Definição de Grafo de Conhecimento
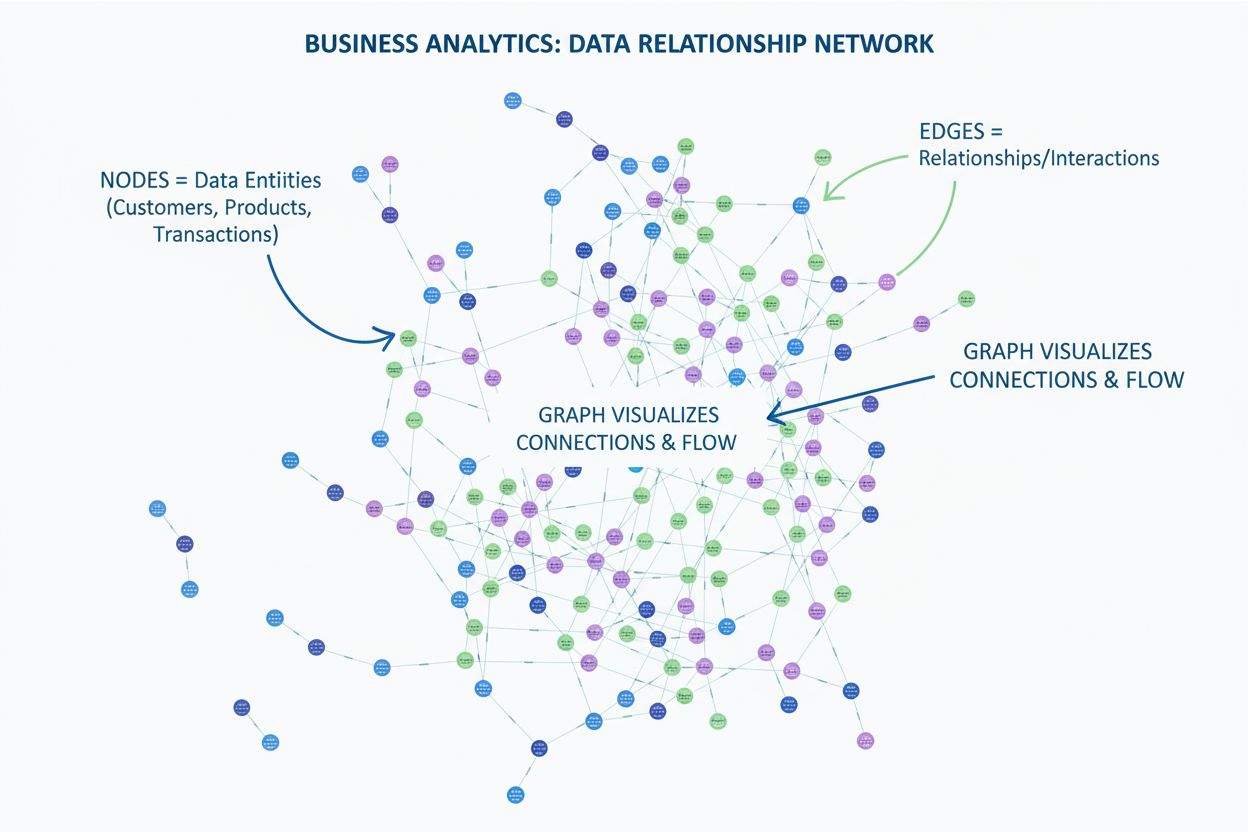
Um grafo de conhecimento é um banco de dados de informações interconectadas que representa entidades do mundo real—como pessoas, lugares, organizações e conceitos—e ilustra as relações semânticas entre elas. Diferentemente de bancos de dados tradicionais, que organizam informações em formatos rígidos e tabulares, grafos de conhecimento estruturam dados como redes de nós (entidades) e arestas (relacionamentos), permitindo que sistemas compreendam significado e contexto, em vez de apenas corresponder palavras-chave. O Grafo de Conhecimento do Google, lançado em 2012, revolucionou a busca ao introduzir a compreensão baseada em entidades, possibilitando que o motor de busca responda a perguntas factuais como “Qual a altura da Torre Eiffel?” ou “Onde foram realizadas as Olimpíadas de 2016?” ao entender o que o usuário realmente procura, não apenas as palavras utilizadas. Em maio de 2024, o Grafo de Conhecimento do Google continha mais de 1,6 trilhão de fatos sobre 54 bilhões de entidades, representando uma enorme expansão em relação aos 500 bilhões de fatos sobre 5 bilhões de entidades em 2020. Esse crescimento reflete a importância crescente do conhecimento estruturado e semântico no funcionamento da busca moderna, sistemas de IA e aplicações inteligentes em diversos setores.
Contexto e Desenvolvimento Histórico
O conceito de grafos de conhecimento surgiu de décadas de pesquisa em inteligência artificial, tecnologias da web semântica e representação do conhecimento. No entanto, o termo ganhou reconhecimento amplo quando o Google introduziu seu Grafo de Conhecimento em 2012, mudando fundamentalmente a forma como os motores de busca entregam resultados. Antes do Grafo de Conhecimento, os motores de busca usavam principalmente correspondência de palavras-chave—se você buscasse “foca”, o Google retornaria resultados para todos os possíveis significados da palavra, sem entender qual entidade você realmente queria saber. O Grafo de Conhecimento mudou esse paradigma ao aplicar princípios de ontologia—um arcabouço formal para definir entidades, seus atributos e relacionamentos—em grande escala. Essa mudança de “strings para coisas” representou um avanço fundamental na tecnologia de busca, permitindo que algoritmos entendessem que “foca” poderia se referir a um mamífero marinho, um artista musical, uma unidade militar ou um dispositivo de segurança, e determinassem qual significado era mais relevante com base no contexto. O mercado global de grafos de conhecimento reflete essa importância, com projeções de crescimento de US$ 1,49 bilhão em 2024 para US$ 6,94 bilhões até 2030, representando uma taxa de crescimento anual composta de aproximadamente 35%. Esse crescimento explosivo é impulsionado pela adoção em empresas de setores como finanças, saúde, varejo e gestão de cadeias de suprimentos, onde organizações reconhecem cada vez mais que entender relações de entidades é fundamental para tomada de decisões, detecção de fraudes e eficiência operacional.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Como Funcionam os Grafos de Conhecimento: Arquitetura Técnica
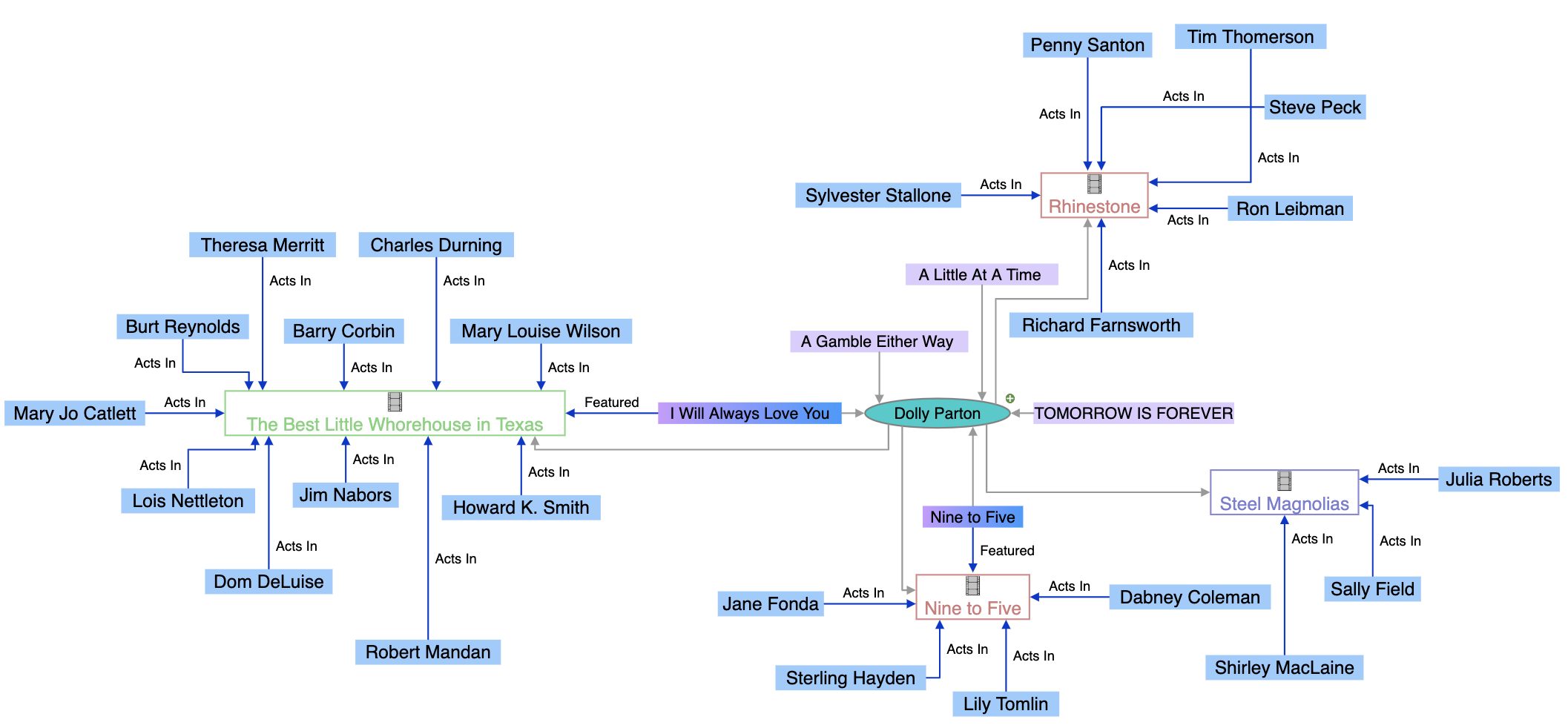
Grafos de conhecimento operam por meio de uma combinação sofisticada de estruturas de dados, tecnologias semânticas e algoritmos de aprendizado de máquina. Em seu núcleo, grafos de conhecimento utilizam um modelo de dados estruturado em grafo composto por três componentes fundamentais: nós (representando entidades como pessoas, organizações ou conceitos), arestas (representando relacionamentos entre entidades) e rótulos (descrevendo a natureza desses relacionamentos). Por exemplo, em um grafo de conhecimento simples, “Seal” pode ser um nó, “é um” pode ser um rótulo de aresta, e “Artista Musical” pode ser outro nó, criando o relacionamento semântico “Seal é um Artista Musical”. Essa estrutura é fundamentalmente diferente dos bancos de dados relacionais, que forçam os dados em linhas e colunas com esquemas predefinidos. Grafos de conhecimento são construídos usando grafos de propriedades rotuladas (que armazenam propriedades diretamente em nós e arestas) ou armazenamento de triplas RDF (Resource Description Framework) (que representam todas as informações como triplas sujeito-predicado-objeto). O poder dos grafos de conhecimento surge de sua capacidade de integrar dados de múltiplas fontes com diferentes estruturas e formatos. Ao ingerir dados em um grafo de conhecimento, processos de enriquecimento semântico utilizam processamento de linguagem natural (PLN) e aprendizado de máquina para identificar entidades, extrair relacionamentos e entender o contexto. Isso permite que grafos de conhecimento reconheçam automaticamente que “IBM”, “International Business Machines” e “Big Blue” referem-se à mesma entidade, e entendam como essa entidade se relaciona com outras como “Watson”, “Computação em Nuvem” e “Inteligência Artificial”. A estrutura interconectada resultante permite consultas e raciocínios sofisticados, impossíveis em bancos de dados tradicionais, permitindo que sistemas respondam a perguntas complexas ao percorrer relacionamentos e inferir novos conhecimentos a partir de conexões existentes.
Grafo de Conhecimento vs. Bancos de Dados Tradicionais: Tabela Comparativa
| Aspecto | Grafo de Conhecimento | Banco de Dados Relacional Tradicional | Banco de Dados em Grafos |
|---|
| Estrutura de Dados | Nós, arestas e rótulos representando entidades e relacionamentos | Tabelas, linhas e colunas com esquemas predefinidos | Nós e arestas otimizados para travessia de relacionamentos |
| Flexibilidade do Esquema | Altamente flexível; evolui conforme novas informações são descobertas | Rígido; requer definição de esquema antes do ingresso dos dados | Flexível; suporta evolução dinâmica do esquema |
| Manipulação de Relacionamentos | Suporte nativo para relacionamentos complexos e de múltiplos níveis | Exige junções entre múltiplas tabelas; computacionalmente caro | Otimizado para consultas eficientes de relacionamentos |
| Linguagem de Consulta | SPARQL (para RDF), Cypher (para grafos de propriedades) ou APIs personalizadas | SQL | Cypher, Gremlin ou SPARQL |
| Compreensão Semântica | Ênfase em significado e contexto via ontologias | Foco em armazenamento e recuperação de dados | Foco em travessia eficiente e correspondência de padrões |
| Casos de Uso | Busca semântica, descoberta de conhecimento, sistemas de IA, resolução de entidades | Transações de negócios, relatórios, sistemas OLTP | Motores de recomendação, detecção de fraudes, análise de redes |
| Integração de Dados | Excelente para integrar dados heterogêneos de múltiplas fontes | Requer ETL e transformação de dados significativos | Bom para dados conectados, mas com menor foco semântico |
| Escalabilidade | Escala para bilhões de entidades e trilhões de fatos | Escala bem para dados estruturados e transacionais | Escala bem para consultas com muitos relacionamentos |
| Capacidades de Inferência | Raciocínio avançado e derivação de conhecimento via ontologias | Limitado; requer programação explícita | Limitado; foca em correspondência de padrões |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
O Papel dos Grafos de Conhecimento em SEO e Visibilidade em IA
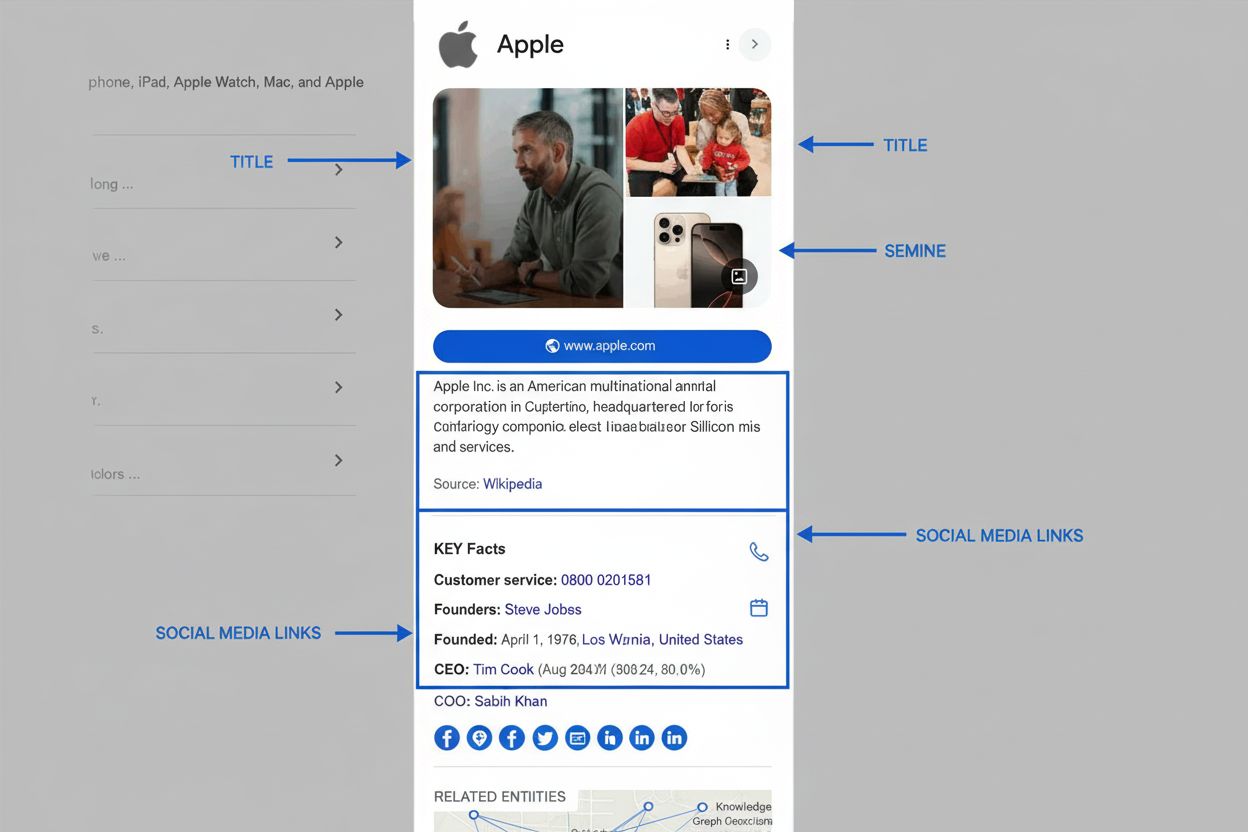
Grafos de conhecimento tornaram-se centrais para estratégias modernas de SEO e visibilidade em IA porque determinam fundamentalmente como as informações aparecem nos resultados de busca e respostas geradas por IA. Quando o Google processa uma busca, uma de suas tarefas principais é identificar a entidade que o usuário está buscando, então recuperar informações relevantes do Grafo de Conhecimento para preencher recursos da SERP. Essa abordagem baseada em entidades levou ao surgimento da busca semântica—a capacidade do Google de entender o significado e contexto das perguntas, e não apenas corresponder palavras-chave. O Grafo de Conhecimento alimenta múltiplos recursos de alta visibilidade na SERP que impactam diretamente as taxas de clique e a visibilidade de marcas. Painéis de conhecimento aparecem de forma proeminente nos resultados desktop e mobile, exibindo fatos selecionados sobre a entidade buscada provenientes do Grafo de Conhecimento. Visões gerais de IA (anteriormente Experiência Generativa de Busca) sintetizam informações de múltiplas fontes identificadas por meio de relações do Grafo de Conhecimento, fornecendo respostas abrangentes que frequentemente empurram os resultados orgânicos tradicionais para baixo. Caixas As pessoas também perguntam aproveitam relações entre entidades para sugerir buscas e tópicos relacionados. Entender esses recursos é fundamental para marcas, pois representam espaços privilegiados nos resultados de busca, frequentemente acima dos resultados orgânicos tradicionais. Para organizações que monitoram sua presença em sistemas de IA como Perplexity, ChatGPT, Claude e Visões Gerais de IA do Google, a otimização do grafo de conhecimento torna-se essencial. Esses sistemas de IA dependem cada vez mais de informações estruturadas de entidades e relações semânticas para gerar respostas precisas e contextuais. Marcas que otimizam corretamente sua presença de entidade em grafos de conhecimento—por meio de marcação de dados estruturados, painéis de conhecimento reivindicados e informações consistentes em diferentes fontes—têm mais chances de aparecer em respostas geradas por IA sobre tópicos relevantes. Por outro lado, marcas com informações de entidade incompletas ou inconsistentes podem ser ignoradas ou mal representadas em sistemas de IA, impactando diretamente sua visibilidade e reputação.
Fontes de Dados e Construção do Grafo de Conhecimento
O Grafo de Conhecimento do Google é composto por um ecossistema diversificado de fontes de dados, cada uma contribuindo com diferentes tipos de informações e servindo a diferentes propósitos. Projetos abertos e comunitários como Wikipedia e Wikidata formam a base de grande parte do conteúdo do Grafo de Conhecimento. A Wikipedia fornece descrições narrativas e informações resumidas que frequentemente aparecem em painéis de conhecimento, enquanto o Wikidata—uma base de conhecimento estruturada que apoia a Wikipedia—oferece dados de entidades e relacionamentos legíveis por máquina. O Google utilizou anteriormente o Freebase, seu próprio banco de dados editado pela comunidade, mas migrou para o Wikidata após encerrar o Freebase em 2016. Fontes de dados governamentais contribuem com informações oficiais, especialmente para consultas factuais. O CIA World Factbook fornece informações sobre países, áreas geográficas e organizações. O Data Commons, projeto público estruturado do Google, agrega dados de organizações governamentais e multilaterais como as Nações Unidas e União Europeia, fornecendo estatísticas e informações demográficas. Dados meteorológicos e de qualidade do ar vêm de agências meteorológicas nacionais e internacionais, permitindo recursos de previsão do tempo do Google. Dados privados licenciados complementam o Grafo de Conhecimento com informações frequentemente atualizadas ou que requerem expertise especializada. O Google licencia dados de mercados financeiros de provedores como Morningstar, S&P Global e Intercontinental Exchange, alimentando recursos de informações de preços e mercados. Dados esportivos vêm de parcerias com ligas, times e agregadores como Stats Perform, fornecendo placares em tempo real e estatísticas históricas. Dados estruturados de sites contribuem significativamente para o enriquecimento do Grafo de Conhecimento. Quando sites implementam marcação Schema.org, eles fornecem informações semânticas explícitas que o Google pode extrair e incorporar. Por isso, implementar dados estruturados adequados—schema de Organização, LocalBusiness, FAQPage e outras marcações relevantes—é fundamental para marcas que desejam influenciar sua representação no Grafo de Conhecimento. Dados do Google Books provenientes de mais de 40 milhões de livros digitalizados fornecem contexto histórico, informações biográficas e descrições detalhadas que enriquecem o conhecimento sobre entidades. Feedback de usuários e painéis de conhecimento reivindicados permitem que indivíduos e organizações influenciem diretamente as informações do Grafo de Conhecimento. Quando usuários enviam feedback sobre painéis de conhecimento ou representantes autorizados reivindicam e atualizam painéis, essas informações são processadas e podem levar a atualizações no Grafo de Conhecimento. Essa abordagem humano-no-ciclo garante que o Grafo de Conhecimento permaneça preciso e representativo, embora os sistemas automatizados do Google tomem a decisão final sobre quais informações aparecem.
Grafos de Conhecimento e E-E-A-T: Construindo Autoridade e Confiança
O Google declara explicitamente que prioriza informações de fontes que demonstram alto E-E-A-T (Experiência, Especialização, Autoridade e Confiabilidade) ao construir e atualizar o Grafo de Conhecimento. Essa conexão entre E-E-A-T e inclusão no Grafo de Conhecimento não é coincidente—reflete o compromisso mais amplo do Google em apresentar informações confiáveis e autoritativas. Se o conteúdo do seu site está aparecendo em recursos da SERP alimentados pelo Grafo de Conhecimento, geralmente é um forte sinal de que o Google reconhece seu site como autoridade naquele assunto. Por outro lado, se seu conteúdo não aparece em recursos alimentados pelo Grafo de Conhecimento, isso pode indicar problemas de E-E-A-T que precisam ser abordados. Construir E-E-A-T para visibilidade no Grafo de Conhecimento exige uma abordagem multifacetada. Experiência significa demonstrar que você ou seus colaboradores têm experiência prática no tema. Para um site de saúde, isso pode significar apresentar conteúdo de profissionais médicos licenciados com anos de experiência clínica. Para uma empresa de tecnologia, significa destacar a expertise de engenheiros e pesquisadores envolvidos nos produtos discutidos. Especialização envolve criar conteúdo profundamente conhecedor, que cubra tópicos de forma abrangente e precisa. Isso vai além de explicações superficiais para demonstrar compreensão genuína de nuances, casos especiais e conceitos avançados. Autoridade requer reconhecimento no seu campo, seja por prêmios, certificações, menções na mídia, palestras ou citações por outras fontes autoritativas. Para organizações, significa estabelecer sua marca como líder reconhecida em seu setor. Confiabilidade se constrói a partir dos outros três elementos e é demonstrada por transparência, precisão, citações adequadas, autoria clara e atendimento ao cliente eficiente. Organizações que se destacam em sinais de E-E-A-T têm mais chances de ter suas informações incluídas no Grafo de Conhecimento e aparecer em respostas geradas por IA, criando um ciclo virtuoso em que autoridade leva à visibilidade, que reforça ainda mais a autoridade.
Grafos de Conhecimento em Sistemas de IA e Busca Generativa
O surgimento de grandes modelos de linguagem (LLMs) e IA generativa deu nova importância aos grafos de conhecimento no ecossistema de IA. Embora LLMs como ChatGPT, Claude e Perplexity não sejam treinados diretamente no Grafo de Conhecimento proprietário do Google, eles dependem cada vez mais de conhecimento estruturado e compreensão semântica semelhantes. Muitos sistemas de IA empregam abordagens de geração aumentada por recuperação (RAG), em que o modelo consulta grafos de conhecimento ou bancos de dados estruturados em tempo real para fundamentar respostas em informações factuais e reduzir alucinações. Grafos de conhecimento públicos como Wikidata são usados para ajustar modelos ou injetar conhecimento estruturado, melhorando sua capacidade de entender relações entre entidades e fornecer informações precisas. Para marcas e organizações, isso significa que a otimização de grafos de conhecimento tem implicações além da Busca Google tradicional. Quando usuários consultam sistemas de IA sobre seu setor, produtos ou organização, a habilidade do sistema de IA de fornecer informações corretas depende em parte de como sua entidade está representada em fontes estruturadas de conhecimento. Uma organização com entrada bem mantida no Wikidata, painel de conhecimento do Google reivindicado e dados estruturados consistentes em seu site tem mais chances de ser representada corretamente em respostas geradas por IA. Por outro lado, organizações com informações incompletas ou conflitantes podem ser mal representadas ou ignoradas em respostas de IA. Isso cria uma nova dimensão de monitoramento de visibilidade em IA—acompanhar não apenas como sua marca aparece nos resultados de busca tradicionais, mas como está representada em respostas geradas por IA em várias plataformas. Ferramentas e plataformas de monitoramento de marcas em IA cada vez mais focam em entender relações de entidades e representação em grafos de conhecimento, reconhecendo que esses fatores influenciam diretamente a visibilidade em IA.
Implementação Prática: Otimizando para Grafos de Conhecimento
Organizações que buscam otimizar sua presença em grafos de conhecimento devem seguir uma abordagem sistemática baseada nos fundamentos de SEO, com estratégias adicionais focadas em entidades. O primeiro passo é implementar marcação de dados estruturados usando o vocabulário Schema.org. Isso significa adicionar marcação JSON-LD, Microdata ou RDFa ao seu site, descrevendo explicitamente sua organização, produtos, pessoas e outras entidades relevantes. Os principais tipos de schema incluem Organization (para informações da empresa), LocalBusiness (para informações locais), Person (para perfis individuais), Product (para produtos) e FAQPage (para perguntas frequentes). Após implementar o schema, é essencial testar e validar sua marcação usando a Ferramenta de Teste de Dados Estruturados do Google para garantir que está correta e reconhecida. O segundo passo envolve auditar e otimizar informações no Wikidata e Wikipedia. Se sua organização ou entidades-chave têm páginas na Wikipedia, garanta que estejam precisas, completas e devidamente referenciadas. No Wikidata, verifique se sua entidade existe e se suas propriedades e relacionamentos estão corretamente representados. No entanto, editar Wikipedia ou Wikidata exige atenção às políticas e normas da comunidade—autopromoção ou conflitos de interesse não revelados podem resultar em reversão de edições e danos à reputação. O terceiro passo é reivindicar e otimizar seu Perfil de Negócio do Google (para negócios locais) e painéis de conhecimento (para pessoas e organizações). Um painel de conhecimento reivindicado oferece maior controle sobre como sua entidade aparece nos resultados de busca e permite sugerir edições mais rapidamente. O quarto passo envolve garantir consistência em todas as propriedades—seu site, Perfil de Negócio do Google, perfis em redes sociais e diretórios de empresas de terceiros. Informações conflitantes confundem os sistemas do Google e podem impedir representação precisa no Grafo de Conhecimento. O quinto passo é criar conteúdo focado em entidades em vez de conteúdo focado em palavras-chave. Ao invés de escrever artigos separados sobre “melhor software CRM”, “funcionalidades do Salesforce” e “preços da HubSpot”, crie um cluster de conteúdo abrangente que estabeleça relações claras de entidades: Salesforce é uma plataforma de CRM, concorre com HubSpot, integra-se ao Slack, etc. Essa abordagem baseada em entidades auxilia os grafos de conhecimento a entenderem o significado semântico e as relações do seu conteúdo.
Aspectos-Chave da Otimização e Implementação de Grafos de Conhecimento
- Implementação de Dados Estruturados: Adicione marcação Schema.org a todas as páginas relevantes, incluindo schemas de Organization, LocalBusiness, Product, Person e FAQPage, e valide usando as ferramentas do Google
- Consistência de Entidades: Mantenha informações empresariais idênticas (nome, endereço, telefone, descrição) em seu site, Perfil de Negócio do Google, redes sociais e diretórios de terceiros para evitar sinais conflitantes
- Reivindicação de Painel de Conhecimento: Reivindique seu painel de conhecimento para obter controle direto sobre as informações da entidade e a capacidade de sugerir edições processadas mais rapidamente pelo Google
- Otimização no Wikidata: Garanta que sua organização ou entidades-chave tenham entradas precisas e completas no Wikidata, com propriedades e relacionamentos adequados, seguindo as diretrizes da comunidade
- Sinais E-E-A-T: Construa autoridade por meio de conteúdo especializado, credenciais de autores, reconhecimento no setor, prêmios, menções na mídia e fontes transparentes para aumentar a inclusão no Grafo de Conhecimento
- Estratégia de Conteúdo Baseada em Entidades: Organize o conteúdo em torno de entidades e seus relacionamentos, em vez de palavras-chave, criando clusters de conteúdo abrangentes que estabelecem conexões semânticas
- Perfis em Redes Sociais: Crie e otimize perfis em plataformas reconhecidas pelo Google (Facebook, Instagram, LinkedIn, YouTube, TikTok, X, Pinterest, Snapchat) e vincule-os usando a propriedade “sameAs” do schema
- Perfis Empresariais de Terceiros: Mantenha perfis em diretórios empresariais autoritativos como Crunchbase, Forbes e Fortune, que o Google utiliza como fontes para o Grafo de Conhecimento
- Monitoramento da Precisão dos Dados: Audite regularmente as informações de sua entidade em todas as fontes e corrija dados desatualizados ou imprecisos, inclusive entrando em contato com sites de terceiros, se necessário
- Envio de Feedback: Use os mecanismos de feedback do Google em painéis de conhecimento e resultados de busca para relatar imprecisões e sugerir melhorias nas informações do Grafo de Conhecimento
- Acompanhamento de Visibilidade em IA: Monitore como sua marca aparece em respostas geradas por IA nas plataformas Perplexity, ChatGPT, Claude e Visões Gerais de IA do Google para entender sua representação como entidade em sistemas de IA
O Futuro dos Grafos de Conhecimento: Evolução e Implicações Estratégicas
Grafos de conhecimento estão evoluindo rapidamente em resposta aos avanços em inteligência artificial, mudanças no comportamento de busca e no surgimento de novas plataformas e tecnologias. Uma tendência importante é a expansão dos grafos de conhecimento multimodais que integram texto, imagens, áudio e vídeo. À medida que buscas por voz e visual se tornam mais comuns, grafos de conhecimento estão se adaptando para entender e representar informações em múltiplas modalidades. O trabalho do Google em busca multimodal com produtos como o Google Lens demonstra essa evolução—o sistema precisa entender não apenas consultas em texto, mas também entradas visuais, exigindo grafos de conhecimento capazes de representar e conectar informações em diferentes tipos de mídia. Outro desenvolvimento importante é a crescente sofisticação do enriquecimento semântico e do processamento de linguagem natural na construção de grafos de conhecimento. Com o avanço do PLN, grafos de conhecimento podem extrair relações semânticas mais sutis de textos não estruturados, reduzindo a dependência de dados manualmente curados ou explicitamente marcados. Isso significa que organizações com conteúdo de alta qualidade e bem escrito podem ter suas informações incorporadas a grafos de conhecimento mesmo sem marcação estruturada explícita, embora a marcação permaneça importante para garantir representação precisa. A integração de grafos de conhecimento com grandes modelos de linguagem e IA generativa representa talvez a evolução mais significativa. À medida que sistemas de IA se tornam centrais para a descoberta de informações, a importância da otimização de grafos de conhecimento vai além da busca tradicional para englobar a visibilidade em IA em múltiplas plataformas. Organizações que entendem e otimizam para grafos de conhecimento terão vantagens tanto na busca tradicional quanto em respostas geradas por IA. Além disso, o aumento dos grafos de conhecimento corporativos reflete a percepção de que os princípios dos grafos de conhecimento se aplicam além da busca pública, beneficiando a gestão do conhecimento organizacional interna. Empresas estão construindo grafos de conhecimento internos para eliminar silos de dados, melhorar a tomada de decisões e viabilizar melhores aplicações de IA. Essa tendência sugere que a alfabetização em grafos de conhecimento será cada vez mais importante para líderes de negócios, cientistas de dados e profissionais de marketing. Por fim, as dimensões regulatórias e éticas dos grafos de conhecimento ganham cada vez mais destaque. À medida que grafos de conhecimento influenciam a apresentação de informações para bilhões de usuários, questões sobre precisão, viés, representação e controle das informações ganham relevância. Organizações devem estar cientes de que a representação de suas entidades em grafos de conhecimento tem consequências reais para sua visibilidade, reputação e resultados de negócios, e devem abordar a otimização desses grafos com o mesmo rigor e ética aplicados a outros aspectos de sua presença digital.