Informační hustota
Zjistěte, co je informační hustota a jak zvyšuje pravděpodobnost citace AI. Objevte praktické techniky pro optimalizaci obsahu pro AI systémy jako ChatGPT, Perp...
13 min čtení

Naučte se vytvářet informačně hustý obsah, který preferují AI systémy. Ovládněte hypotézu rovnoměrné informační hustoty a optimalizujte svůj obsah pro AI Overviews, LLM a lepší citace.
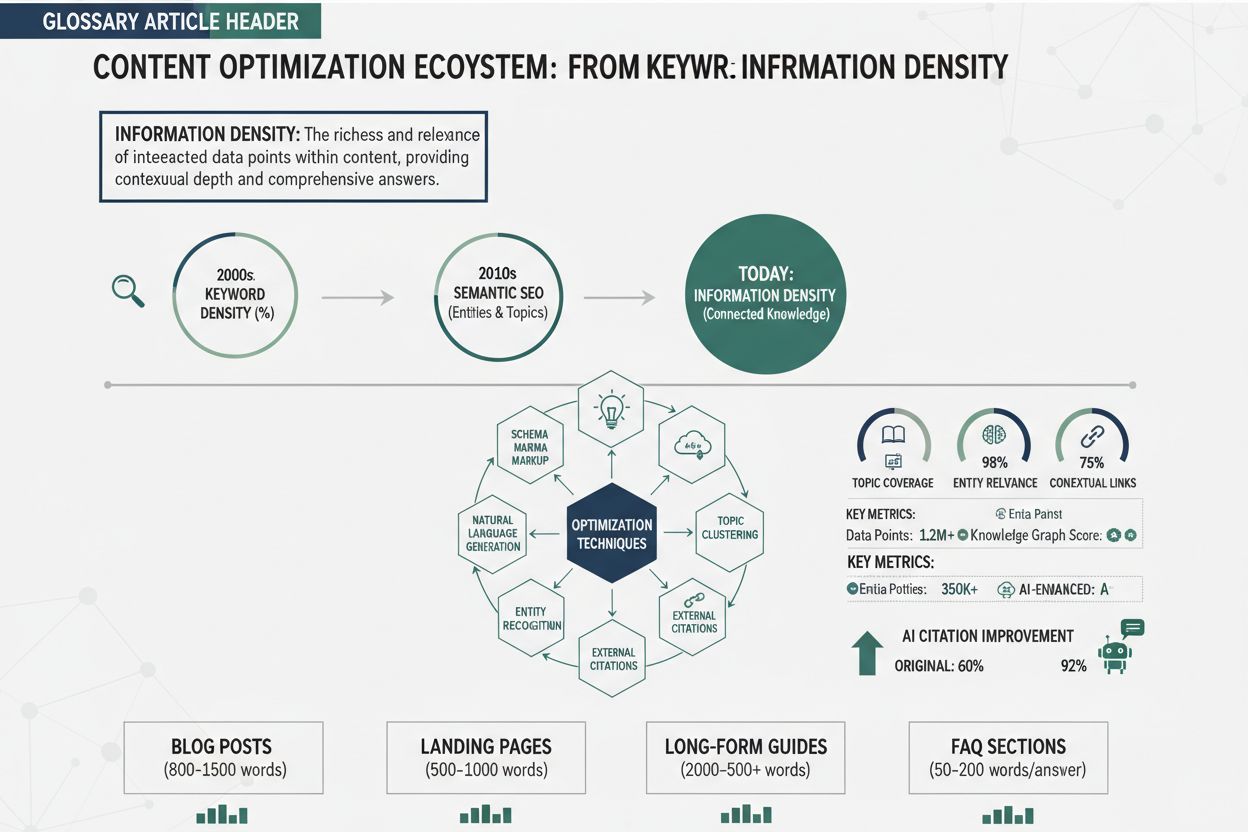
Informační hustota označuje koncentraci smysluplných, praktických poznatků v daném obsahu – tedy kolik hodnoty je obsaženo v každém slově, větě či odstavci. Tento koncept nabývá na významu v éře vyhledávání poháněného AI, zejména s nástupem velkých jazykových modelů (LLM) a AI Overviews. Hypotéza rovnoměrné informační hustoty (UID), lingvistický princip potvrzený aktuálním výzkumem na ArXiv, naznačuje, že lidé i AI systémy zpracovávají informace efektivněji, když je kognitivní zátěž rovnoměrně rozložená v celém obsahu, nikoli koncentrovaná v izolovaných částech. Pro AI systémy hodnotící obsah má informační hustota přímý dopad na pravděpodobnost, že bude váš obsah vybrán, citován a dobře umístěn ve výsledcích AI vyhledávání. Pokud tvoříte hodnotný obsah, nepíšete jen pro lidské čtenáře – optimalizujete také pro to, jak LLM získávají, syntetizují a odkazují informace z vaší práce.
LLM hodnotí hustotu obsahu pomocí více sofistikovaných mechanismů, které daleko přesahují pouhý počet slov nebo frekvenci klíčových slov. Tyto systémy analyzují metriky obsahu pomocí výpočtů založených na entropii, které měří, kolik informací je předáno vzhledem k celkové délce textu, a sledují tzv. „rovnoměrnost kroků“ – tedy konzistenci rozložení informací v sekvenčních částech vašeho obsahu. Když LLM zpracovává váš článek, počítá informační přírůstek na každém tokenu, hodnotí, zda přinášíte konzistentní hodnotu, nebo zda jsou některé části nadbytečné, odbočující či s nízkou hodnotou. Různé hodnoticí rámce upřednostňují odlišné aspekty kvality obsahu, jak ukazuje následující srovnání:
| Metrika | Co měří | Význam pro AI | Nejvhodnější použití |
|---|---|---|---|
| BLEU Score | Přesnost shody slov | Nižší význam pro hustotu | Hodnocení strojového překladu |
| ROUGE Score | Překryv obsahu (recall) | Střední význam | Kvalita shrnutí |
| Perplexita | Predikovatelnost sekvencí | Vysoký význam | Posouzení důvěry LLM |
| Informační hustota | Smysluplný obsah na jednotku délky | Nejvyšší význam | AI citace a výběr |
Porozumění těmto hodnoticím rámcům LLM vám pomůže pochopit, že AI systémy nehledají jen komplexní obsah – hledají obsah, který udržuje konzistentní informační hodnotu napříč celým textem a vyhýbá se běžné chybě „vaty“ nebo balastu, který ředí vaše sdělení.
Rozdíl mezi hustým obsahem a řídkým obsahem zásadně určuje, jak AI systémy s vaším materiálem pracují. Hustý obsah přináší vysokou informační hodnotu s minimem balastu, zatímco řídký obsah obsahuje mnoho opakování, vatu nebo málo hodnotného rozvedení. Klíčové rozdíly:
Praktický příklad: řídký článek o optimalizaci AI obsahu může tři odstavce vysvětlovat, co je AI, další tři proč je obsah důležitý, a teprve potom řeší samotné techniky. Hustý obsah předpokládá základní znalosti, kontext začlení přirozeně a věnuje většinu prostoru konkrétním strategiím. AI systémy tuto efektivitu rozpoznávají a odměňují, protože značí, že autor problematiku dobře ovládá a umí ji sdělit stručně.
Informační hustota se stala klíčovým signálem pro pozici ve vyhledávání poháněném AI – přímo ovlivňuje, zda se váš obsah objeví v AI Overviews a jak často získá citace od AI systémů. Výzkum společnosti BrightEdge analyzující algoritmy AI ukazuje, že obsah vybraný do AI Overviews má přibližně o 40 % vyšší skóre informační hustoty než obsah, který vybrán není, což naznačuje, že AI systémy aktivně upřednostňují hustý, hodnotný materiál při syntéze odpovědí. Vztah mezi informační hustotou a mírou citací je zásadní i z pohledu AmICited.com: když AI systémy jako Perplexity nebo Google AI Overviews potřebují odkázat na zdroj, preferenčně citují obsah, který přináší koncentrovanou hodnotu, protože tím snižují potřebu citovat více zdrojů k zodpovězení jedné otázky. Obsah s vysokou informační hustotou se také lépe umisťuje, protože lépe naplňuje záměr uživatele – AI systémy rozpoznají, že hustý obsah dává úplnější odpovědi a snižuje nutnost hledat další zdroje. Algoritmy AI Overviews navíc hodnotí, zda lze obsah efektivně shrnout a syntetizovat, a hustý obsah je sám o sobě lépe shrnutelný, protože obsahuje méně rušivých prvků, které by musely být během syntézy odstraněny.
Tvorba hodnotného obsahu vyžaduje vědomé strukturální a redakční volby, které upřednostní předání informací před počtem slov. Začněte nemilosrdným auditem svého stávajícího obsahu: identifikujte každou větu, která neposouvá váš hlavní argument nebo nepřináší praktickou hodnotu, a buď ji odstraňte, nebo začleňte do okolních vět s vícero účely. Využívejte strukturované formáty – číslované seznamy, srovnávací tabulky, hierarchické nadpisy a sekce s definicemi – které umožňují čtenářům i AI rychle extrahovat klíčové informace bez nutnosti pročítat narativní prozaický text. Uplatněte princip „jedna myšlenka na odstavec“, aby každá část měla jasný účel a nebyla rozmělněna odbočkami – to přímo podporuje hypotézu UID rovnoměrným rozložením kognitivní zátěže. U složitých pojmů použijte princip postupného odhalování: nejprve představte základní informaci, pak přidávejte detaily, příklady a nuance – tato metoda slouží jak lidským čtenářům, tak LLM, které mohou obsah extrahovat na různých úrovních podrobnosti. Využívejte konkrétní data, statistiky a příklady namísto abstraktních zobecnění; „přibližně o 40 % vyšší informační hustota“ je pro AI hodnotnější než „výrazně vyšší hustota“. Nakonec optimalizujte svůj proces optimalizace obsahu tím, že informační hustotu zařadíte mezi hlavní metriky stejně jako tradiční SEO – procházejte koncepty s otázkou, zda lze každou část zestručnit, spojit či odstranit bez ztráty zásadní hodnoty.
Měření informační hustoty vyžaduje pochopení jak teoretických rámců, tak praktických nástrojů, které má tvůrce obsahu k dispozici. Nejjednodušším způsobem je spočítat skóre informační hustoty pomocí metrik založených na entropii: vydělte celkový informační obsah (měřený v bitech nebo pomocí sémantické analýzy) celkovým počtem slov a určete tak, kolik smysluplných informací na jednotku textu přinášíte. Pomoci mohou různé nástroje: platformy pro zpracování přirozeného jazyka analyzují sémantickou rozmanitost a rozložení pojmů, nástroje na čitelnost odhalí vzorce opakování, vlastní skripty v Pythonu s knihovnami jako NLTK umožní spočítat entropii vašeho obsahu. Praktický příklad: pokud 2 000 slovný článek obsahuje přibližně 150 unikátních sémantických pojmů s rovnoměrným rozdělením, má vyšší informační hustotu než stejně dlouhý článek s pouhými 80 pojmy soustředěnými v první polovině. Můžete použít i zástupné metriky jako poměr unikátních pojmů k počtu slov, průměrný přírůstek informací na odstavec nebo počet praktických závěrů na 500 slov – nejsou perfektní, ale dávají užitečný směr. Výzkum BrightEdge doporučuje sledovat, jak často je váš obsah citován AI systémy jako reálnou validaci informační hustoty; pokud se trvale objevujete v AI Overviews a sbíráte citace, pravděpodobně cílíte na správnou hustotu.
Nejčastější chybou při snaze o informační hustotu je přehnaná optimalizace, kdy autoři usilují o maximální hustotu natolik, že je obsah nečitelný nebo postrádá potřebný kontext a vysvětlení. Často to vede ke „keyword stuffing“ maskovanému jako optimalizace hustoty – násilné vkládání cílových frází do vět, kde se nehodí, což naopak snižuje hodnotu a spouští penalizace AI systémů. Kritickou chybou je i informační přetížení snahou pokrýt příliš mnoho témat v jednom textu; tím porušíte hypotézu UID, když v některých částech soustředíte nadměrnou kognitivní zátěž a jiné necháte řídké. Další častou chybou je špatná struktura: i informačně hustý obsah ztrácí účinnost, není-li organizován hierarchicky s jasnými vazbami mezi pojmy, což nutí čtenáře i AI složitěji hledat hodnotu. Někteří autoři také zaměňují hustotu s krátkostí – vytvoří sice krátký text, ale bez hloubky uspokojující uživatelský záměr nebo poskytující dostatečný kontext pro přesnou syntézu a citaci AI systémů. Nakonec nedostatečně rovnoměrné rozložení informací v rámci obsahu vytváří nerovnoměrnou kognitivní zátěž – např. když všechny statistiky a data soustředíte do úvodu a zbytek je jen vysvětlující narace, porušujete princip UID a snižujete účinnost svého obsahu pro AI.
Principy informační hustoty platí napříč všemi formáty obsahu, ale ideální úroveň hustoty i strategie realizace se výrazně liší podle typu obsahu. Blogové příspěvky těží z mírně až vysoké hustoty s promyšleným využitím příkladů a vysvětlení, která činí husté pojmy přístupnější; technický blog může mít hustotu 70–80 %, zatímco pro začátečníky je vhodnější 50–60 % pro lepší srozumitelnost. Technická dokumentace vyžaduje nejvyšší informační hustotu, protože čtenáři očekávají koncentrovanou hodnotu a minimum balastu – dokumentace s hustotou 85 % a více je v AI systémech úspěšnější, protože je snáze shrnutelná a citovatelná. Produktové stránky vyžadují jiný přístup, vyvažují hustotu s přesvědčivostí a uživatelským zážitkem; chcete-li koncentrovat hodnotu do popisů funkcí a přínosů, přílišná hustota však může zákazníka zahltit a snížit konverzi. Zpravodajské články a žurnalistika mají jiná omezení, kdy je často nutné nižší hustotu kvůli narativnímu kontextu, AI systémy však stále preferují zprávy, které efektivně předávají fakta bez zbytečných komentářů. Vědecké studie a whitepapery mohou udržet velmi vysokou hustotu, protože publikum očekává technickou hloubku, i akademický obsah však těží z jasné struktury a strategického použití shrnutí pro udržení principu UID. Pochopení těchto rozdílů vám umožní optimalizovat informační hustotu vhodně pro konkrétní typ obsahu při zachování účinnosti pro lidi i AI.
S tím, jak se AI systémy stávají sofistikovanějšími, bude informační hustota pravděpodobně ještě důležitějším signálem pro pozici i citace, zejména s rostoucí konkurencí o zařazení do AI Overviews. Nové výzkumy naznačují, že budoucí LLM budou používat stále propracovanější metody hodnocení kvality a hustoty informací – posunou se od prostých entropických výpočtů ke složitější sémantické analýze, která odmění nejen koncentraci, ale i optimální strukturu informací pro syntézu a citaci. Vývoj AI vyhledávání bude pravděpodobně favorizovat tvůrce, kteří chápou, že vývoj AI není o „obcházení algoritmů“, ale o skutečném naplnění uživatelského záměru – hustý, dobře strukturovaný obsah je v tomto ohledu přirozeně výhodný, protože AI poskytuje bohatší materiál ke zpracování. Tvůrci obsahu by se měli připravit na budoucnost, kdy strategie obsahu bude stále více stavět na kvalitě před kvantitou, kdy článek o 1 500 slovech s výjimečnou hustotou překoná pětitisícový s průměrnou hustotou a schopnost sdělit složité myšlenky stručně bude konkurenční výhodou. Organizace, které sledují svou přítomnost v AI Overviews a monitorují míru citací přes platformy jako AmICited.com, získají významný náskok, protože mohou přímo sledovat, jak změny v informační hustotě ovlivňují jejich viditelnost ve vyhledávání poháněném AI. Tvůrci a firmy, kteří už nyní investují do pochopení a optimalizace informační hustoty, budou nejlépe připraveni uspět, až se AI vyhledávání stane hlavním kanálem objevování online obsahu.

Informační hustota označuje koncentraci smysluplných, praktických poznatků v obsahu – tedy kolik hodnoty je obsaženo v každém slově či větě. AI systémy toto kritérium hodnotí, aby rozhodly, který obsah citovat a zobrazit v AI Overviews. Vyšší informační hustota obvykle znamená lepší viditelnost ve výsledcích AI vyhledávání.
Hypotéza UID naznačuje, že efektivní komunikace udržuje stabilní tok informací napříč celým obsahem. AI systémy zpracovávají obsah efektivněji, když je kognitivní zátěž rovnoměrně rozložena, místo aby byla soustředěna v jednotlivých částech. Tento princip přímo ovlivňuje, jak LLM vybírají a citují váš obsah.
Hustý obsah poskytuje vysokou informační hodnotu s minimem balastu, používá přesný jazyk a eliminuje opakování. Řídký obsah obsahuje značné opakování a málo hodnotného rozvedení. AI systémy preferují hustý obsah, protože je efektivnější pro syntézu a citaci, což snižuje potřebu více zdrojů.
Informační hustotu můžete změřit výpočtem poměru smysluplných informací k celkovému počtu slov pomocí metrik založených na entropii. Praktické přístupy zahrnují sledování počtu unikátních sémantických pojmů na slovo, monitorování praktických závěrů na 500 slov nebo pozorování, jak často AI systémy citují váš obsah v AI Overviews.
Ano, výrazně. Výzkum ukazuje, že obsah vybraný do AI Overviews vykazuje přibližně o 40 % vyšší skóre informační hustoty než nevybraný obsah. AI systémy preferenčně citují hustý, hodnotný obsah, protože poskytuje komplexní odpovědi s menší potřebou více zdrojů.
Běžné chyby zahrnují přehnanou optimalizaci vedoucí ke snížené čtivosti, nadměrné vkládání klíčových slov maskované jako hustota, zahlcení informacemi při pokrytí příliš mnoha témat, špatnou strukturu, zaměňování hustoty s krátkostí a nedostatek rovnoměrné distribuce informací napříč obsahem.
Požadavky na informační hustotu se liší podle formátu: technická dokumentace těží z hustoty 85 % a více, blogové příspěvky jsou efektivní při 70–80 %, produktové stránky vyvažují hustotu s přesvědčivostí na 50–70 % a zpravodajské články mohou mít nižší hustotu kvůli narativním požadavkům. Hustotu optimalizujte podle konkrétního typu obsahu.
S rostoucí sofistikovaností AI systémů se informační hustota pravděpodobně stane ještě důležitějším signálem pro hodnocení. Budoucí LLM pravděpodobně vyvinou propracovanější metody hodnocení kvality informací, přičemž upřednostní tvůrce, kteří chápou, že hustý, dobře strukturovaný obsah lépe naplňuje záměr uživatele.
Sledujte, jak AI systémy jako ChatGPT, Perplexity a Google AI Overviews citují a odkazují na vaši značku. Získejte aktuální přehled o své AI viditelnosti a výkonnosti obsahu.
Zjistěte, co je informační hustota a jak zvyšuje pravděpodobnost citace AI. Objevte praktické techniky pro optimalizaci obsahu pro AI systémy jako ChatGPT, Perp...

Zjistěte, proč již hustota klíčových slov pro AI vyhledávání nehraje roli. Zjistěte, co ChatGPT, Perplexity a Google AI Overviews skutečně upřednostňují při hod...
Diskuze komunity o tom, zda na hustotě klíčových slov záleží pro AI vyhledávání. Skutečné zkušenosti SEO profesionálů s testováním dopadu optimalizace klíčových...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.