
Förfining av sökfrågor
Förfining av sökfrågor är en iterativ process för att optimera sökfrågor för bättre resultat i AI-sökmotorer. Lär dig hur det fungerar i ChatGPT, Perplexity, Go...
14 min läsning
Förutseende av Frågor är den strategiska metoden att identifiera och skapa innehåll som besvarar uppföljande frågor som användare sannolikt kommer att ställa efter sin initiala sökfråga i AI-drivna söksystem. Denna metod är avgörande för AI-sök eftersom moderna språkmodeller inte bara besvarar den omedelbara frågan – de förutser vad användarna vill veta härnäst och visar proaktivt relevant innehåll.
Förutseende av Frågor är den strategiska metoden att identifiera och skapa innehåll som besvarar uppföljande frågor som användare sannolikt kommer att ställa efter sin initiala sökfråga i AI-drivna söksystem. Denna metod är avgörande för AI-sök eftersom moderna språkmodeller inte bara besvarar den omedelbara frågan – de förutser vad användarna vill veta härnäst och visar proaktivt relevant innehåll.
Förutseende av Frågor är den strategiska metoden att identifiera och skapa innehåll som besvarar uppföljande frågor som användare sannolikt kommer att ställa efter sin initiala sökfråga i AI-drivna söksystem. Till skillnad från traditionell SEO, som fokuserar på att matcha exakta nyckelord och ranka för specifika söktermer, kräver Förutseende av Frågor att innehållsskapare tänker flera steg framåt i användarens informationsresa. Denna metod är avgörande för AI-sök eftersom moderna språkmodeller inte bara besvarar den omedelbara frågan – de förutser vad användarna vill veta härnäst och visar proaktivt relevant innehåll. Genom att förstå och besvara dessa förväntade frågor kan innehållsskapare dramatiskt öka sin synlighet på AI-plattformar som ChatGPT, Claude, Perplexity och Googles AI Översikter. Förutseende av Frågor representerar ett grundläggande skifte från nyckelordscentrerat tänkande till konversationscentrerat tänkande, där målet är att bli en oumbärlig resurs genom hela användarens frågeprocess.
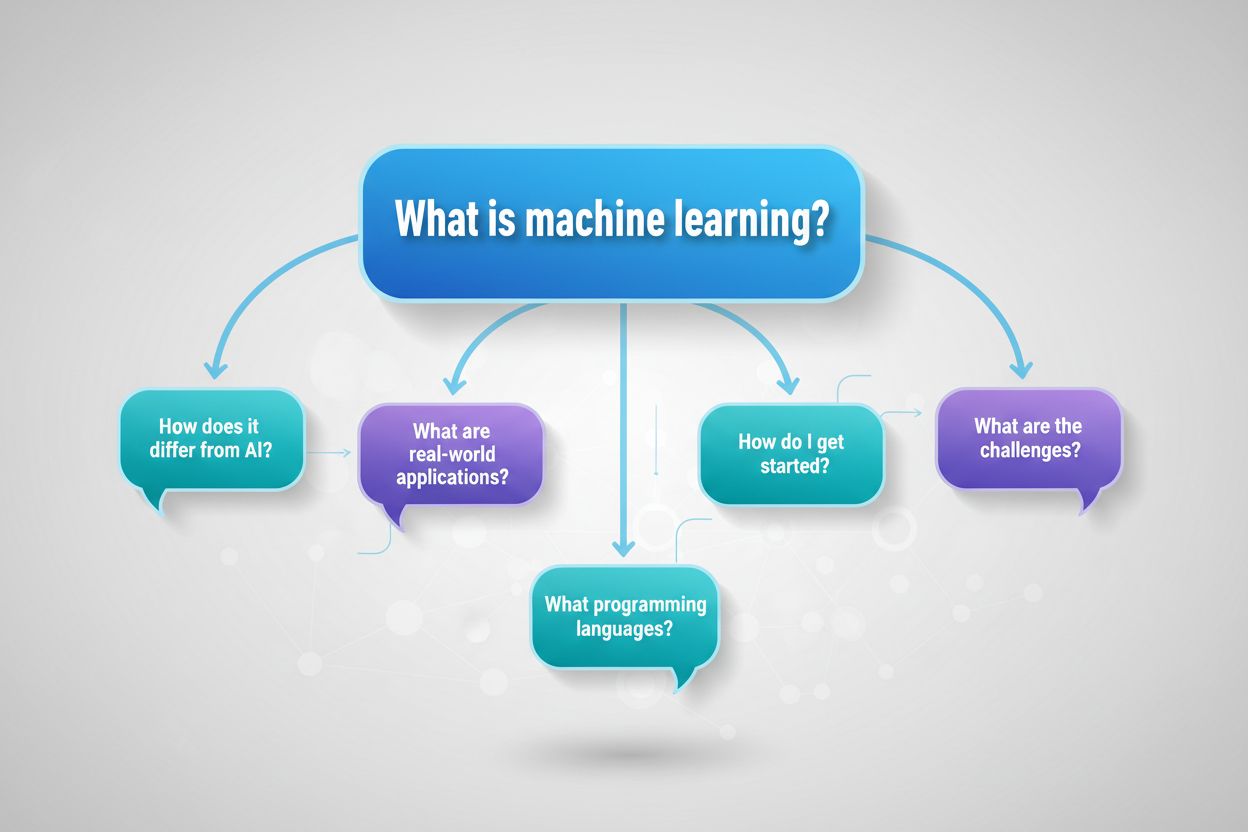
AI-system bearbetar användarfrågor genom en sofistikerad mekanism som kallas query fan-out, där en enskild användarfråga delas upp i flera relaterade underfrågor som AI:n utforskar för att ge ett heltäckande svar. När en användare ställer en initial fråga söker AI:n inte bara efter exakt den frasen – den genererar en serie förväntade uppföljande frågor och söker efter innehåll som besvarar både den ursprungliga frågan och dessa förutsedda nästa steg. Denna mekanik med konversationer i flera steg innebär att innehåll som besvarar sekundära och tertiära frågor kan visas även om användaren aldrig uttryckligen ställer dem. AI:n skapar i princip ett samtalsträd som förgrenar sig från huvudfrågan till relaterade ämnen, definitioner, jämförelser och praktiska tillämpningar. Här är ett exempel på hur detta fungerar:
| Huvudfråga | Förväntade Uppföljande Frågor |
|---|---|
| “Vad är maskininlärning?” | “Hur skiljer sig maskininlärning från AI?” “Vilka är verkliga tillämpningar av maskininlärning?” “Hur börjar jag lära mig maskininlärning?” “Vilka programmeringsspråk används i maskininlärning?” |
| “Bästa praxis för distansarbete” | “Hur förblir jag produktiv när jag jobbar hemifrån?” “Vilka verktyg använder distansteam?” “Hur upprätthåller jag balans mellan arbete och privatliv?” “Vilka är utmaningarna med distansarbete?” |
Genom att förstå denna fan-out-mekanism kan innehållsskapare strategiskt positionera sitt material för att fånga synlighet över flera förväntade frågegrenar.
Förutseende av Frågor är viktigt eftersom det direkt påverkar innehållets synlighet, citeringsfrekvens och användarengagemang på AI-söksplattformar – dagens snabbast växande sökkanal. Enligt färska data har användningen av AI-sök ökat med över 150 % år för år, med plattformar som ChatGPT, Perplexity och Claude som nu hanterar miljarder frågor varje månad. Innehåll som framgångsrikt besvarar förväntade frågor får citeringar oftare eftersom det upplevs relevant för flera frågegrenar inom AI:ns beslutsstruktur. När ditt innehåll citeras av AI-system bygger det auktoritet och förtroende, vilket leder till ökad synlighet inte bara i AI-sök utan även i traditionella sökresultat. Den sammanväxande effekten är betydande: innehåll som rankar bra för förväntade frågor genererar mer trafik, fler engagemangssignaler och fler möjligheter till bakåtlänkar och delningar i sociala medier, vilket skapar en positiv spiral av synlighet och auktoritet.
Att identifiera förväntade frågor kräver en kombination av forskningsmetoder och analytiskt tänkande kring användarbeteende och informationsbehov. De mest effektiva metoderna inkluderar att analysera sökfrågeloggar och autokompletteringsförslag för att se vad användare faktiskt söker efter efter sin initiala fråga, genomföra användarintervjuer och enkäter för att förstå vilka informationsluckor som finns, studera konkurrenters innehåll för att identifiera vilka uppföljande ämnen som tas upp, granska AI-chatttranskript och samtalshistorik för att se vilka frågor användare ställer i konversationer med flera steg, använda verktyg som Answer the Public och SEMrush för att visualisera frågekluster och relaterade frågor samt analysera din egen webbplatsanalys för att se vilka sidor användare besöker i följd. Här är de viktigaste metoderna för att upptäcka förväntade frågor:

Innehållsstrukturen för Förutseende av Frågor bör organiseras hierarkiskt, med ditt huvudämne som H1, primära förväntade frågor som H2-avsnitt och djupare uppföljande frågor som H3-underavsnitt. Denna struktur signalerar till AI-system att ditt innehåll omfattande behandlar inte bara huvudfrågan utan även de förväntade uppföljande frågorna som användare sannolikt kommer att ställa. Varje avsnitt bör vara tillräckligt självständigt för att kunna citeras separat men ändå bidra till den övergripande berättelsen. Här är ett exempel på hur du kan strukturera innehåll för Förutseende av Frågor:
# Huvudämne (H1)
Inledande stycke som besvarar huvudfrågan
## Förväntad Fråga 1 (H2)
Innehåll som besvarar den första uppföljande frågan
### Underfråga 1a (H3)
Djupare utforskning av ett relaterat begrepp
### Underfråga 1b (H3)
En annan vinkel på samma ämne
## Förväntad Fråga 2 (H2)
Innehåll som besvarar den andra uppföljande frågan
### Underfråga 2a (H3)
Praktisk tillämpning eller exempel
## Förväntad Fråga 3 (H2)
Innehåll som besvarar den tredje uppföljande frågan
Denna hierarkiska struktur gör det lätt för AI-system att förstå relationen mellan ditt huvudmaterial och förväntade uppföljande ämnen, vilket ökar sannolikheten för citering över flera frågegrenar.
Att implementera Förutseende av Frågor kräver ett systematiskt tillvägagångssätt som börjar med research och sträcker sig genom innehållsskapande, optimering och kontinuerlig förbättring. Istället för att skapa innehåll i isolering behöver du tänka på hela samtalsresan och säkerställa att ditt innehåll besvarar frågor i varje steg. Implementeringsprocessen bör vara metodisk och datadriven, där insikter från användarbeteende och AI-systemens mönster styr din innehållsstrategi. Här är ett steg-för-steg-upplägg för att implementera Förutseende av Frågor:
Att övervaka och mäta framgång med Förutseende av Frågor kräver att du spårar mätvärden som specifikt speglar AI-synlighet och citeringsmönster, vilka skiljer sig markant från traditionella SEO-mått. De viktigaste mätvärdena inkluderar citeringsfrekvens (hur ofta ditt innehåll citeras i AI-svar), citeringsbredd (hur många olika frågor ditt innehåll citeras för) och engagemangssignaler från AI-plattformar. AmICited.com är det ledande verktyget för att övervaka AI-synlighet och ger detaljerad insyn i vilka av dina innehållsdelar som citeras av stora AI-system, vilka frågor som triggar dina citat och hur din citeringsprestation står sig mot konkurrenter. Utöver AmICited.com bör du också övervaka din webbplatsanalys för trafik från AI-plattformar, spåra rankingar i traditionell sökning för dina förväntade frågor och analysera användarengagemang såsom tid på sidan och scroll-djup för att förstå vilka förväntade frågor som engagerar din publik mest. Genom att kombinera AI-specifika mätvärden med traditionell analys kan du skapa en heltäckande bild av din prestation inom Förutseende av Frågor och identifiera förbättringsmöjligheter.
Förutseende av Frågor representerar ett fundamentalt annorlunda tillvägagångssätt jämfört med traditionell SEO och kräver ett skifte i tankesätt från nyckelordsoptimering till konversationskartläggning. Medan traditionell SEO fokuserar på att ranka för specifika nyckelord och fånga sökvolym för enskilda frågor, fokuserar Förutseende av Frågor på att bli en heltäckande resurs som besvarar hela samtalsresan. De strategiska skillnaderna är betydande och kräver olika planering, innehållsskapande och optimeringsmetoder. Så här jämförs de:
| Aspekt | Traditionell SEO | Förutseende av Frågor |
|---|---|---|
| Fokus | Enskilda nyckelord och sökvolym | Samtalsträd och frågerelationer |
| Innehållsstrategi | Optimera för specifika nyckelord | Besvara huvudfråga och alla förväntade följdfrågor |
| Framgångsmått | Ranking och organisk trafik | AI-citat och samtalstäckning |
| Innehållsstruktur | Nyckelordsoptimerade sidor | Hierarkisk struktur som adresserar frågegrenar |
| Konkurrensfördel | Nyckelordstargeting och bakåtlänkar | Heltäckande täckning och samtalskartläggning |
Att förstå dessa skillnader är avgörande för att utveckla en effektiv strategi för Förutseende av Frågor som kompletterar snarare än ersätter dina traditionella SEO-insatser.
Vanliga misstag vid implementering av Förutseende av Frågor kan allvarligt undergräva dina insatser och slösa resurser på ineffektiva innehållsstrategier. Ett stort misstag är att förutse frågor som användare faktiskt inte ställer – att lägga tid på att skapa innehåll för hypotetiska uppföljningar istället för att forska om vad användarna verkligen vill veta. Ett annat misstag är att skapa tunt, ytligt innehåll som besvarar förväntade frågor utan tillräckligt djup; AI-system föredrar omfattande, auktoritativt innehåll som utforskar varje ämne grundligt. Många innehållsskapare misslyckas också med att uppdatera sitt innehåll när nya förväntade frågor dyker upp eller användarbeteendet förändras, vilket leder till föråldrat material som inte speglar aktuella informationsbehov. Dessutom gör vissa misstaget att överoptimera för AI-system på bekostnad av mänsklig läsbarhet och skapar klumpigt, onaturligt innehåll som inte engagerar riktiga läsare. Bästa praxis inkluderar att genomföra grundlig användarforskning innan innehållet skapas, säkerställa att varje förväntad fråga besvaras med tillräckligt djup och detaljer, regelbundet övervaka och uppdatera ditt innehåll baserat på prestandadata, bibehålla naturligt, läsbart språk som tjänar både människor och AI-system och att fokusera på verkliga användarbehov istället för spekulativa frågor.
Framtiden för Förutseende av Frågor kommer att utvecklas i takt med att AI-söksystem blir mer sofistikerade och användarbeteendet fortsätter att skifta mot konversationella gränssnitt. Framväxande trender inkluderar AI-system som kan förutse användaravsikt med högre noggrannhet, vilket leder till ännu mer komplexa fan-out-mönster för frågor som innehållsskapare måste förutse. Vi ser också ökningen av multimodala AI-sökningar som kombinerar text, bilder, video och andra innehållstyper, vilket kräver strategier för Förutseende av Frågor som sträcker sig bortom skrivet innehåll. I takt med att AI-systemen blir mer personliga kommer Förutseende av Frågor att behöva ta hänsyn till individuella användarpreferenser och kontext, vilket går bortom enhetsstorlek för förväntade frågor. Konkurrensen kommer att hårdna i takt med att fler innehållsskapare tillämpar strategier för Förutseende av Frågor, vilket gör det allt viktigare att inte bara besvara förväntade frågor utan att göra det med överlägsen djup, noggrannhet och användarvärde. Organisationer som bemästrar Förutseende av Frågor nu kommer att ha en betydande fördel när AI-sök fortsätter att växa och bli det främsta sättet användare upptäcker information online.
Traditionell nyckelordsforskning fokuserar på att identifiera enskilda söktermer och optimera innehåll för dessa specifika fraser. Förutseende av Frågor, däremot, kartlägger hela samtalsträd – identifierar inte bara huvudfrågan utan alla uppföljande frågor som användare sannolikt kommer att ställa. Detta kräver att man tänker på användarens avsikt över flera steg i informationsresan istället för att optimera för isolerade nyckelord.
Du kan identifiera förväntade frågor genom flera metoder: analysera sökfrågeloggar och autokompletteringsförslag, genomföra användarintervjuer och enkäter, studera konkurrenters innehåll, granska AI-chatttranskript, använda verktyg som Answer the Public och SEMrush, samt analysera din egen webbplatsanalys för att se vilka sidor användarna besöker i följd. Nyckeln är att kombinera flera forskningsmetoder för att få en heltäckande bild av användarnas informationsbehov.
Ja, avsevärt. Innehåll som framgångsrikt tar upp förväntade frågor får citeringar oftare eftersom det upplevs relevant för flera frågegrenar inom AI:ns beslutsstruktur. När ditt innehåll citeras av AI-system bygger det auktoritet och förtroende, vilket leder till ökad synlighet inte bara i AI-sök utan även i traditionella sökresultat och skapar en sammanväxande effekt av synlighet och auktoritet.
Använd en hierarkisk struktur med ditt huvudämne som H1, primära förväntade frågor som H2-avsnitt och djupare uppföljande frågor som H3-underavsnitt. Denna struktur signalerar till AI-system att ditt innehåll täcker inte bara huvudfrågan utan även förväntade uppföljande frågor. Varje avsnitt bör vara tillräckligt självständigt för att kunna citeras separat men ändå bidra till den övergripande berättelsen.
Spåra mätvärden som är specifika för AI-synlighet, inklusive citeringsfrekvens (hur ofta ditt innehåll citeras), citeringsbredd (hur många olika frågor ditt innehåll citeras för) och engagemangssignaler från AI-plattformar. Verktyg som AmICited.com ger detaljerad insyn i vilka innehållsdelar som citeras, vilka frågor som triggar dina citat och hur din prestation jämför sig med konkurrenter. Kombinera dessa med traditionell analys för att få en helhetsbild.
Förutseende av Frågor är mest värdefullt för omfattande, informationsrikt innehåll som naturligt leder till uppföljande frågor – såsom guider, handledningar, instruktionsartiklar och utbildande material. Det är mindre kritiskt för transaktionellt innehåll som produktsidor eller enkla faktatexter. Men även produktsidor kan dra nytta av att förutse frågor om specifikationer, jämförelser och användningsområden.
Förutseende av Frågor handlar i grunden om att förbereda ditt innehåll för konversationella AI-system som engagerar sig i interaktioner med flera steg. Dessa system svarar inte bara på en fråga och slutar – de förutser vad användarna vill veta härnäst och visar relevant innehåll proaktivt. Genom att förstå hur konversationell AI fungerar kan du strukturera ditt innehåll för att passa dessa systems förväntningar och öka din synlighet.
Flera verktyg kan stödja din strategi för Förutseende av Frågor: Answer the Public för frågeanalys, Google Trends för att identifiera trendande relaterade frågor, SEMrush och Ahrefs för konkurrensanalys, Reddit och Quora för att hitta verkliga användarfrågor, Google Search Console för att förstå användarnas sökbeteende och AmICited.com för att övervaka hur ditt innehåll presterar i AI-sök över flera plattformar.
Spåra hur ditt innehåll citeras i ChatGPT, Perplexity, Google AI Översikter och andra AI-plattformar. Förstå vilka frågor som utlöser dina citat och optimera din strategi för Förutseende av Frågor med verkliga data.
Förfining av sökfrågor är en iterativ process för att optimera sökfrågor för bättre resultat i AI-sökmotorer. Lär dig hur det fungerar i ChatGPT, Perplexity, Go...

Upptäck de bästa verktygen för att hitta AI-sökämnen, nyckelord och frågor som folk ställer i AI-sökmotorer som ChatGPT, Perplexity och Claude. Lär dig vilka ve...
Lär dig om AI-frågemönster – återkommande strukturer och formuleringar som användare använder när de ställer frågor till AI-assistenter. Upptäck hur dessa mönst...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.