Zjistěte, jak Retrieval-Augmented Generation mění AI citace, umožňuje přesné přiřazení zdrojů a zakotvené odpovědi napříč ChatGPT, Perplexity a Google AI Overviews.
Publikováno dne Jan 3, 2026.Naposledy upraveno dne Jan 3, 2026 v 3:24 am
Velké jazykové modely znamenaly revoluci v AI, ale mají zásadní slabinu: omezení znalostí. Tyto modely jsou trénovány na datech do určitého okamžiku, takže nemají přístup k informacím po tomto datu. Kromě zastaralosti trpí tradiční LLM také halucinacemi—sebedůvěrně generují nepravdivé informace, které znějí přesvědčivě—a neposkytují žádné přiřazení zdrojů ke svým tvrzením. Pokud firma potřebuje aktuální tržní data, proprietární výzkum nebo ověřitelná fakta, tradiční LLM selhávají a uživatelé dostávají odpovědi, kterým nemohou věřit ani je ověřit.
Co je RAG – základní definice a komponenty
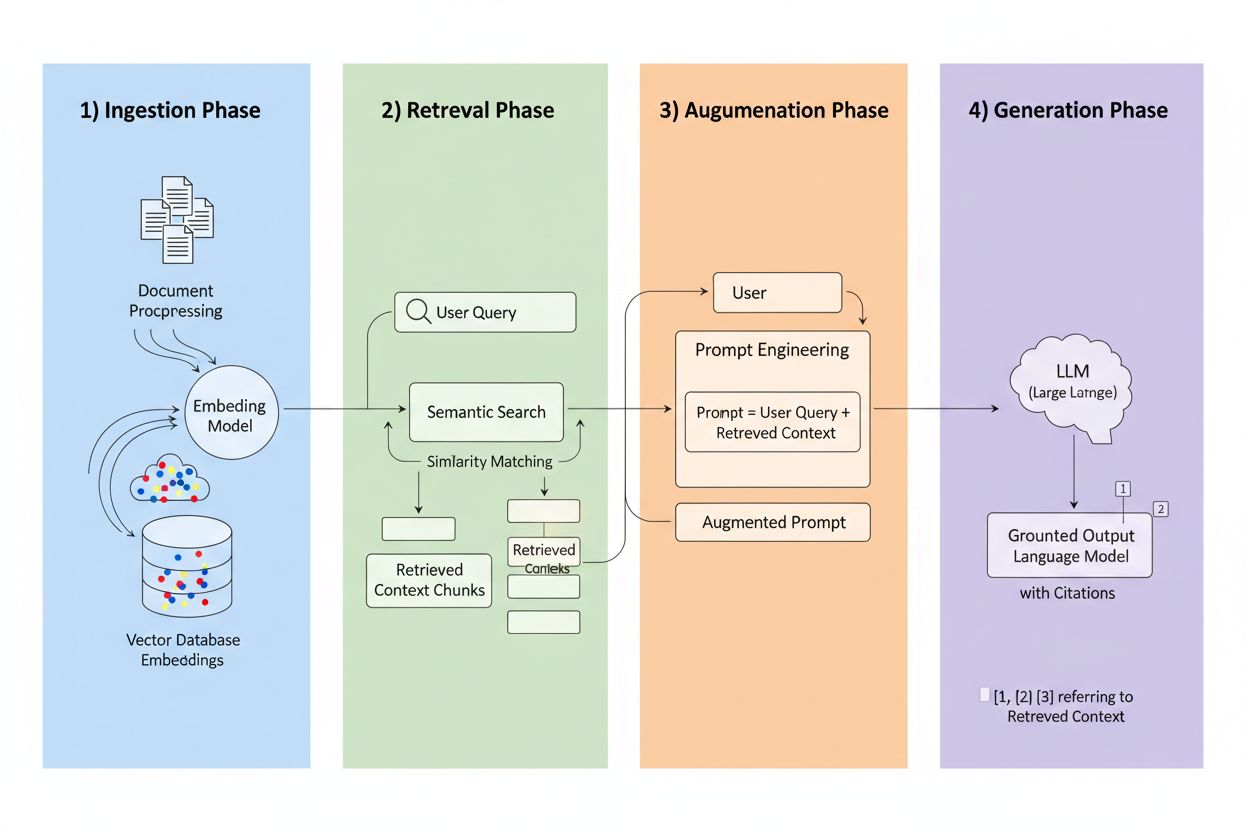
Retrieval-Augmented Generation (RAG) je rámec, který kombinuje generativní sílu LLM s přesností systémů pro vyhledávání informací. Místo spoléhání se pouze na tréninková data RAG získává relevantní informace z externích zdrojů před vygenerováním odpovědi, čímž vytváří proces, který zakotvuje odpovědi v reálných datech. Čtyři základní komponenty spolupracují: Ingestion (převod dokumentů do vyhledávatelných formátů), Retrieval (nalezení nejrelevantnějších zdrojů), Augmentation (obohacení promptu získaným kontextem) a Generation (vytvoření finální odpovědi s citacemi). Takto se RAG liší od tradičních přístupů:
Aspekt
Tradiční LLM
RAG systém
Zdroj znalostí
Statická tréninková data
Externí indexované zdroje
Schopnost citace
Žádná/halucinovaná
Sledovatelná ke zdrojům
Přesnost
Náchylný k chybám
Zakotvený ve faktech
Data v reálném čase
Ne
Ano
Riziko halucinací
Vysoké
Nízké
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Jak funguje RAG Retrieval – technický detailní pohled
Retrieval engine je srdcem RAG a je mnohem sofistikovanější než jednoduché porovnávání klíčových slov. Dokumenty jsou převáděny na vektorové embeddingy—matematická zobrazení zachycující sémantický význam—což systému umožňuje nalézt konceptuálně podobný obsah, i když se přesná slova neshodují. Systém rozděluje dokumenty na zvládnutelné části, obvykle 256–1024 tokenů, čímž vyvažuje zachování kontextu a přesnost vyhledávání. Nejmodernější RAG systémy využívají hybridní vyhledávání, které kombinuje sémantickou podobnost s tradičním porovnáváním klíčových slov, aby zachytily jak konceptuální, tak přesné shody. Reranking mechanismus následně skóruje kandidáty, často pomocí cross-encoder modelů hodnotících relevanci přesněji než počáteční vyhledávání. Relevance se počítá podle více signálů: skóre sémantické podobnosti, překryvu klíčových slov, shody v metadatech a autority domény. Celý tento proces probíhá v milisekundách, takže uživatelé dostávají rychlé a přesné odpovědi bez znatelné prodlevy.
Výhoda citací
Tady RAG mění svět citací: když systém získá informaci z konkrétního indexovaného zdroje, tento zdroj je dohledatelný a ověřitelný. Každý úryvek textu lze navázat zpět na jeho původní dokument, URL nebo publikaci, takže citace jsou automatické a ne halucinované. Tento zásadní posun přináší bezprecedentní transparentnost rozhodování AI—uživatelé přesně vidí, které zdroje ovlivnily odpověď, mohou si tvrzení sami ověřit a sami posoudit důvěryhodnost zdroje. Oproti tradičním LLM, kde jsou citace často vymyšlené nebo obecné, jsou citace RAG zakotvené ve skutečných retrieval událostech. Tato dohledatelnost dramaticky zvyšuje důvěru uživatelů, protože si mohou informace ověřit, místo aby jim museli věřit jen na základě důvěry. Pro tvůrce a vydavatele obsahu to znamená, že jejich práce může být objevena a uznána skrze AI systémy, což otevírá zcela nové kanály viditelnosti.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Faktory kvality citací v RAG systémech
Ne všechny zdroje jsou si v RAG systémech rovny a několik faktorů určuje, který obsah je citován nejčastěji:
Autorita: Reputace domény, profil zpětných odkazů a přítomnost v znalostních grafech signalizují důvěryhodnost retrieval algoritmům
Aktuálnost: Obsah aktualizovaný v cyklu 48–72 hodin je výše hodnocený, protože čerstvost značí aktivní údržbu a spolehlivost
Relevance: Sémantické sladění s uživatelským dotazem určuje, zda se obsah vůbec objeví ve výsledcích retrievalu
Struktura: Jasná hierarchie, popisné nadpisy a sémantické značkování pomáhají systémům správně chápat a extrahovat informace
Faktická hustota: Obsah nabitý konkrétními údaji, statistikami a citacemi nabízí více využitelných úryvků než obecné přehledy
Znalostní graf: Přítomnost ve Wikipedii, Wikidata nebo oborových znalostních databázích dramaticky zvyšuje pravděpodobnost citace
Každý faktor násobí účinek ostatních—dobře strukturovaný, často aktualizovaný článek z autoritativní domény se silnými zpětnými odkazy a přítomností v knowledge graph se stává v RAG systémech magnetem na citace. Vzniká tak nová optimalizační paradigma, kde viditelnost závisí méně na SEO pro návštěvnost a více na tom, stát se důvěryhodným, strukturovaným zdrojem informací.
Jak různé AI platformy využívají RAG pro citace
Různé AI platformy implementují RAG různými strategiemi, což vytváří odlišné vzorce citací. ChatGPT silně upřednostňuje zdroje z Wikipedie—studie ukazují, že přibližně 26–35 % citací pochází pouze z Wikipedie, což odráží její autoritu a strukturovanost. Google AI Overviews využívá pestřejší výběr zdrojů, sahá po zpravodajských portálech, akademických článcích i fórech, přičemž Reddit se objevuje asi v 5 % citací navzdory nižší tradiční autoritě. Perplexity AI obvykle cituje 3–5 zdrojů na odpověď a výrazně preferuje oborové publikace a aktuální zprávy, optimalizuje pro komplexnost a aktuálnost. Tyto platformy hodnotí autoritu domény různě—některé preferují tradiční ukazatele jako zpětné odkazy a stáří domény, jiné kladou důraz na čerstvost obsahu a sémantickou relevanci. Porozumění těmto retrieval strategiím je pro tvůrce obsahu klíčové, protože optimalizace pro RAG jednoho systému se může výrazně lišit od druhého.
RAG vs tradiční vyhledávání – důsledky pro citace
Vzestup RAG zásadně mění tradiční SEO pravidla. V optimalizaci pro vyhledávače citace a viditelnost přímo korelují s návštěvností—musíte získat kliknutí, abyste byli důležití. RAG tuto rovnici obrací: obsah může být citován a ovlivňovat AI odpovědi, aniž by generoval jakoukoli návštěvnost. Dobře strukturovaný, autoritativní článek se může objevit v desítkách AI odpovědí denně, aniž by získal jediné kliknutí, protože uživatelé dostanou odpověď přímo z AI souhrnu. To znamená, že signály autority jsou důležitější než kdy dřív, protože jsou hlavním mechanismem, podle kterého RAG systémy hodnotí kvalitu zdroje. Klíčová je konzistence napříč platformami—jestliže se váš obsah vyskytuje na vašem webu, LinkedInu, oborových databázích i knowledge grafech, RAG systémy vnímají zesílené signály autority. Přítomnost v knowledge graph se mění z „nice-to-have“ na základní infrastrukturu, protože tyto strukturované databáze jsou hlavními retrieval zdroji pro mnoho implementací RAG. Hra na citace se zásadně změnila z „přitáhnout návštěvnost“ na „stát se důvěryhodným informačním zdrojem“.
Optimalizace obsahu pro RAG citace
Chcete-li maximalizovat citace v RAG, musí se strategie obsahu přesunout z optimalizace na návštěvnost k optimalizaci na zdroj. Nastavte cykly aktualizací 48–72 hodin pro trvalý obsah, čímž dáváte retrieval systémům najevo, že vaše informace zůstávají aktuální. Nasazujte strukturované datové značkování (Schema.org, JSON-LD), abyste systémům pomohli správně pochopit význam a vztahy ve vašem obsahu. Slaďte obsah sémanticky s běžnými vzory dotazů—používejte přirozený jazyk, jakým lidé kladou otázky, nejen jak vyhledávají. Formátujte obsah pomocí FAQ a Q&A sekcí, protože tyto přímo odpovídají vzorci otázka–odpověď, který RAG systémy používají. Rozvíjejte nebo přispívejte do Wikipedie a knowledge graphů, protože ty jsou primárními retrieval zdroji na většině platforem. Budujte autoritu zpětnými odkazy prostřednictvím strategických partnerství a citací z dalších důvěryhodných zdrojů, protože link profil zůstává silným signálem autority. Nakonec dbejte na konzistenci napříč platformami—ujistěte se, že vaše klíčová tvrzení, data a sdělení jsou v souladu na webu, sociálních profilech, oborových databázích i knowledge graphech, čímž vytváříte posílené signály spolehlivosti.
Budoucnost RAG a citací
Technologie RAG se rychle vyvíjí a několik trendů mění způsob práce s citacemi. Sofistikovanější retrieval algoritmy půjdou za rámec sémantické podobnosti a budou lépe chápat záměr dotazu a kontext, což zlepší relevanci citací. Specializované znalostní báze se objeví pro konkrétní obory—medicínské RAG systémy využijí kurátorovanou lékařskou literaturu, právní systémy judikaturu a zákony—což vytvoří nové příležitosti pro citace autoritativních doménových zdrojů. Integrace s multi-agentními systémy umožní RAG orchestraci více specializovaných retrieverů, kteří spojí poznatky z různých knowledge base pro komplexnější odpovědi. Přístup k datům v reálném čase se výrazně zlepší a RAG systémy budou schopné začleňovat živé informace z API, databází a streamovaných zdrojů. Agentní RAG—kde AI agenti samostatně rozhodují, co získat, jak to zpracovat a kdy iterovat—vytvoří dynamičtější vzorce citací, potenciálně citující zdroje opakovaně, jak agenti zdokonalují své uvažování.
Role AmICited v monitorování RAG citací
Jak RAG mění způsob, jakým AI systémy objevují a citují zdroje, je pochopení vašeho výkonu v citacích nezbytné. AmICited monitoruje AI citace napříč platformami a sleduje, které vaše zdroje se objevují v ChatGPT, Google AI Overviews, Perplexity a nově vznikajících AI systémech. Uvidíte které konkrétní zdroje jsou citovány, jak často se vyskytují a v jakém kontextu—odhalíte, který obsah rezonuje s retrieval algoritmy RAG. Naše platforma vám pomůže porozumět vzorcům citací v celém obsahu, identifikovat, co činí některé části vhodné pro citaci a jiné neviditelné. Měřte viditelnost vaší značky v AI odpovědích pomocí metrik, které mají význam v éře RAG, posuňte se za hranice tradiční analytiky návštěvnosti. Proveďte konkurenční analýzu výkonu citací a sledujte, jak si vaše zdroje vedou v porovnání s konkurencí v AI-generovaných odpovědích. Ve světě, kde AI citace určují viditelnost a autoritu, je mít jasný přehled o svém výkonu v citacích nezbytné—je to způsob, jak zůstat konkurenceschopný.
Často kladené otázky
Jaký je rozdíl mezi RAG a tradičními LLM?
Tradiční LLM spoléhají na statická tréninková data s omezením znalostí a nemohou přistupovat k informacím v reálném čase, což často vede k halucinacím a neověřitelným tvrzením. RAG systémy před generováním odpovědí získávají informace z externích indexovaných zdrojů, což umožňuje přesné citace a zakotvené odpovědi na základě aktuálních, ověřitelných dat.
Jak RAG zlepšuje přesnost citací?
RAG sleduje každý získaný údaj zpět k jeho původnímu zdroji, díky čemuž jsou citace automatické a ověřitelné namísto halucinovaných. Vytváří to přímé propojení mezi odpovědí a zdrojovým materiálem, což umožňuje uživatelům nezávisle ověřit tvrzení a posoudit důvěryhodnost zdroje.
Jaké faktory určují, které zdroje jsou v RAG systémech citovány?
RAG systémy hodnotí zdroje podle autority (reputace domény a zpětné odkazy), aktuálnosti (obsah aktualizován do 48–72 hodin), sémantické relevance k dotazu, struktury a přehlednosti obsahu, faktické hustoty s konkrétními údaji a přítomnosti v znalostních grafech jako je Wikipedie. Tyto faktory se kombinují a určují pravděpodobnost citace.
Jak mohu optimalizovat svůj obsah pro RAG citace?
Aktualizujte obsah každých 48–72 hodin, abyste udrželi signály čerstvosti, implementujte strukturovaná data (Schema.org), slaďte obsah sémanticky s běžnými dotazy, používejte formátování FAQ a Q&A, budujte přítomnost ve Wikipedii a znalostních grafech, posilujte autoritu zpětnými odkazy a udržujte konzistenci napříč platformami.
Proč je přítomnost v znalostních grafech důležitá pro AI citace?
Znalostní grafy jako Wikipedie a Wikidata jsou hlavními zdroji pro většinu RAG systémů. Přítomnost v těchto strukturovaných databázích dramaticky zvyšuje pravděpodobnost citace a vytváří základní signály důvěry, které AI systémy opakovaně odkazují napříč různými dotazy.
Jak často bych měl aktualizovat obsah kvůli viditelnosti v RAG?
Obsah by měl být aktualizován každých 48–72 hodin, abyste udrželi silné signály aktuálnosti v RAG systémech. Nejde o kompletní přepsání – stačí přidat nové údaje, aktualizovat statistiky nebo rozšířit sekce o nedávný vývoj, abyste si zachovali způsobilost pro citace.
Jakou roli hraje autorita domény v RAG citacích?
Autorita domény funguje jako proxy pro spolehlivost v RAG algoritmech a ovlivňuje přibližně 5 % pravděpodobnosti citace. Hodnotí se podle stáří domény, SSL certifikátů, profilu zpětných odkazů, odborného autorství a přítomnosti v znalostních grafech, což vše dohromady ovlivňuje výběr zdrojů.
Jak AmICited pomáhá sledovat RAG citace?
AmICited sleduje, které vaše zdroje se objevují v AI-generovaných odpovědích napříč ChatGPT, Google AI Overviews, Perplexity a dalšími platformami. Uvidíte frekvenci citací, kontext a výkon oproti konkurenci, což vám pomůže pochopit, co dělá obsah vhodným pro citaci v éře RAG.
Sledujte citace své značky v AI
Zjistěte, jak se vaše značka objevuje v AI-generovaných odpovědích napříč ChatGPT, Perplexity, Google AI Overviews a dalšími. Sledujte vzorce citací, měřte viditelnost a optimalizujte svou přítomnost v AI-driven vyhledávacím prostředí.
Co je RAG ve vyhledávání pomocí AI: Kompletní průvodce Retrieval-Augmented Generation
Zjistěte, co je RAG (Retrieval-Augmented Generation) ve vyhledávání pomocí AI. Objevte, jak RAG zvyšuje přesnost, snižuje halucinace a pohání ChatGPT, Perplexit...
Zjistěte, jak systémy Retrieval-Augmented Generation spravují aktuálnost znalostní báze, předcházejí zastaralým datům a udržují aktuální informace pomocí indexa...
Jak funguje Retrieval-Augmented Generation: Architektura a proces
Zjistěte, jak RAG kombinuje LLM s externími datovými zdroji pro generování přesných odpovědí AI. Pochopte pětistupňový proces, komponenty a proč je důležitý pro...
9 min čtení
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.