
AI správa obsahu
Zjistěte více o AI správě obsahu – o zásadách, procesech a rámcích, které organizace používají k řízení obsahové strategie napříč AI platformami při zachování k...
8 min čtení
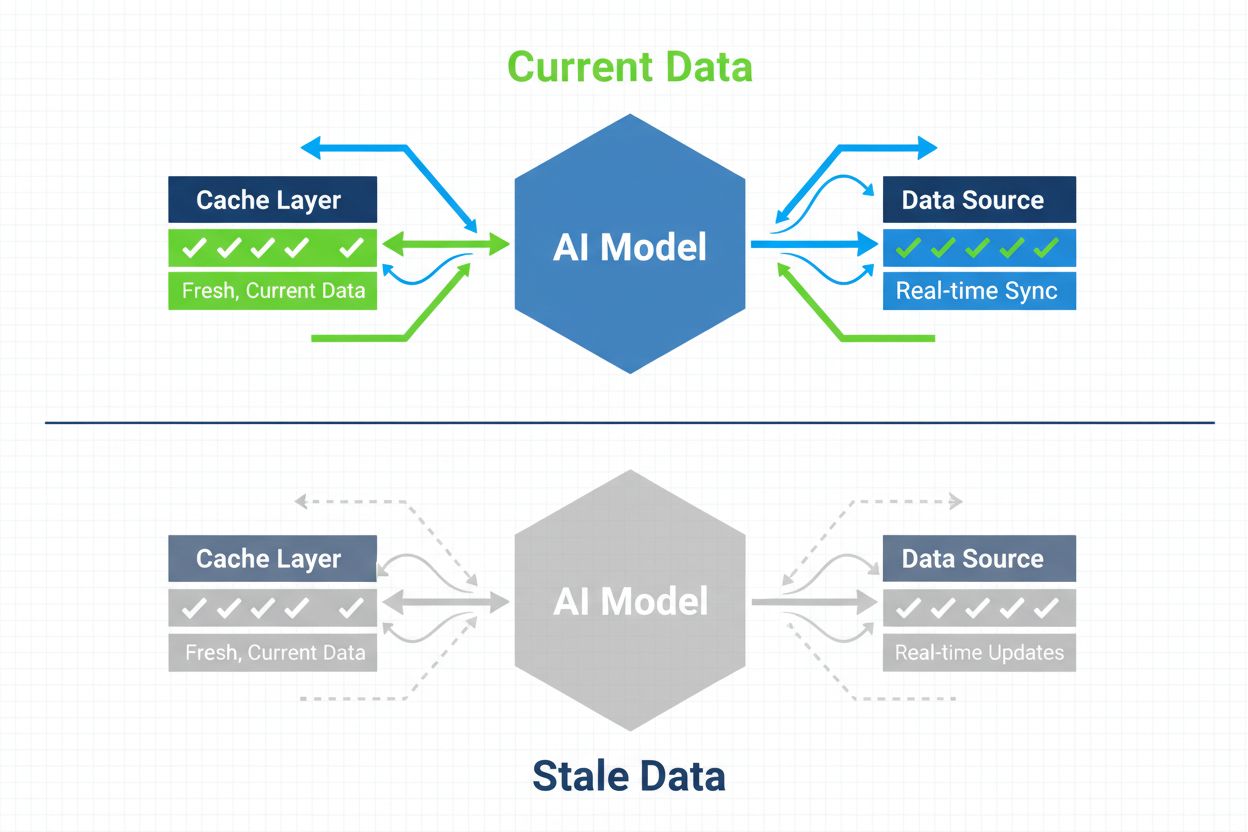
Strategie zajišťující, aby měly AI systémy přístup k aktuálnímu obsahu místo zastaralých verzí v cache. Správa cache vyvažuje výkonové výhody cachování proti riziku poskytování neaktuálních informací pomocí strategií invalidace a monitorování pro udržení čerstvosti dat při současném snižování latence a nákladů.
Strategie zajišťující, aby měly AI systémy přístup k aktuálnímu obsahu místo zastaralých verzí v cache. Správa cache vyvažuje výkonové výhody cachování proti riziku poskytování neaktuálních informací pomocí strategií invalidace a monitorování pro udržení čerstvosti dat při současném snižování latence a nákladů.
Správa AI cache označuje systematický přístup k ukládání a zpětnému získávání již vypočítaných výsledků, výstupů modelu nebo odpovědí API za účelem eliminace zbytečného zpracování a snížení latence v systémech umělé inteligence. Klíčovou výzvou je vyvážení výkonových přínosů cachovaných dat oproti riziku poskytování zastaralých nebo neaktuálních informací, které již nereflektují aktuální stav systému či požadavky uživatelů. Toto je obzvlášť kritické u velkých jazykových modelů (LLM) a AI aplikací, kde jsou náklady na inferenci vysoké a odezva přímo ovlivňuje uživatelský zážitek. Systémy správy cache musí inteligentně rozhodovat, kdy zůstávají cachované výsledky platné a kdy je nutné nové výpočty, což z této problematiky činí zásadní architektonickou otázku produkčních AI nasazení.
Dopad efektivní správy cache na výkon AI systémů je významný a měřitelný v několika ohledech. Zavedení strategií cachování může snížit latenci odpovědí o 80–90 % u opakovaných dotazů a současně zredukovat náklady na API o 50–90 % v závislosti na míře zásahů do cache a architektuře systému. Nad rámec samotných výkonových metrik správa cache přímo ovlivňuje konzistenci přesnosti a spolehlivost systému, protože správně invalidované cache zajišťují uživatelům aktuální informace, zatímco špatná správa cache vede k problémům se zastaralostí dat. Tyto přínosy nabývají na důležitosti s růstem AI systémů na miliony požadavků, kdy kumulativní efekt efektivity cache přímo určuje náklady na infrastrukturu a spokojenost uživatelů.
| Aspekt | S cache | Bez cache |
|---|---|---|
| Doba odezvy | o 80–90 % rychlejší | Výchozí stav |
| Náklady na API | o 50–90 % nižší | Plné náklady |
| Přesnost | Konzistentní | Proměnlivá |
| Škálovatelnost | Vysoká | Omezená |
Strategie invalidace cache určují, jak a kdy se cachovaná data obnovují nebo odstraňují ze skladu, a představují jedno z nejdůležitějších rozhodnutí při návrhu cache architektury. Různé přístupy k invalidaci přinášejí různé kompromisy mezi čerstvostí dat a výkonem systému:
Volba strategie invalidace závisí především na požadavcích aplikace: systémy upřednostňující přesnost dat mohou přijmout vyšší latenci skrze agresivní invalidaci, zatímco na výkon zaměřené aplikace mohou tolerovat mírně zastaralá data pro zachování submilisekundových odezev.
Prompt caching ve velkých jazykových modelech představuje specializovanou aplikaci správy cache, kdy se ukládají mezistavy modelu a sekvence tokenů, aby se zabránilo opakovanému zpracování totožných nebo podobných vstupů. LLM podporují dva hlavní přístupy: přesné cachování, které odpovídá promptům znak po znaku, a sémantické cachování, které rozpozná funkčně ekvivalentní prompty s odlišným zněním. OpenAI implementuje automatické prompt caching s 50% snížením nákladů na cachované tokeny, přičemž je nutné minimálně 1024 tokenů v promptu pro aktivaci cachování. Anthropic nabízí manuální prompt caching s ještě výraznějším 90% snížením nákladů, ale vyžaduje, aby vývojáři spravovali cache klíče a dobu uložení, s minimálním požadavkem na cache v rozsahu 1024–2048 tokenů dle konfigurace modelu. Doba uložení cache v LLM systémech se obvykle pohybuje od několika minut po hodiny, což vyvažuje výpočetní úspory z opětovného využití mezistavů a riziko poskytování zastaralých výstupů modelu u časově citlivých aplikací.
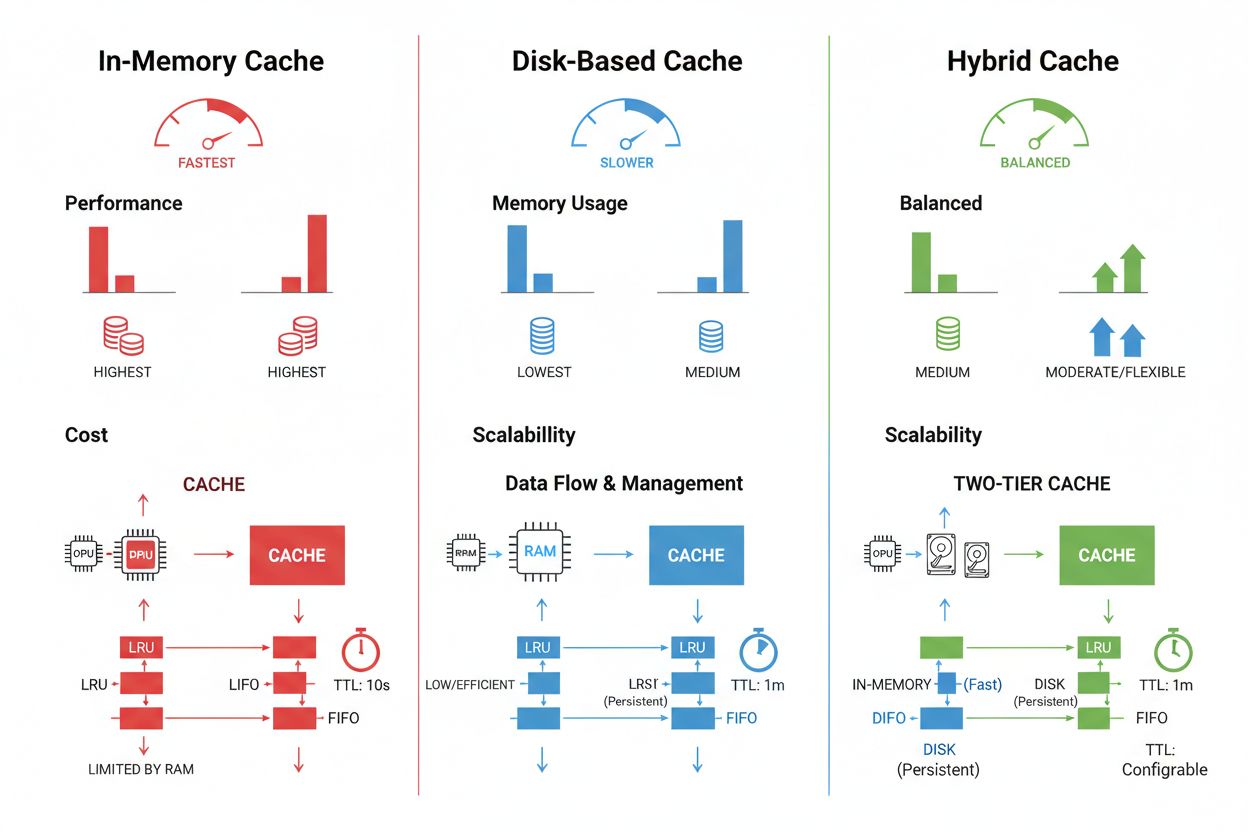
Techniky ukládání a správy cache se výrazně liší podle požadavků na výkon, objem dat a limitů infrastruktury; každá z nich má své výhody i omezení. In-memory řešení jako Redis nabízejí přístup v řádu mikrosekund, což je ideální pro frekventované dotazy, ale spotřebovávají značné množství RAM a vyžadují pečlivou správu paměti. Disková cache pojme větší objemy dat a přetrvává i po restartu systému, ale oproti paměťovým alternativám přináší latenci v řádu milisekund. Hybridní přístupy kombinují oba typy úložišť, často dotazovaná data ukládají do paměti a větší dataset na disk:
| Typ úložiště | Nejvhodnější pro | Výkon | Využití paměti |
|---|---|---|---|
| In-memory (Redis) | Časté dotazy | Nejrychlejší | Vyšší |
| Disková | Velké objemy dat | Střední | Nižší |
| Hybridní | Smíšené zátěže | Vyvážený | Vyvážený |
Efektivní správa cache vyžaduje vhodné nastavení TTL, které odráží volatilitu dat – krátké TTL (minuty) pro rychle se měnící data a delší TTL (hodiny/dny) pro stabilní obsah – spolu s kontinuálním monitorováním míry zásahů do cache, vzorců vytěsňování a využití paměti pro identifikaci možností optimalizace.
Reálné AI aplikace ukazují jak transformační potenciál, tak provozní složitost správy cache napříč různými scénáři. Chatboti pro zákaznický servis využívají cache pro konzistentní odpovědi na časté dotazy a snižují tím náklady na inferenci o 60–70 %, což umožňuje nákladově efektivní škálování na tisíce souběžných uživatelů. Asistenti pro programování cachují běžné vzory kódu a úryvky dokumentace, což umožňuje vývojářům získávat návrhy na doplnění kódu s latencí pod 100 ms i v době špiček. Systémy pro zpracování dokumentů cachují embeddingy a sémantické reprezentace často analyzovaných dokumentů, čímž výrazně urychlují vyhledávání podobností a klasifikační úlohy. Produkční správa cache však přináší významné výzvy: složitost invalidace roste exponenciálně v distribuovaných systémech, kde je třeba udržovat konzistenci cache napříč více servery, omezení zdrojů nutí dělat těžká rozhodnutí ohledně velikosti a pokrytí cache, objevují se bezpečnostní rizika při cachování citlivých dat vyžadujících šifrování a řízení přístupu a koordinace aktualizací cache napříč mikroslužbami může vést k závodům a nekonzistencím dat. Nezbytné jsou komplexní monitorovací nástroje, které sledují čerstvost cache, míru zásahů a události invalidace, aby byla zajištěna spolehlivost systému a bylo možné včas upravit strategie cache na základě změn ve vzorcích dat a chování uživatelů.
Invalidace cache odstraní nebo aktualizuje zastaralá data při změně, což poskytuje okamžitou čerstvost, ale vyžaduje spouštění na základě událostí. Expirace cache nastavuje časový limit (TTL), po který data zůstávají v cache, což je jednodušší na implementaci, ale může vést k poskytování zastaralých dat, pokud je TTL příliš dlouhý. Mnoho systémů kombinuje oba přístupy pro optimální výkon.
Efektivní správa cache může snížit náklady na API o 50-90 % v závislosti na míře zásahů do cache a architektuře systému. Prompt cache od OpenAI nabízí 50% snížení nákladů na cachované tokeny, zatímco Anthropic poskytuje až 90% úsporu. Skutečné úspory závisí na vzorcích dotazů a na tom, kolik dat lze efektivně cachovat.
Prompt caching ukládá mezistavy modelu a sekvence tokenů, aby se zabránilo opětovnému zpracování totožných nebo podobných vstupů ve velkých jazykových modelech. Podporuje přesné cachování (shoda znak po znaku) i sémantické cachování (funkčně ekvivalentní prompty s různým zněním). To snižuje latenci až o 80 % a náklady o 50-90 % u opakovaných dotazů.
Hlavními strategiemi jsou: časově řízená expirace (TTL) pro automatické odstranění po stanovené době, invalidace na základě událostí pro okamžité aktualizace při změně dat, sémantická invalidace pro podobné dotazy na základě významu a hybridní přístupy kombinující více strategií. Výběr závisí na proměnlivosti dat a požadavcích na čerstvost.
In-memory cache (například Redis) poskytuje přístup v řádu mikrosekund, ideální pro časté dotazy, ale spotřebovává značné množství RAM. Disková cache pojme větší objemy dat a přetrvává i po restartu systému, ale přináší latenci v řádu milisekund. Hybridní přístupy kombinují obě varianty, často dotazovaná data ukládají do paměti a větší objemy na disk.
TTL je odpočítávací časovač, který určuje, jak dlouho zůstane cachovaná data platná před expirací. Krátké TTL (minuty) jsou vhodné pro rychle se měnící data, delší TTL (hodiny/dny) pro stabilní obsah. Správná konfigurace TTL vyvažuje čerstvost dat s nutností zbytečných obnov cache a zátěží serveru.
Efektivní správa cache umožňuje AI systémům zpracovávat výrazně více požadavků bez nutnosti úměrného rozšiřování infrastruktury. Snížením výpočetní zátěže na požadavek díky cachování mohou systémy obsluhovat miliony uživatelů nákladově efektivněji. Míra zásahů do cache přímo určuje náklady na infrastrukturu a spokojenost uživatelů v produkčním nasazení.
Cachování citlivých dat přináší bezpečnostní zranitelnosti, pokud nejsou správně šifrována a kontrolována oprávnění k přístupu. Hrozí neoprávněný přístup k cachovaným informacím, únik dat při invalidaci cache a nechtěné cachování důvěrného obsahu. Pro ochranu citlivých dat v cache je nezbytné šifrování, řízení přístupu a monitorování.
AmICited sleduje, jak AI systémy odkazují na vaši značku a zajišťuje, že váš obsah zůstává v AI cache aktuální. Získejte přehled o správě AI cache a čerstvosti obsahu napříč GPT, Perplexity a Google AI Overviews.
Zjistěte více o AI správě obsahu – o zásadách, procesech a rámcích, které organizace používají k řízení obsahové strategie napříč AI platformami při zachování k...

Zjistěte, jak spravovat přístup AI crawlerů k obsahu vašeho webu. Poznejte rozdíl mezi tréninkovými a vyhledávacími crawlery, implementujte ovládání přes robots...

Diskuze komunity o tom, jak znalostní báze a strukturované repozitáře obsahu pomáhají zlepšit AI citace. Skutečné strategie pro tvorbu obsahu přívětivého pro RA...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.