
Co je meta tag noai a jak chrání váš obsah před AI?
Zjistěte, co je meta tag noai, jak funguje při prevenci sběru dat pro AI trénink, jaká má omezení a jak jej implementovat na svůj web pro ochranu obsahu před ge...
6 min čtení

HTML meta tag, který signalizuje AI trénovacím systémům a webovým robotům, že obsah webové stránky nemá být použit pro trénování modelů strojového učení. Původně zavedený DeviantArt, slouží jako mechanismus ochrany obsahu a možnost odhlášení pro tvůrce, kteří se obávají neoprávněného sběru dat pro AI.
HTML meta tag, který signalizuje AI trénovacím systémům a webovým robotům, že obsah webové stránky nemá být použit pro trénování modelů strojového učení. Původně zavedený DeviantArt, slouží jako mechanismus ochrany obsahu a možnost odhlášení pro tvůrce, kteří se obávají neoprávněného sběru dat pro AI.
NoAI meta tag je mechanismus ochrany obsahu realizovaný jako HTML meta tag, který signalizuje AI trénovacím systémům a webovým robotům, že obsah webové stránky nemá být použit pro trénování modelů strojového učení. Tento tag byl původně představen DeviantArt v září 2022 jako reakce komunity na obavy z toho, že umělecká díla jsou bez souhlasu a kompenzace využívána ke generativnímu trénování AI modelů. Meta tag funguje přidáním jednoduchého HTML prohlášení do hlavičky webové stránky, čímž AI systémům jasně sděluje, že obsah nesmí být použit pro trénování. Přestože ve většině jurisdikcí není právně závazný, představuje NoAI tag důležitý opt-out mechanismus pro tvůrce, kteří chtějí chránit své duševní vlastnictví v době stále agresivnějšího sběru dat pro AI.
Webové roboty (také známé jako boti, pavouci nebo scrapery) jsou automatizované softwarové programy, které systematicky procházejí internet, sledují odkazy a stahují obsah za účelem indexace, analýzy nebo sběru dat pro různé účely. Tyto roboty fungují tak, že čtou soubor robots.txt umístěný v kořenovém adresáři webu, který obsahuje instrukce o tom, které části webu by měly nebo neměly být přístupné automatizovaným návštěvníkům. Soubor robots.txt používá specifické direktivy jako User-agent, Disallow a Allow ke sdělení práv robotům, i když jejich dodržování je zcela dobrovolné a závisí na rozhodnutí vývojáře robota. Kromě robots.txt mohou weby sdělovat své preference také HTTP hlavičkami a meta tagy, které poskytují další signály o právech a omezeních při využití obsahu. Různé typy robotů respektují tyto signály v různé míře:
| Typ robota | Dodržování robots.txt | Respektování meta tagů | Využití pro AI trénink |
|---|---|---|---|
| Vyhledávače | Vysoké | Vysoké | Omezené |
| AI trénovací boti | Střední | Střední | Ano |
| Komerční scrapery | Nízké | Nízké | Různé |
| Akademičtí boti | Vysoké | Střední | Jen výzkum |
| Škodliví boti | Žádné | Žádné | Neomezené |
Direktivy noai a noimageai slouží příbuzným, ale odlišným účelům v ochraně obsahu, přičemž hlavní rozdíl spočívá v jejich rozsahu a specifikaci. Direktiva noai je širším signálem, který naznačuje, že veškerý obsah na stránce – včetně textu, obrázků, kódu a jiných médií – nemá být využit pro trénování AI, což je vhodné pro weby s různorodým obsahem nebo ty, které chtějí komplexní ochranu. Naproti tomu noimageai cílí pouze na obrazový obsah, což umožňuje, aby text a další neobrazové materiály mohly být případně použity pro trénování, ale vizuální prvky zůstávají chráněny před využitím v generativních obrazových modelech. Tento rozdíl je důležitý zejména pro weby, které chtějí povolit indexaci textu (například pro vyhledávače nebo přístupnost), ale chránit vizuální obsah před použitím v AI. Zde jsou rozdíly v implementaci:
<!-- Komplexní ochrana veškerého obsahu -->
<meta name="robots" content="noai">
<!-- Specifická ochrana pouze pro obrázky -->
<meta name="robots" content="noimageai">
<!-- Kombinovaný přístup pro maximální srozumitelnost -->
<meta name="robots" content="noai, noimageai">
NoAI meta tag lze implementovat několika způsoby, přičemž každý má své výhody v závislosti na technické infrastruktuře a konkrétních potřebách. Nejpřímější je přidat meta tag přímo do sekce <head> HTML dokumentu, což uplatní direktivu na jednotlivé stránky a umožní případné individuální přizpůsobení. Pro weby s velkým množstvím stránek nebo pro plošné řešení je vhodné nasadit direktivu prostřednictvím HTTP hlaviček, čímž se aplikuje jednotně na veškerý obsah bez nutnosti úprav jednotlivých stránek. Navíc lze použít soubor robots.txt s direktivami cílenými na specifické AI roboty, i když tento způsob je méně standardizovaný než meta tagy nebo hlavičky. Zde jsou tři hlavní způsoby implementace:
<!-- Metoda 1: HTML meta tag (nejběžnější) -->
<head>
<meta name="robots" content="noai">
</head>
# Metoda 2: direktiva v robots.txt
User-agent: *
Disallow: /
X-Robots-Tag: noai
# Metoda 3: HTTP hlavička (přes .htaccess nebo konfiguraci serveru)
X-Robots-Tag: noai
Pro servery Apache přidejte do .htaccess:
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
Pro servery Nginx vložte do serverového bloku:
add_header X-Robots-Tag "noai" always;
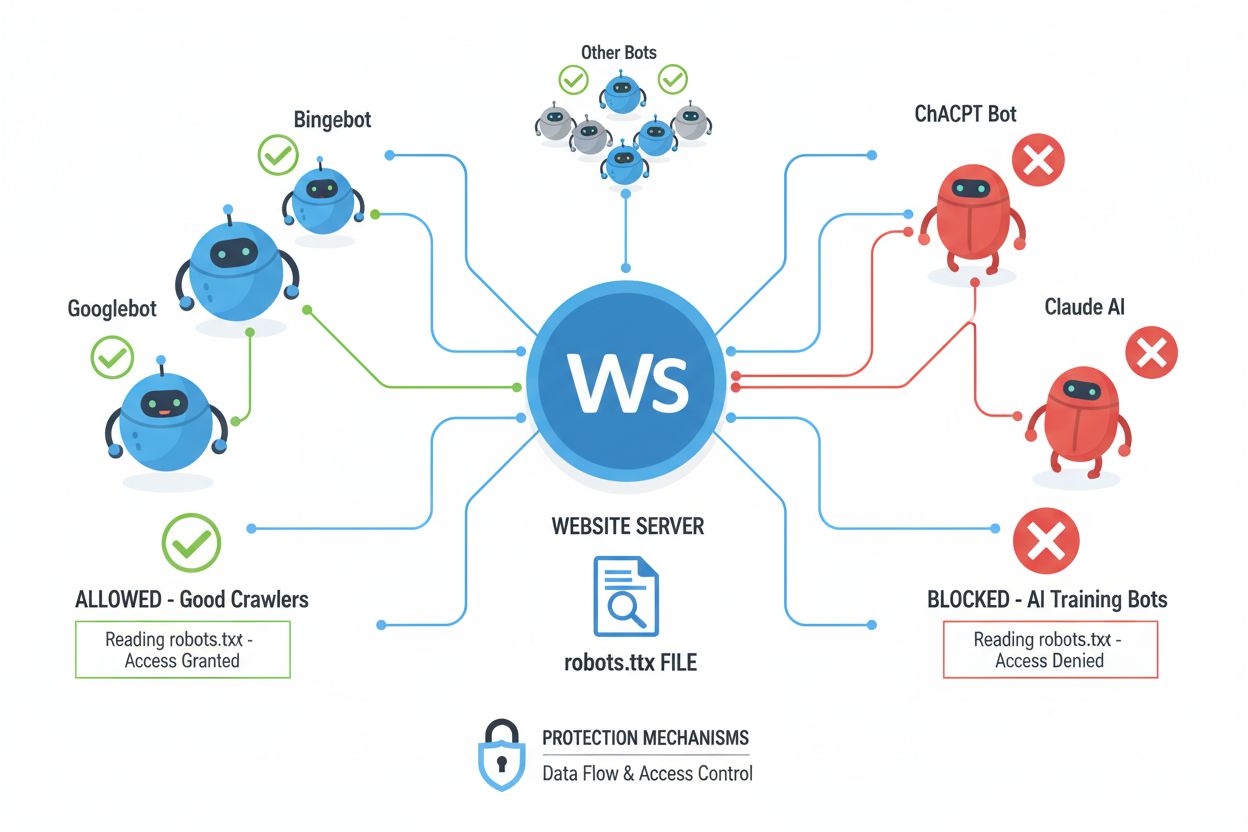
Ačkoliv NoAI meta tag představuje důležitý krok k ochraně obsahu, funguje na principu dobrovolného respektování, tedy záleží zcela na tom, zda AI vývojáři a scrapery tento signál dodržují. Velké AI společnosti jako OpenAI, Google a Anthropic začaly NoAI direktivy respektovat ve svých robotech, ale škodliví aktéři a nelegální scrapery tyto signály často zcela ignorují, takže tag není účinný proti odhodlaným zlodějům dat. Dalším omezením je, že NoAI zabraňuje pouze budoucímu trénování na obsahu; nemůže odstranit data, která již byla nasbírána a využita ve stávajících modelech, ani neposkytuje právní ochranu v případě porušení. Míra dodržování se velmi liší mezi různými AI systémy – některé direktivu respektují, jiné ji záměrně obcházejí, takže NoAI je užitečný, ale ne zcela dostačující nástroj. Tag také nechrání před přímým stažením, screenshoty nebo ručním kopírováním obsahu a nezabrání ani tomu, aby vaši práci využili konkurenti, kteří direktivu ignorují. Proto by měl být NoAI vnímán jako jedna vrstva komplexní strategie ochrany obsahu, nikoli jako samostatné řešení.
NoAI meta tag si získal významnou podporu mezi hlavními AI společnostmi a platformami – OpenAI, Google a Stability AI veřejně potvrdily, že tuto direktivu při trénování modelů respektují. Zavedení NoAI na DeviantArt ovlivnilo širší diskuzi v oboru o etickém vývoji AI a souhlasu tvůrců, což vedlo k větší informovanosti jak mezi AI vývojáři, tak mezi autory obsahu. Přesto je přijetí v oboru nejednotné – menší AI firmy, akademičtí výzkumníci a komerční scrapery mají různou míru dodržování. Vývoj konkurenčních standardů jako C2PA (Coalition for Content Provenance and Authenticity) a debaty o strojově čitelných vyjádřeních práv naznačují, že obor se posouvá směrem k sofistikovanějším, právně podloženým mechanismům ochrany obsahu nad rámec dobrovolných meta tagů. Průmyslové organizace a standardizační orgány aktivně pracují na formalizaci těchto ochran s očekáváním, že budoucí AI regulace může vyžadovat explicitní respektování preferencí tvůrců obsahu a z NoAI se tak může stát nejen dobrovolný signál, ale i právně vymahatelný požadavek.
Implementace NoAI ochrany by měla být součástí vícevrstvého přístupu k zabezpečení obsahu, nikoli samostatným řešením – kombinujte technické, právní a monitorovací strategie pro komplexní ochranu. Pro maximální účinnost zvažte tyto doporučené postupy:
Dále pravidelně provádějte audity své ochrany obsahu, abyste zajistili, že všechny stránky obsahují správné direktivy, a zvažte použití automatizovaných nástrojů pro vyhledávání vašeho obsahu ve veřejných AI datasetech a trénovacích repozitářích. Dokumentujte implementaci NoAI jako součást politiky správy obsahu a komunikujte tato opatření svému publiku, aby vědělo, jak chráníte jejich díla – zejména pokud jste platforma s uživatelským obsahem.
Direktiva noai chrání všechny typy obsahu (text, obrázky, kód) před trénováním AI, zatímco noimageai chrání pouze obrazový obsah. Pro komplexní ochranu použijte noai a noimageai použijte tehdy, když chcete povolit indexaci textu, ale chránit vizuální prvky před generativními obrazovými modely.
Ne, NoAI meta tag funguje na základě dobrovolného respektování a záleží na tom, zda jej AI vývojáři dodržují. Velké firmy jako OpenAI a Google jej respektují, ale škodliví aktéři a nelegální scrapery tyto signály často ignorují, takže jde spíše o jednu vrstvu ochrany než o úplné řešení.
Můžete jej implementovat třemi způsoby: přidáním HTML meta tagu do hlavičky stránky, nastavením HTTP hlaviček na serveru nebo vložením direktiv do souboru robots.txt. Nejčastější a nejjednodušší metoda je HTML meta tag pro většinu majitelů webů.
Velké AI společnosti včetně OpenAI (ChatGPT), Google, Anthropic (Claude) a Stability AI veřejně potvrdily, že respektují NoAI direktivy při trénování svých modelů. Míra dodržování se však liší u menších AI firem, akademických výzkumníků a komerčních scraperů.
Ano, pro maximální účinnost můžete použít oba současně. NoAI meta tag a direktivy v robots.txt spolupracují a sdělují vaše preference ochrany obsahu různým typům robotů a systémů.
Kombinujte NoAI s dalšími ochrannými metodami, jako jsou HTTP hlavičky, pravidla v robots.txt, vodoznaky, přístupová omezení a právní podmínky. Sledujte svůj obsah v AI datasetech a zvažte použití nástrojů pro monitoring neoprávněného použití.
Ačkoliv je široce přijímán hlavními AI firmami, NoAI zatím není formálním W3C standardem. Průmyslové organizace však pracují na sofistikovanějších standardech jako C2PA a strojově čitelných vyjádřeních práv, které by mohly časem získat právní podporu.
NoAI je nejúčinnější v kombinaci s dalšími metodami, jako jsou robots.txt, HTTP hlavičky, vodoznaky, přístupová omezení a právní ochrana. Žádná metoda neposkytuje úplnou ochranu, proto je doporučený vícevrstvý přístup pro komplexní bezpečnost obsahu.
Sledujte, které AI systémy citují vaši značku a obsah pomocí monitorovací platformy AmICited pro AI. Zjistěte přesně, jak je vaše práce využívána ChatGPT, Perplexity, Google AI Overviews a dalšími AI systémy.
Zjistěte, co je meta tag noai, jak funguje při prevenci sběru dat pro AI trénink, jaká má omezení a jak jej implementovat na svůj web pro ochranu obsahu před ge...
Diskuze komunity o meta tagu noai a jeho skutečné účinnosti při ochraně obsahu před trénováním AI. Uživatelé sdílí zkušenosti a limity tohoto přístupu....

Naučte se, jak implementovat meta tagy noai a noimageai pro kontrolu přístupu AI crawlerů k obsahu vašeho webu. Kompletní průvodce hlavičkami pro kontrolu příst...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.