
Co je Burstiness v AI obsahu a jak ovlivňuje detekci
Zjistěte, co znamená burstiness v AI-generovaném obsahu, jak se liší od vzorců lidského psaní a proč je důležitá pro detekci AI a autenticitu obsahu....
7 min čtení
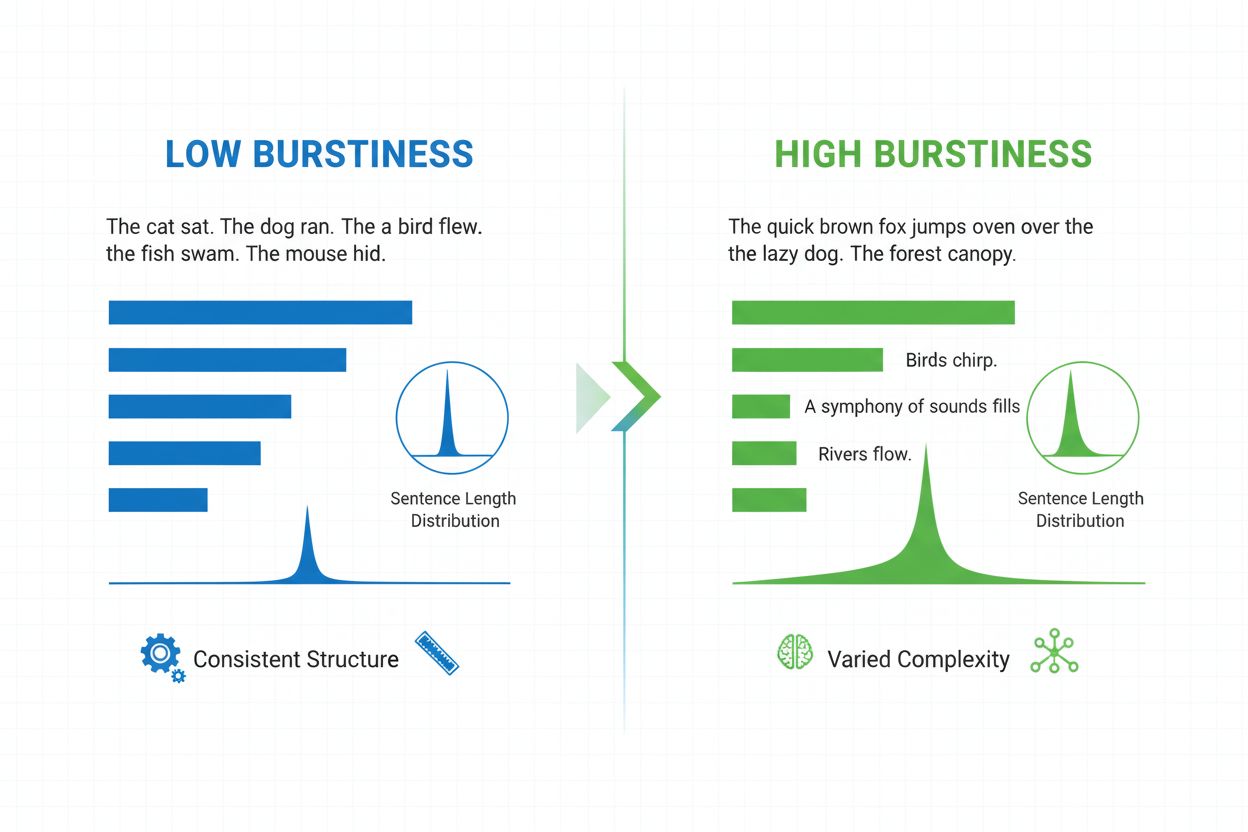
Burstiness je lingvistická metrika, která měří variabilitu délky, struktury a složitosti vět v rámci dokumentu. Kvantifikuje, jak moc autor střídá krátké, úderné věty s delšími a složitějšími, a slouží jako klíčový ukazatel při detekci AI-generovaného obsahu a analýze přirozeného jazyka.
Burstiness je lingvistická metrika, která měří variabilitu délky, struktury a složitosti vět v rámci dokumentu. Kvantifikuje, jak moc autor střídá krátké, úderné věty s delšími a složitějšími, a slouží jako klíčový ukazatel při detekci AI-generovaného obsahu a analýze přirozeného jazyka.
Burstiness je kvantifikovatelná lingvistická metrika, která měří variabilitu a kolísání délky, struktury a složitosti vět v psaném dokumentu nebo úryvku textu. Termín pochází z konceptu „výbuchů“ různých větných vzorců – střídání krátkých, úsporných vět s delšími a složitějšími. V kontextu zpracování přirozeného jazyka a detekce AI obsahu slouží burstiness jako klíčový ukazatel, zda byl text napsán člověkem nebo vygenerován umělou inteligencí. Lidský autor přirozeně vytváří text s vysokou burstiness, protože intuitivně mění konstrukci vět podle důrazu, tempa a stylového záměru. Naproti tomu AI-generovaný text obvykle vykazuje nízkou burstiness, protože jazykové modely jsou trénovány na statistických vzorcích, které upřednostňují konzistenci a předvídatelnost. Porozumění burstiness je zásadní pro tvůrce obsahu, pedagogy, výzkumníky i organizace, které monitorují AI-generovaný obsah na platformách jako ChatGPT, Perplexity, Google AI Overviews a Claude.
Koncept burstiness vznikl z výzkumu v oblasti počítačové lingvistiky a informační teorie, kde vědci usilovali o kvantifikaci statistických vlastností přirozeného jazyka. Rané práce ve stylometrii – statistické analýze stylu psaní – zjistily, že lidské psaní vykazuje charakteristické vzorce variability, které se zásadně liší od strojově generovaného textu. S tím, jak se velké jazykové modely (LLM) v raných 20. letech 21. století stávaly sofistikovanějšími, si výzkumníci uvědomili, že burstiness v kombinaci s perplexitou (měřítkem předvídatelnosti slov) může sloužit jako spolehlivý ukazatel AI-generovaného obsahu. Podle výzkumu QuillBotu a akademických institucí přibližně 78 % podniků nyní využívá nástroje pro monitorování obsahu s AI, které zahrnují analýzu burstiness v rámci svých detekčních algoritmů. Studie Stanford University z roku 2023 o TOEFL esejích ukázala, že metody detekce založené na burstiness, byť užitečné, mají významná omezení – zejména pokud jde o falešně pozitivní výsledky u nerodilého anglického psaní. Tento výzkum vedl k vývoji sofistikovanějších, vícevrstvých systémů detekce AI, které posuzují burstiness spolu s dalšími jazykovými ukazateli, sémantickou koherencí a kontextovou vhodností.
Burstiness se počítá analýzou statistického rozložení délek vět a jejich strukturálních vzorců v textu. Tato metrika kvantifikuje rozptyl – tedy měří, jak moc se jednotlivé věty odchylují od průměrné délky věty v dokumentu. Dokument s vysokou burstiness obsahuje věty, jejichž délka se výrazně liší; například autor může následovat tříslovnou větu („Vidíš?“) větou o pětadvaceti slovech s několika vedlejšími větami a frázemi. Naproti tomu nízká burstiness znamená, že většina vět se pohybuje kolem podobné délky, typicky mezi dvanácti a osmnácti slovy, což vytváří monotónní rytmus. Výpočet zahrnuje několik kroků: nejprve systém změří délku každé věty ve slovech; poté vypočítá průměrnou délku věty; následně stanoví směrodatnou odchylku, která ukáže, jak moc se jednotlivé věty odchylují od průměru. Vyšší směrodatná odchylka znamená větší variabilitu, a tedy vyšší burstiness. Moderní AI detektory jako Winston AI a Pangram využívají sofistikované algoritmy, které nejen počítají slova, ale také analyzují syntaktickou složitost – uspořádání vět, vět a gramatických prvků. Tato hlubší analýza odhaluje, že lidský autor používá rozmanité větné struktury (jednoduché, souvětí, složené i složitě složené věty) v nepředvídatelných vzorcích, zatímco AI modely upřednostňují určité strukturální šablony často obsažené v jejich trénovacích datech.
| Metrika | Burstiness | Perplexita | Zaměření měření |
|---|---|---|---|
| Definice | Variabilita v délce a struktuře vět | Předvídatelnost jednotlivých slov | Větná vs. slovní úroveň |
| Lidské psaní | Vysoká (různorodé struktury) | Vysoká (nepředvídatelná slova) | Přirozený rytmus a slovní zásoba |
| AI-generovaný text | Nízká (jednotné struktury) | Nízká (předvídatelná slova) | Statistická konzistence |
| Aplikace v detekci | Odhaluje strukturální monotónnost | Odhaluje vzorce volby slov | Doplňkové detekční metody |
| Riziko falešně pozitivních | Vyšší u psaní cizinců | Vyšší u technického/akademického psaní | Obě mají omezení |
| Metoda výpočtu | Směrodatná odchylka délek vět | Analýza pravděpodobnostního rozdělení | Různé matematické přístupy |
| Spolehlivost samostatně | Nedostatečná pro jednoznačnou detekci | Nedostatečná pro jednoznačnou detekci | Nejefektivnější v kombinaci |
Velké jazykové modely jako ChatGPT, Claude a Google Gemini jsou trénovány procesem zvaným predikce dalšího tokenu, při kterém se model učí předpovídat statisticky nejpravděpodobnější slovo následující po dané sekvenci. Během tréninku jsou tyto modely explicitně optimalizovány na minimalizaci perplexity na trénovacích datech, což jako vedlejší efekt neúmyslně vytváří nízkou burstiness. Pokud model během tréninku často narazí na konkrétní větnou strukturu, naučí se ji reprodukovat s vysokou pravděpodobností, což vede k jednotným, předvídatelným délkám vět. Výzkum Netus AI a Winston AI ukazuje, že AI modely vykazují charakteristický stylometrický otisk, daný jednotnou větnou konstrukcí, nadužíváním spojovacích frází (jako „Navíc“, „Proto“, „Dále“) a preferencí pasivního rodu před aktivním. Spoléhání modelů na pravděpodobnostní rozdělení znamená, že tíhnou k nejběžnějším vzorcům ze svých trénovacích dat, místo aby zkoumaly celé spektrum možných větných konstrukcí. Vzniká tak paradoxní situace: čím více dat má model k dispozici, tím více se učí reprodukovat běžné vzorce a tím nižší má burstiness. Navíc AI modelům chybí spontánnost a emocionální variabilita typická pro lidské psaní – nepíší jinak, když jsou nadšené, frustrované nebo chtějí něco zdůraznit. Místo toho udržují konzistentní stylový základ, který odráží statistický střed jejich trénovacích dat.
Platformy pro detekci AI začlenily analýzu burstiness jako jádro svých detekčních algoritmů, ovšem s různou mírou sofistikovanosti. První detekční systémy se silně spoléhaly na burstiness a perplexitu jako hlavní metriky, avšak výzkumy ukázaly významná omezení tohoto přístupu. Podle Pangram Labs detektory založené na perplexitě a burstiness generují falešně pozitivní výsledky při analýze textu, který je součástí trénovacích dat jazykových modelů – například Deklarace nezávislosti je často označována za AI-generovanou, protože se v trénovacích datech modelů vyskytuje natolik často, že model jí přiřazuje jednotně nízkou perplexitu. Moderní detekční systémy jako Winston AI a Pangram dnes využívají hybridní přístupy, které kombinují analýzu burstiness s hlubokým učením na základě různorodých vzorků lidského i AI-generovaného textu. Tyto systémy současně analyzují několik jazykových dimenzí: variabilitu větné struktury, lexikální rozmanitost (bohatost slovní zásoby), vzorce interpunkce, kontextovou koherenci a sémantické sladění. Integrace burstiness do širších detekčních rámců výrazně zvýšila přesnost – Winston AI uvádí přesnost 99,98 % při rozlišování AI-generovaného a lidského textu díky analýze více ukazatelů, nikoli pouze burstiness. Metrika je však stále cenná jako jedna ze složek komplexní detekční strategie, zejména v kombinaci s analýzou perplexity, stylometrických vzorců a sémantické konzistence.
Vztah mezi burstiness a čtivostí je v lingvistickém výzkumu dobře zdokumentován. Skóre Flesch Reading Ease a Flesch-Kincaid Grade Level, která měří přístupnost textu, silně korelují se vzorci burstiness. Text s vyšší burstiness obvykle dosahuje lepší čtivosti, protože různorodá délka vět brání kognitivní únavě a udržuje pozornost čtenáře. Pokud čtenář narazí na konzistentní rytmus podobně dlouhých vět, jeho mozek se adaptuje na předvídatelný vzorec, což může vést k nezájmu a sníženému porozumění. Naproti tomu vysoká burstiness vytváří efekt přílivu a odlivu, který udržuje čtenáře duševně aktivního střídáním kognitivní zátěže – krátké věty poskytují rychlé, snadno stravitelné informace, zatímco delší umožňují rozvinout komplexní myšlenky a nuance. Výzkum Metrics Masters ukazuje, že vysoká burstiness zlepšuje zapamatovatelnost přibližně o 15–20 % oproti nízké burstiness, protože rozmanitý rytmus pomáhá účinněji ukládat informace do dlouhodobé paměti. Tento princip platí napříč typy obsahu: blogy, akademické práce, marketingové texty i technická dokumentace těží ze strategické burstiness. Vztah však není lineární – nadměrná burstiness, která upřednostňuje variabilitu před srozumitelností, může text učinit roztříštěným a obtížným ke sledování. Optimální postup spočívá v záměrné variabilitě, kdy volba větné struktury slouží smyslu obsahu a komunikačnímu záměru autora, nikoli jen navyšování metriky.
Navzdory širokému zavedení v AI detekčních systémech má detekce založená na burstiness významná omezení, která by si měli výzkumníci i praktičtí uživatelé uvědomovat. Pangram Labs publikovala rozsáhlý výzkum, který popisuje pět hlavních nedostatků: za prvé, texty z trénovacích dat AI jsou chybně označovány za AI-generované, protože modely jsou optimalizovány na minimalizaci perplexity u těchto dat; za druhé, hodnoty burstiness jsou relativní vůči konkrétním modelům, takže různé modely generují odlišné profily perplexity; za třetí, uzavřené komerční modely jako ChatGPT nezpřístupňují pravděpodobnosti tokenů, což znemožňuje výpočet perplexity; za čtvrté, nerodilí mluvčí angličtiny jsou nepřiměřeně označováni jako AI, protože jejich větné struktury jsou jednotnější; a za páté, detektory založené na burstiness se nemohou iterativně zlepšovat s novými daty. Stanfordská studie TOEFL 2023 zjistila, že přibližně 26 % textů nerodilých angličtinářů bylo nesprávně označeno jako AI-generované na základě detekce burstiness a perplexity, zatímco u rodilých mluvčích šlo jen o 2 % falešných pozitiv. Tato zaujatost vyvolává vážné etické otázky ve školství, kde se AI detekce používá k hodnocení studentských prací. Navíc šablonovitý obsah v marketingu, akademickém psaní či technické dokumentaci přirozeně vykazuje nižší burstiness kvůli stylovým požadavkům a strukturálním konvencím, což v těchto oblastech vede k falešně pozitivním výsledkům. Tato omezení vedla k vývoji propracovanějších metod detekce, které považují burstiness za jeden z mnoha signálů, nikoli za jednoznačný ukazatel AI generování.
Vzorce burstiness se výrazně liší napříč různými žánry a kontexty psaní, což odráží odlišné komunikační cíle a očekávání publika v každé oblasti. Akademické psaní, zejména v přírodních a technických vědách, má tendenci vykazovat nižší burstiness, protože autoři se řídí přísnými stylovými pravidly a jednotnými strukturálními šablonami pro jasnost a přesnost. Právní dokumenty, technické specifikace a vědecké práce upřednostňují konzistenci a předvídatelnost před stylistickou rozmanitostí, což vede k přirozeně nižším hodnotám burstiness. Naproti tomu kreativní psaní, žurnalistika a marketingové texty obvykle vykazují vysokou burstiness, protože v těchto žánrech je prioritou zapojení čtenáře a emocionální dopad prostřednictvím variabilního tempa a rytmu. Beletrie zvláště často využívá dramatických změn délky vět k vytvoření důrazu, budování napětí a kontrole tempa vyprávění. Firemní komunikace zaujímá střední pozici – profesionální e-maily a zprávy zachovávají střední burstiness pro rovnováhu mezi jasností a zapojením čtenáře. Metodika Flesch-Kincaid Grade Level ukazuje, že akademické texty určené pro vysokoškolsky vzdělané publikum často obsahují delší a komplexnější věty, což může vypadat jako snížení burstiness; avšak variace v klauzuli a podřízených větách stále vytváří smysluplnou burstiness. Porozumění těmto kontextovým variacím je pro AI detekční systémy klíčové, protože musí zohlednit žánrové konvence, aby se vyhnuly falešně pozitivním výsledkům. Technický manuál s jednotně dlouhými větami by neměl být označen za AI-generovaný jen proto, že vykazuje nízkou burstiness – nízká burstiness zde odráží vhodné stylistické volby pro daný žánr, nikoli důkaz strojového generování.
Budoucnost analýzy burstiness v detekci AI směřuje k sofistikovanějším, kontextově citlivým přístupům, které uznávají omezení metriky, ale využívají její poznatky. S tím, jak se velké jazykové modely neustále zdokonalují, začínají do svých výstupů začleňovat i variabilitu burstiness, což činí detekci založenou pouze na této metrice méně spolehlivou. Výzkumníci vyvíjejí adaptivní detekční systémy, které analyzují burstiness ve spojení se sémantickou koherencí, faktickou přesností a kontextovou vhodností. Vznik AI nástrojů pro „polidštění“ textu, které záměrně zvyšují burstiness a další lidské rysy, představuje probíhající závod mezi detekčními a „maskovacími“ technologiemi. Odborníci však předpovídají, že skutečně spolehlivá detekce AI bude nakonec záviset na kryptografických metodách ověření a sledování původu obsahu, nikoli jen na jazykové analýze. Pro tvůrce obsahu a organizace je strategicky jasné: místo snahy burstiness „obcházet“ nebo zneužívat by se autoři měli zaměřit na rozvoj autentického, různorodého stylu psaní, který přirozeně odráží lidskou komunikaci. Monitorovací platforma AmICited představuje novou etapu v této oblasti, když sleduje, jak se značky objevují v AI-generovaných odpovědích a analyzuje jazykové charakteristiky těchto zmínek. S rostoucí přítomností AI v generování a šíření obsahu je porozumění burstiness a příbuzným metrikám stále důležitější pro zachování autenticity značky, zajištění akademické integrity a udržení rozlišení mezi lidsky psaným a strojově generovaným obsahem. Vývoj směrem k multisignálním detekčním přístupům naznačuje, že burstiness zůstane relevantní jako jedna ze složek komplexních AI monitorovacích systémů, byť její role bude stále více nuancovaná a závislá na kontextu.
Burstiness a perplexita jsou doplňující se metriky používané při detekci AI. Perplexita měří, jak předvídatelná jsou jednotlivá slova v textu, zatímco burstiness měří variabilitu ve struktuře a délce vět v celém dokumentu. Lidské psaní obvykle vykazuje vyšší perplexitu (nepředvídatelnější volbu slov) a vyšší burstiness (různorodější větné struktury), zatímco AI-generovaný text má tendenci vykazovat nižší hodnoty obou metrik kvůli spoléhání na statistické vzorce z trénovacích dat.
Vysoká burstiness vytváří rytmický tok, který zvyšuje zapojení a porozumění čtenáře. Pokud autoři střídají krátké, úderné věty s delšími a komplexnějšími, udržují pozornost čtenáře a předcházejí monotónnosti. Výzkum ukazuje, že rozmanitá větná struktura zlepšuje zapamatovatelnost a činí text autentičtějším a konverzačnějším. Nízká burstiness, charakterizovaná jednotnou délkou vět, může způsobit, že text působí roboticky a obtížně se sleduje, což snižuje čtivost i zapojení publika.
Burstiness lze záměrně zvýšit cílenou variabilitou větných struktur, avšak takový umělý zásah často vede k nepřirozeně znějícímu textu, který může aktivovat jiné mechanismy detekce. Moderní AI detektory analyzují více jazykových rysů kromě burstiness, včetně sémantické koherence, kontextové vhodnosti a stylometrických vzorců. Autentická burstiness vzniká přirozeně v lidském psaní a odráží jedinečný hlas autora, zatímco nucená variace obvykle postrádá organickou kvalitu charakteristickou pro skutečně lidský text.
Nerodilí mluvčí angličtiny často vykazují nižší hodnoty burstiness, protože jejich psaní odráží omezenější slovní zásobu a jednodušší strategie větné konstrukce. Studenti jazyka obvykle používají jednotnější, předvídatelné větné struktury během zvyšování své úrovně, vyhýbají se složitým větám a různým syntaktickým vzorcům. To vytváří stylometrický profil podobný AI-generovanému textu, což vede k falešně pozitivním výsledkům v systémech detekce AI. Výzkum Stanfordovy univerzity z roku 2023 o TOEFL esejích potvrdil tuto zaujatost a poukázal na zásadní omezení detekce založené na burstiness.
Velké jazykové modely jsou trénovány na rozsáhlých datech, kde se učí předpovídat další slovo na základě statistických vzorců. Během tréninku jsou tyto modely optimalizovány tak, aby minimalizovaly perplexitu na trénovacích datech, což neúmyslně vede k jednotným větným strukturám a předvídatelným posloupnostem slov. Výsledkem je konzistentně nízká burstiness, protože modely generují text výběrem statisticky pravděpodobných kombinací slov, místo aby používaly různorodou, spontánní větnou konstrukci typickou pro lidské psaní. Závislost modelů na pravděpodobnostních rozděleních vytváří homogenní stylistický podpis.
AmICited sleduje, jak se značky a domény objevují v AI-generovaných odpovědích napříč platformami jako ChatGPT, Perplexity a Google AI Overviews. Porozumění burstiness pomáhá monitorovacímu systému AmICited rozlišovat mezi autentickými lidskými citacemi a AI-generovaným obsahem, který zmiňuje vaši značku. Analýzou vzorců burstiness spolu s dalšími jazykovými ukazateli může AmICited poskytnout přesnější pohled na to, zda jsou vaše citace uváděny v opravdu lidsky psaném obsahu, nebo v odpovědích generovaných AI, což umožňuje lepší správu reputace značky.
Autoři mohou přirozeně zvýšit burstiness vědomým střídáním větných konstrukcí při zachování srozumitelnosti a smyslu. Mezi techniky patří střídání jednoduchých oznamovacích vět a komplexních vět s více větami, používání rétorických prostředků jako fragmentů a pomlček pro důraz a variace délek odstavců. Klíčem je, aby variabilita sloužila významu obsahu, nikoli aby existovala sama o sobě. Čtení nahlas, studium různých stylů psaní a revize s důrazem na rytmus přirozeně rozvíjejí schopnost vytvářet autenticky znějící text s vysokou burstiness.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Zjistěte, co znamená burstiness v AI-generovaném obsahu, jak se liší od vzorců lidského psaní a proč je důležitá pro detekci AI a autenticitu obsahu....
Diskuze komunity o burstiness v detekci AI obsahu – co to znamená, jak ovlivňuje viditelnost v AI a zda by tvůrci obsahu měli optimalizovat právě na burstiness....
Zjistěte, co je informační hustota a jak zvyšuje pravděpodobnost citace AI. Objevte praktické techniky pro optimalizaci obsahu pro AI systémy jako ChatGPT, Perp...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.