
Cum performează studiile de caz în rezultatele căutării AI
Află cum se clasează studiile de caz în motoarele de căutare AI precum ChatGPT, Perplexity și Google AI Overviews. Descoperă de ce sistemele AI citează studiile...
11 min citire

Află cum să formatezi studiile de caz pentru citări AI. Descoperă planul pentru structurarea poveștilor de succes pe care LLM-urile le citează în AI Overviews, ChatGPT și Perplexity.
Sistemele AI precum ChatGPT, Perplexity și AI Overviews de la Google schimbă fundamental modul în care cumpărătorii B2B descoperă și validează studiile de caz—totuși majoritatea companiilor încă le publică în formate pe care LLM-urile abia le pot interpreta. Când un cumpărător enterprise întreabă un sistem AI „Ce platforme SaaS funcționează cel mai bine pentru cazul nostru?”, sistemul caută printre milioane de documente pentru a găsi dovezi relevante, însă studiile de caz slab formatate rămân invizibile acestor sisteme de recuperare. Acest lucru creează un decalaj critic: în timp ce studiile de caz tradiționale generează o rată de succes de bază de 21% în etapele finale ale tranzacțiilor, studiile de caz optimizate pentru AI pot crește probabilitatea de citare cu 28-40% dacă sunt structurate corect pentru modelele de învățare automată. Companiile care câștigă în acest peisaj nou înțeleg că avantajul datelor primare vine din a fi descoperit de sistemele AI, nu doar de cititori umani. Fără o optimizare intenționată pentru recuperarea LLM, cele mai convingătoare povești de succes ale clienților tăi sunt practic blocate pentru sistemele AI care influențează acum peste 60% din deciziile de achiziție enterprise.
Un studiu de caz pregătit pentru AI nu este doar o narațiune bine scrisă—este un document strategic structurat care servește în același timp cititorii umani și modelele de învățare automată. Cele mai eficiente studii de caz urmează o arhitectură constantă ce permite LLM-urilor să extragă informații cheie, să înțeleagă contextul și să citeze compania ta cu încredere. Mai jos este planul esențial care separă studiile de caz descoperibile de AI de cele care se pierd în sistemele de recuperare:
| Secțiune | Scop | Optimizare pentru AI |
|---|---|---|
| Rezumat TL;DR | Context imediat pentru cititorii grăbiți | Plasat la început pentru consumul timpuriu de tokeni; 50-75 cuvinte |
| Profil client | Identificare rapidă a profilului companiei | Structurat ca: Industrie / Mărime companie / Locație / Rol |
| Context de business | Definirea problemei și situația de piață | Folosește terminologie constantă; evită variațiile de jargon |
| Obiective | Scopuri specifice și măsurabile ale clientului | Formatează ca listă numerotată; include ținte cuantificabile |
| Soluție | Cum produsul/serviciul tău a abordat nevoia | Explică explicit legătura dintre funcționalități și beneficii |
| Implementare | Detalii despre calendar, proces și adopție | Împarte în faze; include durate și repere cheie |
| Rezultate | Rezultate cuantificate și metrici de impact | Prezintă ca: Măsură / Bază inițială / Final / Îmbunătățire % |
| Dovezi | Date, capturi de ecran sau validare terță | Include tabele pentru metrici; citează clar sursele |
| Citate client | Voce autentică și validare emoțională | Atribuie cu nume, funcție, companie; 1-2 fraze fiecare |
| Semnale de reutilizare | Legături interne și recomandări | Sugerează studii de caz conexe, webinarii sau resurse |
Această structură asigură că fiecare secțiune are dublu scop: se citește natural pentru oameni și oferă claritate semantică pentru sistemele RAG (Retrieval-Augmented Generation) care alimentează LLM-urile moderne. Consistența acestui format în toată biblioteca ta de studii de caz face mult mai ușoară extragerea de date comparabile și citarea companiei tale de către sistemele AI.
Dincolo de structură, alegerile specifice de formatare influențează dramatic dacă sistemele AI pot găsi și cita efectiv studiile de caz. LLM-urile procesează documentele diferit față de oameni—nu scanează sau folosesc ierarhii vizuale precum cititorii, dar sunt extrem de sensibile la marcaje semantice și modele de formatare constante. Iată elementele de formatare care cresc cel mai mult recuperarea AI:
Aceste alegeri nu țin de estetică—ci de a face studiul tău de caz lizibil pentru mașini, astfel încât atunci când un LLM caută dovezi relevante, povestea companiei tale să fie cea citată.
Cea mai sofisticată abordare pentru studiile de caz pregătite AI presupune încapsularea unei scheme JSON direct în documentul studiului de caz sau la nivel de metadata, creând o abordare duală în care oamenii citesc narațiunea, iar mașinile parcurg datele structurate. Schemelor JSON oferă LLM-urilor reprezentări neambigue, lizibile de mașini, ale informațiilor cheie din studiul de caz, îmbunătățind dramatic acuratețea și relevanța citărilor. Iată un exemplu despre cum să structurezi acest lucru:
{
"@context": "https://schema.org",
"@type": "CaseStudy",
"name": "Platformă SaaS enterprise reduce timpul de onboarding cu 60%",
"customer": {
"name": "TechCorp Industries",
"industry": "Servicii financiare",
"companySize": "500-1000 angajați",
"location": "San Francisco, CA"
},
"solution": {
"productName": "Numele produsului tău",
"category": "Automatizare workflow",
"implementationDuration": "8 săptămâni"
},
"results": {
"metrics": [
{"name": "Reducere timp de onboarding", "baseline": "120 zile", "final": "48 zile", "improvement": "60%"},
{"name": "Rată de adopție utilizatori", "baseline": "45%", "final": "89%", "improvement": "97%"},
{"name": "Reducere tichete suport", "baseline": "450/lună", "final": "120/lună", "improvement": "73%"}
]
},
"datePublished": "2024-01-15",
"author": {"@type": "Organization", "name": "Compania ta"}
}
Prin implementarea structurilor JSON conforme schema.org, oferi practic LLM-urilor o modalitate standardizată de a înțelege și cita studiul tău de caz. Această abordare se integrează perfect cu sistemele RAG, permițând modelelor AI să extragă metrici preciși, să înțeleagă contextul clientului și să atribuie citările companiei tale cu încredere ridicată. Companiile care folosesc studii de caz structurate JSON observă o acuratețe a citărilor de 3-4 ori mai mare în răspunsurile generate AI față de formatele doar narative.
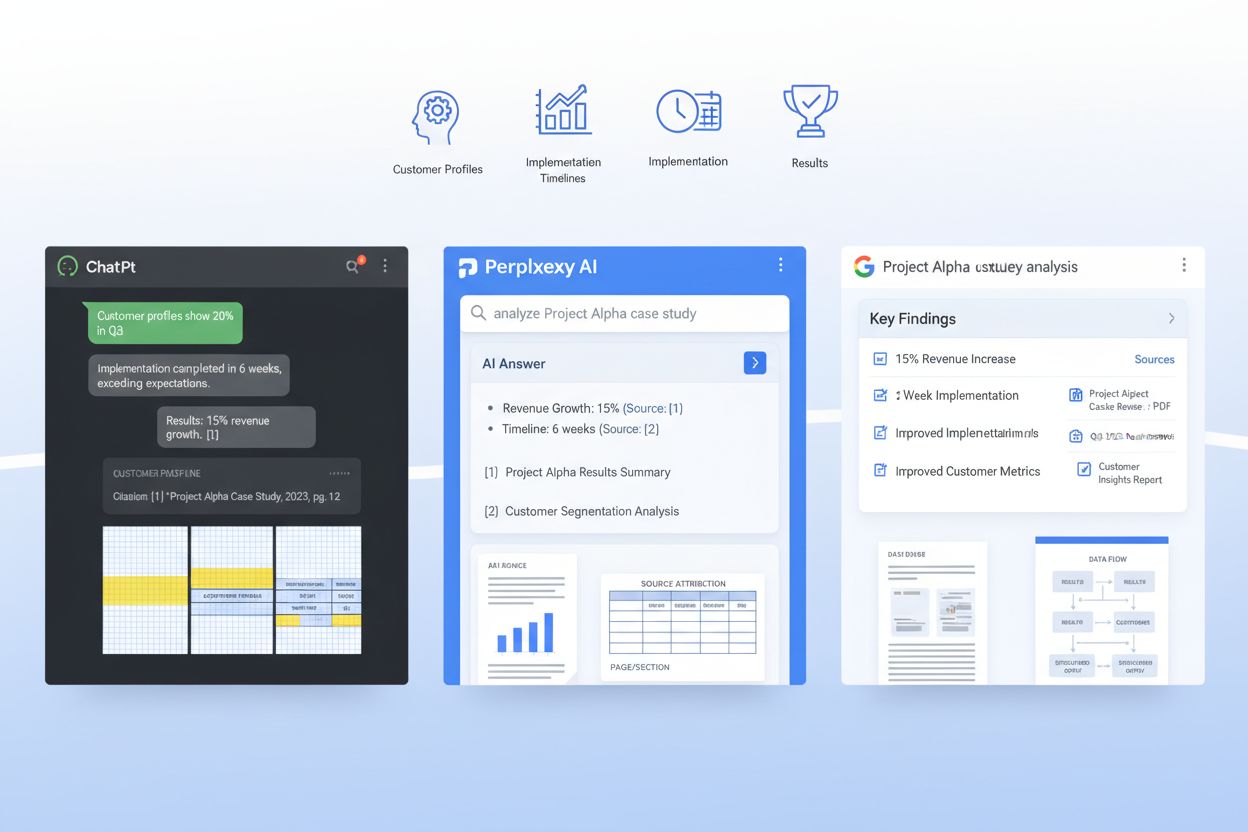
Sistemele RAG nu procesează studiul tău de caz ca un singur bloc—îl împart în fragmente semantice care încap în fereastra de context a unui LLM, iar modul în care structurezi documentul determină direct dacă acele fragmente sunt utile sau fragmentate. O fragmentare eficientă înseamnă organizarea studiului de caz astfel încât granițele semantice naturale să se alinieze cu modul în care sistemele RAG vor diviza conținutul. Asta cere dimensionarea intenționată a paragrafelor: fiecare paragraf să se concentreze pe o singură idee sau un singur punct de date, de obicei 100-150 de cuvinte, astfel încât atunci când un sistem RAG extrage un fragment, acesta să conțină informații complete, coerente, nu fraze izolate. Separarea narativă e critică—folosește pauze clare între declarația problemei, descrierea soluției și rezultate pentru ca LLM-ul să poată extrage „secțiunea de rezultate” ca un tot coerent, fără a amesteca accidental cu detalii de implementare. În plus, eficiența tokenilor contează: folosind tabele pentru metrici în loc de text narativ, reduci numărul de tokeni necesari pentru aceeași informație, permițând LLM-urilor să includă mai mult din studiul tău de caz în răspuns fără a atinge limitele de context. Scopul este să faci studiul tău de caz „prieteni cu RAG”, astfel încât fiecare fragment extras de un sistem AI să fie valoros și corect contextualizat.
Publicarea studiilor de caz pentru sistemele AI presupune echilibrarea specificității care le face credibile cu obligațiile de confidențialitate față de clienți. Multe companii ezită să publice studii de caz detaliate de teamă să nu expună informații sensibile, însă redactarea strategică și anonimizarea permit menținerea transparenței și încrederii. Cea mai eficientă abordare presupune crearea mai multor versiuni pentru fiecare studiu de caz: o versiune internă completă cu nume reale, metrici exacți și detalii proprietare de implementare și o versiune publică optimizată AI care anonimizează clientul, dar păstrează impactul cuantificat și insight-urile strategice. De exemplu, în loc de „TechCorp Industries a economisit $2,3M anual”, poți publica „O companie financiară mid-market a redus costurile operaționale cu 34%”—metrica rămâne suficient de specifică pentru ca LLM-urile să o citeze, dar identitatea clientului e protejată. Controlul versiunilor și urmărirea conformității sunt esențiale: păstrează evidențe clare despre ce informații au fost redactate, de ce și când, asigurând că biblioteca ta de studii de caz este mereu pregătită pentru audit. Această guvernanță îți întărește de fapt strategia de citare AI, deoarece îți permite să publici mai multe studii de caz mai des, fără obstacole legale, oferind LLM-urilor mai multe dovezi de descoperit și citat.
Înainte de publicarea unui studiu de caz, validează că acesta chiar performează bine când este procesat de LLM-uri și sisteme RAG—nu presupune că o formatare bună se traduce automat în performanță AI. Testarea studiilor de caz cu sisteme AI reale dezvăluie dacă structura, metadatele și conținutul permit cu adevărat citarea și recuperarea corectă. Iată cinci metode esențiale de testare:
Aceste teste ar trebui refăcute trimestrial pe măsură ce comportamentul LLM evoluează, iar rezultatele să ghideze actualizările de formatare și structură a studiilor de caz.
Măsurarea impactului studiilor de caz optimizate AI cere urmărirea atât a metricilor de partea AI (cât de des studiile tale de caz sunt citate de LLM-uri), cât și a celor umane (cum influențează aceste citări tranzacțiile reale). Pe partea AI, folosește AmICited.com pentru a monitoriza frecvența citărilor în ChatGPT, Perplexity și Google AI Overviews—urmărește cât de des apare compania ta în răspunsurile AI la întrebări relevante și dacă frecvența citărilor crește după publicarea de studii de caz optimizate AI. Stabilește o bază actuală, apoi setează un obiectiv de creștere a citărilor cu 40-60% în șase luni de la implementarea formatării AI-ready. Pe partea umană, corelează creșterea citărilor AI cu metrici de downstream: urmărește câte tranzacții menționează „Te-am găsit într-o căutare AI” sau „un AI a recomandat studiul tău de caz”, măsoară creșterea ratei de succes în tranzacțiile unde studiul tău a fost citat de AI (țintă: îmbunătățire de 28-40% peste baza de 21%) și monitorizează scurtarea ciclului de vânzare în conturile unde prospectul a descoperit studiul tău prin AI. De asemenea, monitorizează metrici SEO—studiile de caz optimizate AI cu markup schema corespunzător au adesea un ranking mai bun în căutările tradiționale, generând un beneficiu dual. Feedback-ul calitativ de la echipa de vânzări contează la fel de mult: întreabă dacă prospectul sosește cu cunoștințe mai profunde despre produs și dacă citarea studiului de caz reduce timpul de gestionare a obiecțiilor. KPI-ul final este venitul: urmărește ARR-ul incremental atribuit tranzacțiilor influențate de studiile de caz citate de AI și vei avea un argument clar de ROI pentru investiția continuă în acest format.
Optimizarea studiilor de caz pentru citări AI aduce ROI doar dacă procesul devine operaționalizat și repetabil, nu o acțiune singulară. Începe prin a codifica șablonul tău AI-ready într-un format standardizat folosit de echipele de marketing și vânzări pentru fiecare nouă poveste de succes—acest lucru asigură consistență în bibliotecă și reduce timpul de publicare a studiilor de caz noi. Integrează acest șablon în CMS-ul sau sistemul tău de management al conținutului astfel încât publicarea unui studiu de caz să genereze automat schema JSON, antetele de metadate și elementele de formatare, fără muncă manuală. Fă din crearea de studii de caz o activitate trimestrială sau lunară, nu anuală, deoarece LLM-urile descoperă și citează mai des companiile cu biblioteci de studii de caz mai profunde și mai recente. Poziționează studiile de caz ca o componentă centrală a strategiei tale de revenue enablement: ele ar trebui să alimenteze materiale de vânzare, marketing de produs, campanii de demand generation și playbook-uri de succes pentru clienți. În final, stabilește un ciclu continuu de îmbunătățire prin care monitorizezi ce studii de caz generează cele mai multe citări AI, ce metrici rezonează cu LLM-urile și ce segmente de clienți sunt cel mai frecvent citate—apoi folosește aceste insight-uri pentru a ghida următoarea generație de studii de caz. Companiile care câștigă în era AI nu doar scriu studii de caz mai bune; tratează aceste studii ca active strategice de venit ce necesită optimizare, măsurare și rafinare continuă.
Începe prin a extrage textul din PDF-uri și a mapa conținutul existent la o schemă standard cu câmpuri precum profilul clientului, provocare, soluție și rezultate. Creează apoi o versiune HTML sau CMS ușoară a fiecărei povești cu titluri clare și metadate, păstrând PDF-ul original ca resursă descărcabilă, nu ca sursă principală pentru recuperarea AI.
Marketingul sau marketingul de produs deține de obicei narațiunea, dar echipele de vânzări, ingineria de soluții și succesul clienților oferă date brute, detalii de implementare și validare. Echipele juridic, privacy și RevOps ajută la asigurarea guvernanței, redactării corecte și alinierii cu sistemele existente precum CRM-ul și platformele de enablement vânzări.
Un CMS headless sau o platformă de conținut structurat este ideală pentru stocarea schemelor și metadatelor, în timp ce un CRM sau un instrument de enablement vânzări poate oferi poveștile potrivite în fluxul de lucru. Pentru recuperarea AI, de obicei vei asocia o bază de date vectorială cu un layer de orhestrare LLM precum LangChain sau LlamaIndex.
Transcrie testimonialele video și webinariile, apoi etichetează transcrierile cu aceleași câmpuri și secțiuni ca studiile de caz scrise pentru ca AI-ul să le poată cita. Pentru grafice și diagrame, include descrieri scurte (alt-text) sau subtitrări care evidențiază insight-ul cheie, astfel încât modelele de recuperare să poată corela resursele vizuale cu întrebări specifice.
Păstrează schema de bază și ID-urile consistente la nivel global, apoi creează variante traduse care localizează limba, moneda și contextul legislativ, menținând totodată metricile canonice. Stochează versiunile specifice fiecărei localizări ca obiecte separate, dar legate, astfel încât sistemele AI să poată prioritiza răspunsurile în limba utilizatorului fără a fragmenta modelul de date.
Revizuiește studiile de caz cu impact mare cel puțin anual sau mai devreme dacă apar schimbări majore de produs, metrici noi sau modificări în contextul clientului. Folosește un workflow simplu de versionare cu date de ultimă revizuire și status-uri pentru a semnala sistemelor AI și oamenilor care povești sunt cele mai actuale.
Integrează recuperarea studiilor de caz direct în instrumentele deja utilizate de reprezentanți și creează playbook-uri concrete ce arată cum să solicite asistentului probe relevante. Consolidează adopția împărtășind povești de succes unde studiile de caz personalizate, extrase de AI, au ajutat la închiderea mai rapidă a contractelor sau la atragerea de noi stakeholderi.
Studiile de caz tradiționale sunt scrise pentru cititorii umani, cu flux narativ și design vizual. Studiile de caz optimizate AI păstrează această narațiune, dar adaugă metadate structurate, formatare consistentă, scheme JSON și claritate semantică ce permit LLM-urilor să extragă, să înțeleagă și să citeze informații specifice cu o acuratețe de peste 96%.
Urmărește modul în care sistemele AI citează brandul tău în ChatGPT, Perplexity și Google AI Overviews. Obține perspective despre vizibilitatea ta AI și optimizează-ți strategia de conținut.
Află cum se clasează studiile de caz în motoarele de căutare AI precum ChatGPT, Perplexity și Google AI Overviews. Descoperă de ce sistemele AI citează studiile...
Discuție comunitară despre cum performează studiile de caz în rezultatele căutărilor AI. Experiențe reale de la marketeri care urmăresc citațiile studiilor de c...

Află cum să creezi liste de verificare optimizate pentru AI care sunt citate de ChatGPT, Google AI Overviews și Perplexity. Descoperă de ce listele de verificar...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.