
Så säkerställer du att AI-crawlers ser allt ditt innehåll
Lär dig hur du gör ditt innehåll synligt för AI-crawlers som ChatGPT, Perplexity och Googles AI. Upptäck tekniska krav, bästa praxis och övervakningsstrategier ...
10 min läsning
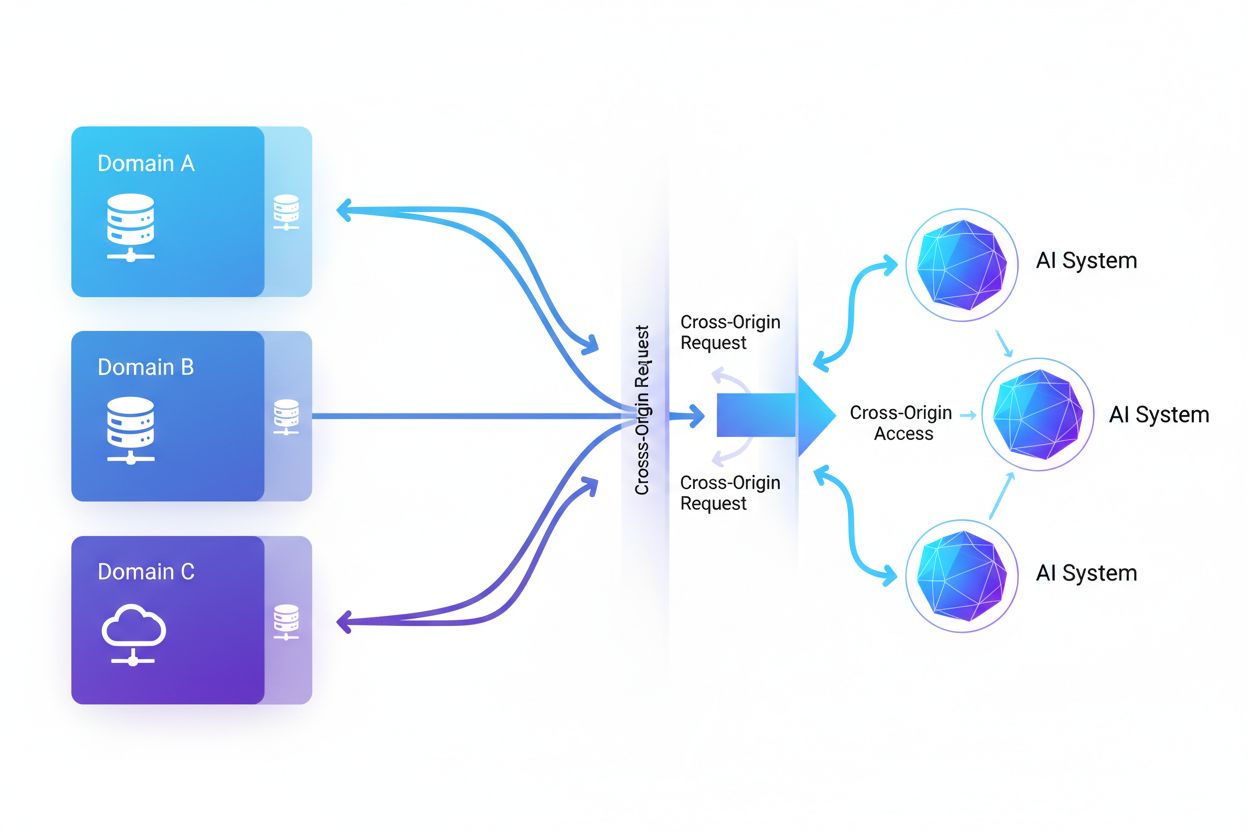
Cross-Origin AI Access avser möjligheten för artificiella intelligenssystem och webbcrawlers att begära och hämta innehåll från domäner som skiljer sig från deras ursprung, reglerat av säkerhetsmekanismer som CORS. Det omfattar hur AI-företag skalar datainsamling för att träna stora språkmodeller samtidigt som de navigerar begränsningar för åtkomst över olika ursprung. Förståelsen av detta koncept är avgörande för innehållsskapare och webbplatsägare för att skydda immateriella rättigheter och behålla kontrollen över hur deras innehåll används av AI-system. Insyn i AI-aktivitet över olika ursprung hjälper till att skilja mellan legitim AI-åtkomst och otillåten skrapning.
Cross-Origin AI Access avser möjligheten för artificiella intelligenssystem och webbcrawlers att begära och hämta innehåll från domäner som skiljer sig från deras ursprung, reglerat av säkerhetsmekanismer som CORS. Det omfattar hur AI-företag skalar datainsamling för att träna stora språkmodeller samtidigt som de navigerar begränsningar för åtkomst över olika ursprung. Förståelsen av detta koncept är avgörande för innehållsskapare och webbplatsägare för att skydda immateriella rättigheter och behålla kontrollen över hur deras innehåll används av AI-system. Insyn i AI-aktivitet över olika ursprung hjälper till att skilja mellan legitim AI-åtkomst och otillåten skrapning.
Cross-Origin AI Access avser möjligheten för artificiella intelligenssystem och webbcrawlers att begära och hämta innehåll från domäner som skiljer sig från deras ursprung, reglerat av säkerhetsmekanismer som Cross-Origin Resource Sharing (CORS). I takt med att AI-företag skalar upp sin datainsamling för att träna stora språkmodeller och andra AI-system har förståelsen för hur dessa system navigerar begränsningar över olika ursprung blivit avgörande för innehållsskapare och webbplatsägare. Utmaningen ligger i att skilja mellan legitim AI-åtkomst för sökindexering och otillåten skrapning för modellträning, vilket gör insyn i AI-aktivitet över olika ursprung nödvändig för att skydda immateriella rättigheter och behålla kontrollen över hur innehållet används.
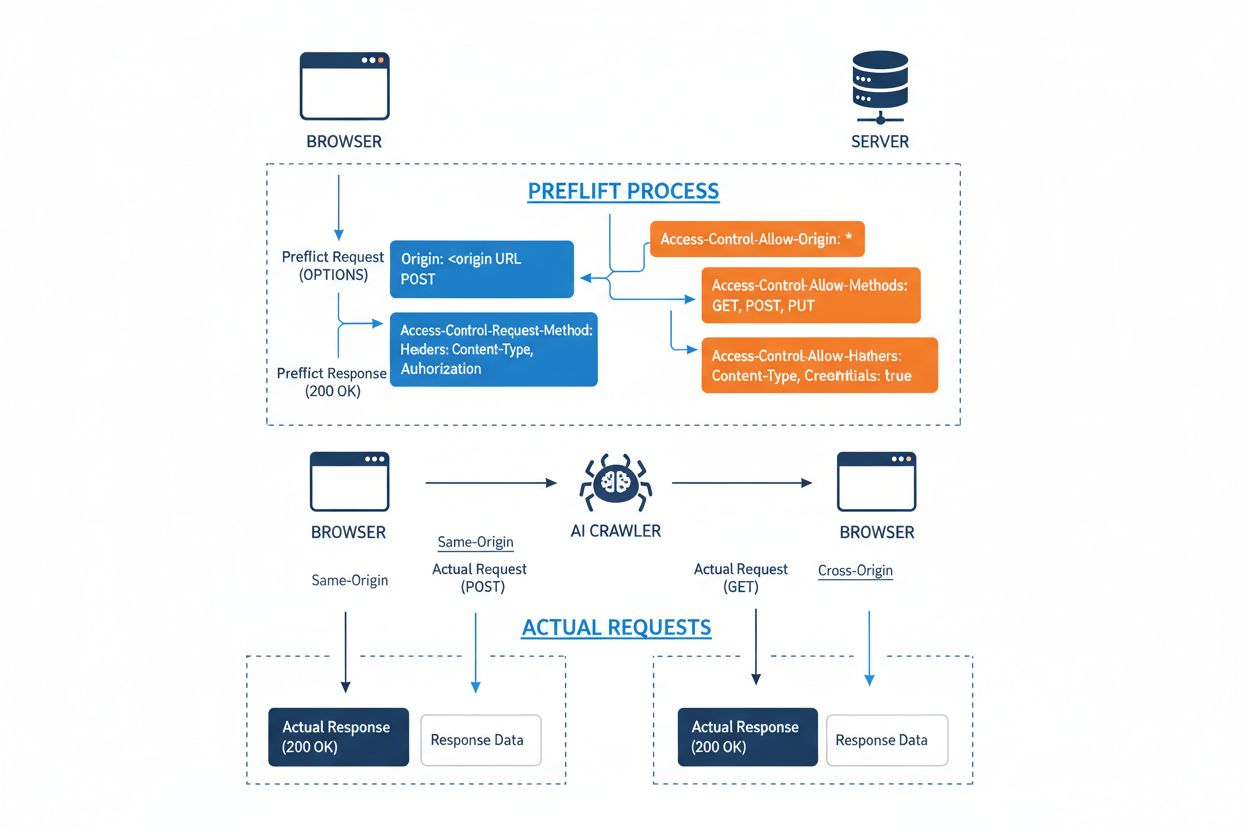
Cross-Origin Resource Sharing (CORS) är en HTTP-headerbaserad säkerhetsmekanism som låter servrar ange vilka ursprung (domäner, scheman eller portar) som får åtkomst till deras resurser. När en AI-crawler eller någon klient försöker få åtkomst till en resurs från ett annat ursprung initierar webbläsaren eller klienten en förhandskontroll (preflight request) med OPTIONS-metoden för att kontrollera om servern tillåter den faktiska begäran. Servern svarar med specifika CORS-headers som bestämmer åtkomstbehörigheter, inklusive vilka ursprung som är tillåtna, vilka HTTP-metoder som får användas, vilka headers som kan inkluderas och om autentiseringsuppgifter som cookies eller inloggningstoken får skickas med begäran.
| CORS Header | Syfte |
|---|---|
Access-Control-Allow-Origin | Anger vilka ursprung som får åtkomst till resursen (* för alla, eller specifika domäner) |
Access-Control-Allow-Methods | Listar tillåtna HTTP-metoder (GET, POST, PUT, DELETE, etc.) |
Access-Control-Allow-Headers | Definierar vilka begärande-headers som är tillåtna (Authorization, Content-Type, etc.) |
Access-Control-Allow-Credentials | Avgör om autentiseringsuppgifter (cookies, auth tokens) får inkluderas i begäranden |
Access-Control-Max-Age | Anger hur länge förhandskontrollssvar får cachas (i sekunder) |
Access-Control-Expose-Headers | Listar svar-headers som klienter kan komma åt |
AI-crawlers interagerar med CORS genom att respektera dessa headers när de är korrekt konfigurerade, även om många sofistikerade bots försöker kringgå dessa begränsningar genom att förfalska user agents eller använda proxy-nätverk. CORS effektivitet som försvar mot otillåten AI-åtkomst beror helt på korrekt serverkonfiguration och crawlerns vilja att följa begränsningarna—en avgörande distinktion som blivit allt viktigare i takt med att AI-företag konkurrerar om träningsdata.
Landskapet av AI-crawlers som får åtkomst till webben har vuxit dramatiskt, med flera stora aktörer som dominerar åtkomstmönster över olika ursprung. Enligt Cloudflares analys av nätverkstrafik är de mest förekommande AI-crawlers:
Dessa crawlers genererar miljarder förfrågningar per månad, där vissa som Bytespider och GPTBot får åtkomst till merparten av internetets publikt tillgängliga innehåll. Den enorma volymen och den aggressiva karaktären på denna aktivitet har fått stora plattformar som Reddit, Twitter/X, Stack Overflow och många nyhetsorganisationer att införa blockeringsåtgärder.
Felkonfigurerade CORS-policyer skapar betydande säkerhetsbrister som AI-crawlers kan utnyttja för att få åtkomst till känslig data utan tillstånd. När servrar sätter Access-Control-Allow-Origin: * utan korrekt validering tillåter de oavsiktligt vilket ursprung som helst—inklusive illvilliga AI-skrapare—att komma åt resurser som borde vara begränsade. En särskilt farlig konfiguration uppstår när Access-Control-Allow-Credentials: true kombineras med wildcard-ursprung, vilket låter angripare stjäla autentiserad användardata genom att göra cross-origin-förfrågningar som inkluderar sessionscookies eller autentiseringstoken.
Vanliga CORS-felkonfigurationer innefattar att dynamiskt spegla Origin-headern direkt i Access-Control-Allow-Origin-svaret utan validering, vilket i praktiken tillåter vilket ursprung som helst att få åtkomst till resursen. Alltför tillåtande vitlistor som inte korrekt validerar domängränser kan utnyttjas via subdomänattacker eller prefixmanipulation. Dessutom misslyckas många organisationer med att implementera korrekt validering av Origin-headern, vilket gör dem sårbara för förfalskade förfrågningar. Konsekvenserna av dessa sårbarheter sträcker sig bortom datastöld till otillåten träning av AI-modeller på skyddat innehåll, insamling av konkurrensinformation och brott mot immateriella rättigheter—risker som verktyg som AmICited.com hjälper organisationer att övervaka och mäta.
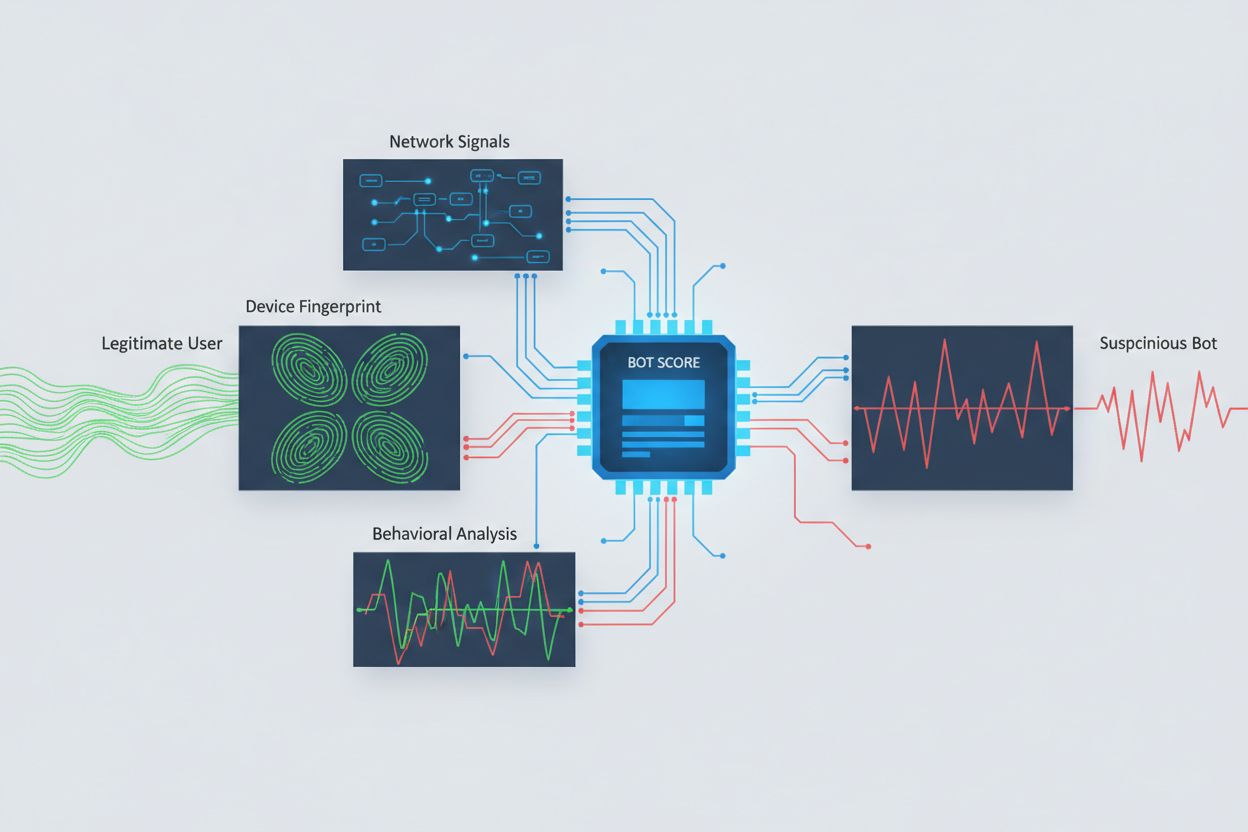
Att identifiera AI-crawlers som försöker få åtkomst över olika ursprung kräver analys av flera signaler utöver enkla user agent-strängar, som är triviala att förfalska. User agent-analys är fortfarande en förstalinjens metod, då många AI-crawlers identifierar sig med specifika user agent-strängar som “GPTBot/1.0” eller “ClaudeBot/1.0”, även om sofistikerade crawlers avsiktligt döljer sin identitet genom att utge sig för att vara legitima webbläsare. Beteendefingeravtryck analyserar hur förfrågningar görs—ser på mönster som förfrågningars timing, sekvensen av besökta sidor, närvaro eller frånvaro av JavaScriptexekvering och interaktionsmönster som skiljer sig fundamentalt från mänskligt surfande.
Nätverkssignalanalys ger djupare detektionsmöjligheter genom att undersöka TLS-handshake-signaturer, IP-reputation, DNS-upplösningsmönster och anslutningsegenskaper som avslöjar botaktivitet även när user agents är förfalskade. Enhetsfingeravtryck samlar dussintals signaler såsom webbläsarversion, skärmupplösning, installerade typsnitt, operativsystemdetaljer och JA3 TLS-fingeravtryck för att skapa unika identifierare för varje förfrågningskälla. Avancerade detektionssystem kan identifiera när flera sessioner kommer från samma enhet eller skript och därigenom fånga distribuerade skrapningsförsök som försöker kringgå hastighetsbegränsning genom att sprida förfrågningar över många IP-adresser. Organisationer kan använda dessa detektionsmetoder via säkerhetsplattformar och övervakningstjänster för att få insyn i vilka AI-system som får åtkomst till deras innehåll och hur de försöker kringgå begränsningar.
Organisationer använder flera kompletterande strategier för att blockera eller kontrollera åtkomst för AI-crawlers över olika ursprung, med insikten att ingen enskild metod ger fullständigt skydd:
User-agent: GPTBot följt av Disallow: /) ger en artig men frivillig mekanism; effektivt mot välbeteende crawlers men lätt ignorerat av beslutsamma skrapareDet mest effektiva försvaret kombinerar flera lager, eftersom beslutsamma angripare utnyttjar svagheter i varje enskild metod. Organisationer måste kontinuerligt övervaka vilka blockeringsmetoder som fungerar och anpassa sig i takt med att crawlers utvecklar sina undvikandetekniker.
Effektiv hantering av Cross-Origin AI Access kräver ett omfattande, lagerbaserat tillvägagångssätt som balanserar säkerhet med operativa behov. Organisationer bör implementera en trappstegsstrategi som börjar med grundläggande kontroller som robots.txt och user agent-filtrering, och därefter successivt lägger till mer sofistikerade detektions- och blockeringsmekanismer baserat på observerade hot. Kontinuerlig övervakning är avgörande—att spåra vilka AI-system som får åtkomst till ditt innehåll, hur ofta de gör förfrågningar och om de respekterar dina begränsningar ger den insyn som krävs för att fatta informerade beslut om åtkomstpolicyer.
Dokumentation av åtkomstpolicyer ska vara tydlig och verkställbar, med explicita användarvillkor som förbjuder otillåten skrapning och anger konsekvenser vid överträdelser. Regelbundna granskningar av CORS-konfigurationer hjälper till att identifiera felkonfigurationer innan de utnyttjas, medan en uppdaterad inventering av kända AI-crawlers user agents och IP-intervall möjliggör snabb respons på nya hot. Organisationer bör även överväga de affärsmässiga konsekvenserna av att blockera AI-åtkomst—vissa AI-crawlers tillför värde via sökindexering eller legitima partnerskap, så policyer bör skilja mellan fördelaktiga och skadliga åtkomstmönster. Implementering av dessa rutiner kräver samordning mellan säkerhets-, juridik- och affärsteam för att säkerställa att policyerna överensstämmer med organisationens mål och regelverk.
Specialiserade verktyg och plattformar har utvecklats för att hjälpa organisationer att övervaka och kontrollera Cross-Origin AI Access med större precision och insyn. AmICited.com erbjuder omfattande övervakning av hur AI-system refererar till och får åtkomst till ditt varumärke över GPTs, Perplexity, Google AI Overviews och andra AI-plattformar, med insyn i vilka AI-modeller som använder ditt innehåll och hur ofta ditt varumärke förekommer i AI-genererade svar. Denna övervakningskapacitet omfattar även spårning av åtkomstmönster över olika ursprung samt förståelse för det bredare ekosystemet av AI-system som interagerar med dina digitala tillgångar.
Utöver övervakning erbjuder Cloudflare bot-hanteringsfunktioner med ett-klick-blockering av kända AI-crawlers och använder maskininlärningsmodeller tränade på nätverksomfattande trafikmönster för att identifiera bots även när de förfalskar user agents. AWS WAF (Web Application Firewall) tillhandahåller anpassningsbara regler för att blockera specifika user agents och IP-intervall, medan Imperva erbjuder avancerad botdetektion som kombinerar beteendeanalys med hotinformation. Bright Data är specialiserat på att förstå bot-trafikmönster och kan hjälpa organisationer att särskilja olika typer av crawlers. Verktygsvalet beror på organisationens storlek, tekniska kompetens och specifika behov—från enkel robots.txt-hantering för små sajter till företagsklassade bot-hanteringsplattformar för stora organisationer som hanterar känslig data. Oavsett val av verktyg kvarstår den grundläggande principen: insyn i AI-åtkomst över olika ursprung är grunden för effektiv kontroll och skydd av digitala tillgångar.
CORS (Cross-Origin Resource Sharing) är en säkerhetsmekanism som styr vilka ursprung som får åtkomst till resurser på en server. Cross-Origin AI Access syftar specifikt på hur AI-system och crawlers interagerar med CORS för att begära innehåll från olika domäner. Medan CORS är det tekniska ramverket beskriver Cross-Origin AI Access den praktiska utmaningen att hantera AI-crawlers beteende inom det ramverket, inklusive detektion och blockering av otillåten AI-åtkomst.
De flesta välbeteende AI-crawlers identifierar sig genom specifika user agent-strängar som 'GPTBot/1.0' eller 'ClaudeBot/1.0' som tydligt anger deras syfte. Många sofistikerade crawlers förfalskar dock avsiktligt user agents genom att utge sig för att vara legitima webbläsare som Chrome eller Safari för att kringgå blockering baserad på user agent. Därför krävs avancerade detektionsmetoder med beteendefingeravtryck och nätverkssignalanalys för att identifiera bots oavsett deras påstådda identitet.
robots.txt tillhandahåller en frivillig mekanism för att be crawlers respektera åtkomstbegränsningar, och välbeteende AI-crawlers som GPTBot följer i allmänhet dessa direktiv. robots.txt är dock inte tvingande—beslutsamma skrapare kan helt enkelt ignorera det. Många AI-företag har ertappats med att kringgå robots.txt-begränsningar, vilket gör det till ett nödvändigt men otillräckligt försvar som bör kombineras med tekniska blockeringsmetoder som user agent-filtrering, hastighetsbegränsning och enhetsfingeravtryck.
Felkonfigurerade CORS-policyer kan tillåta otillåtna AI-crawlers att få åtkomst till känslig data, stjäla autentiserad användarinformation via begäranden med inloggningsuppgifter och skrapa skyddat innehåll för otillåten AI-modellträning. De farligaste konfigurationerna kombinerar wildcard-ursprung med credential-tillstånd, vilket i praktiken tillåter vilket ursprung som helst att få åtkomst till skyddade resurser. Dessa felkonfigurationer kan leda till stöld av immateriella rättigheter, insamling av konkurrensinformation och brott mot innehållslicensavtal.
Detektion kräver analys av flera signaler bortom user agent-strängar. Du kan granska serverloggar efter kända AI-crawlers user agents, implementera beteendefingeravtryck för att identifiera bots utifrån deras interaktionsmönster, analysera nätverkssignaler som TLS-handshakes och DNS-mönster samt använda enhetsfingeravtryck för att identifiera distribuerade skrapningsförsök. Verktyg som AmICited.com erbjuder omfattande övervakning av hur AI-system refererar till ditt varumärke, medan plattformar som Cloudflare erbjuder maskininlärningsbaserad botdetektion som identifierar även förfalskade crawlers.
Ingen enskild metod ger fullständigt skydd, så en lager-på-lager-strategi är mest effektiv. Börja med robots.txt och user agent-filtrering för grundläggande försvar, lägg till hastighetsbegränsning för att minska påverkan, implementera enhetsfingeravtryck för att fånga sofistikerade bots och överväg autentisering eller betalvägg för känsligt innehåll. De mest effektiva organisationerna kombinerar flera tekniker och övervakar kontinuerligt vilka metoder som fungerar samt anpassar sig när crawlers utvecklar sina undvikandetekniker.
Nej. Medan stora företag som OpenAI och Anthropic påstår sig respektera robots.txt och CORS-begränsningar har undersökningar visat att många AI-crawlers kringgår dessa begränsningar. Perplexity AI ertappades med att förfalska user agents för att kringgå blockeringar, och forskning visar att OpenAI:s och Anthropics crawlers har observerats få åtkomst till innehåll trots uttryckliga robots.txt disallow-regler. Denna inkonsekvens gör att tekniska blockeringsmetoder och juridisk upprätthållning blir alltmer nödvändiga.
AmICited.com erbjuder omfattande övervakning av hur AI-system refererar till och får åtkomst till ditt varumärke över GPTs, Perplexity, Google AI Overviews och andra AI-plattformar. Den spårar vilka AI-modeller som använder ditt innehåll, hur ofta ditt varumärke förekommer i AI-genererade svar och ger insyn i det bredare ekosystemet av AI-system som interagerar med dina digitala tillgångar. Denna övervakning hjälper dig att förstå omfattningen av AI-åtkomst och fatta informerade beslut om din strategi för innehållsskydd.
Få fullständig insyn i vilka AI-system som får åtkomst till ditt varumärke över GPTs, Perplexity, Google AI Overviews och andra plattformar. Spåra AI-åtkomstmönster över olika ursprung och förstå hur ditt innehåll används i AI-träning och inferens.
Lär dig hur du gör ditt innehåll synligt för AI-crawlers som ChatGPT, Perplexity och Googles AI. Upptäck tekniska krav, bästa praxis och övervakningsstrategier ...

Lär dig hur du granskar AI-crawlers åtkomst till din webbplats. Upptäck vilka botar som kan se ditt innehåll och åtgärda hinder som förhindrar AI-synlighet i Ch...

Lär dig om AI-crawlfel - tekniska problem som hindrar AI-crawlers från att komma åt innehåll. Förstå JavaScript-rendering, robots.txt, strukturerad data och hur...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.