
Jak strukturovat obsah pro AI citace? Kompletní průvodce pro rok 2025
Zjistěte, jak strukturovat svůj obsah, abyste získali citace od AI vyhledávačů jako ChatGPT, Perplexity a Google AI. Odborné strategie pro viditelnost a citace ...
8 min čtení

Zjistěte, jak testovat formáty obsahu pro AI citace pomocí metodologie A/B testování. Objevte, které formáty přinášejí nejvyšší viditelnost a míru citací v ChatGPT, Google AI Overviews a Perplexity.
Systémy umělé inteligence zpracovávají obsah zásadně odlišně než lidský čtenář – spoléhají na strukturované signály pro pochopení významu a extrakci informací. Zatímco lidé zvládnou i kreativní formátování nebo hutný text, AI modely vyžadují jasnou organizační hierarchii a sémantické značky, aby dokázaly efektivně parsovat a pochopit hodnotu obsahu. Výzkumy ukazují, že strukturovaný obsah se správnou hierarchií nadpisů dosahuje míry citací o 156 % vyšší než nestrukturované alternativy, což odhaluje zásadní rozdíl mezi obsahem přívětivým pro lidi a obsahem přívětivým pro AI. Tento rozdíl vzniká proto, že AI systémy jsou trénovány na obrovských datech, kde dobře organizovaný obsah typicky koreluje s autoritativními, důvěryhodnými zdroji. Porozumění a testování různých formátů obsahu je dnes nezbytné pro značky, které chtějí být viditelné ve výsledcích vyhledávání a odpovědních enginech poháněných AI.
Různé AI platformy vykazují odlišné preference pro zdroje a formáty obsahu, což tvoří složitou optimalizační krajinu. Výzkum analyzující 680 milionů citací napříč hlavními platformami odhaluje výrazné rozdíly v tom, jak ChatGPT, Google AI Overviews a Perplexity získávají své informace. Tyto platformy necitují pouze stejné zdroje – upřednostňují různé typy obsahu podle svých algoritmů a trénovacích dat. Pochopení těchto platforem specifických vzorců je klíčové pro cílenou strategii obsahu, která maximalizuje viditelnost napříč více AI systémy.
| Platforma | Nejcitovanější zdroj | Podíl citací | Preferovaný formát |
|---|---|---|---|
| ChatGPT | Wikipedia | 7,8 % všech citací | Autoritativní znalostní báze, encyklopedický obsah |
| Google AI Overviews | 2,2 % všech citací | Komunitní diskuse, uživatelsky generovaný obsah | |
| Perplexity | 6,6 % všech citací | Peer-to-peer informace, komunitní postřehy |
Výrazná preference ChatGPT pro Wikipedii (47,9 % z jeho top 10 zdrojů) ukazuje bias k autoritativnímu, faktickému obsahu s ověřenou důvěryhodností. Oproti tomu Google AI Overviews i Perplexity mají vyváženější rozložení, Reddit dominuje jejich schématům citací. To ukazuje, že Perplexity upřednostňuje komunitně tvořené informace v 46,7 % top zdrojů, zatímco Google volí diverzifikovanější přístup napříč více typy platforem. Data jasně ukazují, že univerzální obsahová strategie nefunguje – značky musí svůj přístup přizpůsobit podle toho, na kterých AI platformách jim záleží.
Schema markup je pravděpodobně nejvýznamnějším faktorem pro pravděpodobnost AI citace – správně implementovaný JSON-LD markup dosahuje míry citací o 340 % vyšší než identický obsah bez strukturovaných dat. Tento dramatický rozdíl vychází z toho, jak AI enginy interpretují sémantický význam – strukturovaná data dávají explicitní kontext a odstraňují nejasnosti při interpretaci obsahu. Když AI engine narazí na schema markup, okamžitě rozumí vztahům entit, typům obsahu i hierarchii důležitosti, aniž by se spoléhal pouze na zpracování přirozeného jazyka.
Nejúčinnější implementace zahrnují Article schema pro blogové příspěvky, FAQ schema pro sekce otázek a odpovědí, HowTo schema pro instruktážní obsah a Organization schema pro rozpoznání značky. Formát JSON-LD výrazně překonává ostatní strukturované datové formáty, protože AI enginy jej mohou parsovat nezávisle na HTML obsahu, což umožňuje čistší extrakci dat a snižuje složitost zpracování. Sémantické HTML tagy jako <header>, <nav>, <main>, <section>, a <article> poskytují další jasnost, která pomáhá AI lépe pochopit strukturu a hierarchii obsahu než základní značkování.
A/B testování je nejspolehlivější metodika pro zjištění, které formáty obsahu přinášejí nejvyšší míru AI citací ve vašem konkrétním oboru. Namísto spoléhání na obecná doporučení vám kontrolované experimenty umožní změřit skutečný dopad změn formátu na vaši cílovou skupinu a AI viditelnost. Proces vyžaduje pečlivé plánování pro izolaci proměnných a zajištění statistické platnosti, ale získané poznatky investici ospravedlňují.
Dodržujte tento systematický A/B testing rámec:
Statistická významnost vyžaduje pečlivou pozornost velikosti vzorku a délce testu. U AI aplikací s řídkými daty nebo dlouhým chvostem může být rychlý sběr dostatečných pozorování výzvou. Většina expertů doporučuje testy provozovat alespoň 2–4 týdny, aby se zohlednily časové výkyvy a zajistila spolehlivost výsledků.
Výzkum na tisících AI citací ukazuje jasnou výkonnostní hierarchii mezi různými formáty obsahu. Obsah založený na seznamech získává o 68 % více AI citací než text orientovaný na odstavce, především proto, že seznamy poskytují oddělené, snadno parsovatelné informační jednotky, které AI enginy snadno extrahují a syntetizují. Při generování odpovědí mohou AI platformy přímo odkazovat na konkrétní položky seznamu bez nutnosti složitě přeformulovávat věty, což zvyšuje hodnotu seznamového obsahu pro citace.
Tabulky vykazují výjimečný výkon až s 96% přesností AI parsování, výrazně překonávají popisné texty se stejnými informacemi. Tabulkový obsah umožňuje AI rychle extrahovat konkrétní datové body bez složitého rozboru textu, což činí tabulky obzvlášť cennými pro faktografický, srovnávací nebo statistický obsah. Formáty otázek a odpovědí dosahují o 45 % vyšší AI viditelnosti oproti tradičním odstavcovým textům na stejná témata, protože Q&A formát zrcadlí způsob interakce uživatelů s AI i generování odpovědí AI systémy.
Porovnávací formáty (X vs Y) jsou velmi úspěšné, protože poskytují binární, snadno shrnutelné struktury, které odpovídají způsobu, jakým AI rozvíjí dotazy do podtémat. Případové studie kombinují naraci s daty, což je přesvědčivé pro čtenáře a zároveň interpretovatelné pro AI díky struktuře problém–řešení–výsledek. Originální výzkum a expertní postřehy mají přednostní zacházení, protože přinášejí unikátní data, která jinde nejsou dostupná, a AI je vnímá jako signál důvěryhodnosti. Klíčové zjištění je, že žádný formát není univerzální – nejlepší strategie kombinuje více formátů dle typu obsahu a cílové AI platformy.
Implementace schema markup vyžaduje znalost dostupných typů a výběr těch nejvhodnějších pro váš obsah. Pro blogové příspěvky a články poskytuje Article schema komplexní metadata včetně autora, data publikace a struktury obsahu. FAQ schema je ideální pro sekce otázek a odpovědí, kde explicitně označuje otázky i odpovědi a AI je tak může spolehlivě extrahovat. HowTo schema prospívá instruktážnímu obsahu definováním postupných kroků, zatímco Product schema pomáhá e-shopům komunikovat specifikace a ceny.
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "Jaký je nejlepší formát obsahu pro AI citace?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Nejlepší formát obsahu závisí na vaší platformě a publiku, ale strukturované formáty jako seznamy, tabulky a sekce otázek a odpovědí dosahují konzistentně vyšších mír AI citací. Seznamy získávají o 68 % více citací než odstavce, zatímco tabulky dosahují 96% přesnosti v parsování."
}
}
]
}
Implementace vyžaduje důslednost v syntaxi – neplatný schema markup může šance na AI citace naopak snížit. Pro ověření markupů před zveřejněním používejte Google Rich Results Test nebo validační nástroje Schema.org. Zachovejte konzistentní hierarchii formátování pomocí H2 pro hlavní sekce, H3 pro podbody a krátké odstavce (maximálně 50–75 slov) zaměřené na jeden koncept. Přidávejte TL;DR shrnutí na začátek nebo konec sekcí, abyste AI poskytli hotové snippetové odpovědi.
Měření výkonu AI enginů vyžaduje jiné metriky než tradiční SEO – zaměřte se na sledování citací, míru zařazení do odpovědí a zmínky ve znalostních grafech místo pozic ve výsledcích. Sledování citací napříč hlavními platformami je nejpřímější cestou, jak zjistit, zda vaše testování formátů přináší výsledky, a odhalit, které části obsahu AI skutečně cituje. Nástroje jako AmICited přímo sledují, jak AI platformy citují vaši značku na ChatGPT, Google AI Overviews, Perplexity a dalších answer enginech, a poskytují přehled o vzorcích a trendech citací.
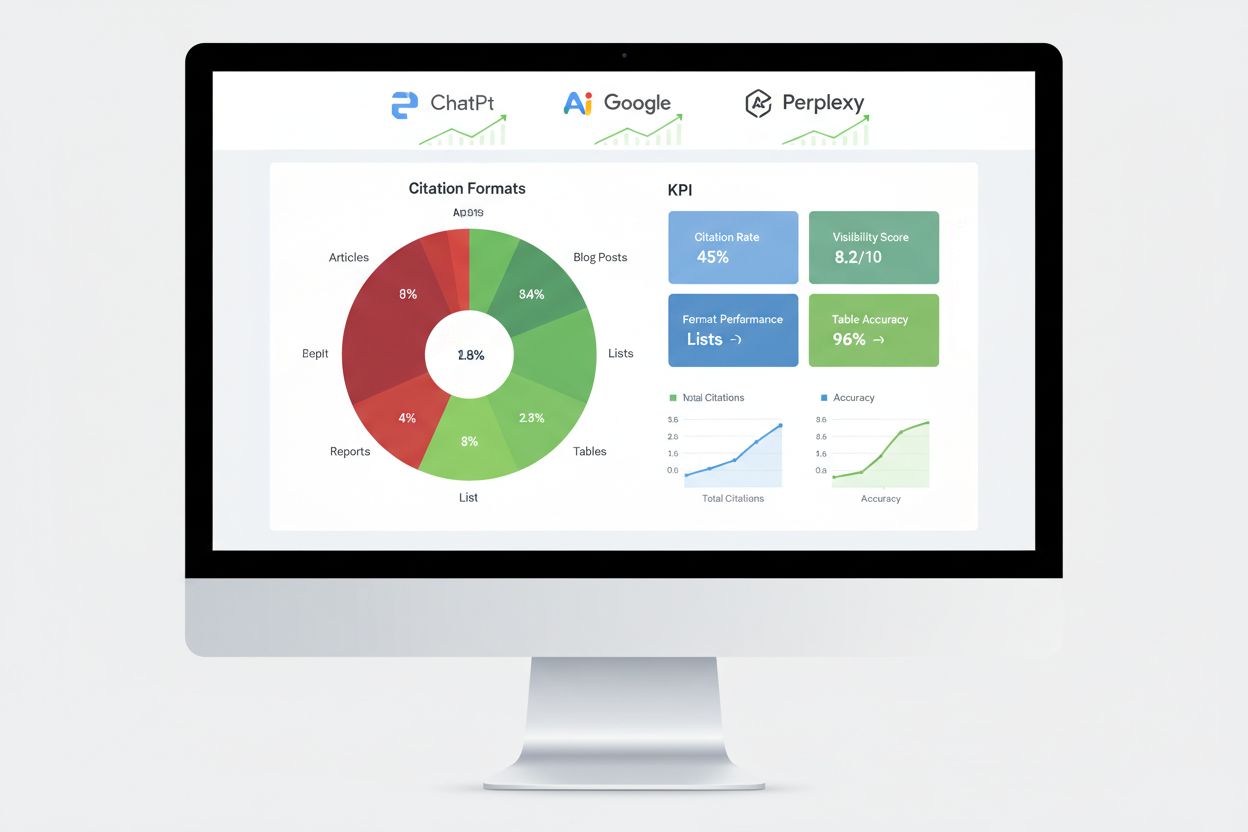
Klíčové metody měření zahrnují sledování míry získání featured snippetů, což ukazuje obsah, který AI považuje za zvlášť hodnotný pro přímé odpovědi. Zobrazení ve znalostních panelech signalizuje, že AI vnímá vaši značku jako autoritativní entitu hodnou vlastní informační karty. Zařazení do výsledků hlasového vyhledávání ukazuje, zda se váš obsah objevuje v konverzačních AI odpovědích, zatímco míra odpovědí generativních enginů měří, jak často AI vaše informace cituje při odpovídání na dotazy uživatelů. A/B testování různých formátů poskytuje nejspolehlivější data o výkonu díky izolaci jednotlivých proměnných. Stanovte základní metriky před změnami a sledujte výkon týdně pro odhalení trendů a anomálií, které mohou značit (ne)úspěšné varianty.
Mnoho organizací při testování formátů opakuje předvídatelné chyby, které ohrožují výsledky a vedou ke špatným závěrům. Nedostatečná velikost vzorku je nejčastější chybou – testování s příliš malým počtem citací či interakcí vede ke statisticky bezvýznamným výsledkům, které se mohou zdát smysluplné, ale jsou náhodné. Zajistěte alespoň 100 citací na variaci a použijte statistické kalkulačky pro přesný výpočet požadovaného vzorku.
Zaměněné proměnné přinášejí bias, když se mění více faktorů zároveň, a pak není jasné, co způsobilo rozdíl. Držte všechny prvky stejné kromě testovaného formátu – zachovejte stejná klíčová slova, délku, strukturu i čas zveřejnění. Časový bias vzniká při testování v atypických obdobích (svátky, mimořádné události, změny algoritmů), což zkresluje výsledky. Testujte v běžném období a minimálně 2–4 týdny pro eliminaci sezónních výkyvů. Výběrový bias nastává, když se testovací skupiny liší způsobem, který ovlivňuje výsledky – zajistěte náhodné přiřazení obsahu k variantám. Zaměňování korelace za kauzalitu vede k falešným závěrům, když vnější faktory náhodně souvisí s obdobím testu. Vždy zvažujte alternativní vysvětlení a validujte výsledky opakovaným testováním před trvalou implementací změn.
Technologická společnost testující formáty obsahu pro AI viditelnost zjistila, že převedením svých srovnávacích článků z odstavcového do strukturovaného tabulkového formátu zvýšila AI citace o 52 % během 60 dní. Tabulky poskytly jasné, snadno skenovatelné informace, které AI mohla přímo extrahovat, zatímco původní text vyžadoval složitější parsování. Délka obsahu i klíčová slova zůstala stejná, jedinou proměnnou byl formát.
Finanční firma zavedla FAQ schema do stávajícího obsahu bez přepisu, pouze přidala strukturované značky ke stávajícím otázkám a odpovědím. Výsledkem bylo 34% zvýšení počtu featured snippetů a 28% nárůst AI citací během 45 dní. Schema markup nezměnil samotný obsah, ale výrazně usnadnil AI jeho identifikaci a extrakci odpovědí. SaaS firma provedla multivariační test tří formátů – seznamy, tabulky a tradiční odstavce – pro stejný obsah o vlastnostech produktu. Výsledky ukázaly, že seznamy překonaly odstavce o 68 %, tabulky měly nejvyšší přesnost parsování AI, ale nižší celkový objem citací. To dokládá, že efektivita formátu závisí na typu obsahu a AI platformě a že testování je nezbytné místo spoléhání na obecné rady. Tyto příklady potvrzují, že správně provedené testování formátů přináší měřitelnou a významnou podporu AI viditelnosti.
Oblast testování formátů obsahu se neustále vyvíjí s tím, jak jsou AI systémy sofistikovanější a objevují se nové optimalizační techniky. Algoritmy multi-armed bandit představují významný pokrok oproti tradičnímu A/B testování, protože dynamicky přerozdělují návštěvnost mezi varianty podle reálného výkonu místo čekání na konec testovacího období. Tento přístup zkracuje čas potřebný k nalezení vítězné varianty a maximalizuje výkon i během samotného testu.
Adaptivní experimentování poháněné reinforcement learningem umožňuje AI modelům průběžně se učit a přizpůsobovat na základě aktuálních experimentů, zlepšovat výkon v reálném čase místo v oddělených testovacích cyklech. AI automatizace v A/B testování sama navrhuje experimenty, analyzuje výsledky i doporučuje optimalizace, což umožňuje testovat více variant současně bez úměrného růstu složitosti. Tyto inovace slibují rychlejší iterace a propracovanější optimalizační strategie. Organizace, které zvládnou testování formátu obsahu dnes, si udrží náskok, až se tyto pokročilé metody stanou standardem, a budou lépe připravené využít nové AI platformy a měnící se algoritmy citací dříve než konkurence.
Nejlepší formát obsahu závisí na vaší platformě a publiku, ale strukturované formáty jako seznamy, tabulky a sekce otázek a odpovědí dosahují konzistentně vyšších mír AI citací. Seznamy získávají o 68 % více citací než odstavce, zatímco tabulky dosahují 96% přesnosti v parsování. Klíčem je testovat různé formáty na vašem konkrétním obsahu a zjistit, co funguje nejlépe.
Většina expertů doporučuje provádět testy alespoň 2–4 týdny, aby se zohlednily časové výkyvy a byla zajištěna spolehlivost výsledků. Tato doba vám umožní nasbírat dostatečný počet datových bodů (obvykle 100+ citací na variaci) a zohlednit sezónní výkyvy nebo změny algoritmů, které mohou výsledky zkreslit.
Ano, můžete provádět multivariační testování napříč více formáty současně, ale to vyžaduje pečlivé plánování, aby nedošlo ke zkomplikování interpretace výsledků. Začněte jednoduchými A/B testy dvou formátů a po zvládnutí základů a zajištění dostatečných statistických zdrojů přejděte na multivariační testování.
Obvykle potřebujete alespoň 100 citací nebo interakcí na každou variaci, abyste dosáhli statistické významnosti. Pro přesný výpočet velikosti vzorku pro vaši požadovanou úroveň spolehlivosti a velikost efektu použijte statistické kalkulačky. Větší vzorky poskytují spolehlivější výsledky, ale vyžadují delší dobu testování.
Začněte identifikací nejrelevantnějšího typu schématu pro váš obsah (Article, FAQ, HowTo atd.), následně jej implementujte ve formátu JSON-LD. Před zveřejněním validujte svůj markup pomocí Google Rich Results Test nebo validačních nástrojů Schema.org. Neplatný schema markup může vašim šancím na citace u AI dokonce uškodit, proto je přesnost klíčová.
Prioritizujte podle svého publika a obchodních cílů. ChatGPT preferuje autoritativní zdroje jako Wikipedii, Google AI Overviews dává přednost komunitnímu obsahu typu Reddit a Perplexity zdůrazňuje peer-to-peer informace. Analyzujte, které platformy přivádějí na váš web nejrelevantnější návštěvnost a optimalizujte nejprve pro ně.
Zařaďte kontinuální testování do své obsahové strategie. Začněte čtvrtletními cykly testování formátů a s narůstající odborností a zavedením základních metrik frekvenci zvyšujte. Pravidelné testování vám pomůže držet krok se změnami algoritmů AI platforem a odhalit nové preference formátů.
Sledujte zlepšení míry citací, získání featured snippetů, zobrazení ve znalostních panelech a míry odpovědí generativních enginů. Před testováním stanovte základní metriky a poté sledujte výkon týdně pro odhalení trendů. Úspěšný test obvykle do 4–8 týdnů přináší zlepšení primární metriky o 20 % a více.
Sledujte, jak AI platformy citují váš obsah v různých formátech. Zjistěte, které struktury obsahu přinášejí největší AI viditelnost a optimalizujte svou strategii na základě reálných dat.
Zjistěte, jak strukturovat svůj obsah, abyste získali citace od AI vyhledávačů jako ChatGPT, Perplexity a Google AI. Odborné strategie pro viditelnost a citace ...
Zjistěte, které formáty obsahu jsou nejčastěji citovány AI modely. Analyzujte data z více než 768 000 AI citací a optimalizujte svou obsahovou strategii pro Cha...
Zjistěte, jak optimalizovat čitelnost obsahu pro AI systémy, ChatGPT, Perplexity a AI vyhledávače. Objevte nejlepší postupy pro strukturu, formátování a jasnost...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.