
Perplexity Spaces
Lær om Perplexity Spaces, samarbejdsmiljøer til forskning, der kombinerer AI-drevet søgning med teamfunktioner til at organisere og dele forskning om specifikke...
6 min læsning

Gemte grupper af AI-genererede svar og kilder i Perplexity, der skaber kuraterede vidensbaser om specifikke emner. Samlinger giver brugere mulighed for at organisere forskning efter emne, gemme vigtige svar med kildehenvisninger og opbygge personlige vidensarkiver for effektiv informationshåndtering.
Gemte grupper af AI-genererede svar og kilder i Perplexity, der skaber kuraterede vidensbaser om specifikke emner. Samlinger giver brugere mulighed for at organisere forskning efter emne, gemme vigtige svar med kildehenvisninger og opbygge personlige vidensarkiver for effektiv informationshåndtering.
Perplexity-samlinger er kuraterede arkiver af AI-genererede svar og deres tilhørende kilder, som brugere kan gemme, organisere og referere til i fremtiden. De fungerer som personlige vidensbaser, hvor brugere samler forskning, indsigter og information om specifikke emner inden for Perplexity-platformen. Samlinger bevarer den fulde kontekst af hvert svar, inklusive kildehenvisninger og kildemateriale, hvilket gør brugere i stand til at opbygge omfattende forskningsarkiver uden at miste vigtig kildeinformation. Denne funktion forvandler Perplexity fra et enkelt forespørgselsværktøj til et vedvarende vidensstyringssystem tilpasset individuelle forskningsbehov.
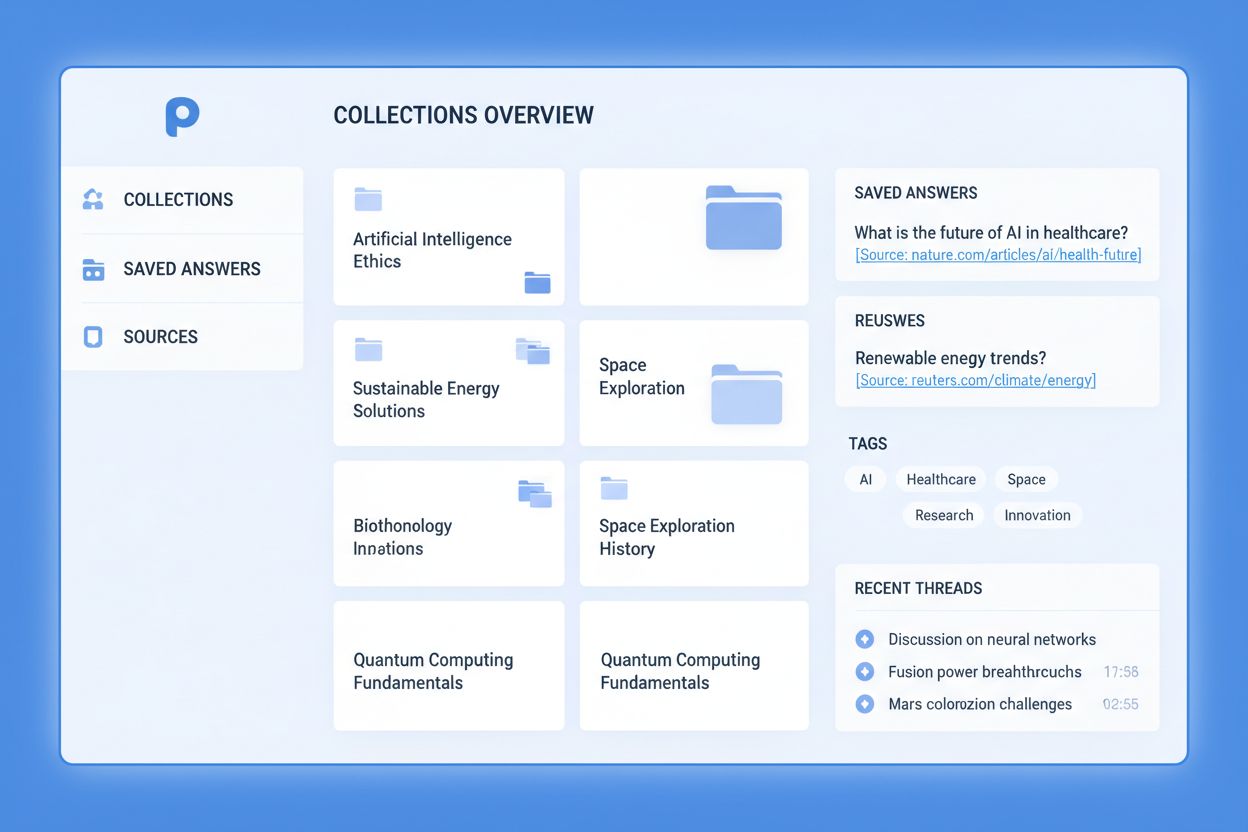
Perplexity-samlinger har udviklet sig betydeligt i takt med, at platformen er modnet, med introduktionen af Spaces som næste generation af denne funktion. Spaces tilbyder forbedret funktionalitet, herunder filuploads, mere detaljerede delingskontroller og avancerede samarbejdsfunktioner, hvilket placerer dem som premium-udgaven af samlinger. Samlinger forbliver dog fuldt funktionsdygtige og er bredt anvendt i hele Perplexity-økosystemet, især blandt brugere på Pro- og Enterprise-abonnementer, som foretrækker det enkle interface eller har etablerede arbejdsgange omkring den oprindelige funktion. Navngivningsskellet afspejler Perplexitys engagement i at tilbyde flere organisatoriske værktøjer, der passer til forskellige brugerbehov og kompleksitetsniveauer.
| Funktion | Samlinger | Spaces |
|---|---|---|
| Gem svar | Ja | Ja |
| Organiser efter emne | Ja | Ja |
| Brugerdefinerede prompts | Ja | Ja |
| Filuploads | Nej | Ja |
| Avanceret deling | Grundlæggende | Avanceret |
| Samarbejdsværktøjer | Begrænsede | Udvidede |
| Tilgængelige abonnementer | Pro, Enterprise | Pro, Enterprise |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Samlinger tilbyder en komplet pakke af organisatoriske og forskningsværktøjer designet til at maksimere produktivitet og vidensbevarelse. Funktionen gem svar gør det muligt for brugere at indfange AI-genererede svar med et enkelt klik og bevare det nøjagtige indhold og kontekst på skabelsestidspunktet. Emnebaseret organisering giver brugerne mulighed for at kategorisere svar i logiske grupper, hvilket gør det intuitivt og effektivt at finde frem til information på tværs af store samlinger. Med funktionen brugerdefinerede prompts kan brugere definere specifikke forespørgselskabeloner inden for samlinger, hvilket sikrer en ensartet forskningsmetode og reducerer gentaget indtastning ved ofte stillede spørgsmål. Samarbejdsfunktioner gør det muligt for brugere at dele samlinger med teammedlemmer og understøtter gruppebaserede forskningsprojekter samt distribueret vidensstyring. Samlet set forvandler disse muligheder spredt forskning til en struktureret, tilgængelig og delbar vidensressource.
Arbejdsprocessen med samlinger følger en intuitiv firetrins-proces, der integreres problemfrit i Perplexitys forskningsoplevelse. Når brugere støder på et værdifuldt svar under deres Perplexity-søgninger, kan de straks gemme det i en eksisterende samling eller oprette en ny med én handling. Systemet bevarer automatisk hele svarteksten, alle tilhørende kildehenvisninger og metadata om, hvornår svaret blev gemt og fra hvilken forespørgsel det stammer. Brugere kan derefter organisere disse gemte svar i deres samlinger ved hjælp af brugerdefinerede tags, mapper eller emnehierarkier afhængigt af deres organisatoriske præferencer. Når de vender tilbage til en samling, kan brugerne hurtigt gennemgå alle gemte svar, få adgang til de oprindelige kilder og endda bruge gemte svar som kontekst for opfølgende forespørgsler. Bevarelsen af kildeinformation sikrer, at brugerne opretholder fulde kildekæder – kritisk for akademisk forskning, indholdsproduktion og professionel dokumentation. Denne arbejdsgang forvandler Perplexity fra et tilstandsløst spørgsmål-svar-værktøj til en vedvarende forskningsplatform, hvor viden akkumuleres og bliver mere værdifuld over tid.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Samlinger tjener mange professionelle og akademiske behov på tværs af brugergrupper, der hver især udnytter funktionen til at løse forskellige organisatoriske udfordringer:
Forskere og akademikere: Saml litteraturgennemgange, organiser resultater efter forskningsspørgsmål, oprethold kildekæder til artikler og byg emnespecifikke vidensbaser, som støtter specialeudvikling og akademisk skrivning.
Indholdsskabere og journalister: Indsaml baggrundsforskning, organiser kildemateriale efter artiklens emne, oprethold faktatjek-referencer og skab genanvendelige forskningsbiblioteker, som accelererer indholdsproduktion.
Erhvervsfolk og analytikere: Byg konkurrentdatabaser, organiser markedsundersøgelser efter branche, oprethold kundespecifikke forskningsarkiver og skab institutionelle vidensbaser, som består på tværs af teams.
Studerende og lærende: Organiser studiemateriale efter fag, saml forskning til opgaver, vedligehold læringsressourcer på tværs af flere kurser og skab personlige vidensbaser, der understøtter langsigtet akademisk succes.
Oprettelse af en samling i Perplexity kræver minimal indsats, men giver større udbytte ved gennemtænkt planlægning og organisering. Brugere starter en ny samling ved at vælge gem-indstillingen på et svar og vælge at oprette en ny samling, hvor de tilføjer et beskrivende navn og eventuelt en beskrivelse, der præciserer samlingens formål og omfang. Effektive navnekonventioner følger typisk en hierarkisk struktur – for eksempel “Markedsanalyse > Teknologisektor > AI-adoption 2024” – hvilket letter navigationen, når samlinger bliver mange. Efterhånden som samlinger vokser, bør brugerne med jævne mellemrum gennemgå og reorganisere indholdet, samle beslægtede svar og fjerne forældet information for at bevare relevans og søgbarhed. De mest succesfulde samlinger anvender konsekvente taggingssystemer og klar organisatorisk logik, der matcher brugerens naturlige tankegang om forskningsområdet. Regelmæssig vedligeholdelse sikrer, at samlinger forbliver værdifulde referenceværktøjer frem for at ende som rodede arkiver med forældet information.
Samlinger giver betydelige fordele for produktivitet og vidensstyring, som vokser over tid i takt med, at brugere opbygger omfattende forskningsarkiver. Tidsbesparelsen ved at undgå gentagen forskning er markant – brugere kan henvise til tidligere indsamlede svar i stedet for at gentage de samme forespørgsler, hvilket accelererer projekter og mindsker kognitiv belastning. Vidensbevarelsen forbedres betydeligt, når forskning er organiseret og tilgængelig; brugere tilegner sig viden mere effektivt, når de kan gennemgå og krydsreferere svar systematisk. Forskningseffektiviteten øges, efterhånden som samlinger bliver mere omfattende, idet brugerne bygger videre på tidligere arbejde frem for at starte forfra ved nye projekter. Kildebevarelsen i samlinger sikrer, at brugerne opretholder korrekt kildeangivelse og kan verificere information ved at vende tilbage til de oprindelige kilder – afgørende for troværdighed i professionelle og akademiske sammenhænge. Samarbejdsfordele opstår, når teams deler samlinger, hvilket muliggør distribuerede forskningsindsatser og sikrer, at institutionsviden overlever udskiftning af teammedlemmer. Den samlede effekt er en transformation fra kortvarig spørgsmål-besvarelse til vedvarende, organiseret og delbar vidensstyring, der bliver mere værdifuld, jo mere den vokser.

Samlinger udgør et vigtigt berøringspunkt for forståelsen af, hvordan information flyder gennem AI-drevne forskningsplatforme, og hvordan brands, produkter og idéer citeres i disse systemer. I takt med, at samlinger samler svar fra Perplexitys AI, skaber de en permanent registrering af, hvordan platformen syntetiserer og præsenterer information om specifikke emner – herunder hvilke kilder der får fremtræde, og hvordan forskellige perspektiver repræsenteres. For organisationer og brands er det blevet essentielt at overvåge, hvordan deres indhold optræder i Perplexity-samlinger – og dermed hvordan det citeres og kontekstualiseres i AI-genererede svar – for at forstå deres synlighed og troværdighed i det AI-drevne informationslandskab. AmICited.com er specialiseret i at spore, hvordan brands, virksomheder og indholdsskabere citeres og repræsenteres på tværs af AI-svar-platforme, herunder overvågning af deres tilstedeværelse i brugeroprettede samlinger og delte forskningsarkiver. Forståelse af dynamikker i samlinger hjælper organisationer med at identificere muligheder for at forbedre deres kildehenvisninger, verificere korrekt repræsentation af deres produkter og services og opdage huller, hvor deres ekspertise bør være mere fremtrædende i AI-genereret forskning.
AmICited sporer, hvordan dit indhold bliver refereret og citeret på tværs af AI-platforme, herunder Perplexity. Opdag om dit brand vises i AI-genererede svar og samlinger.
Lær om Perplexity Spaces, samarbejdsmiljøer til forskning, der kombinerer AI-drevet søgning med teamfunktioner til at organisere og dele forskning om specifikke...
Perplexity-trafik forklaret: besøgende fra Perplexity AI-søgemaskinen. Lær at spore, måle og optimere for AI-drevet henvisningstrafik fra citater.

Lær om Perplexity Fokus-tilstande – specialiserede søgefiltre, der prioriterer Akademiske, Skrivning, Wolfram, YouTube og Reddit-kilder. Opdag hvordan du bruger...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.