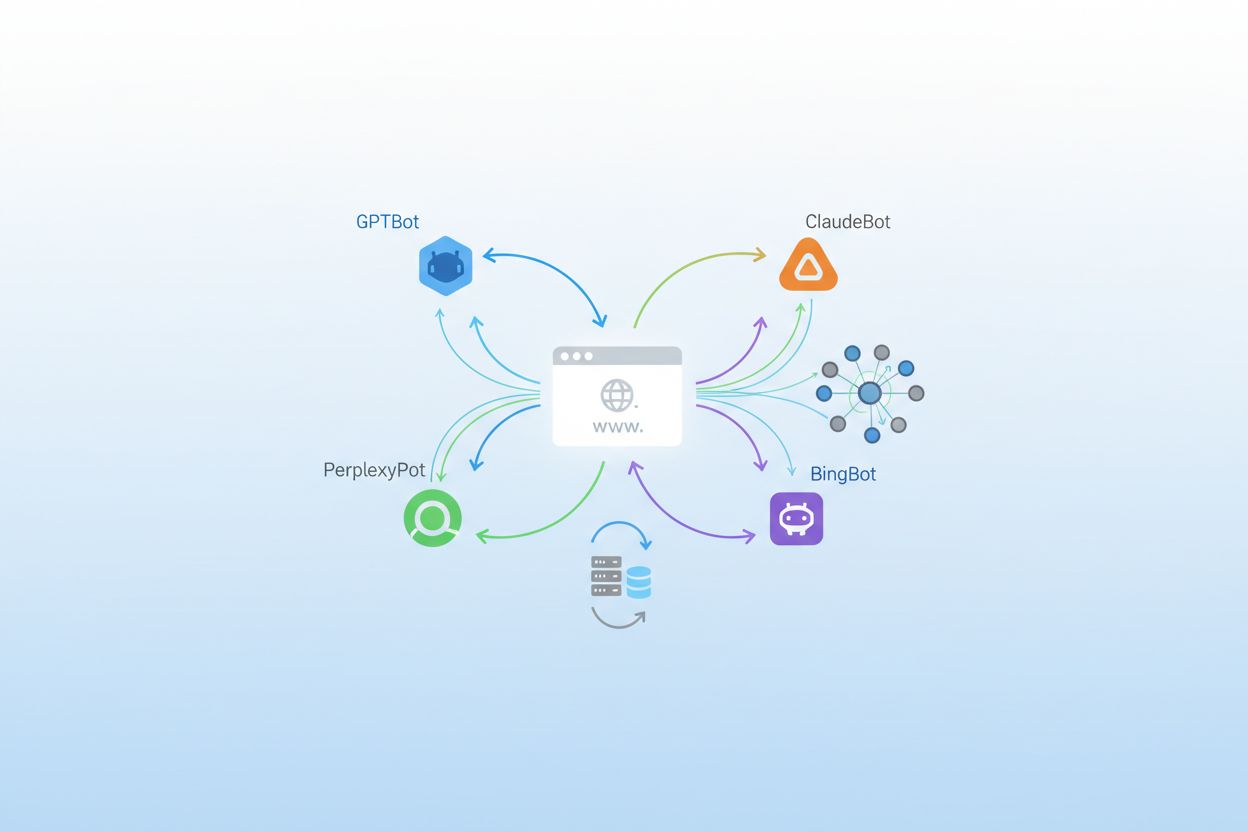
Komplett lista över AI-crawlers 2025: Alla botar du bör känna till
Omfattande guide till AI-crawlers 2025. Identifiera GPTBot, ClaudeBot, PerplexityBot och 20+ andra AI-botar. Lär dig blockera, tillåta eller övervaka crawlers med robots.txt och avancerade tekniker.
Publicerad den Jan 3, 2026.Senast ändrad den Jan 3, 2026 kl 3:24 am
AI-crawlers är automatiserade botar utformade för att systematiskt surfa och samla in data från webbplatser, men deras syfte har förändrats fundamentalt under de senaste åren. Medan traditionella sökmotor-crawlers som Googlebot fokuserar på att indexera innehåll för sökresultat, prioriterar moderna AI-crawlers insamling av träningsdata till stora språkmodeller och generativa AI-system. Enligt färska data från Playwire står AI-crawlers nu för cirka 80 % av all AI-bottrafik, vilket innebär en dramatisk ökning av volym och mångfald bland automatiserade besökare på webbplatser. Denna förändring speglar den bredare omvandlingen av hur artificiella intelligenssystem utvecklas och tränas, där man går bort från publikt tillgängliga dataset till realtidsinsamling av webbinnehåll. Att förstå dessa crawlers har blivit avgörande för webbplatsägare, publicister och innehållsskapare som behöver fatta välgrundade beslut om sin digitala närvaro.
Tre kategorier av AI-crawlers
AI-crawlers kan delas in i tre tydliga kategorier utifrån deras funktion, beteende och påverkan på din webbplats. Tränings-crawlers utgör den största gruppen och står för cirka 80 % av AI-bottrafiken, och är utformade för att samla in innehåll för maskininlärningsmodeller; dessa crawlers arbetar ofta med hög volym och har minimal referenstrafik, vilket gör dem bandbreddskrävande men osannolika att skicka besökare tillbaka till din sajt. Sök- och citerings-crawlers arbetar i måttlig omfattning och är specifikt utformade för att hitta och referera till innehåll i AI-drivna sökresultat och applikationer; till skillnad från tränings-crawlers kan dessa botar faktiskt skicka trafik till din webbplats när användare klickar vidare från AI-genererade svar. Användarinitierade hämtare utgör den minsta kategorin och aktiveras på begäran när användare uttryckligen begär innehämtning via AI-applikationer som ChatGPT:s surf-funktion; dessa crawlers har låg volym men hög relevans för individuella användarfrågor.
OpenAI driver det mest mångsidiga och aggressiva crawler-ekosystemet inom AI-landskapet, med flera botar som fyller olika syften över deras produktsvit. GPTBot är deras primära tränings-crawler, ansvarig för att samla in innehåll för att förbättra GPT-4 och framtida modeller, och har haft en häpnadsväckande 305 % tillväxt i crawlertrafik enligt Cloudflare; denna bot har ett 400:1 crawl-to-referral-förhållande, vilket innebär att den laddar ner innehåll 400 gånger för varje besökare den skickar tillbaka till din sajt. OAI-SearchBot har ett helt annat syfte, med fokus på att hitta och citera innehåll för ChatGPT:s sökfunktion utan att använda innehållet för modellträning. ChatGPT-User representerar den mest explosiva tillväxtkategorin, med en otrolig 2 825 % ökning i trafik, och aktiveras när användare slår på “Bläddra med Bing” för att hämta realtidsinnehåll på begäran. Du kan identifiera dessa crawlers via deras user agent-strängar: GPTBot/1.0, OAI-SearchBot/1.0 och ChatGPT-User/1.0, och OpenAI tillhandahåller IP-verifieringsmetoder för att bekräfta legitim crawlertrafik från deras infrastruktur.
Anthropics och Googles AI-crawlers
Anthropic, företaget bakom Claude, driver en av de mest selektiva men intensiva crawleroperationerna i branschen. ClaudeBot är deras primära tränings-crawler och arbetar med ett extraordinärt 38 000:1 crawl-to-referral-förhållande, vilket innebär att den laddar ner innehåll mycket mer aggressivt än OpenAI:s botar i förhållande till trafik som skickas tillbaka; denna extrema kvot speglar Anthropics fokus på omfattande datainsamling för modellträning. Claude-Web och Claude-SearchBot har olika syften, där den förstnämnda hanterar användarinitierad innehämtning och den senare fokuserar på sök- och citeringsfunktionalitet. Google har anpassat sin crawler-strategi för AI-eran genom att införa Google-Extended, ett särskilt token som låter webbplatser välja att ingå i AI-träning men blockera traditionell Googlebot-indexering, samt Gemini-Deep-Research, som utför djupgående forskningsförfrågningar för användare av Googles AI-produkter. Många webbplatsägare debatterar om de ska blockera Google-Extended eftersom det kommer från samma företag som kontrollerar söktrafiken, vilket gör beslutet mer komplext än med tredjeparts-AI-crawlers.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Meta, Apple, Amazon och Perplexity
Meta har blivit en betydande aktör inom AI-crawlerområdet med Meta-ExternalAgent, som står för cirka 19 % av AI-crawlertrafiken och används för att träna deras AI-modeller samt driva funktioner över Facebook, Instagram och WhatsApp. Meta-WebIndexer fyller en kompletterande funktion, med fokus på webbindexering för deras AI-drivna funktioner och rekommendationer. Apple introducerade Applebot-Extended för att stödja Apple Intelligence, deras AI-funktioner på enheten, och denna crawler har vuxit stadigt i takt med att företaget utökar sina AI-möjligheter på iPhone, iPad och Mac. Amazon driver Amazonbot för att driva Alexa och Rufus, deras AI-shoppingassistent, vilket gör den relevant för e-handelssajter och produktinriktat innehåll. PerplexityBot representerar en av de mest dramatiska tillväxthistorierna inom crawler-landskapet, med en häpnadsväckande 157 490 % ökning i trafik, vilket speglar den explosiva tillväxten för Perplexity AI som sökalternativ; trots denna massiva tillväxt står Perplexity fortfarande för en mindre absolut volym jämfört med OpenAI och Google, men utvecklingen pekar mot snabbt ökande betydelse.
Framväxande och specialiserade crawlers
Utöver de stora aktörerna finns det många framväxande och specialiserade AI-crawlers som aktivt samlar in data från webbplatser över hela internet. Bytespider, som drivs av ByteDance (moderbolag till TikTok), upplevde en dramatisk 85 % minskning i crawlertrafik, vilket antyder antingen en strategiförändring eller minskat behov av träningsdata. Cohere, Diffbot och Common Crawls CCBot representerar specialiserade crawlers med fokus på specifika användningsområden, från språkmodellträning till strukturerad dataextraktion. You.com, Mistral och DuckDuckGo har var och en sina egna crawlers för att stödja sina AI-drivna sök- och assistentfunktioner, vilket ytterligare ökar komplexiteten i crawler-landskapet. Nya crawlers dyker upp regelbundet, där startups och etablerade företag kontinuerligt lanserar AI-produkter som kräver webbinsamling. Att hålla sig informerad om dessa nya crawlers är avgörande eftersom blockering eller tillåtelse av dem kan ha stor inverkan på din synlighet i nya AI-drivna upptäcktsplattformar och applikationer.
Hur du identifierar AI-crawlers
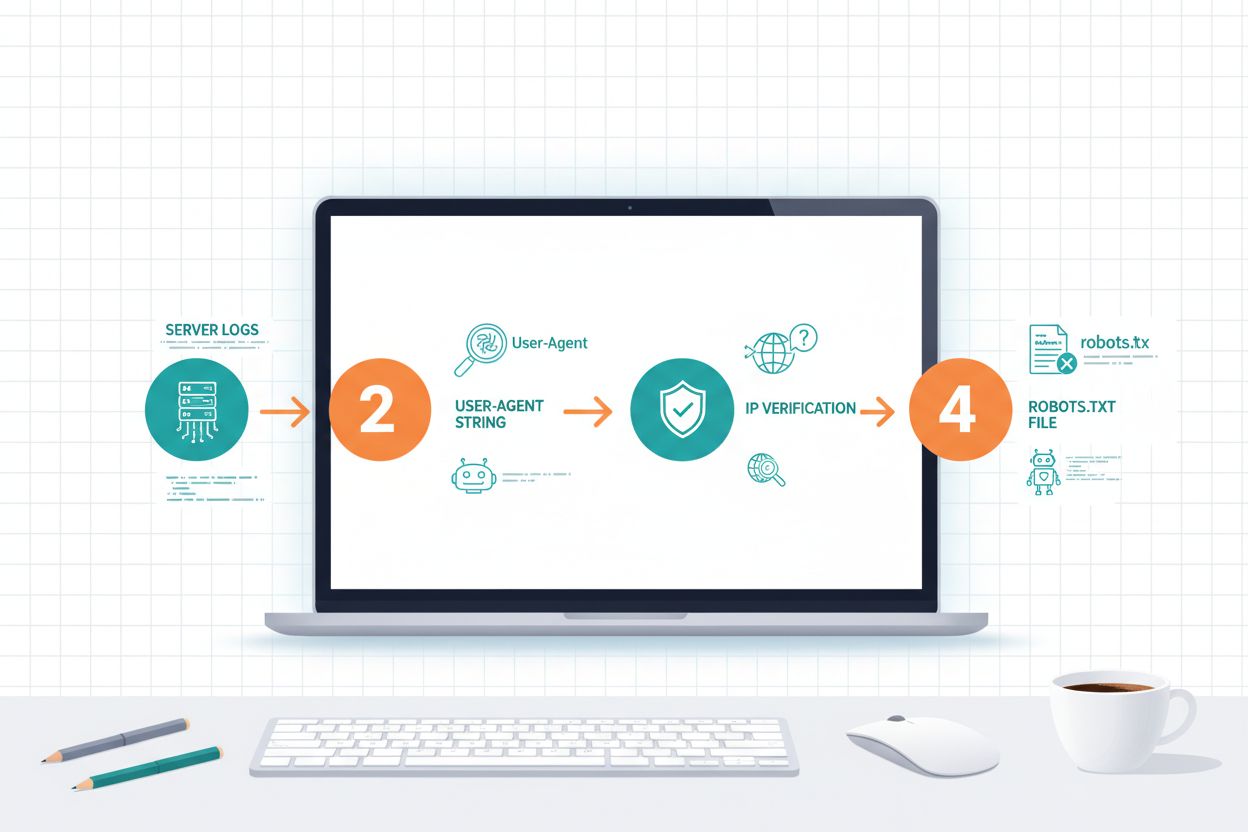
Att identifiera AI-crawlers kräver förståelse för hur de identifierar sig själva och analys av trafikmönster på din server. User-agent-strängar är den primära identifieringsmetoden, eftersom varje crawler presenterar sig med en specifik identifierare i HTTP-förfrågningar; till exempel använder GPTBotGPTBot/1.0, ClaudeBot använder Claude-Web/1.0, och PerplexityBot använder PerplexityBot/1.0. Genom att analysera dina serverloggar (vanligtvis finns de i /var/log/apache2/access.log på Linux-servrar eller IIS-loggar på Windows) kan du se vilka crawlers som besöker din webbplats och hur ofta. IP-verifiering är en annan viktig teknik, där du kan kontrollera att en crawler som utger sig för att vara från OpenAI eller Anthropic faktiskt kommer från deras legitima IP-intervall, vilka dessa företag publicerar för säkerhetsändamål. En granskning av din robots.txt-fil visar vilka crawlers du uttryckligen har tillåtit eller blockerat, och jämförelse med faktisk trafik visar om crawlers respekterar dina direktiv. Verktyg somCloudflare Radar ger realtidsinsyn i crawlertrafik och kan hjälpa dig identifiera vilka botar som är mest aktiva på din webbplats. Praktiska identifieringssteg inkluderar: att kontrollera din analysplattform för bottrafik, granska råa serverloggar efter user-agent-mönster, korsrefera IP-adresser med publicerade crawler-IP-intervall och använda onlineverktyg för crawlerverifiering för att bekräfta misstänkta trafikkällor.
Avvägningar: Blockera eller tillåta
Att avgöra om du ska tillåta eller blockera AI-crawlers innebär att väga flera konkurrerande affärsöverväganden som inte har något universellt svar. De främsta avvägningarna inkluderar:
Synlighet i AI-applikationer: Genom att tillåta crawlers säkerställer du att ditt innehåll syns i AI-drivna sökresultat, upptäcktsplattformar och AI-assistenters svar, vilket potentiellt kan driva trafik från nya källor
Bandbredd och serverbelastning: Tränings-crawlers förbrukar betydande bandbredd och serverresurser, med vissa webbplatser som rapporterar 10–30 % ökning i trafik från AI-botar enbart, vilket kan öka driftkostnaderna
Innehållsskydd vs. trafik: Att blockera crawlers skyddar ditt innehåll från att användas i AI-träning men eliminerar också möjligheten till referenstrafik från AI-drivna upptäcktsplattformar
Referenstrafikpotential: Sök- och citerings-crawlers som PerplexityBot och OAI-SearchBot kan skicka trafik tillbaka till din webbplats, medan tränings-crawlers som GPTBot och ClaudeBot vanligtvis inte gör det
Konkurrensläge: Konkurrenter som tillåter crawlers kan få synlighet i AI-applikationer medan du förblir osynlig, vilket påverkar din marknadsposition i AI-drivna upptäckter
Eftersom 80 % av AI-bottrafik kommer från tränings-crawlers med minimal referenspotential, väljer många publicister att blockera tränings-crawlers men tillåta sök- och citerings-crawlers. Beslutet beror slutligen på din affärsmodell, innehållstyp och strategiska prioriteringar kring AI-synlighet kontra resursförbrukning.
Konfigurera Robots.txt för AI-crawlers
Robots.txt-filen är ditt främsta verktyg för att kommunicera crawler-policy till AI-botar, men det är viktigt att förstå att efterlevnad är frivillig och inte tekniskt tvingande. Robots.txt använder user-agent-matchning för att rikta in sig på specifika crawlers, så att du kan skapa olika regler för olika botar; till exempel kan du blockera GPTBot men tillåta OAI-SearchBot, eller blockera alla tränings-crawlers men tillåta sök-crawlers. Enligt ny forskning har endast 14 % av de 10 000 största domänerna infört AI-specifika robots.txt-regler, vilket visar att de flesta webbplatser ännu inte har optimerat sina crawler-policyer för AI-eran. Filen använder enkel syntax där du anger user-agent-namn följt av disallow- eller allow-direktiv, och du kan använda jokertecken för att matcha flera crawlers med liknande namn.
Här är tre praktiska robots.txt-konfigurationsscenarier:
Kom ihåg att robots.txt endast är rådgivande, och skadliga eller icke-kompatibla crawlers kan ignorera dina direktiv helt. User-agent-matchning är inte skiftlägeskänslig, så gptbot, GPTBot och GPTBOT avser samma crawler, och du kan använda User-agent: * för att skapa regler som gäller för alla crawlers.
Avancerade skyddsmetoder
Utöver robots.txt finns flera avancerade metoder som ger starkare skydd mot oönskade AI-crawlers, även om varje metod har olika effektivitet och implementationskomplexitet. IP-verifiering och brandväggsregler låter dig blockera trafik från specifika IP-intervall kopplade till AI-crawlers; du kan hämta dessa intervall från crawler-operatörernas dokumentation och konfigurera din brandvägg eller Web Application Firewall (WAF) för att avvisa förfrågningar från dessa IP:er, även om detta kräver löpande underhåll när IP-intervall ändras. .htaccess-blockering på servernivå ger Apache-skydd genom att kontrollera user-agent-strängar och IP-adresser innan innehåll levereras, vilket ger tillförlitligare efterlevnad än robots.txt eftersom det sker på servernivå istället för att förlita sig på att crawlers följer reglerna.
Här är ett praktiskt .htaccess-exempel för avancerad crawler-blockering:
# Blockera AI-tränings-crawlers på servernivå<IfModulemod_rewrite.c> RewriteEngine On# Blockera på user-agent-sträng RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|Meta-ExternalAgent|Amazonbot|Bytespider) [NC]
RewriteRule ^.*$ - [F,L]
# Blockera på IP-adress (exempel-IP - byt ut mot faktiska crawler-IP) RewriteCond %{REMOTE_ADDR} ^192\.0\.2\.0$ [OR]
RewriteCond %{REMOTE_ADDR} ^198\.51\.100\.0$
RewriteRule ^.*$ - [F,L]
# Tillåt specifika crawlers medan andra blockeras RewriteCond %{HTTP_USER_AGENT} !OAI-SearchBot [NC]
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule># HTML meta-tagg-metod (lägg till i sidhuvudet)# <meta name="robots" content="noarchive, noimageindex"># <meta name="googlebot" content="noindex, nofollow">
HTML meta-taggar som <meta name="robots" content="noarchive"> och <meta name="googlebot" content="noindex"> ger sidnivåkontroll, även om de är mindre tillförlitliga än blockering på servernivå eftersom crawlers måste läsa HTML:en för att se dem. Det är viktigt att notera att IP-spoofing är tekniskt möjligt, vilket innebär att sofistikerade aktörer kan utge sig för att vara legitima crawler-IP:er, så en kombination av flera metoder ger bättre skydd än att förlita sig på en enskild strategi. Varje metod har sina fördelar: robots.txt är lätt att införa men inte tvingande, IP-blockering är tillförlitlig men kräver underhåll, .htaccess erbjuder enforcement på servernivå och meta-taggar ger granularitet på sidnivå.
Övervakning och verifiering
Att införa crawler-policy är bara halva jobbet; du måste aktivt övervaka om crawlers följer dina direktiv och justera din strategi utifrån verkliga trafikmönster. Serverloggar är din primära datakälla, vanligen placerade på /var/log/apache2/access.log på Linux-servrar eller i IIS-loggmappen på Windows-servrar, där du kan söka efter specifika user-agent-strängar för att se vilka crawlers som besöker din sajt och hur ofta. Analysplattformar som Google Analytics, Matomo eller Plausible kan konfigureras för att spåra bottrafik separat från mänskliga besökare, vilket gör att du kan se volym och beteende för olika crawlers över tid. Cloudflare Radar ger realtidsinsyn i crawlertrafik över internet och kan visa hur din webbplats crawlertrafik står sig mot branschgenomsnittet. För att verifiera att crawlers respekterar dina blockeringar kan du använda onlinetjänster för att kontrollera din robots.txt, granska serverloggarna efter blockerade user-agents och korsrefera IP-adresser med publicerade crawler-IP-intervall för att bekräfta att trafiken verkligen kommer från legitima källor. Praktiska övervakningssteg inkluderar: att sätta upp veckovis logganalys för att spåra crawlervolym, konfigurera aviseringar för ovanlig crawler-aktivitet, granska din analysdashboard månadsvis för bottrafiktrender och utföra kvartalsvisa granskningar av din crawler-policy för att säkerställa att de fortfarande överensstämmer med dina affärsmål. Regelbunden övervakning hjälper dig identifiera nya crawlers, upptäcka policyöverträdelser och fatta datadrivna beslut om vilka crawlers du ska tillåta eller blockera.
AI-crawlers framtid
Landskapet för AI-crawlers fortsätter att utvecklas snabbt, med nya aktörer som träder fram och befintliga crawlers som utökar sina förmågor i oväntade riktningar. Framväxande crawlers från företag som xAI (Grok), Mistral och DeepSeek börjar samla in webbdata i stor skala, och varje nytt AI-startup som lanseras kommer sannolikt att introducera en egen crawler för att stödja modellträning och produktfunktioner. Agentiska webbläsare utgör en ny front inom crawler-teknik, med system som ChatGPT Operator och Comet som kan interagera med webbplatser som mänskliga användare, klicka på knappar, fylla i formulär och navigera i komplexa gränssnitt; dessa webbläsarbaserade agenter innebär unika utmaningar eftersom de är svårare att identifiera och blockera med traditionella metoder. Utmaningen med webbläsarbaserade agenter är att de kanske inte tydligt identifierar sig i user-agent-strängar och potentiellt kan kringgå IP-baserad blockering genom att använda bostadsproxies eller distribuerad infrastruktur. Nya crawlers dyker upp regelbundet, ibland utan förvarning, vilket gör det viktigt att hålla sig informerad om utvecklingen inom AI och justera dina policyer därefter. Utvecklingen antyder att crawlertrafiken kommer att fortsätta öka, med Cloudflare som rapporterar en 18 % ökning av crawlertrafik totalt från maj 2024 till maj 2025, och denna tillväxt kommer sannolikt att accelerera i takt med att fler AI-applikationer når mainstream. Webbplatsägare och publicister måste förbli vaksamma och anpassningsbara, regelbundet granska sina crawler-policyer och övervaka nya utvecklingar för att säkerställa att deras strategier förblir effektiva i detta snabbt föränderliga landskap.
Övervaka ditt varumärke i AI-svar
Samtidigt som det är viktigt att hantera crawleråtkomst till din webbplats, är det minst lika viktigt att förstå hur ditt innehåll används och citeras i AI-genererade svar. AmICited.com är en specialiserad plattform som löser detta problem genom att spåra hur AI-crawlers samlar in ditt innehåll och övervaka om ditt varumärke och innehåll citeras korrekt i AI-drivna applikationer. Plattformen hjälper dig att förstå vilka AI-system som använder ditt innehåll, hur ofta din information förekommer i AI-svar och om korrekt attribution ges till dina ursprungskällor. För publicister och innehållsskapare ger AmICited.com värdefulla insikter om din synlighet i AI-ekosystemet, så att du kan mäta effekten av ditt beslut att tillåta eller blockera crawlers och förstå det faktiska värdet du får från AI-drivna upptäckter. Genom att övervaka dina citeringar över flera AI-plattformar kan du fatta mer informerade beslut om din crawler-policy, identifiera möjligheter att öka innehållets synlighet i AI-svar och säkerställa att din immateriella rättighet tillskrivs korrekt. Om du är seriös med att förstå ditt varumärkes närvaro på det AI-drivna nätet ger AmICited.com den transparens och övervakning du behöver för att hålla dig uppdaterad och skydda värdet av ditt innehåll i denna nya era av AI-drivna upptäckter.
Vanliga frågor
Vad är skillnaden mellan tränings-crawlers och sökcrawlers?
Tränings-crawlers som GPTBot och ClaudeBot samlar in innehåll för att bygga dataset till stora språkmodeller och blir en del av AI:ns kunskapsbas. Sökmotor-crawlers som OAI-SearchBot och PerplexityBot indexerar innehåll för AI-drivna sökupplevelser och kan skicka referenstrafik tillbaka till publicister via citeringar.
Bör jag blockera alla AI-crawlers eller bara tränings-crawlers?
Det beror på dina affärsprioriteringar. Att blockera tränings-crawlers skyddar ditt innehåll från att inkorporeras i AI-modeller. Att blockera sökcrawlers kan minska din synlighet på AI-drivna upptäcktsplattformar som ChatGPT search eller Perplexity. Många publicister väljer selektiv blockering som riktar sig mot tränings-crawlers men tillåter sök- och citerings-crawlers.
Hur verifierar jag om en crawler är legitim eller spoofad?
Den mest tillförlitliga verifieringsmetoden är att kontrollera förfrågnings-IP:n mot officiellt publicerade IP-intervall från crawler-operatörer. Stora företag som OpenAI, Anthropic och Amazon publicerar sina crawler-IP-adresser. Du kan även använda brandväggsregler för att vitlista verifierade IP:er och blockera förfrågningar från oidentifierade källor som utger sig för att vara AI-crawlers.
Påverkar blockering av Google-Extended mina sökrankningar?
Google anger officiellt att blockering av Google-Extended inte påverkar sökrankningar eller inkludering i AI Overviews. Vissa webbansvariga har dock uttryckt oro, så övervaka din sökprestanda efter att du infört blockeringar. AI Overviews i Google Search följer vanliga Googlebot-regler, inte Google-Extended.
Hur ofta bör jag uppdatera min AI-crawler-blocklista?
Nya AI-crawlers dyker upp regelbundet, så granska och uppdatera din blocklista minst kvartalsvis. Följ resurser som ai.robots.txt-projektet på GitHub för community-underhållna listor. Kontrollera serverloggar varje månad för att identifiera nya crawlers som besöker din webbplats men inte finns i din nuvarande konfiguration.
Kan AI-crawlers ignorera robots.txt-direktiv?
Ja, robots.txt är rådgivande snarare än tvingande. Välskötta crawlers från stora företag respekterar i regel robots.txt-direktiv, men vissa crawlers ignorerar dem. För starkare skydd, implementera servernivå-blockering via .htaccess eller brandväggsregler och verifiera legitima crawlers genom publicerade IP-adressintervall.
Vilken påverkan har AI-crawlers på min webbplats bandbredd?
AI-crawlers kan skapa betydande serverbelastning och bandbreddsförbrukning. Vissa infrastrukturprojekt rapporterade att blockering av AI-crawlers minskade bandbreddsförbrukningen från 800GB till 200GB dagligen, vilket sparar cirka 1 500 USD per månad. Publicister med hög trafik kan se betydande kostnadsminskningar genom selektiv blockering.
Hur kan jag övervaka vilka AI-crawlers som besöker min webbplats?
Kontrollera dina serverloggar (vanligtvis på /var/log/apache2/access.log i Linux) efter user-agent-strängar som matchar kända crawlers. Använd analysplattformar som Google Analytics eller Cloudflare Radar för att spåra bottrafik separat. Ställ in aviseringar för ovanlig crawler-aktivitet och genomför kvartalsvisa granskningar av din crawler-policy.
Övervaka ditt varumärke i AI-svar
Spåra hur AI-plattformar som ChatGPT, Perplexity och Google AI Overviews refererar till ditt innehåll. Få realtidsnotiser när ditt varumärke nämns i AI-genererade svar.
Hur du Tillåter AI-botar att Crawla din Webbplats: Komplett robots.txt & llms.txt-guide
Lär dig hur du tillåter AI-botar som GPTBot, PerplexityBot och ClaudeBot att crawla din webbplats. Konfigurera robots.txt, ställ in llms.txt och optimera för AI...
AI-crawlers förklarade: GPTBot, ClaudeBot och fler
Förstå hur AI-crawlers som GPTBot och ClaudeBot fungerar, deras skillnader från traditionella sökmotor-crawlers och hur du optimerar din webbplats för synlighet...
Ska du blockera eller tillåta AI-crawlers? Beslutsramverk
Lär dig hur du fattar strategiska beslut om att blockera AI-crawlers. Utvärdera innehållstyp, trafikkällor, intäktsmodeller och konkurrensposition med vårt omfa...
11 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.