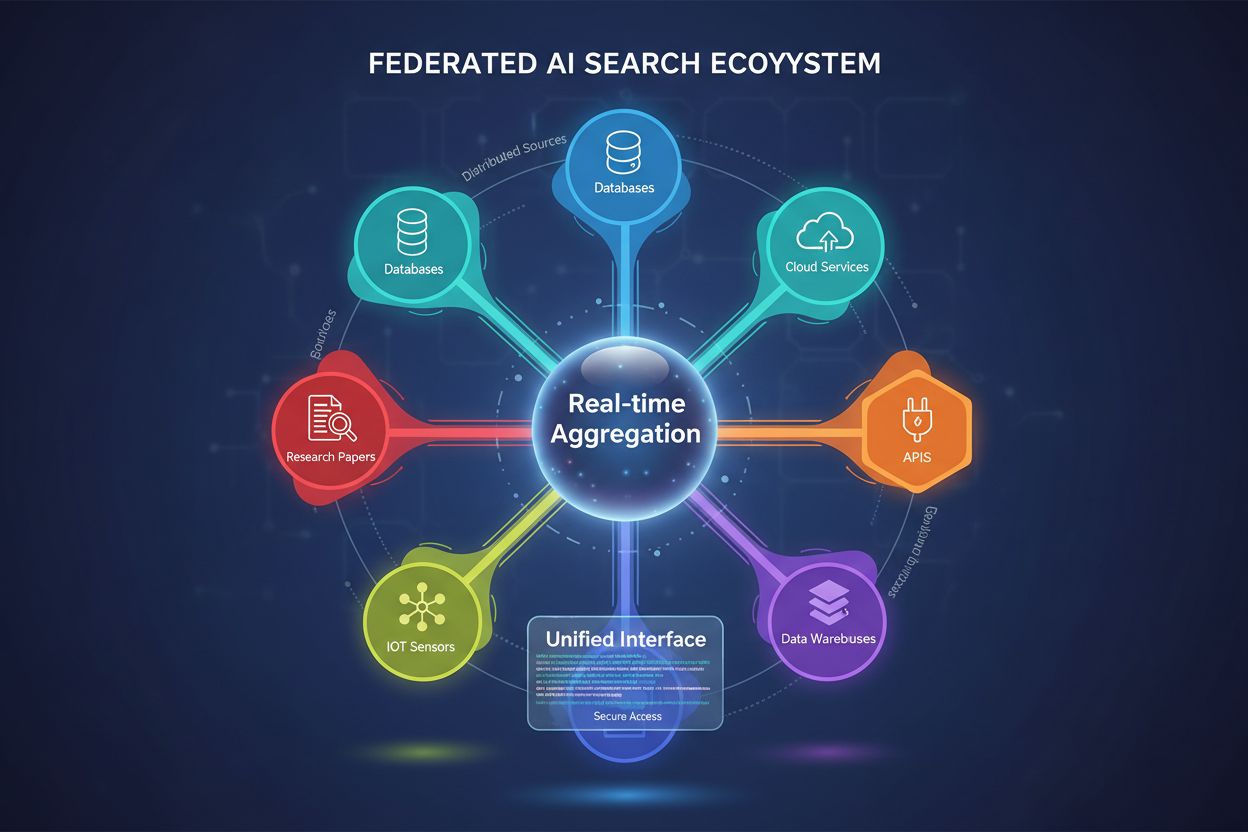
Federerad AI-sökning är ett system som samtidigt söker i flera oberoende datakällor med en enda sökfråga och aggregerar resultaten i realtid utan att flytta eller duplicera data. Det gör det möjligt för organisationer att få tillgång till distribuerad information över databaser, API:er och molntjänster samtidigt som datasäkerhet och efterlevnad upprätthålls. Till skillnad från traditionella centraliserade sökmotorer bevarar federerade system datakällornas självständighet och ger ändå enhetlig informationsupptäckt. Detta tillvägagångssätt är särskilt värdefullt för företag som hanterar olika datakällor över olika avdelningar, geografier eller organisationer.
Federerad AI-sökning
Federerad AI-sökning är ett system som samtidigt söker i flera oberoende datakällor med en enda sökfråga och aggregerar resultaten i realtid utan att flytta eller duplicera data. Det gör det möjligt för organisationer att få tillgång till distribuerad information över databaser, API:er och molntjänster samtidigt som datasäkerhet och efterlevnad upprätthålls. Till skillnad från traditionella centraliserade sökmotorer bevarar federerade system datakällornas självständighet och ger ändå enhetlig informationsupptäckt. Detta tillvägagångssätt är särskilt värdefullt för företag som hanterar olika datakällor över olika avdelningar, geografier eller organisationer.
Kärndefinition & Nyckelkaraktäristika
Federerad AI-sökning är ett distribuerat informationssökningssystem som samtidigt söker i flera heterogena datakällor och intelligent aggregerar resultat med hjälp av artificiella intelligensmetoder. Till skillnad från traditionella centraliserade sökmotorer som bibehåller ett enda indexerat register, arbetar federerad AI-sökning över decentraliserade nätverk av oberoende databaser, kunskapsbaser och informationssystem utan att kräva datakonsolidering eller centraliserad indexering.
Den grundläggande principen bakom federerad AI-sökning är käll-agnostisk sökning, där en enda användarfråga intelligent dirigeras till relevanta datakällor, behandlas självständigt av varje källa och därefter syntetiseras till en enhetlig resultatmängd. Detta tillvägagångssätt bevarar datakällornas självständighet och möjliggör omfattande informationsupptäckt över organisatoriska och tekniska gränser.
Nyckelkaraktäristika för federerade AI-söksystem inkluderar:
Distribuerad arkitektur: Data förblir på sin ursprungliga plats över flera register, vilket eliminerar behovet av datamigrering eller centraliserad lagring. Varje källa bibehåller sitt eget index, sina egna åtkomstkontroller och uppdateringsmekanismer oberoende av de andra.
Intelligent frågoroutning: AI-algoritmer analyserar inkommande sökfrågor för att identifiera vilka källor som sannolikt innehåller relevant information, vilket optimerar sökeffektiviteten och minskar onödiga frågor till irrelevanta databaser.
Resultataggregering och rankning: Maskininlärningsmodeller syntetiserar resultat från flera källor och tillämpar sofistikerade rankningsalgoritmer som tar hänsyn till källans trovärdighet, resultatets relevans, aktualitet och användarens kontext.
Stöd för heterogena källor: Federerade system hanterar olika dataformat, scheman, frågespråk och åtkomstprotokoll, inklusive relationsdatabaser, dokumentlager, kunskapsgrafer, API:er och ostrukturerade textregister.
Integrering i realtid: Till skillnad från batchbaserade datalagringsmetoder erbjuder federerad sökning nära realtidsåtkomst till aktuell information från alla anslutna källor, vilket säkerställer att resultaten är färska och korrekta.
Semantisk förståelse: Moderna federerade AI-sökningar utnyttjar naturlig språkbehandling och semantisk analys för att förstå frågeintentioner bortom nyckelords-matchning, vilket möjliggör mer exakt källval och tolkning av resultat.
Hur federerad AI-sökning fungerar
Den operativa arbetsflödet för federerad AI-sökning består av flera koordinerade steg, där varje steg förstärks av artificiell intelligens för att optimera prestanda och resultatkvalitet.
Steg
Process
AI-komponent
Utdata
Frågeanalys
Användarfrågan tolkas och analyseras för intention, entiteter och kontext
Arbetsflödet bygger på parallell exekvering, där flera källor frågas samtidigt i stället för sekventiellt. Denna parallellisering minskar avsevärt den totala svarstiden trots den extra koordineringskostnaden. Avancerade federerade system implementerar adaptiv frågeplanering, där systemet lär sig av historiska frågemönster för att optimera källval och exekveringsstrategier över tid.
Timeout- och reservmekanismer är avgörande komponenter för att säkerställa systemets tillförlitlighet. När en källa svarar långsamt eller misslyckas kan systemet antingen vänta med adaptiva timeout-inställningar eller fortsätta med resultat från tillgängliga källor, vilket ger en gradvis minskning av resultatens fullständighet snarare än total felhantering.
Federerade AI-söksystem kan kategoriseras längs flera dimensioner:
Efter arkitekturmodell:
Centraliserad federerad sökning: En central koordinator hanterar frågoroutning och resultataggregering samt metadata om alla källor. Detta förenklar koordineringen men innebär en potentiell felpunkt.
Decentraliserad federerad sökning: Peer-to-peer-arkitektur där vilken nod som helst kan initiera sökningar och koordinera resultat utan central myndighet. Detta ger robusthet men ökar koordinationskomplexiteten.
Hybrid federerad sökning: Kombinerar centraliserad koordinering för kärnfunktioner med decentraliserade funktioner för redundans och skalbarhet.
Efter typ av datakälla:
Strukturerad datafederation: Integrerar relationsdatabaser, datalager och strukturerade register med väldefinierade scheman.
Ostrukturerad datafederation: Söker i dokumentregister, textkollektioner och innehållshanteringssystem utan fasta schemakrav.
Kunskapsgrafsfederation: Söker i distribuerade kunskapsgrafer och semantiska nätverk, och utnyttjar ontologier för intelligent integrering.
API-baserad federation: Aggregerar resultat från flera webbtjänster och REST-API:er och hanterar olika svarsformat och protokoll.
Hybridinnehållsfederation: Kombinerar flera datatyper i ett enda federerat söksystem.
Efter omfattning och skala:
Företagsintern federerad sökning: Integrerar datakällor inom organisationen, vanligtvis med kontrollerad åtkomst och kända källkarakteristika.
Webbskalig federerad sökning: Fungerar över internetåtkomliga källor med okända eller varierande egenskaper, vilket kräver robust hantering av opålitliga källor.
Domänspecifik federation: Fokuserar på särskilda branscher eller kunskapsområden med specialiserade källtyper och domänspecifika rankningskriterier.
Efter intelligensnivå:
Grundläggande federation: Enkel frågoroutning och resultatsammanslagning utan avancerade AI-komponenter.
Intelligent federation: Inkluderar maskininlärning för källval, rankning och optimering av resultatkvalitet.
Semantisk federation: Utnyttjar kunskapsgrafer, ontologier och semantisk förståelse för djup integrering mellan heterogena källor.
Autonom federation: Självoptimerande system som kontinuerligt lär sig och anpassar källval och rankningsstrategier.
Viktiga fördelar & styrkor
Dataautonomi och styrning: Organisationer behåller kontrollen över sin data och slipper flytta känslig information till centraliserade register. Detta bevarar datastyrningspolicyer, efterlevnadskrav och säkerhetskontroller på källnivå.
Skalbarhet utan konsolidering: Federerade system kan skalas genom att lägga till nya källor utan att kräva datamigrering eller omstrukturering av datalager. Detta gör det möjligt för organisationer att gradvis integrera nya datakällor i takt med att verksamhetsbehoven förändras.
Realtidsåtkomst till information: Genom att direkt fråga källorna ger federerad sökning åtkomst till aktuell information utan den latens som batchbaserade datalager innebär. Detta är särskilt värdefullt för tidskritiska applikationer.
Kostnadseffektivitet: Eliminerar de betydande infrastruktur- och driftkostnader som är förknippade med att bygga och underhålla centraliserade datalager. Organisationer undviker dataduplicering, överflödig lagring och komplexa ETL-processer.
Minskad dataduplicering: Till skillnad från datalagringsmetoder som duplicerar data mellan system behåller federerad sökning en enda sanningskälla, vilket minskar lagringsbehovet och säkerställer konsistens.
Flexibilitet och anpassningsförmåga: Nya källor kan integreras utan att ändra befintlig infrastruktur eller reindexera centraliserade register. Denna flexibilitet möjliggör snabb respons på förändrade affärskrav.
Förbättrad datakvalitet: Genom att fråga auktoritativa källor direkt minskas problem med inaktuell eller inkonsekvent data som kan uppstå vid periodisk synkronisering i datalager.
Förhöjd säkerhet: Känslig data lämnar aldrig sin ursprungliga plats, vilket minskar risken för obehörig åtkomst eller intrång. Åtkomstkontroller hanteras på källnivå i stället för centralt.
Stöd för heterogena källor: Federerade system stödjer olika teknologier, format och protokoll utan krav på standardisering eller migrering till gemensamma plattformar.
Intelligent resultatsyntes: AI-driven rankning och aggregering ger högre kvalitet på resultaten än enkel sammanslagning, med hänsyn till källans trovärdighet, resultatets relevans och användarkontext.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
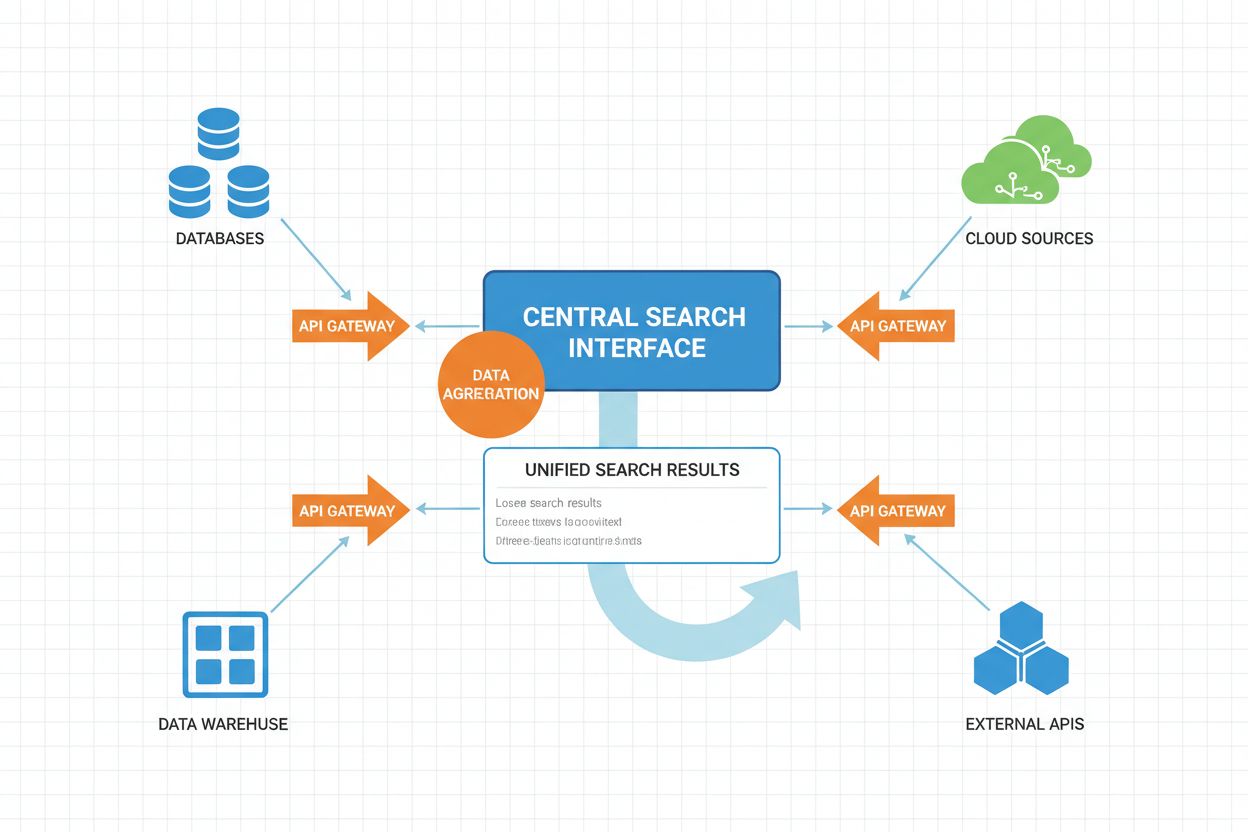
Teknisk arkitektur & komponenter
Moderna federerade AI-söksystem består av flera sammankopplade tekniska komponenter som samarbetar för att tillhandahålla integrerad sökfunktionalitet.
Frågebehandlingsmotor: Den centrala komponenten som tar emot användarfrågor och orkestrerar arbetsflödet för federerad sökning. Motorn inkluderar frågeparsing, semantisk analys och identifiering av intentioner. Avancerade implementationer använder transformerbaserade språkmodeller för att förstå komplexa frågesemantiker och användarintentioner.
Källregister och metadatahantering: Bibehåller omfattande metadata om tillgängliga datakällor, inklusive schemainformation, innehållskaraktäristik, uppdateringsfrekvens, tillgänglighetsmönster och prestandamått. Detta register möjliggör intelligent källval och sökoptimering. Maskininlärningsmodeller analyserar historiska frågemönster för att förutsäga källors relevans för nya frågor.
Intelligent källvalskomponent: Använder maskininlärningsklassificerare för att avgöra vilka källor som sannolikt innehåller relevant information för en given fråga. Denna modul tar hänsyn till flera faktorer, såsom källans innehållstäckning, historisk sökframgång, tillgänglighet och uppskattad svarstid. Avancerade system använder förstärkningsinlärning för att kontinuerligt optimera källval baserat på frågeresultat.
Frågeöversättnings- och anpassningslager: Konverterar användarfrågor till källspecifika format och frågespråk. Detta inkluderar SQL-generering för relationsdatabaser, SPARQL för kunskapsgrafer, REST-API-anrop för webbtjänster och naturliga språkfrågor för ostrukturerade textsöksystem. Semantisk mappning säkerställer att frågeintentionen bevaras över olika frågespråk och datamodeller.
Distribuerad exekveringskoordinator: Hanterar parallell sökexekvering över flera källor, inklusive timeout-hantering, lastbalansering och felåterställning. Denna komponent implementerar adaptiva timeout-strategier som justeras utifrån källans svarsmönster och systembelastning.
Resultatnormaliseringsmotor: Konverterar resultat från heterogena källor till gemensamt format för aggregering och rankning. Detta inkluderar schemajustering, datatypkonvertering och formatstandardisering. Motorn hanterar saknade fält, motstridiga datatyper och strukturella skillnader mellan källor.
Semantisk berikningsmodul: Förbättrar resultat med ytterligare kontext och semantisk information, såsom entitetslänkning till kunskapsbaser, semantisk taggning utifrån ontologier och relationsutvinning från ostrukturerad text. Dessa berikningar förbättrar rankningsnoggrannhet och resultatförståelse.
Learning-to-rank-modell: En maskininlärningsmodell tränad på historiska par av frågor och resultat för att förutsäga resultatets relevans. Modellen tar hänsyn till hundratals faktorer, inklusive källans trovärdighet, innehållets aktualitet, användarprofil och semantisk likhet mellan fråga och resultat. Moderna implementationer använder gradientförstärkning eller neurala nätverksbaserade rankningsmodeller.
Dedupliceringsmotor: Identifierar och tar bort dubbletter eller nästan dubbletter av resultat från olika källor. Detta görs med hjälp av likhetsmått, inklusive exakt matchning, fuzzy string-matching och semantisk likhet baserat på embeddingar.
Personaliseringmotor: Anpassar resultatordning utifrån användarprofiler, historiska preferenser och kontextuell information. Denna komponent implementerar kollaborativ filtrering och innehållsbaserade rekommendationer för att öka relevansen för varje användare.
Cache- och optimeringslager: Implementerar intelligent cachning för att minska redundanta frågor till källor. Detta inkluderar cache för frågeresultat, källmetadata och inlärda frågemönster som förutser framtida informationsbehov.
Övervaknings- och analysmodul: Följer systemprestanda, källtillförlitlighet, frågemönster och kvalitetsmått på resultat. Dessa data återkopplas till optimeringskomponenter för kontinuerlig förbättring av systemet.
Användningsområden i olika branscher
Hälso- och sjukvård samt medicinsk forskning: Federerad sökning integrerar patientjournaler över sjukhussystem, forskningsdatabaser, kliniska prövningsregister och medicinska litteraturarkiv. Läkare kan fråga om hela patienthistoriker över flera vårdgivare utan att centralisera känslig medicinsk data. Forskare får tillgång till distribuerade kliniska data för epidemiologiska studier och bibehåller HIPAA-efterlevnad och patientsekretess.
Finansiella tjänster: Banker och investeringsbolag använder federerad sökning för att fråga handelsdata, marknadsinformation, regulatoriska databaser och interna transaktionsregister samtidigt. Detta möjliggör realtidsriskbedömning, efterlevnadsövervakning och marknadsanalys utan att konsolidera känslig finansiell data.
Juridik och efterlevnad: Advokatbyråer och företagsjuridiska avdelningar söker i rättsfallsdatabaser, regulatoriska register, interna dokumenthanteringssystem och kontraktsregister. Federerad sökning möjliggör omfattande juridisk research och bevarar advokatklientprivilegium och dokumentsekretess.
E-handel och detaljhandel: Nätbutiker integrerar produktkataloger från flera lager, leverantörssystem och marknadsplattformar. Federerad sökning ger enhetlig produktupptäckt med bibehållen kontroll för leverantörer över eget lager och prissättning.
Offentlig sektor och förvaltning: Myndigheter söker över distribuerade databaser såsom folkbokföring, skatteuppgifter, tillståndssystem och offentliga register utan att centralisera känslig medborgardata. Detta möjliggör omfattande offentliga tjänster med bibehållen datasäkerhet och integritet.
Tillverkning och försörjningskedja: Tillverkare integrerar leverantörsdatabaser, lagerhantering, produktionsregister och logistikplattformar. Federerad sökning ger synlighet i försörjningskedjan och låter partners behålla egna system och affärshemligheter.
Utbildning och forskning: Universitet söker över institutionella register, bibliotekssystem, forskningsdatabaser och öppna publikationer. Federerad sökning möjliggör omfattande akademisk upptäckt och respekterar institutionell självständighet och immaterialrätt.
Telekommunikation: Teleoperatörer söker över kunddatabaser, nätverksinfrastrukturregister, faktureringssystem och tjänstekataloger. Federerad sökning möjliggör enhetlig kundservice samtidigt som separata system bibehålls för olika tjänstelinjer och regioner.
Energi och verktyg: Energibolag söker över produktionsanläggningar, distributionsnät, kunddatabaser och regulatoriska efterlevnadssystem. Federerad sökning ger operativ insyn medan regionala aktörer behåller egna system.
Media och förlag: Medieorganisationer söker över innehållsregister, arkiv, rättighetshanteringssystem och distributionsplattformar. Federerad sökning möjliggör omfattande innehållsupptäckt och bevarar ägande och licensrestriktioner.
Utmaningar & begränsningar
Källheterogenitet och integrationskomplexitet: Att integrera olika datakällor med olika scheman, frågespråk och åtkomstprotokoll kräver stort ingenjörsarbete. Schemakartläggning och semantisk anpassning är särskilt utmanande när samma begrepp representeras olika mellan källor.
Söklatens och prestanda: Federerad sökning innebär per definition att flera källor frågas, vilket ökar latensen jämfört med centraliserade system. Långsamma eller oresponsiva källor kan försämra den totala prestandan. Timeout-hantering måste finjusteras för att balansera mellan fullständighet och snabbhet.
Källtillförlitlighet och tillgänglighet: Federerade system är beroende av att externa källor är tillgängliga och svarar snabbt. Nätverksfel, källornas driftstopp eller prestandaförsämring påverkar direkt sökkvaliteten. Graciös degradering krävs när källor fallerar.
Resultatkvalitet och rankningsnoggrannhet: Att aggregera resultat från källor med olika kvalitet, täckning och relevanskriterier är utmanande. Rankningsmodeller måste ta hänsyn till variationer i källtrovärdighet och undvika bias mot vissa källor.
Dataaktualitet och konsistens: Federerade system hämtar aktuell data från källorna, men dessa kan ha olika uppdateringsfrekvens och konsistensgarantier. Att försona motsägande information kräver avancerad konfliktlösning.
Skalbarhetsbegränsningar: När antalet källor ökar växer koordineringskostnaden. Att välja relevanta källor bland tusentals möjliga blir beräkningsmässigt dyrt. Parallell exekvering över många källor kräver robust infrastruktur.
Säkerhet och åtkomstkontroll: Federerade system måste upprätthålla åtkomstkontroller på källnivå samtidigt som de erbjuder enhetliga sökgränssnitt. Att säkerställa att användare bara ser information de är behöriga för är komplext, särskilt i multihyresmiljöer.
Integritet och dataskydd: Federerad sökning måste följa integritetsregler som GDPR, CCPA och branschspecifika krav. Systemet måste utformas så att känsliga data inte exponeras via resultataggregering eller metadataanalys.
Källdetektering och hantering: Att identifiera och katalogisera tillgängliga källor, upprätthålla korrekt metadata och hantera källors livscykel (tillägg, borttagning, uppdateringar) kräver fortlöpande operativt arbete.
Semantisk interoperabilitet: Att uppnå full semantisk interoperabilitet mellan källor med olika ontologier och datamodeller är fortfarande svårt. Automatiska schemakartläggnings- och entitetsupplösningstekniker har begränsningar.
Koordineringskostnad: Medan federerad sökning eliminerar kostnader för datakonsolidering tillkommer samordningskostnader för distribuerad exekvering, felhantering och optimering av frågoroutning.
Begränsad standardisering: Brist på universella standarder för federerade sökprotokoll och gränssnitt försvårar systemintegration och ökar risken för leverantörsinlåsning.
Federerad AI-sökning jämfört med närliggande teknologier
Federerad AI-sökning vs. datalagring: Datalagring konsoliderar data från flera källor till ett centraliserat lager för snabba sökningar men kräver omfattande ETL och medför datalatens. Federerad sökning frågar källorna direkt och ger realtidsåtkomst men med högre latens. Lagring passar historisk analys och rapportering, medan federerad sökning excellerar för aktuell informationsupptäckt.
Federerad AI-sökning vs. datasjöar: Datasjöar lagrar rådata från flera källor i en central plats med minimal bearbetning. De är flexibla men kräver mycket lagring och styrning. Federerad sökning undviker datakonsolidering helt, bevarar källornas självständighet men kräver mer avancerad frågehantering.
Federerad AI-sökning vs. API:er och mikrotjänster: API:er ger programmatisk åtkomst till enskilda tjänster men kräver detaljerad kunskap om varje tjänst. Federerad sökning abstraherar bort källspecifika detaljer och möjliggör enhetliga sökningar över tjänster. API:er passar för applikationsintegration, medan federerad sökning möjliggör informationsupptäckt mellan tjänster.
Federerad AI-sökning vs. kunskapsgrafer: Kunskapsgrafer representerar information som sammankopplade entiteter och relationer och möjliggör semantisk resonemang. Federerad sökning kan fråga distribuerade kunskapsgrafer men kräver inte centraliserad grafkonstruktion. Kunskapsgrafer ger djupare semantisk förståelse, medan federerad sökning betonar källautonomi.
Federerad AI-sökning vs. sökmotorer: Traditionella sökmotorer bygger centraliserade index över genomsökt innehåll. Federerad sökning frågar källor direkt utan förindexering. Sökmotorer ger omfattande täckning av offentligt innehåll, medan federerad sökning excellerar vid integrering av privata, proprietära eller specialiserade källor.
Federerad AI-sökning vs. master data management (MDM): MDM-system skapar auktoritativa masterposter genom att konsolidera data från flera källor. Federerad sökning frågar källor oberoende utan att skapa masterposter. MDM passar datastyrning och konsistens, medan federerad sökning betonar källautonomi och realtidsåtkomst.
Federerad AI-sökning vs. företagssökning: Företagssökning indexerar vanligtvis interna dokument och databaser i ett centraliserat index. Federerad sökning frågar källor direkt utan central indexering. Företagssökning erbjuder snabba fritextsökningar, medan federerad sökning stödjer olika källtyper och realtidsuppdateringar.
Federerad AI-sökning vs. blockchain och distribuerade liggare: Blockchainsystem upprätthåller distribuerad konsensus mellan noder och säkerställer dataintegritet och oföränderlighet. Federerad sökning samordnar sökningar mellan oberoende källor utan konsensuskrav. Blockchain används för förtroende och verifiering, federerad sökning för informationsupptäckt.
Bästa praxis för implementation
Omfattande källbedömning: Gör en noggrann bedömning av källornas egenskaper, såsom datakvalitet, uppdateringsfrekvens, tillgänglighetsmönster, schemakomplexitet och åtkomstprotokoll innan integration. Detta informerar källvalsaloritmer och sätter realistiska prestandaförväntningar.
Stegvis integration: Börja med ett fåtal välkända källor och expandera gradvis. Detta ger tid att bygga kompetens, identifiera integrationsutmaningar och förbättra processer innan skalning.
Robust metadatahantering: Satsa på omfattande metadata om källor, inklusive schemainformation, täckning, kvalitetsmått och prestanda. Upprätthåll metadata med automatiserad övervakning och regelbunden validering.
Intelligent källval: Implementera maskininlärningsbaserat källval som lär sig av sökresultat. Följ vilka källor som ger relevanta resultat för olika frågetyper och optimera källvalet kontinuerligt.
Adaptiv timeout-hantering: Använd adaptiva timeouts som justeras efter källans svarsmönster och systembelastning. Undvik fasta timeouts som antingen väntar för länge eller ger upp för tidigt.
Säkrad resultatkvalitet: Etablera kvalitetsmått för resultat, inklusive relevans, aktualitet och fullständighet. Inför feedbacksystem där användare kan betygsätta resultatkvaliteten,
Vanliga frågor
Vad är den största skillnaden mellan federerad AI-sökning och traditionell centraliserad sökning?
Traditionell centraliserad sökning konsoliderar all data till ett enda indexerat lager, vilket kräver datamigrering och introducerar latens. Federerad AI-sökning söker direkt i flera oberoende källor i realtid utan att flytta eller duplicera data, vilket bevarar källornas självständighet och ger enhetlig åtkomst. Detta gör federerad sökning idealisk för organisationer med distribuerade datakällor och strikta krav på datastyrning.
Hur upprätthåller federerad AI-sökning säkerhet och efterlevnad?
Federerad AI-sökning behåller data på dess ursprungliga plats och respekterar varje källas åtkomstkontroller och säkerhetspolicyer. Användare får endast åtkomst till information de är behöriga att se, och känslig data lämnar aldrig sitt ursprungssystem. Detta förenklar efterlevnaden av regleringar som GDPR och HIPAA genom att eliminera riskerna som är förknippade med centralisering av känslig information.
Vilka är de största utmaningarna med att implementera federerad AI-sökning?
Viktiga utmaningar inkluderar hantering av heterogena datakällor med olika scheman och format, hantering av söklatens från flera källor, säkerställande av konsekvent resultatrankning mellan källor och bibehållande av systemets tillförlitlighet när källor är otillgängliga. Organisationer måste också investera i robust metadatahantering och intelligenta algoritmer för källval för att optimera prestandan.
Kan federerad AI-sökning skalas när antalet datakällor ökar?
Ja, federerad AI-sökning kan skalas genom att lägga till nya källor utan att kräva datamigrering eller omstrukturering av datalager. Men när antalet källor ökar växer koordineringskostnaden för sökningar. Moderna system använder maskininlärning för intelligent källval och implementerar cache-strategier för att upprätthålla prestanda i stor skala.
Hur skiljer sig federerad AI-sökning från datalagring (data warehousing)?
Datalagring konsoliderar data i ett centraliserat lager, vilket möjliggör snabba sökningar men kräver betydande ETL-arbete och introducerar datalatens. Federerad sökning söker direkt i källorna och ger realtidsåtkomst men med högre söklatens. Lagring passar historisk analys och rapportering, medan federerad sökning är bäst för aktuell informationsupptäckt över distribuerade källor.
Vilka branscher har mest nytta av federerad AI-sökning?
Hälso- och sjukvård, finans, e-handel, offentlig sektor och forskningsorganisationer har stor nytta av federerad sökning. Sjukvården använder det för att integrera patientjournaler över vårdgivare, finans använder det för efterlevnad och riskbedömning, e-handel använder det för enhetlig produktupptäckt och forskningsorganisationer använder det för att söka i distribuerade akademiska databaser.
Hur förbättrar AI federerade sökfunktioner?
AI förbättrar federerad sökning genom naturlig språkbehandling för förståelse av frågor, maskininlärning för intelligent källval, semantisk analys för bättre rankning av resultat och automatisk deduplicering. AI-modeller lär sig av sökbeteenden för att kontinuerligt optimera källval och resultatsammanslagning, vilket förbättrar systemets prestanda över tid.
Vilken roll spelar semantisk förståelse i federerad AI-sökning?
Semantisk förståelse gör det möjligt för federerade system att förstå frågeintentioner bortom nyckelords-matchning, identifiera relevanta källor mer exakt och ranka resultat efter betydelse snarare än bara nyckelordsöverensstämmelse. Detta inkluderar entitetsigenkänning, relationsutvinning och integration av kunskapsgrafer, vilket ger mer relevanta och kontextuellt lämpliga sökresultat.
Övervaka hur AI refererar till ditt varumärke
AmICited spårar hur AI-system som ChatGPT, Perplexity och Google AI Overviews citerar och refererar till ditt varumärke. Förstå din AI-synlighet och optimera din närvaro i AI-genererade svar.
Hur företagsorganisationer närmar sig AI-sökning: Strategi och implementering
Strategi för företags-AI-sökning: integration, styrning, ROI-mått. Lär dig hur stora organisationer implementerar AI-sökningsplattformar för ChatGPT, Perplexity...
Lär dig hur Query Fanout fungerar i AI-söksystem. Upptäck hur AI utökar enskilda frågor till flera underfrågor för att förbättra svarens noggrannhet och förståe...
Läser AI-crawlers strukturerad data? Komplett guide till AI-synlighet i sök
Lär dig hur AI-crawlers bearbetar strukturerad data. Upptäck varför JSON-LD-implementeringen är avgörande för synlighet i ChatGPT, Perplexity, Claude och Google...
8 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.