
阻止(或允许)AI爬虫的完整指南
了解如何通过robots.txt、服务器级拦截和高级防护方法阻止或允许GPTBot、ClaudeBot等AI爬虫。完整的技术指南,附有示例。
1 分钟阅读

有策略地选择性允许或阻止AI爬虫,以控制内容用于训练还是实时检索。这涉及使用robots.txt文件、服务器级控制和监控工具,管理哪些AI系统可以访问您的内容及其用途。
有策略地选择性允许或阻止AI爬虫,以控制内容用于训练还是实时检索。这涉及使用robots.txt文件、服务器级控制和监控工具,管理哪些AI系统可以访问您的内容及其用途。
AI爬虫管理指的是控制和监控人工智能系统如何访问和使用网站内容用于训练和搜索的实践。与传统搜索引擎爬虫为网页搜索结果建立索引不同,AI爬虫专为收集数据以训练大型语言模型或驱动AI搜索功能而设计。不同机构的此类活动规模差异巨大——OpenAI的爬虫爬取与引用比例为1,700:1,即每提供一次引用会访问内容1,700次,而Anthropic的比例高达73,000:1,凸显了现代AI系统训练所需的数据消耗之巨。有效的爬虫管理可让网站所有者决定其内容是否用于AI训练、是否出现在AI搜索结果中,或是否得到自动化访问保护。
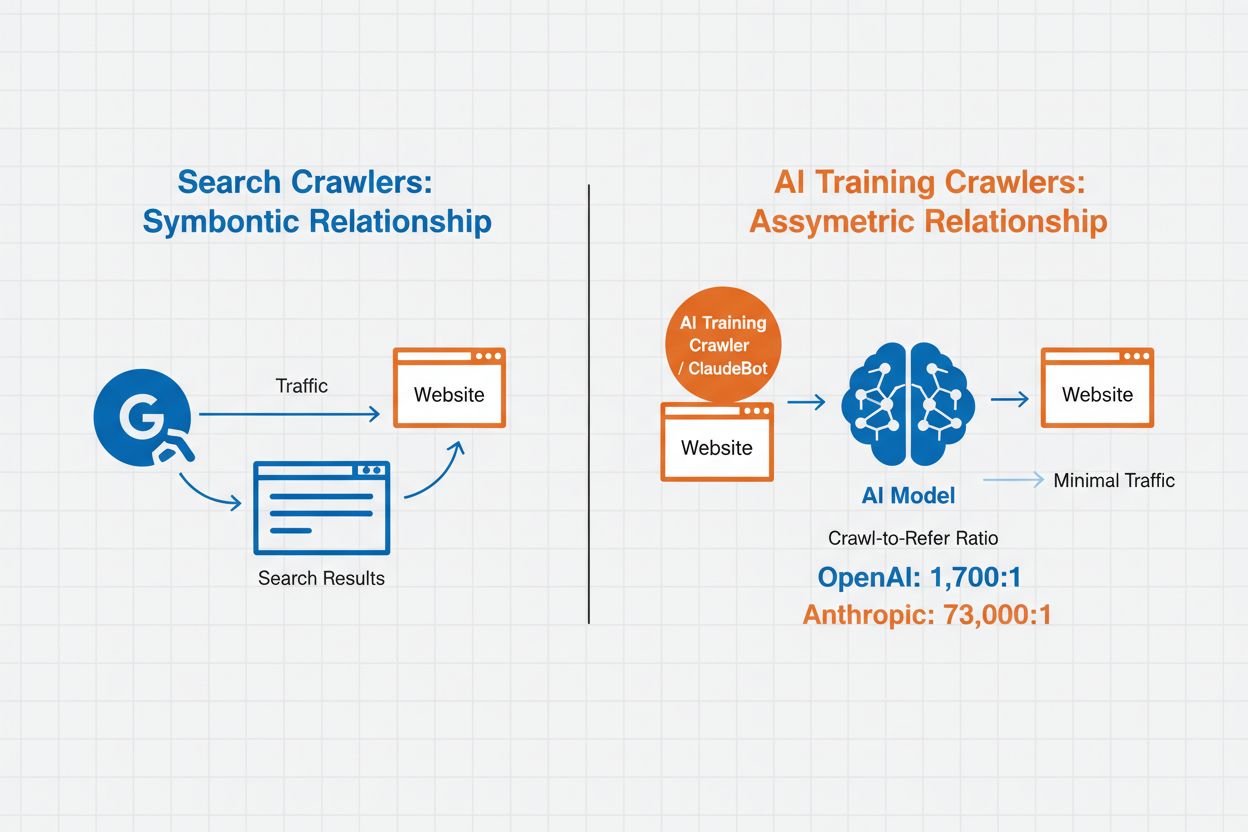
AI爬虫根据其目的和数据使用模式分为三大类。训练爬虫用于收集数据以开发机器学习模型,需要消耗大量内容以提升AI能力。搜索与引用爬虫为AI驱动的搜索功能建立内容索引,并在AI回答中提供出处,使用户可通过AI界面发现您的内容。用户触发型爬虫则在用户与AI工具互动时按需运行,例如ChatGPT用户上传文档或请求分析特定网页时。了解这些分类有助于您根据内容策略和业务目标,明智决定允许或阻止哪些爬虫。
| 爬虫类型 | 目的 | 例子 | 是否用于训练数据 |
|---|---|---|---|
| 训练 | 模型开发与改进 | GPTBot, ClaudeBot | 是 |
| 搜索/引用 | AI搜索结果与出处引用 | Google-Extended, OAI-SearchBot, PerplexityBot | 视情况而定 |
| 用户触发 | 按需内容分析 | ChatGPT-User, Meta-ExternalAgent, Amazonbot | 与上下文相关 |
AI爬虫管理直接影响您网站的流量、收入和内容价值。当爬虫无偿消耗您的内容时,您失去了通过推荐、广告展示或用户互动获益的机会。许多网站报告称,随着用户直接在AI生成的回答中找到答案,而非点击原始来源,流量显著下降,从而失去推荐流量和相关广告收入。除了经济影响外,还存在重要的法律和伦理考量——您的内容属于知识产权,您有权控制其用法及是否获得署名或补偿。此外,放任爬虫访问还可能增加服务器负载和带宽成本,尤其是那些不遵守限速指令、抓取频率极高的爬虫。
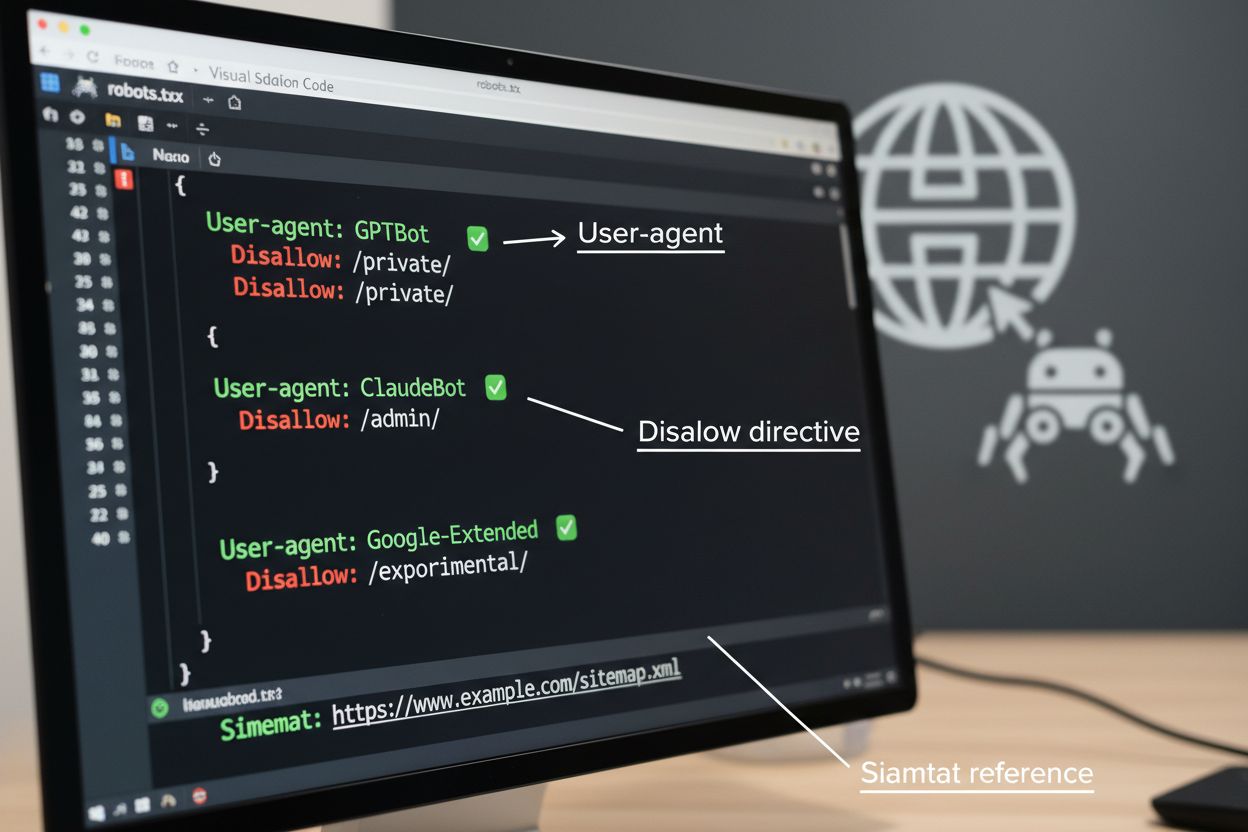
robots.txt文件是管理爬虫访问的基础工具,需放置在网站根目录,用于告知自动化代理爬取偏好。该文件通过User-agent指令针对特定爬虫,并用Disallow或Allow规则允许或限制对特定路径和资源的访问。但robots.txt有重要局限——它是一项自愿标准,依赖爬虫自觉遵守,恶意或设计不良的爬虫可能完全忽视。此外,robots.txt无法阻止爬虫访问公开内容,只是请求其尊重您的偏好。因此,robots.txt应作为分层爬虫管理的一部分,而非唯一防线。
# 阻止AI训练爬虫
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# 允许搜索引擎
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# 其他爬虫的默认规则
User-agent: *
Allow: /
除了robots.txt,多个高级技术可提供更强的执行力和更细粒度的爬虫访问控制。这些方法作用于基础设施的不同层,可组合以实现全面保护:
是否阻止AI爬虫涉及内容保护与可见性间的重要权衡。全面阻止所有AI爬虫,会让您的内容无法出现在AI搜索结果、AI摘要或被AI工具引用中,可能降低在新兴渠道中的可见度。反之,完全开放访问则意味着您的内容无偿为AI训练所用,并可能因用户直接从AI获取答案而减少推荐流量。战略建议采取选择性阻止:允许如OAI-SearchBot和PerplexityBot等能带来推荐流量的引用型爬虫,同时阻止如GPTBot和ClaudeBot等不署名的数据消耗型训练爬虫。您也可以考虑允许Google-Extended,以保持在Google AI Overviews中的可见度(该渠道可带来大量流量),同时阻止竞争对手的训练爬虫。最优策略取决于您的内容类型、商业模式和受众——新闻与出版机构或许更倾向于阻止,而教育内容创作者可能更适合争取AI渠道的广泛可见性。
仅有爬虫控制措施还不够,必须验证爬虫是否真正遵守您的指令。服务器日志分析是监控爬虫活动的主要方法——检查访问日志中的User-Agent字符串和请求模式,识别哪些爬虫正在访问您的网站,以及是否遵守robots.txt规则。许多爬虫声称合规却仍访问被阻止路径,因此持续监控至关重要。像Cloudflare Radar这样的工具可实时展示流量模式,帮助识别可疑或不合规的爬虫行为。可为访问受阻资源的尝试设置自动警报,并定期审计日志,捕捉新爬虫或可能表明规避行为的变化。
要实施有效的AI爬虫管理,需采取系统化方法,在保护与战略可见性之间找到平衡。请依照以下八步建立全面的爬虫管理策略:
AmICited.com提供专业平台,帮助您监控AI系统在不同模型和应用中如何引用和使用您的内容。该服务可实时追踪AI生成回答中的您的内容引用,助您了解哪些爬虫最频繁地使用您的内容,以及您的作品在AI输出中的出现频率。通过分析爬虫模式和引用数据,AmICited.com让您的爬虫管理策略建立在数据基础之上——您可清晰看到哪些爬虫通过引用和推荐带来价值,哪些则仅消耗内容未署名。这些情报让爬虫管理从被动防御转变为优化内容在AI网络中可见性和影响力的战略工具。
训练爬虫如GPTBot和ClaudeBot收集内容以建立大语言模型的数据集,会消耗您的内容但不会带来推荐流量。搜索爬虫如OAI-SearchBot和PerplexityBot会为AI驱动的搜索结果建立索引,并可能通过引用将访问者带回您的网站。阻止训练爬虫可保护您的内容不被纳入AI模型,而阻止搜索爬虫可能会降低您在AI发现平台上的可见度。
不会。阻止如GPTBot、ClaudeBot和CCBot等AI训练爬虫不会影响您的Google或Bing搜索排名。传统搜索引擎使用不同的爬虫(如Googlebot、Bingbot),它们与AI训练爬虫独立运作。只有当您想完全从搜索结果中消失时才应阻止传统搜索爬虫,否则会损害SEO。
检查您的服务器访问日志,识别爬虫的User-Agent字符串。查找User-Agent字段中包含'bot'、'crawler'或'spider'的条目。像Cloudflare Radar这样的工具可实时显示哪些AI爬虫正在访问您的网站及其流量模式。您还可以使用能区分爬虫流量和真实访客的分析平台。
会。robots.txt是一种依赖爬虫自觉遵守的建议标准——无法强制执行。像OpenAI、Anthropic和Google等大公司的正规爬虫一般会遵守robots.txt指令,但有些爬虫会完全忽略。为更强的保护,可通过.htaccess、防火墙规则或基于IP的限制实现服务器级阻止。
这取决于您的业务优先级。阻止所有训练爬虫可以防止您的内容被纳入AI模型,同时可以允许可能带来推荐流量的搜索爬虫。许多出版商采用选择性阻止策略,只针对训练爬虫,而允许搜索和引用爬虫。决策时请考虑您的内容类型、流量来源和变现模式。
至少每季度审查并更新您的爬虫管理策略。新的AI爬虫不断出现,现有爬虫也可能在未通知的情况下更新其User-Agent。关注GitHub上的ai.robots.txt等社区维护清单,并每月检查服务器日志,识别新爬虫访问您的网站。
AI爬虫可能对您的流量和收入产生重大影响。当用户直接从AI系统获取答案而不是访问您的网站时,您会失去推荐流量和相关广告展示。研究显示,某些AI平台的爬取与推荐比例高达73,000:1,即每带回一名访客会爬取您的内容数千次。阻止训练爬虫可保护您的流量,而允许搜索爬虫可能带来一定推荐效益。
检查您的服务器日志,看被阻止的爬虫是否仍然出现在访问日志中。使用如Google Search Console的robots.txt测试工具或Merkle的Robots.txt Tester验证您的配置。直接访问yoursite.com/robots.txt以确认内容是否正确。定期监控日志,捕捉应被阻止但仍出现的爬虫。
了解如何通过robots.txt、服务器级拦截和高级防护方法阻止或允许GPTBot、ClaudeBot等AI爬虫。完整的技术指南,附有示例。

了解如何使用robots.txt控制哪些AI机器人访问您的内容。完整指南,涵盖如何屏蔽GPTBot、ClaudeBot及其他AI爬虫的实用案例与配置策略。...

了解如何在服务器日志中识别并监控GPTBot、PerplexityBot和ClaudeBot等AI爬虫。发现User-Agent字符串、IP验证方法以及跟踪AI流量的最佳实践。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.