
Vysvětlení AI crawlerů: GPTBot, ClaudeBot a další
Pochopte, jak fungují AI crawleři jako GPTBot a ClaudeBot, v čem se liší od tradičních crawlerů vyhledávačů a jak optimalizovat svůj web pro viditelnost ve vyhl...
12 min čtení
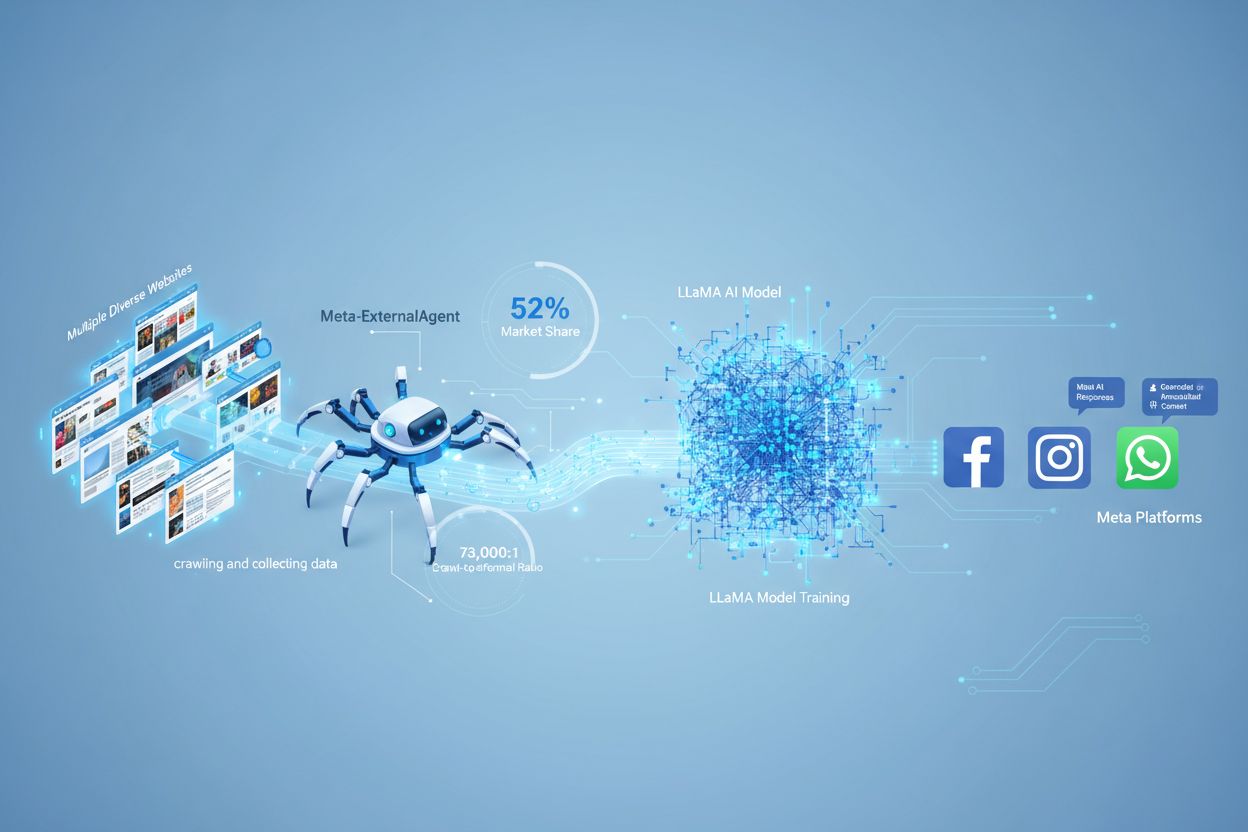
Meta-ExternalAgent je webový crawler společnosti Meta, spuštěný v červenci 2024 za účelem sběru veřejně dostupného obsahu pro trénink AI modelů jako LLaMA. Identifikuje se pomocí User-Agent řetězce meta-externalagent/1.1 a kontroluje, zda se obsah zobrazí v odpovědích Meta AI napříč Facebookem, Instagramem a WhatsAppem. Vydavatelé ho mohou blokovat pomocí robots.txt nebo serverových nastavení, avšak dodržování je dobrovolné a právně nezávazné.
Meta-ExternalAgent je webový crawler společnosti Meta, spuštěný v červenci 2024 za účelem sběru veřejně dostupného obsahu pro trénink AI modelů jako LLaMA. Identifikuje se pomocí User-Agent řetězce meta-externalagent/1.1 a kontroluje, zda se obsah zobrazí v odpovědích Meta AI napříč Facebookem, Instagramem a WhatsAppem. Vydavatelé ho mohou blokovat pomocí robots.txt nebo serverových nastavení, avšak dodržování je dobrovolné a právně nezávazné.
Meta-ExternalAgent je webový crawler provozovaný společností Meta Platforms, který byl spuštěn v červenci 2024 za účelem sběru dat pro trénink modelů umělé inteligence. Tento crawler, identifikovaný User-Agent řetězcem meta-externalagent/1.1, se liší od staršího crawleru facebookexternalhit, který byl využíván především pro náhledy odkazů a funkce sdílení na sociálních sítích. Meta-ExternalAgent představuje významnou změnu v přístupu Meta ke sběru tréninkových dat pro AI iniciativy, včetně jazykových modelů LLaMA a chatbotu Meta AI integrovaného napříč Facebookem, Instagramem a WhatsAppem. Na rozdíl od předchozích crawlerů Meta tento agent funguje s minimální transparentností a byl nasazen bez formálního veřejného oznámení.

Meta-ExternalAgent funguje jako automatizovaný bot, který systematicky prochází webové stránky na internetu a extrahuje text a obsah pro účely tréninku AI modelů. Crawler odesílá HTTP požadavky na webové servery, identifikuje se unikátní User-Agent hlavičkou a stahuje obsah stránek k dalšímu zpracování. Po nasbírání obsahu jej systémy Meta analyzují a tokenizují, čímž jej převádějí na tréninková data, která zlepšují schopnosti jejich rozsáhlých jazykových modelů. Crawler respektuje soubor robots.txt pouze dobrovolně, což je spíše čestný systém než právně závazná povinnost. Podle dat Cloudflare představuje Meta-ExternalAgent přibližně 52 % veškerého AI crawler provozu na internetu, což z něj činí jednu z nejagresivnějších operací sběru dat v AI průmyslu. Crawler funguje nepřetržitě a někteří vydavatelé uvádějí frekvence crawlování, které naznačují, že Meta upřednostňuje komplexní pokrytí webového obsahu před selektivním sběrem.
| Název crawleru | User-Agent řetězec | Hlavní účel | Datum spuštění | Využití dat |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | Trénink AI modelů (LLaMA, Meta AI) | červenec 2024 | Tréninková data pro generativní AI |
| facebookexternalhit | facebookexternalhit/1.1 | Náhledy odkazů a sdílení na sociálních sítích | ~2010 | Open Graph metadata, náhledy |
| Facebot | facebot/1.0 | Ověřování obsahu aplikací Facebook | ~2015 | Validace obsahu pro mobilní aplikace |
| Applebot | Applebot/0.1 | Apple Siri a indexace vyhledávání | ~2015 | Indexace vyhledávání a hlasový asistent |
| Googlebot | Googlebot/2.1 | Indexace Google vyhledávání | ~1998 | Budování indexu vyhledávače |
Meta-ExternalAgent představuje zásadní riziko pro tvůrce a vydavatele obsahu, protože funguje v bezprecedentním měřítku a zároveň poskytuje minimální přehled o tom, jak je obsah využíván. Podle výzkumu Cloudflare představuje Meta-ExternalAgent 52 % veškerého AI crawler provozu, což výrazně převyšuje konkurenty jako GPTBot od OpenAI a AI crawlery Googlu. Tato dominance znamená, že Meta sbírá více tréninkových dat než jakákoli jiná AI společnost, přičemž vydavatelé nedostávají žádnou kompenzaci ani zmínku, když je jejich obsah použit pro trénink AI modelů Meta. Poměr 73 000:1 mezi crawlováním a referral návštěvností ukazuje, že Meta masivně získává obsah, aniž by na zdrojové weby posílala téměř jakoukoli návštěvnost — což je zásadní nerovnováha ve směně hodnot. Přesto pouze 2 % webů aktivně blokuje Meta-ExternalAgent, zatímco 25 % blokuje GPTBot, což naznačuje, že mnoho vydavatelů o přítomnosti crawleru ani jeho důsledcích neví. S investicí Meta ve výši 40 miliard dolarů do AI infrastruktury lze očekávat další nárůst agresivního sběru dat, takže je pro vydavatele zásadní porozumět a aktivně řídit vztah k tomuto crawleru.
Vydavatelé mohou kontrolovat přístup Meta-ExternalAgent pomocí souboru robots.txt, ale je důležité si uvědomit, že tento mechanismus je pouze dobrovolný a právně nevynutitelný. Pro blokování Meta-ExternalAgent přidejte do svého souboru robots.txt následující pravidlo:
User-agent: meta-externalagent
Disallow: /
Pokud chcete crawler povolit, ale omezit jej jen na určité adresáře, použijte například:
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
Někteří vydavatelé ale uvádějí, že Meta-ExternalAgent pokračuje v crawlování i po nastavení blokace v robots.txt, což naznačuje, že Meta nemusí vždy tato pravidla dodržovat. Pro komplexnější ochranu lze implementovat blokování na úrovni HTTP hlaviček nebo využít pravidla Content Delivery Network (CDN) k identifikaci a odmítnutí požadavků od Meta-ExternalAgent podle User-Agent řetězce. Vydavatelé mohou také sledovat své serverové logy a hledat User-Agent řetězec meta-externalagent/1.1, aby ověřili, zda crawler přistupuje k jejich obsahu. Nástroje jako AmICited.com pomáhají vydavatelům sledovat, zda je jejich obsah citován nebo používán v odpovědích Meta AI, čímž poskytují přehled o využití jejich práce AI systémy Meta.

Když uživatelé komunikují s chatboty Meta AI na Facebooku, Instagramu nebo WhatsAppu, jsou odpovědi částečně založeny na obsahu získaném Meta-ExternalAgent. Odpovědi Meta AI však obvykle neobsahují viditelné citace nebo zmínky o zdrojových webech, takže uživatelé často netuší, který vydavatel přispěl k odpovědi, kterou dostali. Tento nedostatek transparentnosti představuje zásadní problém pro tvůrce, kteří chtějí zjistit, jakou hodnotu jejich práce přináší AI systémům Meta. Na rozdíl od některých konkurentů, kteří do AI odpovědí citace zahrnují, Meta upřednostňuje uživatelský zážitek před atribucí vydavatele. Absence viditelných citací také znamená, že vydavatelé nemohou snadno sledovat, jak často jejich obsah ovlivňuje odpovědi Meta AI, což ztěžuje vyhodnocení obchodního dopadu využití jejich obsahu pro trénink AI. Tato mezera ve viditelnosti je jedním z hlavních důvodů, proč jsou monitorovací řešení pro vydavatele stále důležitější.
Vydavatelé mohou ověřit aktivitu Meta-ExternalAgent analýzou serverových logů, které prozradí IP adresy crawleru, vzorce požadavků a četnost přístupu k obsahu. Kontrolou přístupových logů lze identifikovat požadavky s User-Agent řetězcem meta-externalagent/1.1 a určit, které stránky jsou crawlovány nejčastěji. Pokročilé monitorovací nástroje umožňují sledovat vzorce crawleru v čase a odhalit, zda Meta upřednostňuje určité typy obsahu nebo sekce webu. Vydavatelé by rovněž měli sledovat využití šířky pásma, protože agresivní crawlování Meta-ExternalAgent může výrazně zatížit serverové zdroje, zejména u webů s velkým množstvím obsahu. Kromě toho lze využít nástroje jako AmICited.com ke sledování, zda se jejich obsah objevuje v odpovědích Meta AI, a sledovat vzorce citací napříč platformami Meta. Nastavení upozornění na neobvyklou aktivitu crawleru pomůže vydavatelům odhalit změny v chování Meta při sběru dat a včas reagovat. Pravidelné audity serverových logů by měly být součástí strategie správy AI crawlerů každého vydavatele, aby si udrželi přehled o tom, jak je jejich obsah přístupný a používán.
Právní status Meta-ExternalAgent zůstává sporný, protože pokračují soudní spory ze strany tvůrců, umělců a vydavatelů, kteří napadají právo Meta používat jejich díla k tréninku AI bez výslovného souhlasu či kompenzace. Meta argumentuje, že webové crawlování spadá pod princip fair use, kritici však tvrdí, že rozsah a komerční charakter sběru dat v kombinaci s absencí atribuce představují porušení autorských práv. Soubor robots.txt, přestože je široce respektovaným průmyslovým standardem, nemá právní sílu, a Meta tedy není povinna blokovací pravidla dodržovat. Některé jurisdikce připravují regulace v oblasti sběru dat pro AI, například evropská AI Act či návrhy zákonů v dalších regionech, které mohou na firmy jako Meta uvalit přísnější požadavky. Z etického hlediska je klíčovou otázkou, zda by tvůrci měli mít právo kontrolovat, jak je jejich dílo využíváno pro komerční trénink AI a zda současný systém dostatečně kompenzuje autory za hodnotu jejich obsahu. Vydavatelé by měli sledovat vývoj právních rámců a zvážit konzultaci s právníky ohledně svých práv a povinností v souvislosti s přístupem AI crawlerů. Rovnováha mezi podporou inovací v AI a ochranou práv tvůrců zůstává nevyřešena, což z této oblasti činí předmět aktivního právního a regulatorního vývoje.
Oblast správy AI crawlerů se rychle vyvíjí, protože vydavatelé, regulátoři a AI firmy vyjednávají podmínky sběru a využití dat. Agresivní nasazení Meta-ExternalAgent ukazuje, že velké technologické firmy považují webový obsah za zásadní tréninkový materiál pro konkurenční AI systémy a tento trend pravděpodobně zesílí s tím, jak se AI schopnosti stávají klíčovou součástí byznys strategií. V budoucnu lze očekávat silnější právní ochranu tvůrců, povinné licenční rámce pro data k tréninku AI a technické standardy, které vydavatelům usnadní kontrolu a monetizaci využití jejich obsahu v AI systémech. Vznik nástrojů jako AmICited.com odráží rostoucí poptávku po transparentnosti a odpovědnosti v tom, jak AI systémy používají publikovaný obsah, což naznačuje, že monitoring a ověřování se stanou běžnou praxí pro tvůrce obsahu. S dozráváním AI průmyslu lze očekávat sofistikovanější vyjednávání mezi tvůrci a AI firmami, což může vést k novým obchodním modelům, které budou vydavatele spravedlivě kompenzovat za jejich přínos pro trénink AI.
Meta-ExternalAgent je specializovaný AI crawler Meta spuštěný v červenci 2024, identifikovaný User-Agent řetězcem meta-externalagent/1.1. Liší se od facebookexternalhit, který generuje náhledy odkazů pro sdílení na sociálních sítích. Meta-ExternalAgent sbírá obsah specificky pro trénink modelů LLaMA a Meta AI, zatímco facebookexternalhit je využíván pro sociální funkce již od roku 2010.
Meta-ExternalAgent můžete zablokovat přidáním pravidel do souboru robots.txt. Přidejte 'User-agent: meta-externalagent' následované 'Disallow: /' pro kompletní blokaci. Pro komplexnější ochranu použijte blokování na úrovni serveru pomocí .htaccess (Apache) nebo pravidel konfigurace Nginx. Robots.txt je však dobrovolný a právně nezávazný, takže někteří vydavatelé hlásí pokračující crawlování i přes blokování.
Ne, blokování Meta-ExternalAgent nemá vliv na náhledy odkazů na Facebooku. Crawler facebookexternalhit zajišťuje generování náhledů a funkce sdílení na sociálních sítích. Můžete zablokovat meta-externalagent a zároveň povolit facebookexternalhit, aby i nadále generoval atraktivní náhledy při sdílení obsahu na platformách Meta.
Meta-ExternalAgent má poměr crawlování k referralům přibližně 73 000 : 1, což znamená, že Meta získává obsah v obrovském měřítku, zatímco na zdrojové weby prakticky neposílá žádnou návštěvnost. To představuje zásadní nerovnováhu oproti tradičním vyhledávačům, které crawlery obsah výměnou za referral návštěvnost.
robots.txt je čestný systém a není právně závazný. Zatímco mnoho crawlerů respektuje pravidla robots.txt, někteří vydavatelé uvádějí, že Meta-ExternalAgent pokračuje v crawlování jejich webů i přes explicitní blokaci v robots.txt. Pro zaručenou ochranu použijte blokování na úrovni serveru pomocí HTTP hlaviček, pravidel CDN nebo konfigurace firewallu.
Zkontrolujte přístupové logy serveru na požadavky s User-Agent řetězcem 'meta-externalagent/1.1'. Také můžete použít monitorovací nástroje jako AmICited.com ke sledování, zda se váš obsah zobrazuje v odpovědích Meta AI. Nástroje jako Dark Visitors a Cloudflare Analytics poskytují další přehled o aktivitě AI crawlerů na vašem webu.
Podle dat Cloudflare představuje Meta-ExternalAgent přibližně 52 % veškerého provozu AI crawlerů na internetu, což z něj činí nejagresivnější operaci sběru dat pro AI. To výrazně převyšuje konkurenty, jako je GPTBot od OpenAI a AI crawlery Googlu, což ukazuje dominantní pozici Meta ve sběru webového obsahu pro AI trénink.
Rozhodnutí závisí na vašich obchodních prioritách. Pokud je návštěvnost z Meta AI pro vaše publikum hodnotná, můžete povolit přístup. Zvažte však, že Meta neposkytuje žádnou kompenzaci ani atribuci za obsah použitý k tréninku AI. Mnoho vydavatelů používá selektivní strategie blokování, které zastaví trénink AI, ale zachovají funkci náhledů pro sdílení na sociálních sítích.
Získejte přehled o tom, jak se váš obsah zobrazuje v odpovědích Meta AI napříč Facebookem, Instagramem a WhatsAppem. Sledujte citace AI a pochopte přítomnost své značky v AI generovaných odpovědích.
Pochopte, jak fungují AI crawleři jako GPTBot a ClaudeBot, v čem se liší od tradičních crawlerů vyhledávačů a jak optimalizovat svůj web pro viditelnost ve vyhl...

Zjistěte, co jsou AI crawler user-agenty, jak fungují v HTTP komunikaci a jaké jsou nejlepší postupy pro kontrolu přístupu na váš web ze strany AI crawlerů jako...

Objevte, jak optimalizace Meta AI mění reklamu na Facebooku a Instagramu díky automatizaci s podporou AI, real-time biddingem a inteligentním cílením na publiku...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.