
Skal du blokere eller tillade AI-crawlere? Beslutningsramme
Lær at træffe strategiske beslutninger om blokering af AI-crawlere. Vurder indholdstype, trafikkilder, indtægtsmodeller og konkurrenceposition med vores omfatte...
11 min læsning

Den strategiske praksis med selektivt at tillade eller blokere AI-crawlere for at kontrollere, hvordan indhold bruges til træning versus realtidssøgning. Dette involverer brug af robots.txt-filer, serverkontroller og overvågningsværktøjer til at styre, hvilke AI-systemer der kan få adgang til dit indhold og til hvilke formål.
Den strategiske praksis med selektivt at tillade eller blokere AI-crawlere for at kontrollere, hvordan indhold bruges til træning versus realtidssøgning. Dette involverer brug af robots.txt-filer, serverkontroller og overvågningsværktøjer til at styre, hvilke AI-systemer der kan få adgang til dit indhold og til hvilke formål.
AI Crawler Management refererer til praksissen med at kontrollere og overvåge, hvordan kunstige intelligenssystemer får adgang til og bruger webstedsindhold til trænings- og søgeformål. I modsætning til traditionelle søgemaskinecrawlere, der indekserer indhold til websøgeresultater, er AI-crawlere specifikt designet til at indsamle data til træning af store sprogmodeller eller drive AI-drevne søgefunktioner. Omfanget af denne aktivitet varierer dramatisk mellem organisationer—OpenAI’s crawlere opererer med et 1.700:1 crawl-to-refer-forhold, hvilket betyder, at de tilgår indhold 1.700 gange for hver reference, de giver, mens Anthropics forhold når 73.000:1, hvilket understreger det massive dataforbrug, der kræves for at træne moderne AI-systemer. Effektiv crawler management gør det muligt for webstedsejere at beslutte, om deres indhold skal bidrage til AI-træning, vises i AI-søgeresultater eller forblive beskyttet mod automatiseret adgang.
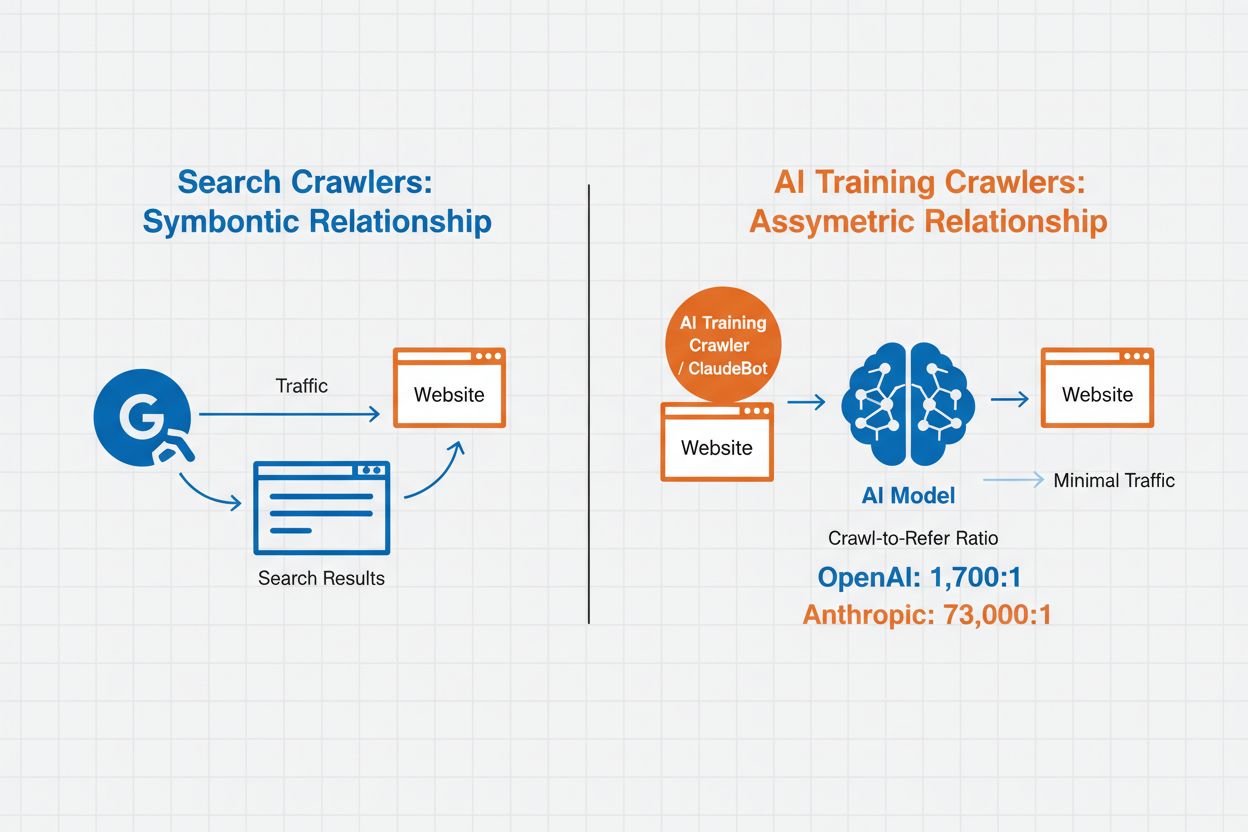
AI-crawlere falder i tre forskellige kategorier baseret på deres formål og databrugsmønstre. Træningscrawlere er designet til at indsamle data til udvikling af maskinlæringsmodeller og forbruger store mængder indhold for at forbedre AI-evner. Søge- og citeringscrawlere indekserer indhold for at drive AI-drevne søgefunktioner og levere attribution i AI-genererede svar, hvilket gør det muligt for brugere at opdage dit indhold via AI-grænseflader. Brugerudløste crawlere fungerer on-demand, når brugere interagerer med AI-værktøjer, f.eks. når en ChatGPT-bruger uploader et dokument eller anmoder om analyse af en bestemt webside. Forståelse af disse kategorier hjælper dig med at træffe informerede beslutninger om, hvilke crawlere du vil tillade eller blokere baseret på din indholdsstrategi og dine forretningsmål.
| Crawler Type | Purpose | Examples | Training Data Used |
|---|---|---|---|
| Training | Model development and improvement | GPTBot, ClaudeBot | Yes |
| Search/Citation | AI search results and attribution | Google-Extended, OAI-SearchBot, PerplexityBot | Varies |
| User-Triggered | On-demand content analysis | ChatGPT-User, Meta-ExternalAgent, Amazonbot | Context-specific |
AI crawler management har direkte indflydelse på dit websteds trafik, indtjening og indholdsværdi. Når crawlere forbruger dit indhold uden kompensation, mister du muligheden for at drage fordel af den trafik gennem henvisninger, annoncevisninger eller brugerengagement. Websteder har rapporteret betydelige trafikreduktioner, da brugere finder svar direkte i AI-genererede svar i stedet for at klikke sig videre til den oprindelige kilde, hvilket effektivt afskærer henvisningstrafik og tilhørende annonceindtægter. Ud over de økonomiske konsekvenser er der vigtige juridiske og etiske overvejelser—dit indhold repræsenterer intellektuel ejendom, og du har ret til at kontrollere, hvordan det bruges, og om du modtager attribution eller kompensation. Derudover kan ubegrænset crawler-adgang øge serverbelastning og båndbreddeomkostninger, især fra crawlere med aggressive crawl-rater, der ikke respekterer rate-limiting-direktiver.
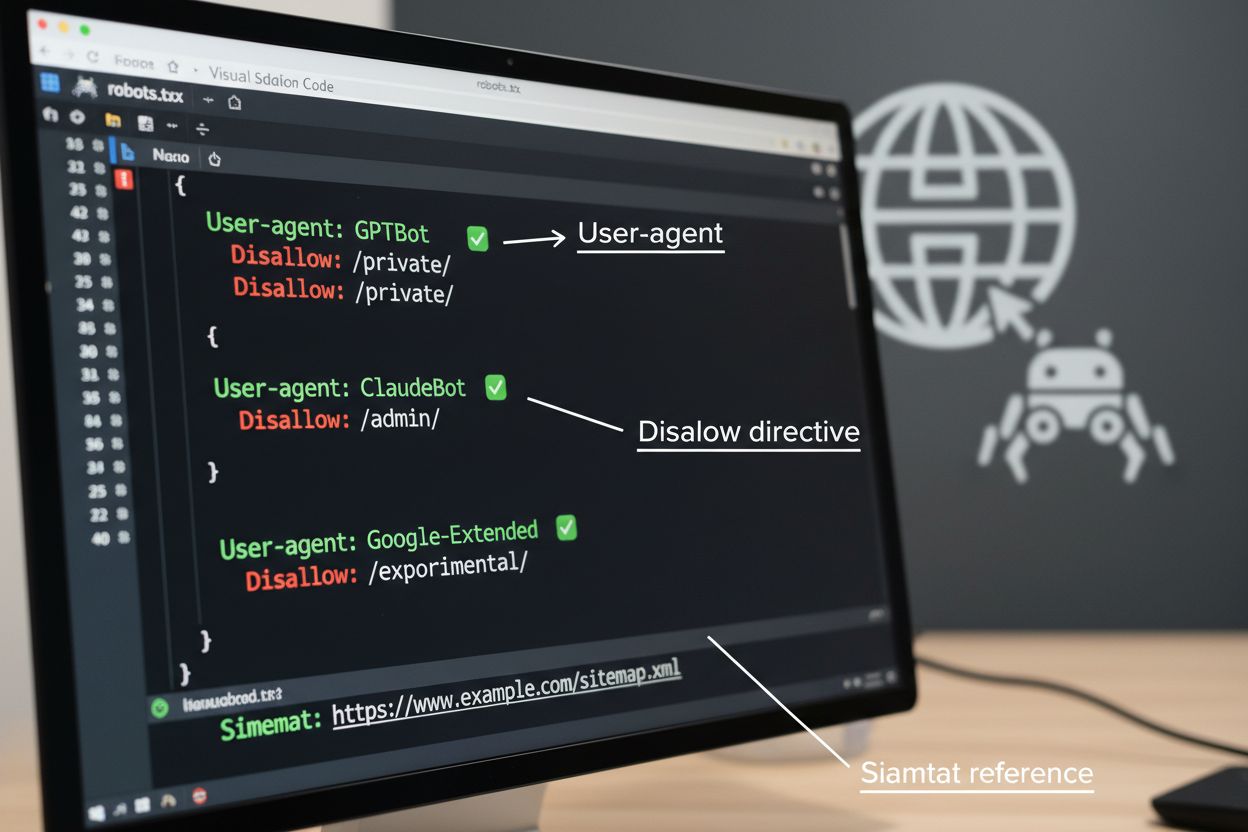
robots.txt-filen er det grundlæggende værktøj til at styre crawler-adgang, placeret i dit websteds rodkatalog for at kommunikere crawlpræferencer til automatiserede agenter. Denne fil bruger User-agent-direktiver til at målrette specifikke crawlere og Disallow- eller Allow-regler til at tillade eller begrænse adgang til bestemte stier og ressourcer. Dog har robots.txt vigtige begrænsninger—det er en frivillig standard, der er afhængig af crawlernes overholdelse, og ondsindede eller dårligt designede bots kan helt ignorere den. Derudover forhindrer robots.txt ikke crawlere i at tilgå offentligt tilgængeligt indhold; den anmoder blot om, at de respekterer dine præferencer. Af disse grunde bør robots.txt være en del af en lagdelt tilgang til crawler management og ikke din eneste forsvarslinje.
# Block AI training crawlers
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# Allow search engines
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Default rule for other crawlers
User-agent: *
Allow: /
Ud over robots.txt tilbyder flere avancerede teknikker stærkere håndhævelse og mere granuleret kontrol over crawler-adgang. Disse metoder fungerer på forskellige lag af din infrastruktur og kan kombineres for omfattende beskyttelse:
Beslutningen om at blokere AI-crawlere indebærer vigtige afvejninger mellem indholdsbeskyttelse og synlighed. At blokere alle AI-crawlere eliminerer muligheden for, at dit indhold vises i AI-søgeresultater, AI-drevne sammendrag eller bliver citeret af AI-værktøjer—hvilket potentielt mindsker synligheden over for brugere, der opdager indhold via disse nye kanaler. Omvendt betyder ubegrænset adgang, at dit indhold bruges til AI-træning uden kompensation og kan mindske henvisningstrafikken, da brugere får svar direkte fra AI-systemer. En strategisk tilgang indebærer selektiv blokering: at tillade citeringscrawlere som OAI-SearchBot og PerplexityBot, der giver henvisningstrafik, mens træningscrawlere som GPTBot og ClaudeBot, der forbruger data uden attribution, blokeres. Du kan også overveje at tillade Google-Extended for at bevare synlighed i Google AI Overviews, som kan generere betydelig trafik, mens konkurrenters træningscrawlere blokeres. Den optimale strategi afhænger af din indholdstype, forretningsmodel og målgruppe—nyhedssider og udgivere kan prioritere blokering, mens uddannelsesindholdsproducenter måske får fordel af bredere AI-synlighed.
Implementering af crawlerkontroller er kun effektivt, hvis du verificerer, at crawlere faktisk overholder dine direktiver. Serverloganalyse er den primære metode til at overvåge crawleraktivitet—undersøg dine adgangslogs for User-Agent-strenge og anmodningsmønstre for at identificere, hvilke crawlere der tilgår dit websted, og om de respekterer dine robots.txt-regler. Mange crawlere påstår overholdelse, men fortsætter med at tilgå blokerede stier, hvilket gør løbende overvågning afgørende. Værktøjer som Cloudflare Radar giver realtidsindsigt i trafikmønstre og kan hjælpe med at identificere mistænkelig eller ikke-overholdende crawleradfærd. Opsæt automatiske advarsler for forsøg på at tilgå blokerede ressourcer, og revider periodisk dine logs for at opfange nye crawlere eller ændrede mønstre, der kan indikere forsøg på unddragelse.
Effektiv AI crawler management kræver en systematisk tilgang, der balancerer beskyttelse med strategisk synlighed. Følg disse otte trin for at etablere en omfattende crawler management-strategi:
AmICited.com tilbyder en specialiseret platform til at overvåge, hvordan AI-systemer refererer til og bruger dit indhold på tværs af forskellige modeller og applikationer. Tjenesten giver realtidssporing af dine citationer i AI-genererede svar og hjælper dig med at forstå, hvilke crawlere der mest aktivt bruger dit indhold, og hvor ofte dit arbejde vises i AI-uddata. Ved at analysere crawlermønstre og citedata gør AmICited.com det muligt at træffe datadrevne beslutninger om din crawler management-strategi—du kan se præcis, hvilke crawlere der giver værdi gennem citationer og henvisninger, versus dem der forbruger indhold uden attribution. Denne indsigt forvandler crawler management fra en defensiv praksis til et strategisk værktøj til at optimere dit indholds synlighed og effekt på det AI-drevne web.
Træningscrawlere som GPTBot og ClaudeBot indsamler indhold for at opbygge datasæt til udvikling af store sprogmodeller og forbruger dit indhold uden at give henvisningstrafik. Søgecrawlere som OAI-SearchBot og PerplexityBot indekserer indhold til AI-drevne søgeresultater og kan sende besøgende tilbage til dit websted gennem citationer. At blokere træningscrawlere beskytter dit indhold mod at blive indarbejdet i AI-modeller, mens blokering af søgecrawlere kan reducere din synlighed på AI-drevne opdagelsesplatforme.
Nej. Blokering af AI-træningscrawlere som GPTBot, ClaudeBot og CCBot påvirker ikke dine Google- eller Bing-søgeplaceringer. Traditionelle søgemaskiner bruger andre crawlere (Googlebot, Bingbot), der fungerer uafhængigt af AI-træningsbots. Blokér kun traditionelle søgecrawlere, hvis du helt vil forsvinde fra søgeresultater, hvilket ville skade din SEO.
Undersøg dine serveradgangslogs for at identificere crawler User-Agent-strenge. Kig efter poster, der indeholder 'bot', 'crawler' eller 'spider' i User-Agent-feltet. Værktøjer som Cloudflare Radar giver realtidsindsigt i, hvilke AI-crawlere der får adgang til dit websted og deres trafikmønstre. Du kan også bruge analyseplatforme, der skelner mellem bottrafik og menneskelige besøgende.
Ja. robots.txt er en rådgivende standard, der er afhængig af crawlernes overholdelse—det er ikke håndhæveligt. Velopdragne crawlere fra store virksomheder som OpenAI, Anthropic og Google respekterer generelt robots.txt-direktiver, men nogle crawlere ignorerer dem helt. For stærkere beskyttelse skal du implementere serverbaseret blokering via .htaccess, firewall-regler eller IP-baserede begrænsninger.
Det afhænger af dine forretningsprioriteter. At blokere alle træningscrawlere beskytter dit indhold mod at blive indarbejdet i AI-modeller, mens du potentielt tillader søgecrawlere, der kan give henvisningstrafik. Mange udgivere bruger selektiv blokering, der målretter træningscrawlere, mens de tillader søge- og citeringscrawlere. Overvej din indholdstype, trafikkilder og indtjeningsmodel, når du beslutter din strategi.
Gennemgå og opdater din crawler management-politik mindst kvartalsvis. Nye AI-crawlere dukker op regelmæssigt, og eksisterende crawlere opdaterer deres brugeragenter uden varsel. Følg ressourcer som ai.robots.txt-projektet på GitHub for fællesskabsvedligeholdte lister, og tjek dine serverlogs månedligt for at identificere nye crawlere, der besøger dit websted.
AI-crawlere kan have stor indvirkning på din trafik og indtjening. Når brugere får svar direkte fra AI-systemer i stedet for at besøge dit websted, mister du henvisningstrafik og tilhørende annoncevisninger. Forskning viser crawl-to-refer-forhold på op til 73.000:1 for nogle AI-platforme, hvilket betyder, at de tilgår dit indhold tusindvis af gange for hver besøgende, de sender tilbage. Blokering af træningscrawlere kan beskytte din trafik, mens tilladelse af søgecrawlere kan give nogle henvisningsfordele.
Tjek dine serverlogs for at se, om blokerede crawlere stadig vises i dine adgangslogs. Brug testværktøjer som Google Search Console's robots.txt-tester eller Merkle's Robots.txt Tester til at validere din konfiguration. Få adgang til din robots.txt-fil direkte på ditdomæne.dk/robots.txt for at verificere, at indholdet er korrekt. Overvåg dine logs regelmæssigt for at fange crawlere, der burde være blokeret, men stadig dukker op.
AmICited.com sporer AI-referencer til dit brand i realtid på tværs af ChatGPT, Perplexity, Google AI Overviews og andre AI-systemer. Tag datadrevne beslutninger om din crawler management-strategi.
Lær at træffe strategiske beslutninger om blokering af AI-crawlere. Vurder indholdstype, trafikkilder, indtægtsmodeller og konkurrenceposition med vores omfatte...

Få indsigt i hvordan AI-crawlere som GPTBot og ClaudeBot fungerer, hvordan de adskiller sig fra traditionelle søgemaskinecrawlere, og hvordan du optimerer dit s...

Lær hvilke AI-crawlere du skal tillade eller blokere i din robots.txt. Omfattende guide, der dækker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med konf...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.