
Skórování relevance obsahu
Zjistěte, jak skórování relevance obsahu využívá AI algoritmy k měření shody obsahu s uživatelskými dotazy a záměrem. Pochopte BM25, TF-IDF a jak vyhledávače a ...
7 min čtení

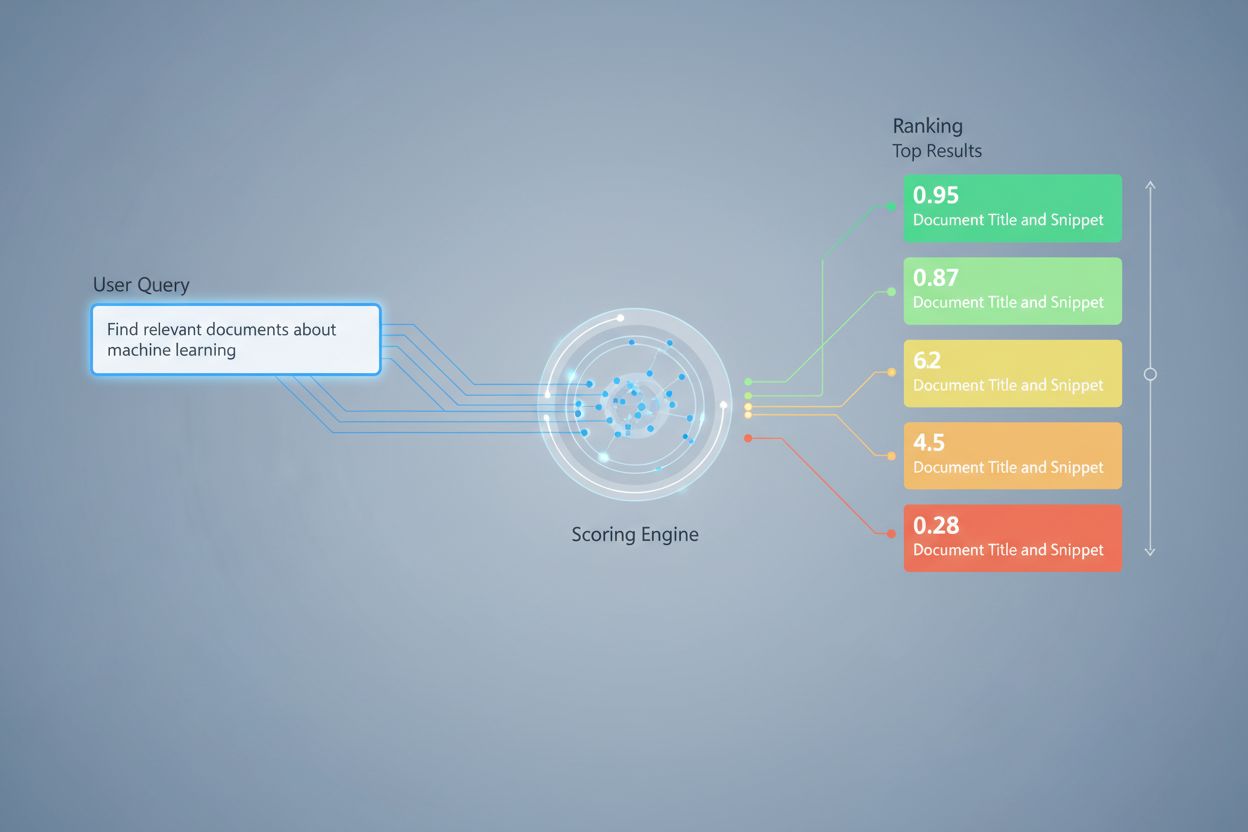
Skórování vyhledávání pomocí AI je proces kvantifikace relevance a kvality nalezených dokumentů nebo pasáží ve vztahu k uživatelskému dotazu. Využívá sofistikované algoritmy k posouzení sémantického významu, kontextové vhodnosti a kvality informací, a rozhoduje, které zdroje budou předány jazykovým modelům pro generování odpovědí v RAG systémech.
Skórování vyhledávání pomocí AI je proces kvantifikace relevance a kvality nalezených dokumentů nebo pasáží ve vztahu k uživatelskému dotazu. Využívá sofistikované algoritmy k posouzení sémantického významu, kontextové vhodnosti a kvality informací, a rozhoduje, které zdroje budou předány jazykovým modelům pro generování odpovědí v RAG systémech.
Skórování vyhledávání pomocí AI je proces kvantifikace relevance a kvality nalezených dokumentů nebo pasáží ve vztahu k uživatelskému dotazu či úkolu. Na rozdíl od jednoduchého porovnávání klíčových slov, které identifikuje pouze povrchovou shodu termínů, skórování vyhledávání využívá sofistikované algoritmy k posouzení sémantického významu, kontextové vhodnosti a kvality informací. Tento mechanismus skórování je základním kamenem systémů Retrieval-Augmented Generation (RAG), kde určuje, které zdroje budou předány jazykovým modelům pro generování odpovědí. V moderních LLM aplikacích má skórování vyhledávání přímý dopad na přesnost odpovědí, snížení halucinací a spokojenost uživatelů tím, že k fázi generování propouští pouze nejrelevantnější informace. Kvalita skórování vyhledávání je proto zásadní součástí celkového výkonu a spolehlivosti systému.
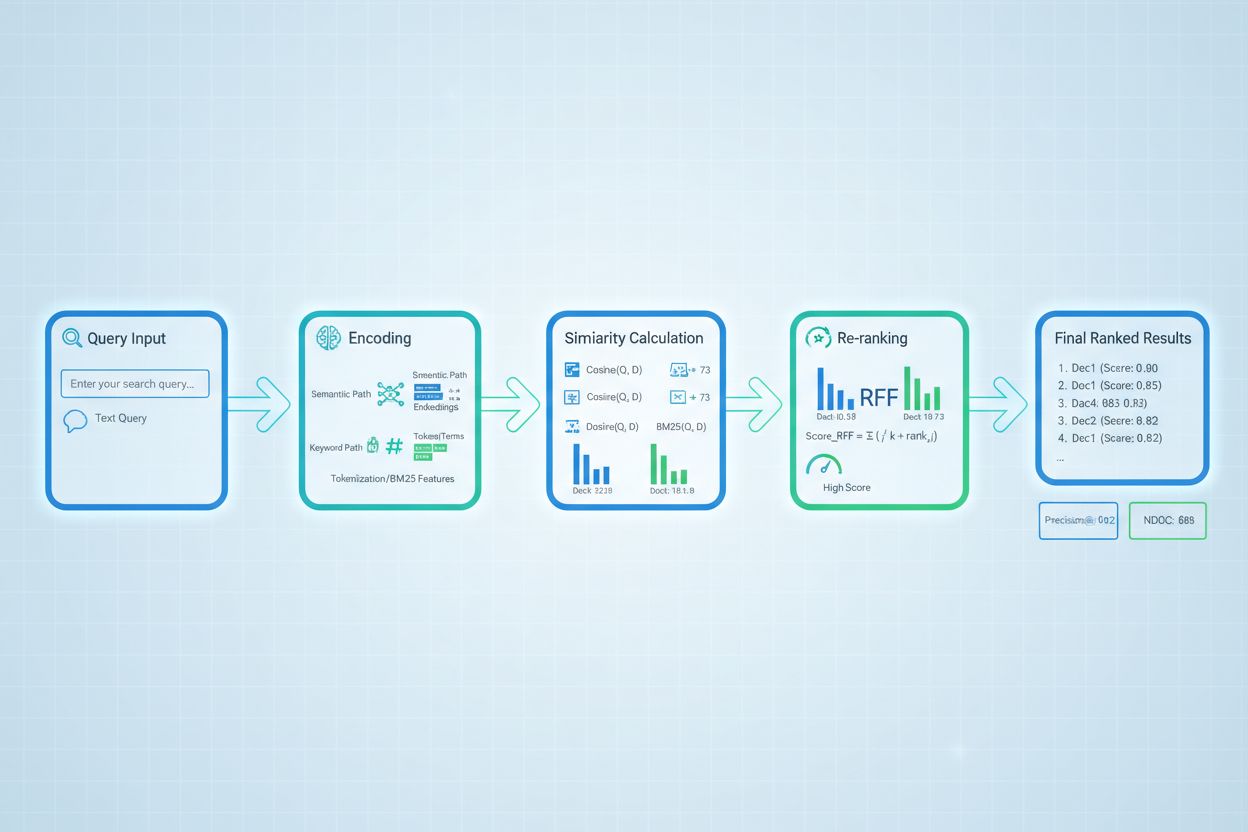
Skórování vyhledávání využívá několik algoritmických přístupů, z nichž každý má své silné stránky pro různé případy použití. Sémantické skórování podobnosti využívá embeddingové modely k měření pojmové shody mezi dotazy a dokumenty ve vektorovém prostoru, a zachycuje tak význam přesahující povrchová klíčová slova. BM25 (Best Matching 25) je pravděpodobnostní funkce řazení, která zohledňuje četnost termínů, inverzní četnost dokumentů a normalizaci délky dokumentu, což ji činí velmi účinnou pro tradiční textové vyhledávání. TF-IDF (Term Frequency-Inverse Document Frequency) váží termíny podle jejich důležitosti v dokumentu a napříč kolekcemi, ale postrádá sémantické porozumění. Hybridní přístupy kombinují více metod—například spojení skóre BM25 a sémantického skóre—aby využily jak lexikální, tak sémantické signály. Mimo samotné metody skórování poskytují hodnotící metriky jako Precision@k (procento relevantních výsledků v top-k), Recall@k (procento všech relevantních dokumentů nalezených v top-k), NDCG (Normalized Discounted Cumulative Gain, zohledňující pozici v řazení) a MRR (Mean Reciprocal Rank) kvantitativní měřítka kvality vyhledávání. Pochopení výhod a nevýhod jednotlivých přístupů—například efektivity BM25 oproti hlubšímu porozumění sémantického skórování—je klíčové pro výběr vhodných metod pro konkrétní aplikace.
| Metoda skórování | Jak funguje | Nejvhodnější pro | Klíčová výhoda |
|---|---|---|---|
| Sémantická podobnost | Porovnává embeddingy pomocí kosinové podobnosti nebo jiných distančních metrik | Pojmový význam, synonyma, parafráze | Zachycuje sémantické vztahy nad rámec klíčových slov |
| BM25 | Pravděpodobnostní řazení zohledňující četnost termínů a délku dokumentu | Přesné shody frází, dotazy podle klíčových slov | Rychlé, efektivní, ověřené v praxi |
| TF-IDF | Váží termíny podle četnosti v dokumentu a vzácnosti v kolekci | Tradiční informační vyhledávání | Jednoduché, srozumitelné, nenáročné |
| Hybridní skórování | Kombinuje sémantické a lexikální přístupy váženou fúzí | Obecné vyhledávání, složité dotazy | Využívá silné stránky více metod |
| Skórování pomocí LLM | Používá jazykové modely k hodnocení relevance pomocí vlastních promptů | Složité kontextové hodnocení, oborově specifické úlohy | Zachycuje jemné sémantické vztahy |
V RAG systémech funguje skórování vyhledávání na několika úrovních, aby byla zajištěna kvalita generování. Systém obvykle skóruje jednotlivé chuncky nebo pasáže v dokumentech, což umožňuje jemnozrnný odhad relevance namísto posuzování celých dokumentů jako atomických jednotek. Toto skórování relevance na úrovni chunků umožňuje systému extrahovat pouze nejpodstatnější segmenty informací, čímž se snižuje šum a nerelevantní kontext, který by mohl jazykový model zmást. RAG systémy často implementují práhy skóre nebo cutoff mechanismy, které filtrují výsledky s nízkým skóre ještě před fází generování, a tím zabraňují, aby nekvalitní zdroje ovlivnily finální odpověď. Kvalita získaného kontextu přímo koreluje s kvalitou generování—vysoce skórované, relevantní pasáže vedou k přesnějším, podloženým odpovědím, zatímco nekvalitní retrieval zavádí halucinace a faktické chyby. Sledování skóre vyhledávání poskytuje včasné signály degradace systému, což z něj činí klíčovou metriku pro monitoring AI odpovědí a zajištění kvality v produkčních systémech.
Re-ranking slouží jako druhý filtr, který zpřesňuje původní výsledky vyhledávání a často výrazně zlepšuje přesnost řazení. Po prvotním získání kandidátních výsledků s předběžnými skóre aplikuje re-ranker sofistikovanější logiku pro nové řazení nebo filtrování těchto kandidátů, většinou pomocí výpočetně náročnějších modelů, které si mohou dovolit hlubší analýzu. Reciprocal Rank Fusion (RRF) je populární technika, jež kombinuje pořadí z více vyhledávačů přiřazením skóre podle pozice výsledku a následným sloučením těchto skóre do jednotného pořadí, které často překonává jednotlivé vyhledávače. Normalizace skóre je zásadní při kombinování výsledků různých metod, protože surová skóre z BM25, sémantické podobnosti a dalších přístupů bývají na různých škálách a musí být převedena do srovnatelných rozsahů. Ensemble přístupy využívají současně více retrieval strategií, přičemž re-ranking rozhoduje o finálním pořadí na základě kombinovaných důkazů. Tento vícefázový přístup výrazně zlepšuje přesnost a robustnost sestavení pořadí oproti jednofázovému retrievalu, zejména v náročných doménách, kde různé metody zachycují komplementární signály relevance.
Precision@k: Měří podíl relevantních dokumentů mezi top-k výsledky; užitečné pro posouzení důvěryhodnosti (např. Precision@5 = 4/5 znamená, že 80 % z top-5 výsledků je relevantních)
Recall@k: Vypočítává procento všech relevantních dokumentů nalezených mezi top-k; důležité pro zajištění úplnosti pokrytí relevantních informací
Hit Rate: Binární metrika indikující, zda se alespoň jeden relevantní dokument objevil mezi top-k výsledky; vhodná pro rychlé kontroly kvality v produkčních systémech
NDCG (Normalized Discounted Cumulative Gain): Zohledňuje pozici v pořadí tím, že vyšší hodnotu přiděluje relevantním dokumentům na předních místech; pohybuje se v rozmezí 0-1 a je ideální pro hodnocení kvality řazení
MRR (Mean Reciprocal Rank): Měří průměrnou pozici prvního relevantního výsledku napříč více dotazy; zvlášť užitečné pro posouzení, zda se nejrelevantnější dokument umisťuje vysoko
F1 skóre: Harmonický průměr přesnosti a úplnosti; poskytuje vyvážené hodnocení, pokud jsou falešně pozitivní i negativní výsledky stejně důležité
MAP (Mean Average Precision): Průměruje hodnoty přesnosti na každé pozici, kde je nalezen relevantní dokument; komplexní metrika pro celkovou kvalitu pořadí napříč více dotazy
Skórování relevance pomocí LLM využívá samotné jazykové modely jako hodnotitele relevance dokumentů a nabízí tak flexibilní alternativu k tradičním algoritmickým přístupům. V tomto paradigmatu pečlivě sestavené prompty instruují LLM, aby posoudil, zda nalezená pasáž odpovídá na zadaný dotaz, a generuje buď binární skóre relevance (relevantní/nerelavantní), nebo číselné skóre (např. na škále 1–5 podle síly relevance). Tento přístup zachycuje jemné sémantické vztahy a oborově specifickou relevanci, kterou tradiční algoritmy mohou přehlédnout, zejména u složitých dotazů vyžadujících hluboké porozumění. Skórování pomocí LLM však přináší výzvy včetně výpočetní náročnosti (inference LLM je nákladnější než embeddingová podobnost), možné nekonzistence mezi různými prompty a modely, a potřeby kalibrace pomocí lidských hodnocení pro zajištění souladu skóre se skutečnou relevancí. Navzdory těmto omezením se skórování LLM osvědčilo při vyhodnocování kvality RAG systémů i při tvorbě trénovacích dat pro specializované skórovací modely, což z něj činí důležitý nástroj pro monitoring kvality AI odpovědí.
Úspěšná implementace skórování vyhledávání vyžaduje pečlivé zvážení několika praktických aspektů. Výběr metody závisí na požadavcích použití: sémantické skórování vyniká v pochopení významu, ale vyžaduje embeddingové modely, zatímco BM25 nabízí rychlost a efektivitu pro lexikální shodu. Klíčovým faktorem je kompromis mezi rychlostí a přesností—embeddingové skórování poskytuje lepší pochopení relevance, ale přináší latenci, zatímco BM25 a TF-IDF jsou rychlejší, ale méně sémanticky sofistikované. Výpočetní náklady zahrnují čas inference modelu, nároky na paměť a potřeby škálování infrastruktury, což je zvlášť důležité pro produkční systémy s vysokým objemem dotazů. Ladění parametrů znamená nastavování práhů, vah v hybridních přístupech a cutoffů pro re-ranking s cílem optimalizovat výkon pro konkrétní obory a použití. Průběžné sledování výkonu skórování pomocí metrik jako NDCG a Precision@k pomáhá včas odhalit degradaci, umožňuje proaktivní vylepšení systému a zajišťuje konzistentní kvalitu odpovědí v produkčních RAG systémech.
Pokročilé techniky skórování vyhledávání posouvají hodnocení relevance za základní úroveň a umožňují zachytit složité kontextové vztahy. Přepisování dotazů může zlepšit skórování přeformulováním uživatelských dotazů do více sémanticky ekvivalentních variant, což umožní vyhledávači nalézt relevantní dokumenty, které by doslovné zadání minulo. Hypotetické embeddingy dokumentů (HyDE) generují syntetické relevantní dokumenty z dotazů a tyto hypotetické využívají ke zlepšení skórování nalezením skutečných dokumentů podobných ideálním relevantním obsahům. Vícedotazové přístupy posílají více variant dotazu do vyhledávačů a agregují jejich skóre, což zvyšuje robustnost a pokrytí oproti retrievalu s jediným dotazem. Oborově specifické skórovací modely trénované na označených datech z konkrétních odvětví nebo znalostních domén dosahují lepšího výkonu než obecné modely, což je zvlášť cenné pro specializované aplikace, jako jsou medicínské nebo právní AI systémy. Kontextové úpravy skóre zohledňují faktory jako aktuálnost dokumentu, autoritu zdroje a uživatelský kontext, což umožňuje sofistikovanější odhad relevance přesahující čistě sémantickou podobnost a reflektující reálné faktory důležité pro nasazení AI v produkci.
Skórování vyhledávání přiřazuje dokumentům číselné hodnoty relevance podle jejich vztahu k dotazu, zatímco řazení uspořádává dokumenty podle těchto skóre. Skórování je hodnotící proces, řazení je výsledek tohoto procesu. Oba kroky jsou v RAG systémech nezbytné pro přesné odpovědi.
Skórování vyhledávání rozhoduje, které zdroje se dostanou k jazykovému modelu pro generování odpovědi. Kvalitní skórování zajišťuje výběr relevantních informací, snižuje halucinace a zlepšuje přesnost odpovědí. Špatné skórování vede k nerelevantnímu kontextu a nespolehlivým AI odpovědím.
Sémantické skórování využívá embeddingy k pochopení pojmového významu a zachytává synonyma i související pojmy. Skórování podle klíčových slov (například BM25) porovnává přesná slova a fráze. Sémantické skórování je lepší pro pochopení záměru, skórování podle klíčových slov vyniká ve vyhledání konkrétních informací.
Klíčové metriky zahrnují Precision@k (přesnost nejlepších výsledků), Recall@k (pokrytí relevantních dokumentů), NDCG (kvalita řazení) a MRR (pozice prvního relevantního výsledku). Zvolte metriky podle svého použití: Precision@k pro kvalitu, Recall@k pro úplnost pokrytí.
Ano, skórování pomocí LLM využívá jazykové modely jako hodnotitele relevance. Tento přístup zachycuje jemné sémantické vztahy, ale je výpočetně náročný. Je užitečný pro vyhodnocení kvality RAG a tvorbu trénovacích dat, přičemž vyžaduje kalibraci podle lidských hodnocení.
Re-ranking aplikuje druhé kolo filtrování pomocí sofistikovanějších modelů pro zpřesnění výsledků. Techniky jako Reciprocal Rank Fusion kombinují více metod vyhledávání a zvyšují přesnost a robustnost. Re-ranking výrazně překonává jednofázové vyhledávání v komplexních oblastech.
BM25 a TF-IDF jsou rychlé a nenáročné, vhodné pro systémy v reálném čase. Sémantické skórování vyžaduje inferenci embedding modelu, což zvyšuje latenci. Skórování pomocí LLM je nejdražší. Výběr závisí na požadavcích na zpoždění a dostupných výpočetních zdrojích.
Zvažte priority: sémantické skórování pro úkoly zaměřené na význam, BM25 pro rychlost a efektivitu, hybridní přístupy pro vyvážený výkon. Vyhodnocujte na svém oboru pomocí metrik jako NDCG a Precision@k. Testujte více metod a měřte jejich dopad na kvalitu výsledné odpovědi.
Sledujte, jak AI systémy jako ChatGPT, Perplexity a Google AI odkazují na vaši značku a vyhodnocují kvalitu jejich vyhledávání a řazení zdrojů. Zajistěte si správné citování a umístění svého obsahu v AI systémech.
Zjistěte, jak skórování relevance obsahu využívá AI algoritmy k měření shody obsahu s uživatelskými dotazy a záměrem. Pochopte BM25, TF-IDF a jak vyhledávače a ...

Zjistěte, co znamenají skóre čitelnosti pro viditelnost ve vyhledávání pomocí AI. Objevte, jak Flesch-Kincaid, struktura vět a formátování obsahu ovlivňují cita...
Zjistěte, co jsou AI vyhledávače, jak se liší od tradičního vyhledávání a jak ovlivňují viditelnost značek. Prozkoumejte platformy jako Perplexity, ChatGPT, Goo...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.