
SearchGPT
Lær hvad SearchGPT er, hvordan det fungerer, og dets indflydelse på søgning, SEO og digital markedsføring. Udforsk funktioner, begrænsninger og fremtiden for AI...
8 min læsning
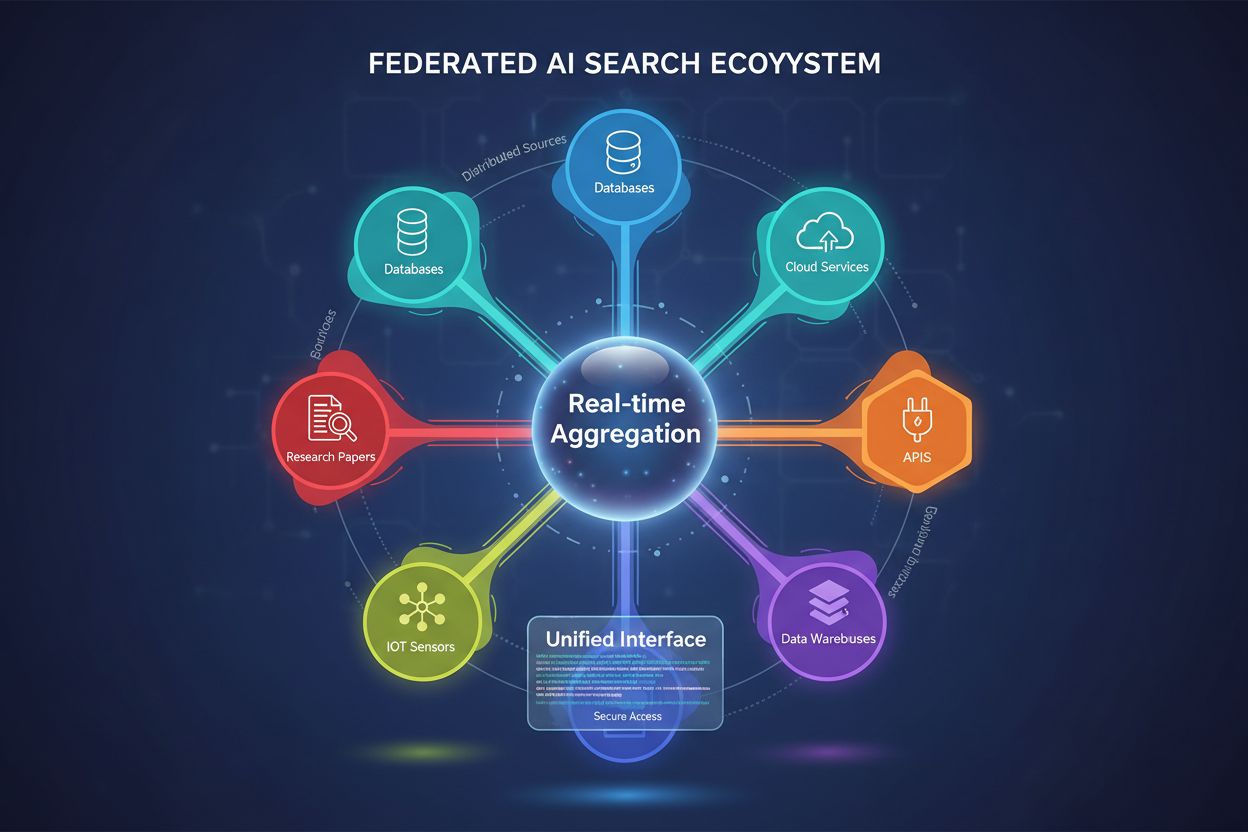
Fødereret AI-søgning er et system, der forespørger flere uafhængige datakilder samtidigt ved hjælp af en enkelt søgeforespørgsel og samler resultater i realtid uden at flytte eller duplikere data. Det gør det muligt for organisationer at få adgang til distribueret information på tværs af databaser, API’er og cloud-tjenester, mens datasikkerhed og compliance opretholdes. I modsætning til traditionelle centraliserede søgemaskiner bevarer fødererede systemer dataautonomi, samtidig med at de giver en samlet informationsopdagelse. Denne tilgang er særligt værdifuld for virksomheder, der håndterer forskellige datakilder på tværs af afdelinger, geografier eller organisationer.
Fødereret AI-søgning er et system, der forespørger flere uafhængige datakilder samtidigt ved hjælp af en enkelt søgeforespørgsel og samler resultater i realtid uden at flytte eller duplikere data. Det gør det muligt for organisationer at få adgang til distribueret information på tværs af databaser, API'er og cloud-tjenester, mens datasikkerhed og compliance opretholdes. I modsætning til traditionelle centraliserede søgemaskiner bevarer fødererede systemer dataautonomi, samtidig med at de giver en samlet informationsopdagelse. Denne tilgang er særligt værdifuld for virksomheder, der håndterer forskellige datakilder på tværs af afdelinger, geografier eller organisationer.
Fødereret AI-søgning er et distribueret informationshentningssystem, der samtidigt forespørger flere heterogene datakilder og intelligent samler resultater ved hjælp af kunstig intelligens. I modsætning til traditionelle centraliserede søgemaskiner, der vedligeholder et enkelt indekseret arkiv, opererer fødereret AI-søgning på tværs af decentrale netværk af uafhængige databaser, vidensbaser og informationssystemer uden at kræve datakonsolidering eller central indeksering.
Kerneprincippet bag fødereret AI-søgning er kildeagnostisk forespørgsel, hvor en enkelt brugerforespørgsel intelligent videresendes til relevante datakilder, behandles uafhængigt af hver kilde og derefter syntetiseres til et samlet resultat. Denne tilgang bevarer dataautonomi, samtidig med at den muliggør omfattende informationsopdagelse på tværs af organisatoriske og tekniske grænser.
Nøglekarakteristika for fødererede AI-søgningssystemer inkluderer:
Distribueret arkitektur: Data forbliver på deres oprindelige placering på tværs af flere arkiver, hvilket fjerner behovet for datamigrering eller centraliseret lagring. Hver kilde vedligeholder sit eget indeks, adgangskontrol og opdateringsmekanismer uafhængigt.
Intelligent forespørgselsrouting: AI-algoritmer analyserer indgående forespørgsler for at afgøre, hvilke kilder der sandsynligvis indeholder relevant information, optimerer søgeeffektivitet og reducerer unødvendige forespørgsler til irrelevante databaser.
Resultatsammenlægning og rangering: Maskinlæringsmodeller syntetiserer resultater fra flere kilder og anvender avancerede rangeringsalgoritmer, der tager hensyn til kilde-troværdighed, resultatrelevans, aktualitet og brugerens kontekst.
Understøttelse af heterogene kilder: Fødererede systemer håndterer forskellige dataformater, skemaer, forespørgselssprog og adgangsprotokoller, herunder relationelle databaser, dokumentlagre, vidensgrafer, API’er og ustrukturerede tekstarkiver.
Integration i realtid: I modsætning til batch-baserede datalagringsmetoder giver fødereret søgning næsten realtidsadgang til aktuel information fra alle tilknyttede kilder, hvilket sikrer opdaterede og nøjagtige resultater.
Semantisk forståelse: Moderne fødereret AI-søgning udnytter naturlig sprogbehandling og semantisk analyse for at forstå forespørgselsintention ud over nøgleords-matchning, hvilket muliggør mere præcis kildevalg og resultatfortolkning.
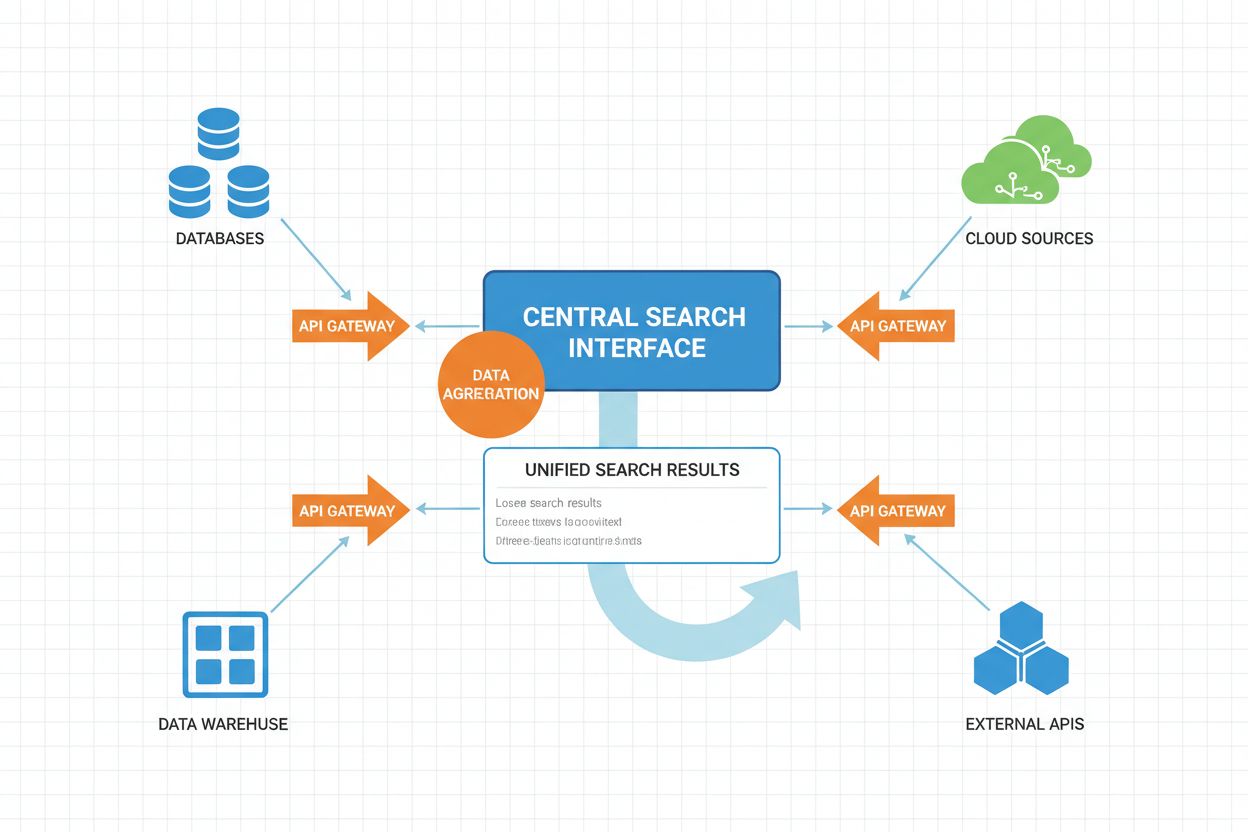
Den operationelle arbejdsgang for fødereret AI-søgning involverer flere koordinerede faser, hver forstærket af kunstig intelligens for at optimere ydeevne og resultatkvalitet.
| Fase | Proces | AI-komponent | Output |
|---|---|---|---|
| Forespørgselsanalyse | Brugerens forespørgsel parses og analyseres for intention, entiteter og kontekst | NLP, navngiven entitetsgenkendelse, intentionklassificering | Struktureret forespørgselsrepræsentation, identificerede entiteter, intentionssignaler |
| Kildevalg | Systemet afgør, hvilke datakilder der er mest relevante for forespørgslen | Maskinlæringsbaserede rangeringsmodeller, kilde-relevansklassificering | Prioriteret liste over mål-kilder, tillidsscorer |
| Forespørgselstranslation | Forespørgslen oversættes til kilde-specifikke formater og sprog | Skema-mapping, forespørgselstranslationsmodeller, semantisk matching | Kilde-specifikke forespørgsler (SQL, SPARQL, API-kald, osv.) |
| Distribueret udførelse | Forespørgsler udføres parallelt på tværs af udvalgte kilder | Load balancing, timeout management, parallel behandling | Rå resultater fra hver kilde, eksekveringsmetadata |
| Resultatnormalisering | Resultater fra forskellige kilder konverteres til fælles format | Skema-tilpasning, datatypekonvertering, formatstandardisering | Normaliseret resultat med ensartet struktur |
| Semantisk berigelse | Resultater udstyres med ekstra kontekst og metadata | Entitetslinking, semantisk tagging, vidensgraf-integration | Berigede resultater med semantiske annotationer |
| Rangering og deduplikering | Resultater rangeres efter relevans og dubletter fjernes | Learning-to-rank-modeller, lighedsdetektion, relevansscoring | Deduplikeret, rangeret resultatliste |
| Personaliseret visning | Resultater tilpasses brugerprofil og præferencer | Collaborative filtering, brugermodellering, kontekstbevidsthed | Personaliseret resultatvisning |
| Præsentation | Resultater formateres til brugergrænsefladen | Naturlig sprog-generering, resultatsummering | Brugerrettet resultatvisning |
Arbejdsgangen er centreret om paralleleksekvering, hvor flere kilder forespørges samtidigt frem for sekventielt. Denne parallelisering reducerer markant den samlede forespørgselslatens trods den ekstra koordinationsomkostning. Avancerede fødererede systemer implementerer adaptiv forespørgselsplanlægning, hvor systemet lærer af historiske forespørgselsmønstre for at optimere kildevalg og eksekveringsstrategier over tid.
Timeout- og fallback-mekanismer er kritiske komponenter for systemets pålidelighed. Når en kilde svarer langsomt eller fejler, kan systemet enten vente med adaptive timeouts eller fortsætte med resultater fra tilgængelige kilder, så resultatet forringes yndefuldt frem for at fejle helt.
Fødererede AI-søgningssystemer kan kategoriseres efter flere dimensioner:
Efter arkitekturmodel:
Efter datakildetype:
Efter omfang og skala:
Efter intelligensniveau:
Dataautonomi og datastyring: Organisationer bevarer kontrollen over deres data og eliminerer behovet for at overføre følsomme informationer til centraliserede arkiver. Dette opretholder datastyringspolitikker, overholdelseskrav og sikkerhedskontroller på kilde-niveau.
Skalerbarhed uden konsolidering: Fødererede systemer skaleres ved at tilføje nye kilder uden at kræve datamigrering eller omstrukturering af datalagre. Organisationer kan således integrere nye datakilder gradvist efter forretningsbehov.
Adgang til information i realtid: Ved at forespørge kilder direkte giver fødereret søgning adgang til aktuel information uden den forsinkelse, der er forbundet med batch-baseret datalagring. Dette er især værdifuldt for tidskritiske applikationer.
Omkostningseffektivitet: Eliminerer betydelige infrastruktur- og driftsomkostninger forbundet med opbygning og vedligeholdelse af centraliserede datalagre. Organisationer undgår datadublering, redundant lagring og komplekse ETL-processer.
Reduceret dataredundans: I modsætning til datalagring, hvor data duplikeres på tværs af systemer, bevarer fødereret søgning én sandhedskilde, hvilket reducerer lagerbehov og sikrer konsistens.
Fleksibilitet og tilpasningsevne: Nye kilder kan integreres uden ændring af eksisterende infrastruktur eller re-indeksering af centrale arkiver. Denne fleksibilitet gør det muligt hurtigt at reagere på nye forretningskrav.
Forbedret datakvalitet: Ved at forespørge autoritative kilder direkte reducerer fødereret søgning datastagnation og inkonsistens, som kan opstå ved periodisk datasynkronisering i lagringsløsninger.
Øget sikkerhed: Følsomme data forlader aldrig deres oprindelige placering, hvilket mindsker risikoen for uautoriseret adgang eller brud. Adgangskontrol forbliver på kilde-niveau frem for centraliserede systemer.
Understøttelse af heterogene kilder: Fødererede systemer håndterer forskellige teknologier, formater og protokoller uden at kræve standardisering eller migrering til fælles platforme.
Intelligent resultatsyntese: AI-drevne rangerings- og sammenlægningsalgoritmer giver resultater af højere kvalitet end simpel sammenlægning, idet der tages hensyn til kilde-troværdighed, relevans og brugerens kontekst.
Moderne fødererede AI-søgningssystemer består af flere sammenhængende tekniske komponenter, der arbejder sammen om at levere integreret søgefunktionalitet.
Forespørgselsbehandlingsmotor: Den centrale komponent, der modtager brugerforespørgsler og orkestrerer fødereret søgearbejdsgang. Denne motor indeholder forespørgselsanalyse, semantisk analyse og intentionsgenkendelse. Avancerede systemer bruger transformerbaserede sproglige modeller til at forstå komplekse forespørgsler og implicit brugerintention.
Kilde-register og metadatastyring: Vedligeholder omfattende metadata om tilgængelige datakilder, inklusiv skemainformation, indholdskarakteristika, opdateringsfrekvens, tilgængelighedsmønstre og ydelsesstatistikker. Dette register muliggør intelligent kildevalg og optimering. Maskinlæringsmodeller analyserer historiske forespørgselsmønstre for at forudsige kilderelevans til nye forespørgsler.
Intelligent kildevalg-modul: Bruger maskinlæringsklassificeringer til at afgøre, hvilke kilder der sandsynligvis indeholder relevant information til en given forespørgsel. Modulet tager højde for flere faktorer, herunder kildeindhold, historisk succesrate, tilgængelighed og forventet svartid. Avancerede systemer anvender reinforcement learning for løbende at optimere kildevalg baseret på resultater.
Forespørgselstranslation og tilpasningslag: Konverterer brugerforespørgsler til kilde-specifikke formater og forespørgselssprog. Dette inkluderer SQL-generering for relationelle databaser, SPARQL for vidensgrafer, REST-API-kald for webtjenester og naturlige sprogforespørgsler for ustrukturerede systemer. Semantisk mapping sikrer, at forespørgselsintention bevares på tværs af sprog og datamodeller.
Distribueret eksekveringskoordinator: Styrer parallel forespørgselsudførelse på tværs af flere kilder, håndterer timeout management, load balancing og fejlhåndtering. Denne komponent implementerer adaptive timeout-strategier, der tilpasses efter kildesvarsmønstre og systembelastning.
Resultatnormaliseringsmotor: Konverterer resultater fra heterogene kilder til et fælles format til sammenlægning og rangering. Dette omfatter skema-tilpasning, datatypekonvertering og formatstandardisering. Motoren håndterer manglende felter, modstridende datatyper og strukturforskelle.
Semantisk berigelsesmodul: Beriger resultater med ekstra kontekst og semantisk information, f.eks. entitetslinking til vidensbaser, semantisk tagging via ontologier og relationsudtræk fra tekst. Disse berigelser forbedrer rangeringsnøjagtighed og forståelighed.
Learning-to-rank-model: En maskinlæringsmodel trænet på historiske forespørgsels-resultat-par for at forudsige resultatrelevans. Modellen betragter flere hundrede features, inklusiv kilde-troværdighed, indholdsaktualitet, brugerprofil og semantisk lighed mellem forespørgsel og resultat. Moderne systemer bruger gradient boosting eller neurale netværksbaserede rangeringsmodeller.
Deduplikationsmotor: Identificerer og fjerner dublerede eller næsten dublerede resultater fra forskellige kilder ved hjælp af lighedsmetrikker, f.eks. eksakt match, fuzzy string matching og semantisk lighed baseret på embedding.
Personaliseringsmotor: Tilpasser resultatrækkefølge baseret på brugerprofiler, historiske præferencer og kontekst. Komponenten anvender collaborative filtering og indholdsanbefaling for at forbedre relevansen for den enkelte bruger.
Caching- og optimeringslag: Implementerer intelligent caching for at reducere overflødige forespørgsler til kilder. Dette dækker cache af forespørgselsresultater, kilde-metadata og lærte forespørgselsmønstre, der forudsiger fremtidige informationsbehov.
Overvågnings- og analysmodul: Overvåger systemydelse, kildepålidelighed, forespørgselsmønstre og resultatkvalitetsmålinger. Disse data bruges løbende til at optimere systemet.
Sundhedsvæsen og medicinsk forskning: Fødereret søgning integrerer patientjournaler på tværs af hospitalssystemer, forskningsdatabaser, kliniske forsøgsregistre og medicinske litteraturarkiver. Læger kan forespørge komplette patienthistorikker uden at centralisere følsomme data. Forskere får adgang til distribuerede kliniske data til epidemiologiske studier, mens HIPAA og patientprivatliv opretholdes.
Finansielle tjenester: Banker og investeringsvirksomheder bruger fødereret søgning til at forespørge handelsdata, markedsinformation, regulatoriske databaser og interne transaktionsregistre samtidigt. Dette muliggør risikovurdering, compliance-overvågning og markedsanalyse i realtid uden at konsolidere følsomme finansielle data.
Jura og compliance: Advokatfirmaer og juridiske afdelinger søger på tværs af domsdatabase, regulatoriske registre, interne dokumentstyringssystemer og kontraktarkiver. Fødereret søgning muliggør omfattende juridisk research, mens fortrolighed og dokumentbeskyttelse opretholdes.
E-handel og detail: Onlineforhandlere integrerer produktkataloger på tværs af lagre, leverandørsystemer og markedspladser. Fødereret søgning giver samlet produktsøgning, mens leverandører bevarer uafhængige lagre og prisstrategier.
Offentlig forvaltning: Myndigheder søger i distribuerede databaser som folketællinger, skatteregistre, tilladelser og offentlige registre uden at centralisere borgerdata. Dette muliggør omfattende offentlig service, mens datasikkerhed og privatliv sikres.
Produktion og forsyningskæde: Produktionsvirksomheder integrerer leverandørdatabaser, lagerstyringssystemer, produktionsregistrering og logistikplatforme. Fødereret søgning skaber forsyningskædeoverblik, mens partnere bevarer uafhængige systemer og fortrolige oplysninger.
Uddannelse og forskning: Universiteter søger i institutionelle arkiver, bibliotekssystemer, forskningsdatabaser og åbne publikationer. Fødereret søgning muliggør omfattende akademisk research, mens institutionel autonomi og ophavsret respekteres.
Telekommunikation: Teleselskaber søger i kundedatabaser, netværksinfrastruktur, faktureringssystemer og servicekataloger. Fødereret søgning skaber samlet kundeservice, mens separate systemer bevares for forskellige forretningsområder og geografiske regioner.
Energi og forsyning: Energiselskaber søger i produktionsanlæg, distributionsnet, kundedatabaser og overholdelsesystemer. Fødereret søgning giver operationelt overblik, mens regionale operatører bevarer uafhængige systemer.
Medier og udgivelse: Medievirksomheder søger i indholdsarkiver, rettighedsstyring og distributionsplatforme. Fødereret søgning muliggør samlet indholdsopdagelse, mens ejerskab og licensforhold bevares.
Kildeheterogenitet og integrationskompleksitet: Integrering af forskellige datakilder med forskellige skemaer, forespørgselssprog og protokoller kræver betydelig teknisk indsats. Skema-mapping og semantisk tilpasning er udfordrende, især når kilder repræsenterer samme begreb forskelligt.
Forespørgselslatens og ydeevne: Fødereret søgning involverer flere kilder og er derfor langsommere end centraliserede systemer. Langsomme eller utilgængelige kilder kan forringe ydeevnen. Timeout management kræver finjustering for at balancere fuldstændighed og hurtighed.
Kildepålidelighed og tilgængelighed: Systemet afhænger af, at eksterne kilder er tilgængelige og reagerer hurtigt. Netværksfejl, nedetid eller ydelsesforringelse påvirker straks søgekvalitet. Yndefuld degradering er nødvendig, når kilder fejler.
Resultatkvalitet og rangeringsnøjagtighed: Sammenlægning af resultater fra kilder med forskellig kvalitet, dækning og relevanskriterier er udfordrende. Rangeringsmodeller skal tage højde for variationer i kilde-troværdighed og undgå bias mod bestemte kilder.
Dataaktualitet og konsistens: Fødererede systemer tilgår aktuelle data, men opdateringsfrekvens og konsistensgarantier varierer. Forlig af modstridende information kræver avancerede konfliktløsningsstrategier.
Skaleringsbegrænsninger: Når antallet af kilder stiger, vokser koordinationsomkostningen. Udvælgelse af relevante kilder blandt tusinder bliver ressourcekrævende. Parallel eksekvering kræver robust infrastruktur.
Sikkerhed og adgangskontrol: Systemet skal håndhæve adgangskontrol på kilde-niveau, mens en samlet søgegrænseflade tilbydes. At sikre, at brugere kun ser information, de har adgang til, er komplekst, især i multi-tenant-miljøer.
Privatliv og databeskyttelse: Fødereret søgning skal overholde databeskyttelsesregler som GDPR, CCPA og brancheregler. At sikre, at følsomme data ikke lækkes gennem resultatsammenlægning eller metadataanalyse, kræver omhyggeligt design.
Kildeopdagelse og -styring: Identifikation, katalogisering og vedligeholdelse af kildemetadata samt styring af kilders livscyklus kræver vedvarende driftsindsats.
Semantisk interoperabilitet: Ægte semantisk interoperabilitet på tværs af kilder med forskellige ontologier og datamodeller er fortsat udfordrende. Automatiseret skema-mapping og entitetsresolution har begrænsninger.
Koordinationsomkostninger: Fødereret søgning eliminerer konsolideringsomkostninger, men introducerer koordinationsomkostninger. Håndtering af distribueret eksekvering, fejl og routing kræver avanceret infrastruktur.
Begrænset standardisering: Manglen på universelle standarder for fødererede søgeprotokoller og grænseflader gør integration vanskeligere og øger risikoen for leverandørlåsning.
Fødereret AI-søgning vs. datalagring: Datalagring konsoliderer data fra flere kilder i et centraliseret arkiv, hvilket muliggør hurtige forespørgsler, men kræver omfattende ETL-arbejde og introducerer forsinkelse. Fødereret søgning forespørger kilder direkte og giver adgang i realtid, men med højere latenstid. Warehousing egner sig til historisk analyse og rapportering, mens fødereret søgning er bedst til aktuel opdagelse.
Fødereret AI-søgning vs. data lakes: Data lakes lagrer rå data fra flere kilder i et centraliseret miljø med minimal transformation. De giver fleksibilitet, men kræver betydelig lager- og styringsindsats. Fødereret søgning undgår konsolidering, bevarer kildeautonomi, men kræver mere avanceret forespørgselsbehandling.
Fødereret AI-søgning vs. API’er og mikrotjenester: API’er giver programmatisk adgang til enkeltstående tjenester, men kræver kendskab til hver tjenestes interface. Fødereret søgning abstraherer kildespecifikke detaljer og muliggør samlet forespørgsel på tværs af tjenester. API’er egner sig til applikationsintegration, mens fødereret søgning muliggør tværgående informationsopdagelse.
Fødereret AI-søgning vs. vidensgrafer: Vidensgrafer repræsenterer information som forbundne entiteter og relationer og muliggør semantisk ræsonnement. Fødereret søgning kan forespørge distribuerede vidensgrafer uden at kræve centraliseret grafkonstruktion. Vidensgrafer giver dybere semantisk forståelse, mens fødereret søgning vægter kildeautonomi.
Fødereret AI-søgning vs. søgemaskiner: Traditionelle søgemaskiner vedligeholder centraliserede indekser over crawlet indhold. Fødereret søgning forespørger kilder direkte uden forhåndsindeksering. Søgemaskiner dækker offentligt indhold, mens fødereret søgning er bedst til private, proprietære eller specialiserede kilder.
Fødereret AI-søgning vs. master data management (MDM): MDM-systemer skaber autoritative master records ved at konsolidere data fra flere kilder. Fødereret søgning forespørger kilder uafhængigt uden at oprette master records. MDM egner sig til datastyring og konsistens, mens fødereret søgning vægter kildeautonomi og adgang i realtid.
Fødereret AI-søgning vs. enterprise search: Enterprise search indekserer typisk interne dokumenter og databaser i et centraliseret indeks. Fødereret søgning forespørger kilder direkte uden central indeksering. Enterprise search giver hurtig fuldtekstsøgning, mens fødereret søgning understøtter forskellige kildetyper og realtidsopdateringer.
Fødereret AI-søgning vs. blockchain og distribuerede registre: Blockchain opretholder distribueret konsensus og sikrer dataintegritet og uforanderlighed. Fødereret søgning koordinerer forespørgsler på tværs af uafhængige kilder uden konsensus. Blockchain egner sig til tillid og verifikation, mens fødereret søgning vægter informationsopdagelse.
Omfattende kildevurdering: Vurder alle kilders egenskaber grundigt, herunder datakvalitet, opdateringsfrekvens, tilgængelighed, skemakompleksitet og adgangsprotokoller, før integration. Dette informerer kildevalg og sætter realistiske forventninger til ydeevne.
Trinvis integration: Start med få, velkendte kilder og udvid gradvist systemet. Dette gør det lettere at identificere udfordringer tidligt og optimere processen, før der skal skaleres.
Robust metadatastyring: Invester i omfattende kildemetadata om skema, indholdsdækning, kvalitetsmålinger og ydels
Traditionel centraliseret søgning konsoliderer alle data i et enkelt indekseret arkiv, hvilket kræver datamigrering og introducerer forsinkelse. Fødereret AI-søgning forespørger flere uafhængige kilder direkte i realtid uden at flytte eller duplikere data, hvilket bevarer kildeautonomi, mens der gives samlet adgang. Dette gør fødereret søgning ideel til organisationer med distribuerede datakilder og strenge krav til datastyring.
Fødereret AI-søgning holder data på deres oprindelige placering og respekterer hver kildes adgangskontrol og sikkerhedspolitikker. Brugere får kun adgang til information, de er autoriseret til at se, og følsomme data forlader aldrig deres kildesystem. Denne tilgang forenkler overholdelse af regler som GDPR og HIPAA ved at eliminere risici forbundet med centralisering af følsomme oplysninger.
Nøgleudfordringer omfatter håndtering af heterogene datakilder med forskellige skemaer og formater, håndtering af forespørgselsforsinkelse fra flere kilder, sikring af ensartet resultatrangering på tværs af kilder samt opretholdelse af systempålidelighed, når kilder er utilgængelige. Organisationer skal også investere i robust metadatastyring og intelligente kildevalgsalgoritmer for at optimere ydeevnen.
Ja, fødereret AI-søgning skaleres ved at tilføje nye kilder uden at kræve datamigrering eller omstrukturering af datalagre. Dog stiger koordineringsomkostningerne for forespørgsler, efterhånden som antallet af kilder øges. Moderne systemer bruger maskinlæring til intelligent kildevalg og implementerer caching-strategier for at opretholde ydeevnen ved skala.
Data warehousing konsoliderer data i et centraliseret arkiv, hvilket muliggør hurtige forespørgsler, men kræver betydelig ETL-indsats og introducerer dataforsinkelse. Fødereret søgning forespørger kilder direkte og giver adgang i realtid, men med højere forespørgselsforsinkelse. Warehousing egner sig til historisk analyse og rapportering, mens fødereret søgning er bedst til aktuel informationsopdagelse på tværs af distribuerede kilder.
Sundhedsvæsen, finans, e-handel, offentlige myndigheder og forskningsorganisationer har betydelig fordel af fødereret søgning. Sundhedsvæsen bruger det til at integrere patientjournaler på tværs af udbydere, finans bruger det til compliance og risikovurdering, e-handel bruger det til samlet produktopdagelse, og forskningsorganisationer bruger det til at søge i distribuerede akademiske databaser.
AI forbedrer fødereret søgning via naturlig sprogbehandling for forespørgselsforståelse, maskinlæring til intelligent kildevalg, semantisk analyse for bedre rangering og automatisk deduplikering. AI-modeller lærer af forespørgselsmønstre for løbende at optimere kildevalg og resultatsammenlægning, hvilket forbedrer systemets ydeevne over tid.
Semantisk forståelse gør det muligt for fødererede systemer at forstå forespørgslens hensigt ud over blot nøgleords-matchning, identificere relevante kilder mere præcist og rangere resultater baseret på betydning i stedet for kun nøgleords-overlap. Dette omfatter entitetsgenkendelse, relationsudtræk og integration af vidensgrafer, hvilket resulterer i mere relevante og kontekstuelt passende søgeresultater.
AmICited sporer, hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews citerer og refererer til dit brand. Forstå din AI-synlighed og optimer din tilstedeværelse i AI-genererede svar.
Lær hvad SearchGPT er, hvordan det fungerer, og dets indflydelse på søgning, SEO og digital markedsføring. Udforsk funktioner, begrænsninger og fremtiden for AI...

Lær hvordan du beregner AI search ROI med dokumenterede målinger, formler og frameworks. Mål brandets synlighed i ChatGPT, Perplexity og andre AI svarmotorer ef...
Lær hvordan du kommer i gang med Generative Engine Optimization (GEO) i dag. Opdag essentielle strategier til at optimere dit indhold til AI-søgemaskiner som Ch...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.