Vzory AI dotazů
Zjistěte více o vzorech AI dotazů – opakujících se strukturách a formulacích, které uživatelé používají při pokládání otázek AI asistentům. Objevte, jak tyto vz...
5 min čtení
Objevte, jak moderní AI systémy jako Google AI Mode a ChatGPT rozkládají jeden dotaz na více vyhledávání. Poznejte mechanismy rozvětvení dotazů, dopady na viditelnost v AI a optimalizaci obsahové strategie.
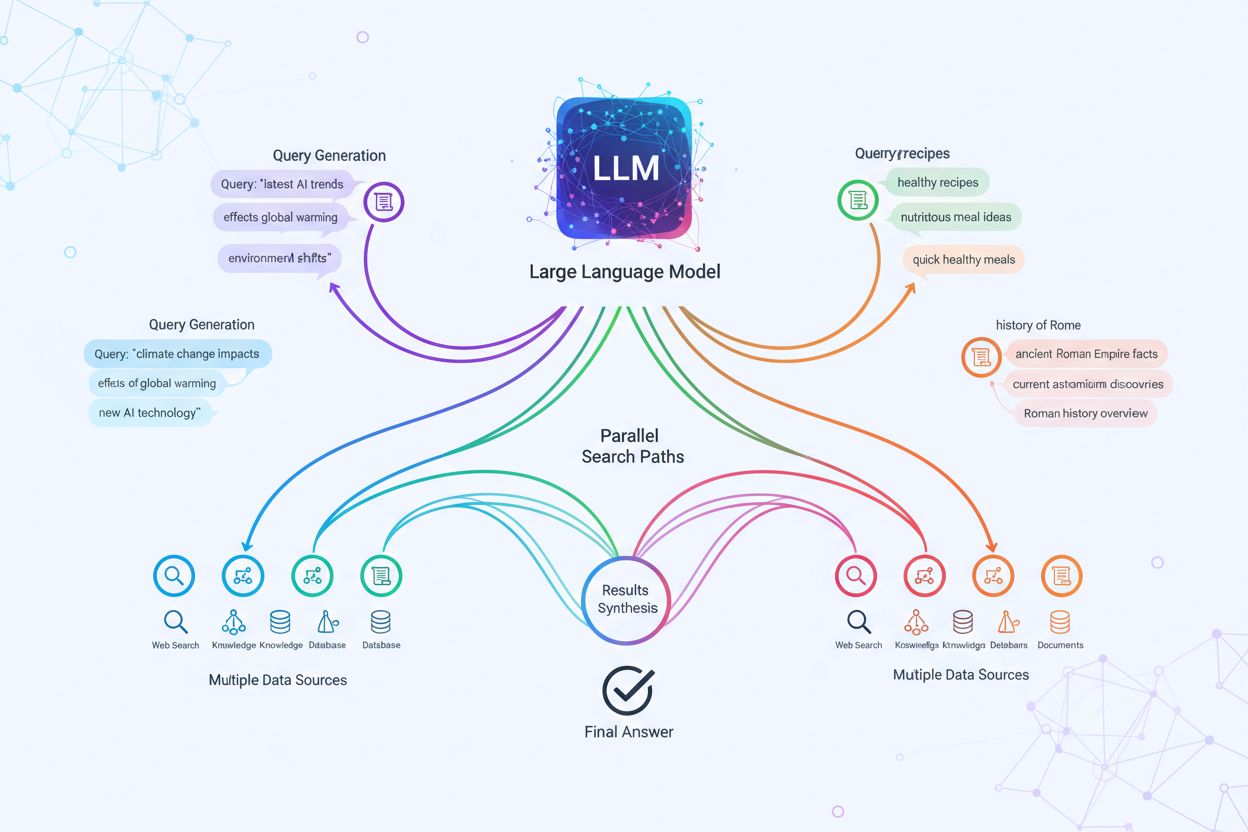
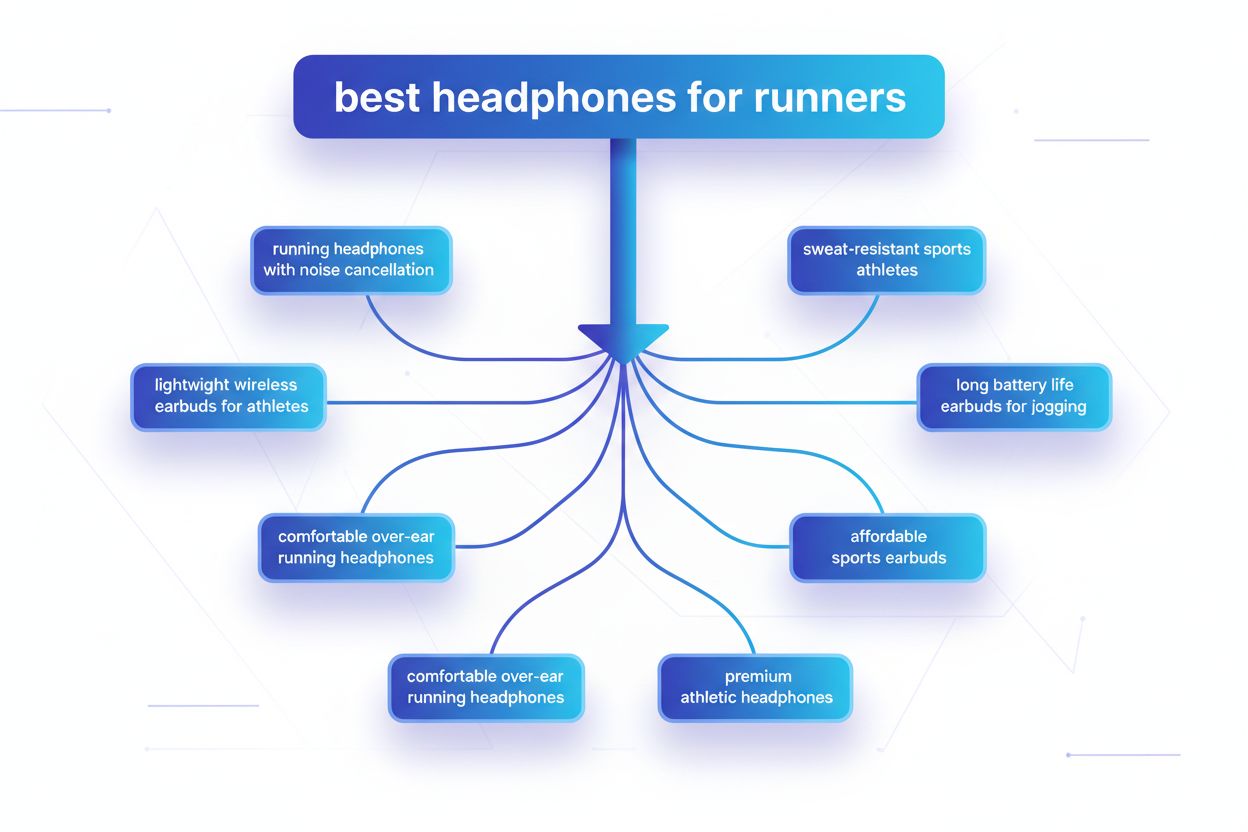
Rozvětvení dotazů je proces, při kterém velké jazykové modely automaticky rozdělí jeden uživatelský dotaz na více poddotazů, aby získaly komplexnější informace z různých zdrojů. Místo jednoho vyhledávání moderní AI systémy rozkládají uživatelský záměr do 5–15 souvisejících dotazů, které zachycují různé úhly pohledu, interpretace a aspekty původního požadavku. Například když uživatel hledá „nejlepší sluchátka pro běžce“ v Google AI Mode, systém vygeneruje přibližně 8 různých vyhledávání včetně variant jako „běžecká sluchátka s potlačením hluku“, „lehké bezdrátové špunty pro sportovce“, „potuodolná sportovní sluchátka“ a „sluchátka s dlouhou výdrží baterie na běhání“. To představuje zásadní odklon od tradičního vyhledávání, kde se jeden textový dotaz porovnává s indexem. Klíčové charakteristiky rozvětvení dotazů zahrnují:
Technická implementace rozvětvení dotazů spoléhá na sofistikované NLP algoritmy, které analyzují složitost dotazu a generují sémanticky smysluplné varianty. LLM generují osm hlavních typů variant dotazů: ekvivalentní dotazy (přeformulování se stejným významem), navazující dotazy (zkoumání souvisejících témat), zobecňující dotazy (rozšíření rozsahu), specifikující dotazy (zúžení zaměření), kanonizující dotazy (standardizace terminologie), překladové dotazy (převod mezi doménami), implikační dotazy (zkoumání logických důsledků) a upřesňující dotazy (odstranění nejasností). Systém využívá neuronové jazykové modely k posouzení složitosti dotazu—měří např. počet entit, hustotu vztahů a sémantickou nejednoznačnost—a rozhoduje, kolik poddotazů vygenerovat. Po vygenerování jsou tyto dotazy prováděny paralelně v různých vyhledávacích systémech, včetně webových crawlerů, znalostních grafů (např. Google Knowledge Graph), strukturovaných databází a vektorových indexů podobnosti. Jednotlivé platformy tuto architekturu implementují s různou mírou transparentnosti a sofistikovanosti:
| Platforma | Mechanismus | Transparentnost | Počet dotazů | Metoda řazení |
|---|---|---|---|---|
| Google AI Mode | Explicitní rozvětvení s viditelnými dotazy | Vysoká | 8–12 dotazů | Vícefázové řazení |
| Microsoft Copilot | Iterativní Bing Orchestrator | Střední | 5–8 dotazů | Skórování relevance |
| Perplexity | Hybridní vyhledávání s vícestupňovým řazením | Vysoká | 6–10 dotazů | Na základě citací |
| ChatGPT | Implicitní generování dotazů | Nízká | Neznámý | Interní vážení |
Složité dotazy procházejí sofistikovaným rozkladem, kdy je systém rozdělí na základní entity, atributy a vztahy před generováním variant. Při zpracování dotazu jako „Bluetooth sluchátka s pohodlným náhlavním designem a dlouhou výdrží baterie vhodná pro běžce“ provádí systém porozumění zaměřené na entity identifikací klíčových entit (Bluetooth sluchátka, běžci) a extrakcí zásadních atributů (pohodlné, náhlavní, dlouhá výdrž baterie). Proces rozkladu využívá znalostní grafy k pochopení vztahů mezi entitami a sémantických variací—rozpoznává například, že „náhlavní sluchátka“ a „circumaurální sluchátka“ jsou ekvivalentní, nebo že „dlouhá výdrž baterie“ může znamenat 8+ hodin, 24+ hodin nebo vícedenní výdrž podle kontextu. Systém zjišťuje související koncepty pomocí měření sémantické podobnosti, chápe, že dotazy na „odolnost proti potu“ a „voděodolnost“ spolu souvisejí, ale nejsou totožné, a že „běžce“ mohou zajímat i „cyklisté“, „návštěvníci posilovny“ nebo „outdooroví sportovci“. Tento rozklad umožňuje generovat cílené poddotazy, které zachycují různé aspekty uživatelského záměru, místo pouhého přeformulování původního požadavku.
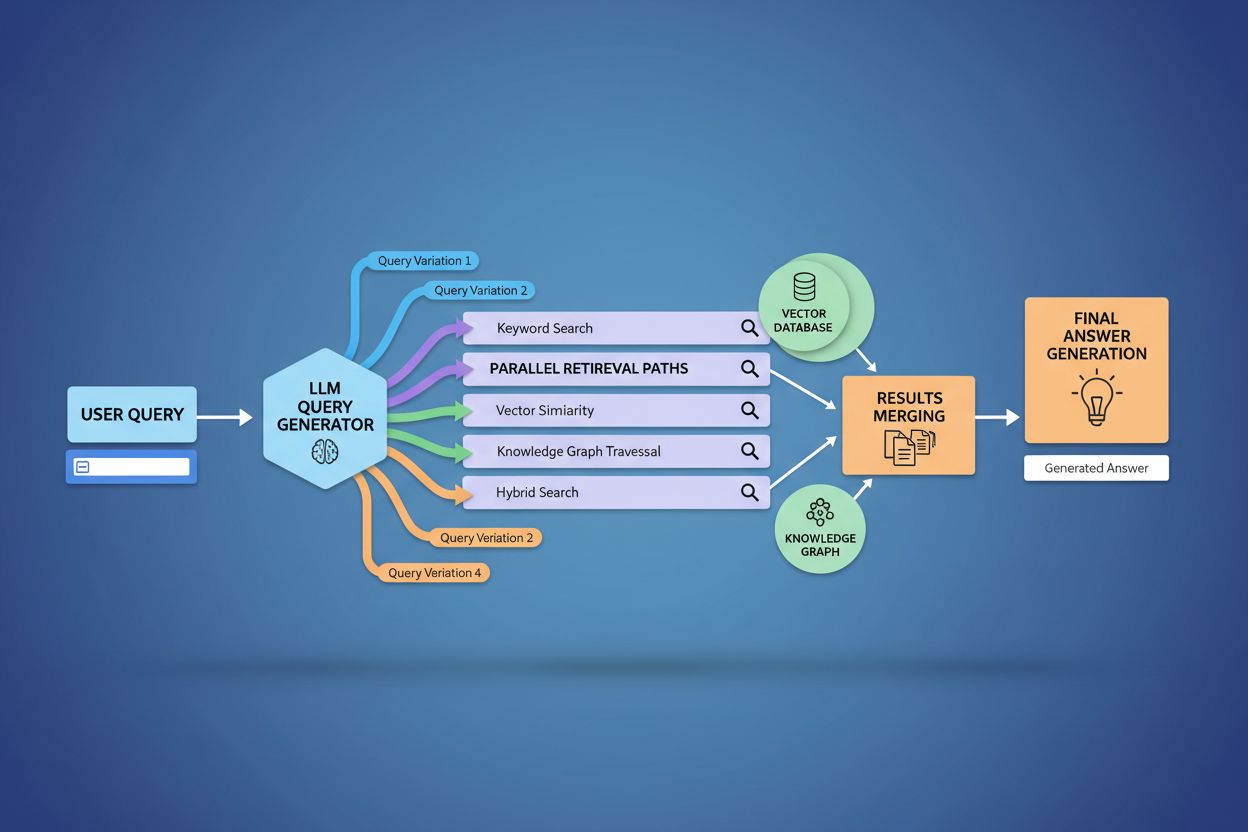
Rozvětvení dotazů zásadně posiluje vyhledávací komponentu rámců Retrieval-Augmented Generation (RAG) tím, že umožňuje bohatší a rozmanitější sběr důkazů před fází generování. V tradičních RAG pipeline je jeden dotaz vnořen a porovnáván s vektorovou databází, což může vést k přehlédnutí relevantních informací, které používají jinou terminologii či koncept. Rozvětvení dotazů tuto slabinu řeší spuštěním více vyhledávání paralelně, přičemž každé je optimalizováno pro konkrétní variantu dotazu a společně shromažďují důkazy z různých úhlů a zdrojů. Tato strategie paralelního vyhledávání výrazně snižuje riziko halucinací tím, že odpovědi LLM zakotví ve více nezávislých zdrojích—když systém získává informace o „náhlavních sluchátkách“, „circumaurálním designu“ a „plnoformátových sluchátkách“ zvlášť, může ověřovat tvrzení napříč těmito výsledky. Architektura implementuje sémantické dělení na pasáže a vyhledávání na základě pasáží, kdy jsou dokumenty děleny na smysluplné sémantické jednotky namísto pevných délek, což systému umožňuje vyhledat nejrelevantnější pasáže bez ohledu na strukturu dokumentu. Kombinací důkazů z více poddotazů poskytují RAG systémy odpovědi, které jsou komplexnější, lépe podložené a méně náchylné k sebevědomě nesprávným výstupům, které trápí přístup s jedním dotazem.
Uživatelský kontext a personalizační signály dynamicky ovlivňují, jak rozvětvení dotazů rozšiřuje jednotlivé požadavky, čímž vznikají personalizované cesty vyhledávání, které se mohou výrazně lišit uživatel od uživatele. Systém zahrnuje více dimenzí personalizace včetně uživatelských atributů (geografická poloha, demografický profil, profesní role), vzorců vyhledávací historie (předchozí dotazy a kliknuté výsledky), časových signálů (denní doba, roční období, aktuální události) a kontextu úkolu (zda uživatel zkoumá, nakupuje nebo se učí). Například dotaz na „nejlepší sluchátka pro běžce“ se rozšíří jinak pro 22letého ultramaratonce v Keni než pro 45letého rekreačního běžce v Minnesotě—prvnímu uživateli systém zvýrazní odolnost a odolnost proti horku, druhému pohodlí a dostupnost. Tato personalizace však přináší problém „dvojbodové transformace“, kdy systém chápe aktuální dotazy jako varianty historických vzorců, což může omezovat objevování a posilovat stávající preference. Personalizace může neúmyslně vytvářet filtrační bubliny, kdy expanze dotazů systematicky zvýhodňuje zdroje a pohledy odpovídající uživatelově historii, což omezuje kontakt s alternativními názory nebo novými informacemi. Porozumění těmto mechanismům je zásadní pro tvůrce obsahu, protože stejný obsah může, ale také nemusí být vyhledán podle uživatelského profilu a historie.
Hlavní AI platformy implementují rozvětvení dotazů s výrazně odlišnými architekturami, úrovněmi transparentnosti a strategickými přístupy, které odrážejí jejich infrastrukturu a filozofii návrhu. Google AI Mode používá explicitní, viditelné rozvětvení dotazů, kde uživatelé mohou vidět 8–12 vygenerovaných poddotazů zobrazených vedle výsledků, a systém spouští stovky individuálních vyhledávání v rámci Google indexu pro získání komplexních důkazů. Microsoft Copilot využívá iterativní přístup řízený Bing Orchestrator, který generuje 5–8 dotazů sekvenčně, přičemž sadu dotazů průběžně upřesňuje podle průběžných výsledků před finálním vyhledáváním. Perplexity implementuje hybridní vyhledávací strategii s vícestupňovým řazením, generuje 6–10 dotazů a provádí je jak na webových zdrojích, tak ve vlastním indexu; poté aplikuje sofistikované algoritmy řazení pro zvýraznění nejrelevantnějších pasáží. Přístup ChatGPT zůstává pro uživatele převážně neprůhledný, generování dotazů probíhá implicitně v rámci interního zpracování modelu, takže není jasné, kolik dotazů je generováno nebo jak jsou prováděny. Tyto architektonické rozdíly mají zásadní dopady na transparentnost, reprodukovatelnost a možnosti optimalizace obsahu pro každou platformu:
| Aspekt | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Viditelnost dotazů | Plně viditelná uživateli | Částečně viditelná | Viditelná v citacích | Skrytá |
| Model provádění | Paralelní dávka | Iterativní sekvenční | Paralelní s řazením | Interní/implicitní |
| Různorodost zdrojů | Pouze Google index | Bing + vlastní | Web + vlastní index | Trénovací data + pluginy |
| Transparentnost citací | Vysoká | Střední | Velmi vysoká | Nízká |
| Možnosti přizpůsobení | Omezené | Střední | Vysoké | Střední |
Rozvětvení dotazů přináší řadu technických a sémantických výzev, které mohou způsobit odklon systému od skutečného uživatelského záměru tím, že vyhledá technicky související, ale ve výsledku neužitečné informace. Sémantický posun nastává při generativní expanzi, když LLM vytváří varianty dotazu, které jsou sice sémanticky příbuzné, ale postupně mění význam—dotaz na „nejlepší sluchátka pro běžce“ může být rozšířen na „sportovní sluchátka“, poté „sportovní vybavení“ a nakonec „fitness zařízení“, čímž se stále více vzdaluje původnímu záměru. Systém musí rozlišovat mezi latentním záměrem (co by uživatel mohl chtít, kdyby věděl víc) a explicitním záměrem (co skutečně požadoval); příliš agresivní expanze může tyto kategorie zaměnit, což vede k vyhledání informací o produktech, které uživatel nikdy nechtěl. K postupné odchylce dochází, když každý vygenerovaný dotaz vytváří další poddotazy a vzniká rozvětvující se strom stále vzdálenějších vyhledávání, která dohromady přinášejí informace užitečné jen okrajově. Filtrační bubliny a personalizační zkreslení znamenají, že dva uživatelé se stejným dotazem obdrží systematicky jiné rozšíření na základě svého profilu, což může vést ke vzniku ozvěnových komor, kde expanze každého uživatele posiluje jeho stávající preference. V praxi se tyto problémy projevují např. tím, že uživateli hledajícímu „cenově dostupná sluchátka“ rozšíří systém dotaz i na luxusní značky podle jeho historie prohlížení, nebo že dotaz na „sluchátka pro sluchově postižené“ rozšíří na obecné produkty pro přístupnost, čímž se rozmělní specifika původního záměru.
Růst rozvětvení dotazů zásadně mění obsahovou strategii od optimalizace na pozice klíčových slov k viditelnosti na základě citací, což vyžaduje, aby tvůrci přehodnotili strukturu i prezentaci informací. Tradiční SEO se zaměřovalo na pozice ve vyhledávání pro konkrétní klíčová slova; AI vyhledávání upřednostňuje být citován jako autoritativní zdroj napříč různými variantami dotazů a kontexty. Tvůrci obsahu by měli přijmout strategii atomického, entitami bohatého obsahu, kde jsou informace strukturovány kolem konkrétních entit (produkty, koncepty, lidé) s bohatým sémantickým označením, které AI systémům umožňuje extrahovat a citovat relevantní pasáže. Důležitost získává tematické seskupování a autorita v tématu—místo izolovaných článků na jednotlivá klíčová slova se úspěšný obsah soustředí na komplexní pokrytí témat, což zvyšuje šanci na vyhledání napříč rozmanitými variantami dotazů generovanými rozvětvením. Implementace schéma označení a strukturovaných dat umožňuje AI lépe chápat strukturu obsahu a efektivněji extrahovat informace, čímž se zvyšuje pravděpodobnost citace. Metriky úspěchu se posouvají od sledování pozic klíčových slov k monitorování četnosti citací prostřednictvím nástrojů jako AmICited.com, který sleduje, jak často se značka a obsah objevují v AI odpovědích. Mezi doporučené postupy patří: tvorba komplexního, dobře zdrojovaného obsahu pokrývajícího různé úhly pohledu; implementace bohatých schémat (Organization, Product, Article schemas); budování tematické autority propojeným obsahem; a pravidelný audit, jak se váš obsah zobrazuje v AI odpovědích napříč různými platformami i segmenty uživatelů.
Rozvětvení dotazů je nejvýznamnější architektonickou změnou ve vyhledávání od zavedení mobile-first indexace a zásadně restrukturalizuje, jak je informace objevována a prezentována uživatelům. Evoluce směrem k sémantické infrastruktuře znamená, že vyhledávací systémy budou stále více fungovat na bázi významu místo klíčových slov, přičemž rozvětvení dotazů se stává výchozím mechanismem vyhledávání místo volitelného vylepšení. Metriky citací nabývají stejné důležitosti jako zpětné odkazy při určování viditelnosti a autority obsahu—obsah citovaný v 50 různých AI odpovědích má větší váhu než obsah na první pozici pro jediné klíčové slovo. Tento posun přináší výzvy i příležitosti: tradiční SEO nástroje sledující pozice klíčových slov ztrácí relevanci a vyžadují nové rámce měření zaměřené na četnost citací, různorodost zdrojů a výskyt napříč variantami dotazů. Zároveň vznikají příležitosti pro značky optimalizovat přímo pro AI vyhledávání tvorbou autoritativního, dobře strukturovaného obsahu, který slouží jako důvěryhodný zdroj napříč různými interpretacemi dotazů. Do budoucna lze očekávat větší transparentnost mechanismů rozvětvení dotazů, kdy platformy budou soutěžit v tom, jak jasně uživatelům ukazují logiku svého vícedotazového přístupu, a tvůrci obsahu budou rozvíjet specializované strategie pro maximalizaci viditelnosti napříč rozmanitými vyhledávacími cestami, které rozvětvení přináší.
Rozvětvení dotazu je automatizovaný proces, kdy AI systémy rozkládají jeden uživatelský dotaz na více poddotazů a provádějí je paralelně, zatímco rozšíření dotazu tradičně znamená přidání souvisejících výrazů k jednomu dotazu. Rozvětvení dotazu je sofistikovanější, generuje sémanticky rozmanité varianty, které zachycují různé úhly pohledu a interpretace původního záměru.
Rozvětvení dotazu významně ovlivňuje viditelnost, protože váš obsah musí být dohledatelný napříč různými variantami dotazu, nejen přesně na uživatelský dotaz. Obsah, který řeší různé úhly, používá různorodou terminologii a je dobře strukturován se schématem, má větší šanci být vyhledán a citován napříč rozmanitými poddotazy generovanými rozvětvením.
Všechny hlavní AI vyhledávací platformy používají mechanismy rozvětvení dotazů: Google AI Mode využívá explicitní, viditelné rozvětvení (8-12 dotazů); Microsoft Copilot používá iterativní rozvětvení přes Bing Orchestrator; Perplexity implementuje hybridní vyhledávání s vícestupňovým hodnocením; a ChatGPT využívá implicitní generování dotazů. Každá platforma to implementuje jinak, ale všechny rozkládají složité dotazy na více vyhledávání.
Ano. Optimalizujte tvorbou atomického, entitami bohatého obsahu strukturovaného kolem konkrétních konceptů; implementací komplexního schéma označení; budováním tematické autority skrz propojený obsah; používáním jasné, rozmanité terminologie; a pokrytím více úhlů tématu. Nástroje jako AmICited.com vám pomohou sledovat, jak se váš obsah zobrazuje napříč různými rozklady dotazů.
Rozvětvení dotazu zvyšuje latenci, protože více dotazů běží paralelně, ale moderní systémy to zmírňují paralelním zpracováním. Zatímco jeden dotaz může trvat 200 ms, provedení 8 dotazů paralelně obvykle přidá jen 300–500 ms celkové latence díky souběžnému běhu. Tento kompromis se vyplatí kvůli vyšší kvalitě odpovědí.
Rozvětvení dotazu posiluje Retrieval-Augmented Generation (RAG) tím, že umožňuje bohatší sběr důkazů. Místo získávání dokumentů pro jeden dotaz získává rozvětvení důkazy pro více variant dotazu paralelně, což poskytuje LLM rozmanitější a komplexnější kontext pro přesnější odpovědi a snižuje riziko halucinací.
Personalizace ovlivňuje, jak jsou dotazy rozkládány na základě uživatelských atributů (lokace, historie, demografie), časových signálů a kontextu úkolu. Stejný dotaz se rozšiřuje jinak pro různé uživatele, což vytváří personalizované cesty vyhledávání. To může zlepšit relevanci, ale zároveň vytváří filtrační bubliny, kde uživatelé vidí systematicky odlišné výsledky podle svého profilu.
Rozvětvení dotazu představuje nejvýznamnější změnu ve vyhledávání od zavedení mobile-first indexace. Tradiční metriky pozic klíčových slov ztrácí význam, protože stejný dotaz se rozšiřuje jinak pro různé uživatele. SEO odborníci musí přesunout pozornost od pozic klíčových slov k viditelnosti na základě citací, struktuře obsahu a optimalizaci entit, aby uspěli v AI vyhledávání.
Zjistěte, jak se vaše značka zobrazuje napříč AI vyhledávacími platformami, když jsou dotazy rozšiřovány a rozkládány. Sledujte citace a zmínky v AI-generovaných odpovědích.
Zjistěte více o vzorech AI dotazů – opakujících se strukturách a formulacích, které uživatelé používají při pokládání otázek AI asistentům. Objevte, jak tyto vz...

Upřesnění dotazu je iterativní proces optimalizace vyhledávacích dotazů pro lepší výsledky v AI vyhledávačích. Zjistěte, jak funguje v ChatGPT, Perplexity, Goog...

Zjistěte, co je odhad objemu AI dotazů, jak se liší od tradičního objemu vyhledávání a proč je klíčový pro optimalizaci viditelnosti obsahu napříč ChatGPT, Perp...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.