Vilka innehållsformat får flest AI-citat? Dataanalys
Upptäck vilka innehållsformat som citeras mest av AI-modeller. Analysera data från över 768 000 AI-citat för att optimera din innehållsstrategi för ChatGPT, Per...
9 min läsning

Lär dig hur du testar innehållsformat för AI-citat med hjälp av A/B-testmetodik. Upptäck vilka format som ger högst AI-synlighet och citeringsfrekvens i ChatGPT, Google AI Overviews och Perplexity.
Artificiella intelligenssystem bearbetar innehåll fundamentalt annorlunda än mänskliga läsare och förlitar sig på strukturerade signaler för att förstå betydelse och extrahera information. Medan människor kan navigera genom kreativ formatering eller tät prosa kräver AI-modeller tydliga organisationshierarkier och semantiska markörer för att effektivt tolka och förstå innehållets värde. Forskning visar att strukturerat innehåll med korrekt rubrikhierarki får 156 % högre citeringsfrekvens än ostrukturerade alternativ, vilket belyser en avgörande skillnad mellan innehåll anpassat för människor och AI. Denna skillnad finns eftersom AI-system tränas på stora datamängder där välorganiserat innehåll oftast korrelerar med auktoritativa och tillförlitliga källor. Att förstå och testa olika innehållsformat har blivit avgörande för varumärken som vill synas i AI-baserade sökresultat och svarsmotorer.
Olika AI-plattformar uppvisar distinkta preferenser för innehållskällor och format, vilket skapar en komplex optimeringsmiljö. Forskning som analyserar 680 miljoner citat på stora plattformar avslöjar stora skillnader i hur ChatGPT, Google AI Overviews och Perplexity hämtar sin information. Dessa plattformar citerar inte bara samma källor – de prioriterar olika typer av innehåll baserat på sina algoritmer och träningsdata. Att förstå dessa plattformsspecifika mönster är avgörande för att utveckla riktade innehållsstrategier som maximerar synligheten över flera AI-system.
| Plattform | Mest citerade källa | Citeringsandel | Föredraget format |
|---|---|---|---|
| ChatGPT | Wikipedia | 7,8 % av alla citat | Auktoritativa kunskapsbaser, encyklopediskt innehåll |
| Google AI Overviews | 2,2 % av alla citat | Gemenskapsdiskussioner, användargenererat innehåll | |
| Perplexity | 6,6 % av alla citat | Peer-to-peer-information, gemenskapsinsikter |
ChatGPT:s överväldigande preferens för Wikipedia (47,9 % av dess topp 10-källor) visar en tydlig förkärlek för auktoritativt, faktabaserat innehåll med etablerad trovärdighet. Däremot uppvisar både Google AI Overviews och Perplexity en mer balanserad fördelning, där Reddit dominerar citeringsmönstret. Detta visar att Perplexity prioriterar gemenskapsdriven information med 46,7 % av toppkällorna, medan Google har en mer diversifierad strategi över flera plattformstyper. Data visar tydligt att en universell innehållsstrategi inte fungerar – varumärken måste anpassa sin strategi efter vilka AI-plattformar som är viktigast för deras målgrupp.
Schema markup är kanske den viktigaste faktorn för sannolikheten att bli citerad av AI, där korrekt implementerad JSON-LD markup ger 340 % högre citeringsfrekvens än identiskt innehåll utan strukturerad data. Denna dramatiska skillnad beror på hur AI-motorer tolkar semantisk betydelse – strukturerad data ger explicit kontext som tar bort tvetydigheter vid tolkning av innehåll. När en AI-motor stöter på schema markup förstår den direkt entitetsrelationer, innehållstyper och hierarkisk betydelse utan att enbart förlita sig på naturlig språkbehandling.
De mest effektiva schema-implementeringarna inkluderar Article-schema för blogginlägg, FAQ-schema för frågor-och-svar-sektioner, HowTo-schema för instruktionsinnehåll och Organization-schema för varumärkesigenkänning. JSON-LD-formatet överträffar specifikt andra strukturerade dataformat eftersom AI-motorer kan tolka det oberoende av HTML-innehållet, vilket möjliggör renare datautvinning och minskad processkomplexitet. Semantiska HTML-taggar som <header>, <nav>, <main>, <section> och <article> ger ytterligare tydlighet som hjälper AI-system att förstå innehållsstruktur och hierarki mer effektivt än grundläggande markup.
A/B-testning ger den mest tillförlitliga metoden för att avgöra vilka innehållsformat som ger högst AI-citeringsfrekvens i din specifika nisch. Istället för att förlita dig på allmänna bästa praxis kan du med kontrollerade experiment mäta den faktiska effekten av formatändringar på din publik och AI-synlighet. Processen kräver noggrann planering för att isolera variabler och säkerställa statistisk validitet, men insikterna rättfärdigar investeringen.
Följ denna systematiska A/B-testningsram:
Statistisk signifikans kräver uppmärksamhet på stickprovsstorlek och testlängd. I AI-applikationer med gles data eller långsvansfördelning kan det vara svårt att snabbt samla in tillräckligt många observationer. De flesta experter rekommenderar att tester pågår i minst 2–4 veckor för att ta hänsyn till tidsmässiga variationer och säkerställa tillförlitliga resultat.
Forskning på tusentals AI-citat visar tydliga prestationshierarkier mellan olika innehållsformat. Listbaserat innehåll får 68 % fler AI-citat än texttunga alternativ, främst för att listor ger diskreta, lätttolkade informationsenheter som AI-motorer enkelt kan extrahera och sammanfatta. När AI-plattformar genererar svar kan de referera till specifika listpunkter utan att behöva omformulera komplexa meningar, vilket gör listbaserat innehåll mycket värdefullt för citering.
Tabeller visar exceptionell prestanda med upp till 96 % noggrannhet vid AI-tolkning, långt bättre än prosa som beskriver samma information. Tabellinnehåll gör det möjligt för AI-system att snabbt extrahera specifika datapunkter utan komplex texttolkning, vilket gör tabeller särskilt värdefulla för faktabaserat, jämförande eller statistiskt innehåll. Frågor-och-svar-format får 45 % högre AI-synlighet jämfört med traditionella styckeformat för identiska ämnen, eftersom Q&A-innehåll speglar hur användare interagerar med AI-plattformar och hur AI-system genererar svar.
Jämförelseformat (X vs Y) fungerar mycket väl eftersom de ger binära, lättsammanfattade strukturer som ligger nära hur AI-system bryter ner frågor i delämnen. Fallstudier blandar berättelser med data, vilket gör dem övertygande för läsare och tolkbara för AI tack vare deras problem–lösning–resultat-struktur. Egen forskning och expertinsikter får förtur eftersom de erbjuder unik data som inte finns någon annanstans och ger trovärdighets-signaler som AI-system uppmärksammar och belönar. Den viktigaste insikten är att inget format fungerar universellt – den bästa strategin kombinerar flera format utifrån innehållstyp och mål-AI-plattform.
Att implementera schema markup kräver förståelse för de olika typerna och att välja de som är mest relevanta för ditt innehåll. För blogginlägg och artiklar ger Article-schema omfattande metadata, inklusive författare, publiceringsdatum och innehållsstruktur. FAQ-schema fungerar utmärkt för frågor-och-svar-sektioner, där frågor och svar märks upp explicit så att AI-system kan extrahera dem tillförlitligt. HowTo-schema gynnar instruktionsinnehåll genom att definiera sekventiella steg, medan Product-schema hjälper e-handelsplatser att kommunicera specifikationer och priser.
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "Vilket är det bästa innehållsformatet för AI-citat?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Det bästa innehållsformatet beror på din plattform och publik, men strukturerade format som listor, tabeller och frågor-och-svar-sektioner uppnår konsekvent högre AI-citeringsfrekvens. Listor får 68 % fler citat än stycken, medan tabeller uppnår 96 % igenkänningsnoggrannhet."
}
}
]
}
Implementeringen kräver noggrannhet i syntaxen – ogiltig schema markup kan faktiskt försämra dina AI-citeringschanser istället för att förbättra dem. Använd Googles Rich Results Test eller Schema.orgs valideringsverktyg för att verifiera din markup innan publicering. Håll konsekventa formateringshierarkier med H2:or för huvudsakliga sektioner, H3:or för underpunkter och korta stycken (50–75 ord max) som fokuserar på enskilda koncept. Lägg till TL;DR-sammanfattningar i början eller slutet av sektioner för att ge AI färdiga utdrag som kan stå som självständiga svar.
Att mäta AI-motorns prestanda kräver andra mätvärden än traditionell SEO, med fokus på citeringsspårning, svarsinclusion och omnämnanden i kunskapsgrafer snarare än positioner i sökresultat. Citeringsövervakning på stora plattformar ger den mest direkta insikten om dina formattestningsinsatser lyckas, och visar vilka innehållsdelar som AI-system faktiskt refererar till. Verktyg som AmICited spårar specifikt hur AI-plattformar citerar ditt varumärke på ChatGPT, Google AI Overviews, Perplexity och andra svarsmotorer, vilket ger insikt i citeringsmönster och trender.
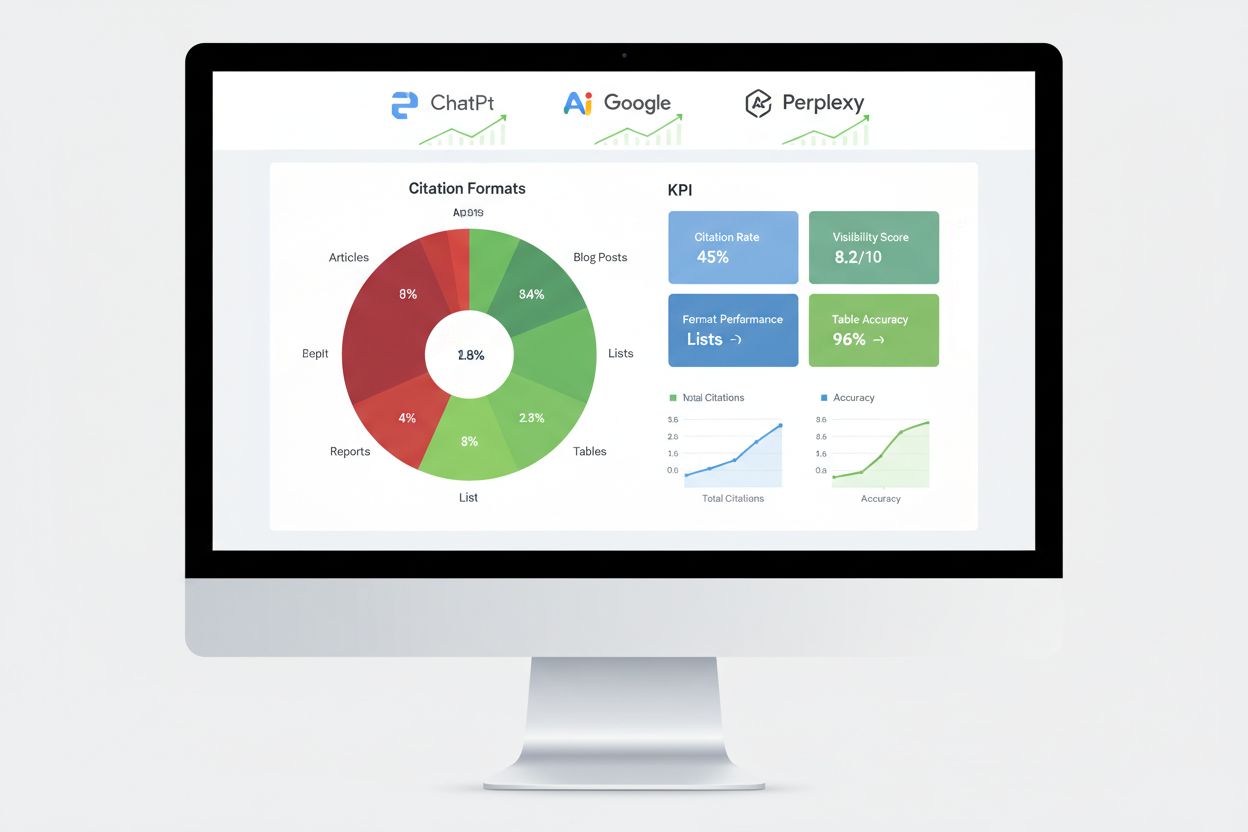
Viktiga mätmetoder innefattar att spåra andelen utvalda utdrag, vilket visar innehåll som AI-system finner särskilt värdefullt för direkta svar. Kunskapspanel-förekomst signalerar att AI-system erkänner ditt varumärke som en auktoritativ entitet värdig egna informationspaneler. Förekomst i röstsökresultat visar om ditt innehåll används i konversations-AI-svar, medan generativa motorers svarsfrekvens visar hur ofta AI-system refererar till ditt innehåll vid användarfrågor. A/B-testning av olika format ger de mest tillförlitliga prestandadata genom att isolera enskilda variabler och identifiera specifika effektfaktorer. Fastställ baslinjemått före ändringar och övervaka sedan utvecklingen veckovis för att spåra trender och avvikelser som kan tyda på framgångsrika eller mindre lyckade formatförändringar.
Många organisationer som testar format fastnar i förutsägbara fällor som äventyrar resultaten och leder till felaktiga slutsatser. Otillräckliga stickprov är det vanligaste felet – tester med för få citat eller interaktioner leder till statistiskt osäkra resultat som verkar meningsfulla men egentligen speglar slumpen. Se till att samla in minst 100 citat per variant innan du drar slutsatser och använd statistiska kalkylatorer för att fastställa exakt stickprovsstorlek för din konfidensnivå och effektstorlek.
Störande variabler inför bias när flera faktorer ändras samtidigt, vilket gör det omöjligt att avgöra vilken förändring som orsakat observerade skillnader. Håll alla element identiska utom det format du testar – samma nyckelord, längd, struktur och publiceringstid. Tidsmässig bias uppstår när testning sker under ovanliga perioder (helger, större nyhetshändelser, plattformsförändringar) som snedvrider resultaten. Kör tester under normala perioder och ta hänsyn till säsongsvariationer genom att testa i minst 2–4 veckor. Urvalsbias uppstår när testgrupper skiljer sig på sätt som påverkar resultatet – säkerställ slumpmässig tilldelning av innehåll till varianter. Fela tolkningar av korrelation och kausalitet leder till felaktiga slutsatser när yttre faktorer råkar sammanfalla med testperioden. Överväg alltid alternativa förklaringar till observerade förändringar och bekräfta resultat genom flera testrundor innan du gör permanenta ändringar.
Ett teknikföretag som testade innehållsformat för AI-synlighet upptäckte att omvandling av deras produktjämförelseartiklar från styckeformat till strukturerade jämförelsetabeller ökade AI-citeringarna med 52 % på 60 dagar. Tabellerna gav tydlig, överskådlig information som AI-systemen kunde extrahera direkt, medan den ursprungliga prosan krävde mer komplex tolkning. De behöll identisk textmängd och nyckelordsoptimering, så att formatändringen blev den enda variabeln.
Ett finansbolag implementerade FAQ-schema på sitt befintliga innehåll utan att skriva om något, utan lade bara till strukturerad markup på existerande frågor-och-svar-sektioner. Detta resulterade i 34 % fler utvalda utdrag och 28 % ökning av AI-citat inom 45 dagar. Schema markup förändrade inte innehållet i sig men gjorde det mycket enklare för AI-system att identifiera och extrahera relevanta svar. Ett SaaS-företag genomförde multivariat testning mellan tre format samtidigt – listor, tabeller och traditionella stycken – för identiskt innehåll om deras produktfunktioner. Resultaten visade att listor överträffade stycken med 68 %, medan tabeller gav högst noggrannhet vid AI-tolkning men lägre total citeringsvolym. Detta visade att formateffektivitet varierar beroende på innehållstyp och AI-plattform, och bekräftade att testning är avgörande istället för att förlita sig på generella bästa praxis. Dessa verkliga exempel visar att formattestning ger mätbara, betydande förbättringar av AI-synlighet när det görs på rätt sätt.
Landskapet för innehållsformattestning utvecklas ständigt i takt med att AI-system blir mer sofistikerade och nya optimeringstekniker utvecklas. Multi-armed bandit-algoritmer är ett stort framsteg jämfört med traditionell A/B-testning, då de dynamiskt justerar trafikfördelningen till olika varianter baserat på realtidsresultat istället för att vänta på förutbestämda testperioder. Detta minskar tiden för att identifiera vinnande varianter och maximerar prestanda under själva testperioden.
Adaptiv experimentering med hjälp av förstärkningsinlärning gör det möjligt för AI-modeller att kontinuerligt lära sig och anpassa sig utifrån pågående experiment, vilket förbättrar prestandan i realtid istället för genom avgränsade testcykler. AI-driven automatisering av A/B-testning använder AI för att automatisera experimentdesign, resultatanalys och optimeringsrekommendationer, vilket gör att organisationer kan testa fler varianter samtidigt utan att komplexiteten ökar proportionellt. Dessa nya tillvägagångssätt utlovar snabbare iterationscykler och mer avancerade optimeringsstrategier. Organisationer som behärskar innehållsformattestning idag kommer att ha konkurrensfördelar när dessa avancerade tekniker blir standard och kan dra nytta av nya AI-plattformar och utvecklande citeringsalgoritmer innan konkurrenterna hinner anpassa sina strategier.
Det bästa innehållsformatet beror på din plattform och publik, men strukturerade format som listor, tabeller och frågor-och-svar-sektioner uppnår konsekvent högre AI-citeringsfrekvens. Listor får 68 % fler citat än stycken, medan tabeller uppnår 96 % igenkänningsnoggrannhet. Nyckeln är att testa olika format med ditt specifika innehåll för att identifiera vad som fungerar bäst.
De flesta experter rekommenderar att tester pågår i minst 2–4 veckor för att ta hänsyn till tidsmässiga variationer och säkerställa tillförlitliga resultat. Denna period gör det möjligt att samla in tillräckligt med datapunkter (vanligtvis 100+ citat per variant) och ta hänsyn till säsongsvariationer eller förändringar i plattformsalgoritmer som kan påverka resultaten.
Ja, du kan genomföra multivariata tester över flera format samtidigt, men detta kräver noggrann planering för att undvika komplexitet vid tolkning av resultaten. Börja med enkla A/B-tester där två format jämförs, och gå vidare till multivariat testning när du förstår grunderna och har tillräckliga statistiska resurser.
Du behöver vanligtvis minst 100 citat eller interaktioner per variant för att uppnå statistisk signifikans. Använd statistiska kalkylatorer för att fastställa exakt stickprovsstorlek för din specifika konfidensnivå och effektstorlek. Större stickprov ger mer tillförlitliga resultat men kräver längre testperioder.
Börja med att identifiera den mest relevanta schematypen för ditt innehåll (Artikel, FAQ, HowTo etc.), använd sedan JSON-LD-format för implementeringen. Validera din markup med Googles Rich Results Test eller Schema.orgs valideringsverktyg innan publicering. Ogiltig schema markup kan faktiskt skada dina AI-citeringschanser, så noggrannhet är avgörande.
Prioritera utifrån din publik och dina affärsmål. ChatGPT föredrar auktoritativa källor som Wikipedia, Google AI Overviews föredrar gemenskapsinnehåll som Reddit, och Perplexity lyfter fram peer-to-peer-information. Analysera vilka plattformar som ger mest relevant trafik till din sajt och optimera för dessa först.
Implementera kontinuerlig testning som en del av din innehållsstrategi. Börja med kvartalsvisa testcykler, och öka sedan frekvensen när du bygger upp expertis och etablerar baslinjemått. Regelbunden testning hjälper dig att ligga steget före AI-plattformsalgoritmer och upptäcka nya formatpreferenser.
Följ förbättringar i citeringsfrekvens, andel utvalda utdrag, förekomst i kunskapspaneler och svarsfrekvens i generativa motorer. Fastställ baslinjemått innan testning, och övervaka sedan resultat veckovis för att identifiera trender. Ett lyckat test visar vanligtvis på över 20 % förbättring av ditt primära mätvärde inom 4–8 veckor.
Spåra hur AI-plattformar citerar ditt innehåll över olika format. Upptäck vilka innehållsstrukturer som ger mest AI-synlighet och optimera din strategi med verkliga data.
Upptäck vilka innehållsformat som citeras mest av AI-modeller. Analysera data från över 768 000 AI-citat för att optimera din innehållsstrategi för ChatGPT, Per...

Lär dig hur du strukturerar ditt innehåll för att bli citerad av AI-sökmotorer som ChatGPT, Perplexity och Google AI. Expertråd för AI-synlighet och citat....
Upptäck hur innehåll i flera format ökar AI-synligheten i ChatGPT, Google AI Overview och Perplexity. Lär dig det femstegsramverk som maximerar varumärkescitat ...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.