseada em burstiness apresenta limitações significativas que pesquisadores e profissionais devem entender. A Pangram Labs publicou uma pesquisa abrangente demonstrando cinco principais deficiências: primeiro, textos de conjuntos de dados de treinamento de IA são falsamente classificados como gerados por IA porque os modelos são otimizados para minimizar a perplexidade nesses dados; segundo, os valores de burstiness são relativos a modelos de linguagem específicos, então diferentes modelos produzem perfis de perplexidade distintos; terceiro, modelos comerciais de código fechado como o ChatGPT não expõem probabilidades de tokens, tornando impossível calcular a perplexidade; quarto, falantes não nativos de inglês são desproporcionalmente sinalizados como gerados por IA devido a suas estruturas de frases mais uniformes; e quinto, detectores baseados em burstiness não conseguem se autoaprimorar iterativamente com dados adicionais. O estudo de Stanford de 2023 sobre redações do TOEFL constatou que aproximadamente 26% dos textos de falantes não nativos de inglês foram incorretamente sinalizados como gerados por IA por detectores baseados em perplexidade e burstiness, em comparação com apenas 2% de falsos positivos em textos de nativos. Esse viés levanta sérias questões éticas em ambientes educacionais onde a detecção de IA é usada para avaliar trabalhos de alunos. Além disso, conteúdo orientado por template em marketing, textos acadêmicos e documentação técnica naturalmente apresenta burstiness mais baixa devido a exigências de estilo e convenções estruturais, levando a falsos positivos nesses domínios. Essas limitações impulsionaram o desenvolvimento de abordagens de detecção mais sofisticadas que tratam burstiness como um sinal entre muitos, e não como um indicador definitivo de geração por IA.
Os padrões de burstiness variam significativamente entre diferentes gêneros e contextos de escrita, refletindo os distintos objetivos comunicativos e expectativas do público de cada domínio. A escrita acadêmica, especialmente nas áreas de STEM, tende a apresentar burstiness mais baixa porque os autores seguem guias de estilo rigorosos e utilizam templates estruturais consistentes para garantir clareza e precisão. Documentos legais, especificações técnicas e artigos científicos priorizam a consistência e previsibilidade em vez da variação estilística, resultando em valores naturalmente baixos de burstiness. Por outro lado, redação criativa, jornalismo e textos de marketing geralmente demonstram alta burstiness porque esses gêneros priorizam o engajamento do leitor e o impacto emocional por meio de ritmo e variação. Ficção literária, em particular, utiliza mudanças dramáticas no comprimento das frases para criar ênfase, construir tensão e controlar o ritmo narrativo. A comunicação empresarial ocupa uma posição intermediária — e-mails profissionais e relatórios mantêm burstiness moderada para equilibrar clareza e engajamento. A métrica Flesch-Kincaid Grade Level revela que textos acadêmicos destinados a públicos universitários costumam empregar frases mais longas e complexas, o que poderia parecer reduzir burstiness; no entanto, a variação na estrutura das orações e padrões de subordinação ainda gera burstiness significativa. Compreender essas variações contextuais é crucial para sistemas de detecção de IA, pois precisam considerar convenções de escrita específicas de cada gênero para evitar falsos positivos. Um manual técnico com frases uniformemente longas não deve ser sinalizado como gerado por IA simplesmente por apresentar burstiness baixa — a baixa burstiness reflete escolhas estilísticas apropriadas ao gênero, não evidência de geração automática.
O futuro da análise de burstiness na detecção de IA caminha para abordagens cada vez mais sofisticadas e sensíveis ao contexto, reconhecendo as limitações da métrica e, ao mesmo tempo, aproveitando seus insights. À medida que grandes modelos de linguagem se tornam mais avançados, começam a incorporar variação de burstiness em suas saídas, tornando a detecção baseada apenas nessa métrica menos confiável. Pesquisadores estão desenvolvendo sistemas de detecção adaptativos que analisam burstiness em conjunto com coerência semântica, precisão factual e adequação contextual. O surgimento de ferramentas de humanização de IA que aumentam deliberadamente burstiness e outras características humanas representa uma corrida armamentista contínua entre tecnologias de detecção e evasão. Entretanto, especialistas preveem que a detecção de IA realmente confiável dependerá, em última instância, de métodos de verificação criptográfica e rastreamento de procedência, não apenas da análise linguística. Para criadores de conteúdo e organizações, a implicação estratégica é clara: em vez de enxergar burstiness como uma métrica a ser manipulada, escritores devem focar no desenvolvimento de estilos autênticos e variados que reflitam naturalmente os padrões de comunicação humana. A plataforma de monitoramento da AmICited representa uma nova fronteira nesse cenário, acompanhando como as marcas aparecem em respostas geradas por IA e analisando as características linguísticas dessas aparições. Conforme sistemas de IA tornam-se mais prevalentes na geração e distribuição de conteúdo, compreender burstiness e métricas relacionadas torna-se cada vez mais importante para manter a autenticidade de marca, garantir integridade acadêmica e preservar a distinção entre conteúdo escrito por humanos e gerado por máquinas. A evolução para abordagens de detecção multissinal sugere que burstiness continuará relevante como um dos componentes dos sistemas de monitoramento de IA abrangentes, mesmo que seu papel se torne mais sutil e dependente do contexto.
Burstiness e perplexidade são métricas complementares usadas na detecção de IA. Perplexidade mede o quão previsíveis são as palavras individuais em um texto, enquanto burstiness mede a variação na estrutura e comprimento das frases em todo o documento. Escrita humana normalmente apresenta perplexidade mais alta (escolhas de palavras menos previsíveis) e burstiness mais alta (estruturas de frases mais variadas), enquanto textos gerados por IA tendem a mostrar valores mais baixos para ambas as métricas devido à dependência de padrões estatísticos aprendidos nos dados de treinamento.
Alta burstiness cria um fluxo rítmico que aumenta o engajamento e a compreensão do leitor. Quando os escritores alternam entre frases curtas e impactantes e outras mais longas e complexas, isso mantém o interesse do leitor e evita monotonia. Pesquisas mostram que a variação da estrutura das frases melhora a retenção de memória e faz com que o conteúdo pareça mais autêntico e conversacional. Burstiness baixa, caracterizada por frases uniformes, pode tornar o texto robótico e difícil de acompanhar, reduzindo tanto os índices de legibilidade quanto o engajamento do público.
Embora burstiness possa ser intencionalmente aumentada por meio da variação deliberada da estrutura das frases, fazê-lo artificialmente geralmente resulta em textos com som pouco natural, que podem acionar outros mecanismos de detecção. Detectores modernos de IA analisam múltiplas características linguísticas além de burstiness, incluindo coerência semântica, adequação contextual e padrões estilométricos. Burstiness autêntica surge naturalmente da escrita humana genuína e reflete a voz única do escritor, enquanto a variação forçada normalmente não possui a qualidade orgânica que caracteriza textos realmente escritos por humanos.
Falantes não nativos de inglês frequentemente apresentam pontuações mais baixas de burstiness porque seus padrões de escrita refletem um vocabulário mais limitado e estratégias de construção de frases mais simples. Aprendizes de línguas normalmente utilizam estruturas de frases mais uniformes e previsíveis à medida que desenvolvem proficiência, evitando orações complexas e padrões sintáticos variados. Isso cria um perfil estilométrico semelhante ao texto gerado por IA, levando a falsos positivos em sistemas de detecção de IA. Pesquisa da Universidade de Stanford em 2023 sobre redações do TOEFL confirmou esse viés, destacando uma limitação crítica dos métodos de detecção baseados em burstiness.
Grandes modelos de linguagem são treinados em conjuntos massivos de dados nos quais aprendem a prever a próxima palavra com base em padrões estatísticos. Durante o treinamento, esses modelos são otimizados para minimizar a perplexidade em seus dados de treinamento, o que inadvertidamente resulta em estruturas de frases uniformes e sequências de palavras previsíveis. Isso gera burstiness consistentemente baixa porque os modelos produzem texto selecionando combinações de palavras estatisticamente prováveis ao invés de empregarem a construção variada e espontânea de frases típica da escrita humana. A dependência dos modelos em distribuições de probabilidade cria uma assinatura estilística homogênea.
A AmICited monitora como marcas e domínios aparecem em respostas geradas por IA em plataformas como ChatGPT, Perplexity e Google AI Overviews. Compreender burstiness ajuda o sistema de monitoramento da AmICited a distinguir entre citações autênticas escritas por humanos e conteúdos gerados por IA que mencionam sua marca. Ao analisar padrões de burstiness juntamente com outros marcadores linguísticos, a AmICited pode fornecer insights mais precisos sobre se sua marca está sendo citada em conteúdo genuinamente humano ou em respostas de IA, possibilitando melhor gestão da reputação da marca.
Escritores podem aprimorar o burstiness organicamente ao variar conscientemente a construção das frases, mantendo clareza e propósito. Técnicas incluem alternar entre frases declarativas simples e frases complexas com múltiplas orações, usar recursos retóricos como fragmentos e travessões para dar ênfase e variar o comprimento dos parágrafos. O segredo é garantir que a variação sirva ao significado do conteúdo e não exista apenas por si mesma. Ler em voz alta, estudar estilos de escrita diversos e revisar com atenção ao ritmo desenvolve naturalmente a capacidade de produzir texto com alto burstiness, que soa autêntico e envolvente.
Comece a rastrear como os chatbots de IA mencionam a sua marca no ChatGPT, Perplexity e outras plataformas. Obtenha insights acionáveis para melhorar a sua presença de IA.
Saiba o que significa burstiness em conteúdo gerado por IA, como difere dos padrões de escrita humana e por que é importante para a detecção de IA e autenticida...
Discussão da comunidade sobre burstiness na detecção de conteúdo de IA – o que significa, como afeta a visibilidade em IA e se criadores de conteúdo devem otimi...
Saiba o que significa a pontuação de perplexidade em conteúdo e modelos de linguagem. Entenda como ela mede a incerteza do modelo, precisão preditiva e avaliaçã...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.