
Vergleichsartikel: Das meistzitierte Content-Format in der KI-Suche
Erfahren Sie, warum Vergleichsartikel das leistungsstärkste Content-Format in der KI-Suche sind. Lernen Sie, wie Sie Vergleichs-Content für ChatGPT-, Perplexity...
8 Min. Lesezeit

Erfahren Sie, wie Sie Inhaltsformate für KI-Zitate mit der A/B-Testing-Methode testen. Entdecken Sie, welche Formate die höchste KI-Sichtbarkeit und Zitatraten in ChatGPT, Google AI Overviews und Perplexity erzielen.
Künstliche Intelligenz verarbeitet Inhalte grundlegend anders als menschliche Leser und ist auf strukturierte Signale angewiesen, um Bedeutung zu verstehen und Informationen extrahieren zu können. Während Menschen kreative Formatierungen oder dichte Prosa bewältigen, benötigen KI-Modelle klare Hierarchien und semantische Marker, um Inhalte effektiv zu parsen und ihren Wert zu erfassen. Studien zeigen, dass strukturierte Inhalte mit korrekten Überschriftenhierarchien um 156 % häufiger zitiert werden als unstrukturierte Alternativen – ein entscheidender Unterschied zwischen menschen- und KI-freundlichen Inhalten. Diese Diskrepanz entsteht, weil KI-Systeme auf riesigen Datensätzen trainiert werden, in denen gut organisierte Inhalte meist mit autoritativen, vertrauenswürdigen Quellen korrelieren. Das Verständnis und Testen verschiedener Inhaltsformate ist für Marken, die Sichtbarkeit in KI-gesteuerten Suchergebnissen und Antwortmaschinen anstreben, unerlässlich geworden.
Verschiedene KI-Plattformen zeigen unterschiedliche Präferenzen bei Quellen und Formaten, was die Optimierung komplex macht. Untersuchungen mit 680 Millionen Zitaten auf den wichtigsten Plattformen zeigen deutliche Unterschiede darin, wie ChatGPT, Google AI Overviews und Perplexity ihre Informationen beziehen. Diese Plattformen zitieren nicht einfach dieselben Quellen – sie priorisieren verschiedene Inhaltstypen basierend auf ihren Algorithmen und Trainingsdaten. Das Verständnis dieser plattformspezifischen Muster ist entscheidend, um gezielte Content-Strategien zu entwickeln, die die Sichtbarkeit über mehrere KI-Systeme hinweg maximieren.
| Plattform | Meistzitierte Quelle | Zitat-Anteil | Bevorzugtes Format |
|---|---|---|---|
| ChatGPT | Wikipedia | 7,8 % aller Zitate | Autoritative Wissensdatenbanken, enzyklopädische Inhalte |
| Google AI Overviews | 2,2 % aller Zitate | Community-Diskussionen, nutzergenerierte Inhalte | |
| Perplexity | 6,6 % aller Zitate | Peer-to-Peer-Informationen, Community-Insights |
ChatGPTs überwältigende Präferenz für Wikipedia (47,9 % der Top-10-Quellen) zeigt eine starke Tendenz zu autoritativen, faktenbasierten Inhalten mit etablierter Glaubwürdigkeit. Im Gegensatz dazu zeigen Google AI Overviews und Perplexity ausgewogenere Verteilungen, wobei Reddit ihre Zitatmuster dominiert. Das zeigt: Perplexity priorisiert community-getriebene Informationen mit 46,7 % der Top-Quellen, während Google einen diverseren Ansatz über verschiedene Plattformtypen verfolgt. Die Daten machen deutlich, dass eine universelle Content-Strategie nicht funktionieren kann – Marken müssen ihren Ansatz auf die für ihre Zielgruppe wichtigsten KI-Plattformen abstimmen.
Schema-Markup ist vielleicht der wichtigste Faktor für die Wahrscheinlichkeit, von KI zitiert zu werden: Richtig implementiertes JSON-LD-Markup erzielt um 340 % höhere Zitatraten als identische Inhalte ohne strukturierte Daten. Dieser Unterschied rührt daher, wie KI-Engines semantische Bedeutung interpretieren – strukturierte Daten liefern expliziten Kontext und beseitigen Mehrdeutigkeiten bei der Inhaltsauswertung. Erkennt eine KI-Engine ein Schema-Markup, versteht sie sofort Entitätsbeziehungen, Inhaltstypen und Hierarchien, ohne sich ausschließlich auf Natural Language Processing verlassen zu müssen.
Die effektivsten Schema-Typen sind Article-Schema für Blogposts, FAQ-Schema für Q&A-Abschnitte, HowTo-Schema für Anleitungen und Organization-Schema für Markenbekanntheit. Das JSON-LD-Format ist anderen strukturierten Datenformaten überlegen, weil KI-Engines es unabhängig vom HTML-Inhalt parsen können – das erleichtert saubere Datenextraktion und reduziert Verarbeitungsaufwand. Semantische HTML-Tags wie <header>, <nav>, <main>, <section> und <article> sorgen für zusätzliche Klarheit und helfen KI-Systemen, die Struktur und Hierarchie von Inhalten besser zu verstehen als einfaches Markup.
A/B-Testing ist die zuverlässigste Methode, um zu bestimmen, welche Inhaltsformate in Ihrer Nische die höchsten KI-Zitatraten erzielen. Anstatt sich auf allgemeine Best Practices zu verlassen, ermöglichen kontrollierte Experimente, den tatsächlichen Einfluss von Formatänderungen auf Ihre Zielgruppe und KI-Sichtbarkeit zu messen. Der Prozess erfordert sorgfältige Planung, um Variablen zu isolieren und statistische Gültigkeit sicherzustellen – aber die daraus gewonnenen Erkenntnisse rechtfertigen den Aufwand.
Folgen Sie diesem systematischen A/B-Testing-Framework:
Statistische Signifikanz erfordert besondere Aufmerksamkeit in Bezug auf Stichprobengröße und Testdauer. Gerade bei KI-Anwendungen mit wenig Daten oder Long-Tail-Verteilungen kann es schwierig sein, schnell genug Beobachtungen zu sammeln. Die meisten Experten empfehlen, Tests mindestens 2–4 Wochen laufen zu lassen, um zeitliche Schwankungen zu berücksichtigen und zuverlässige Ergebnisse zu erzielen.
Untersuchungen anhand tausender KI-Zitate zeigen klare Leistungsunterschiede je nach Inhaltsformat. Listenbasierte Inhalte erhalten 68 % mehr KI-Zitate als absatzlastige Alternativen, hauptsächlich weil Listen diskrete, einfach zu parende Informationseinheiten bieten, die KI-Engines leicht extrahieren und zusammenfassen können. Beim Generieren von Antworten können KI-Plattformen auf bestimmte Listenelemente verweisen, ohne komplexe Satzumstellungen oder Umschreibungen vornehmen zu müssen – was Listen für Zitationszwecke besonders wertvoll macht.
Tabellen zeigen mit bis zu 96 % Genauigkeit ausgezeichnete Leistung beim KI-Parsing und sind damit Fließtexten mit identischen Informationen deutlich überlegen. Tabellarische Inhalte ermöglichen es KI-Systemen, spezifische Datenpunkte schnell zu erfassen, ohne aufwendiges Text-Parsing – besonders wertvoll für Fakten, Vergleiche oder statistische Inhalte. Frage-Antwort-Formate erzielen eine um 45 % höhere KI-Sichtbarkeit als klassische Fließtextformate zum gleichen Thema, da Q&A-Inhalte das Interaktionsverhalten der Nutzer mit KI-Plattformen widerspiegeln und wie KI-Systeme Antworten generieren.
Vergleichsformate (X vs Y) schneiden außergewöhnlich gut ab, weil sie binäre, leicht zusammenzufassende Strukturen bieten, die mit der KI-Logik zur Unterteilung von Anfragen korrespondieren. Case Studies verbinden erzählerische Elemente mit Daten und sind damit für Leser überzeugend und für KI durch die Problem-Lösung-Ergebnis-Struktur gut interpretierbar. Eigene Forschung und Experteneinschätzungen werden bevorzugt behandelt, weil sie exklusive Daten liefern, die nirgends sonst verfügbar sind und damit Glaubwürdigkeitssignale senden, die KI-Systeme erkennen und belohnen. Die wichtigste Erkenntnis: Kein Format funktioniert universell – die beste Strategie kombiniert gezielt mehrere Formate je nach Inhaltstyp und Ziel-KI-Plattform.
Die Implementierung von Schema-Markup erfordert ein Verständnis der verfügbaren Typen und die Auswahl derjenigen, die am besten zu Ihren Inhalten passen. Für Blogposts und Artikel liefert das Article-Schema umfassende Metadaten wie Autor, Veröffentlichungsdatum und Struktur. FAQ-Schema eignet sich hervorragend für Frage-Antwort-Abschnitte, da es Fragen und Antworten explizit ausweist, sodass KI-Systeme sie zuverlässig extrahieren können. HowTo-Schema ist ideal für Anleitungen, da es Schrittfolgen definiert, während das Produkt-Schema E-Commerce-Seiten hilft, Spezifikationen und Preise zu kommunizieren.
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "Was ist das beste Inhaltsformat für KI-Zitate?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Das beste Inhaltsformat hängt von Ihrer Plattform und Zielgruppe ab, aber strukturierte Formate wie Listen, Tabellen und Q&A-Abschnitte erzielen durchweg höhere KI-Zitatraten. Listen erhalten 68 % mehr Zitate als Absätze, während Tabellen eine Parsing-Genauigkeit von 96 % erzielen."
}
}
]
}
Bei der Implementierung kommt es auf die Syntaxgenauigkeit an – ungültiges Schema-Markup kann Ihre KI-Zitatchancen sogar verschlechtern, statt sie zu verbessern. Nutzen Sie den Google Rich Results Test oder die Validierungstools von Schema.org, um Ihr Markup vor der Veröffentlichung zu prüfen. Halten Sie konsistente Formatierungshierarchien ein: H2 für Hauptabschnitte, H3 für Unterpunkte und kurze Absätze (maximal 50–75 Wörter), die sich auf Einzelkonzepte konzentrieren. Fügen Sie TL;DR-Zusammenfassungen am Anfang oder Ende von Abschnitten hinzu, um der KI fertige Snippets zu liefern, die als eigenständige Antworten dienen können.
Die Leistungsbewertung von KI-Engines erfordert andere Kennzahlen als klassisches SEO – im Fokus stehen Zitat-Tracking, Antwortquoten und Knowledge-Graph-Nennungen statt Ranking-Positionen. Monitoring der Zitate auf den wichtigsten Plattformen gibt den direktesten Einblick, ob Ihre Format-Tests erfolgreich sind, und zeigt, welche Inhalte tatsächlich von KI-Systemen referenziert werden. Tools wie AmICited verfolgen genau, wie KI-Plattformen Ihre Marke auf ChatGPT, Google AI Overviews, Perplexity und anderen Antwortmaschinen zitieren, und geben Einblick in Zitatmuster und Trends.
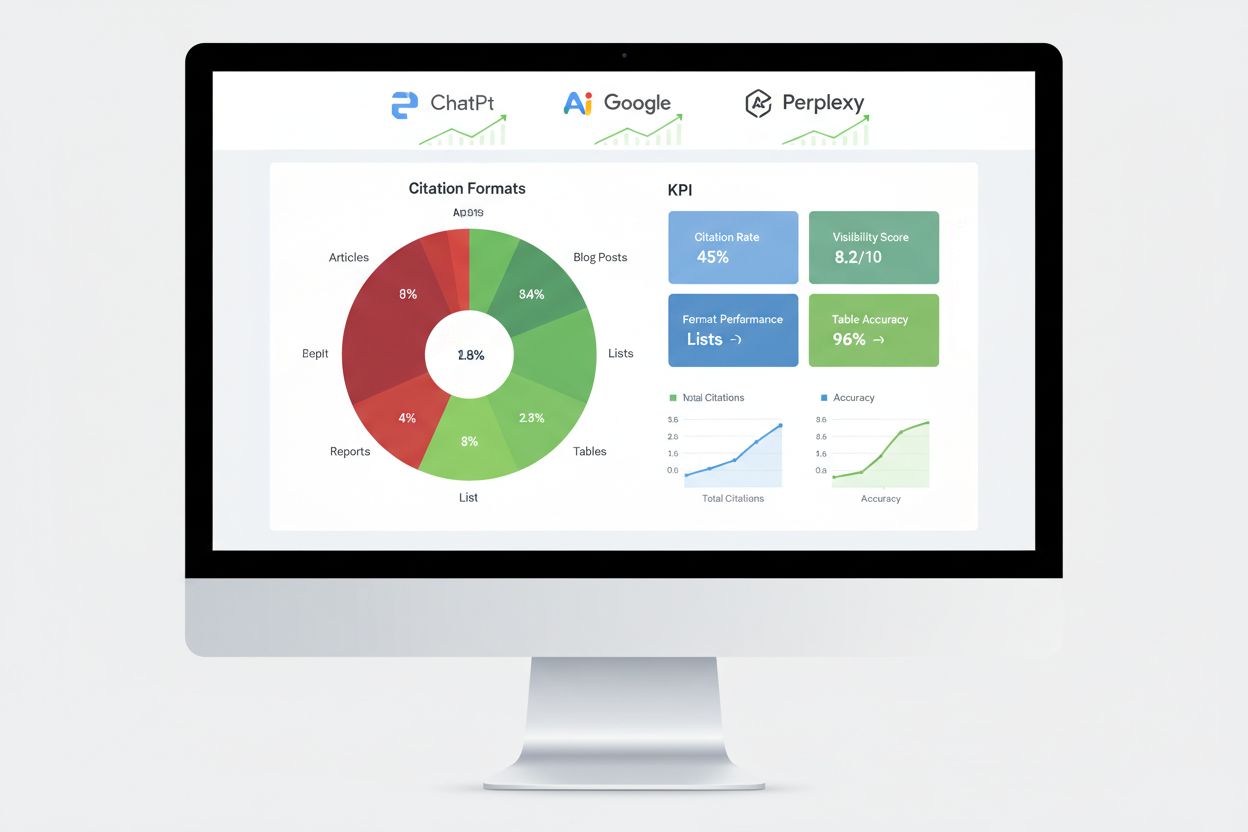
Wichtige Messansätze sind die Überwachung der Featured Snippet-Erfassungsrate, die zeigt, welche Inhalte von KI-Systemen besonders als direkte Antworten geschätzt werden. Knowledge Panel-Auftritte signalisieren, dass KI-Systeme Ihre Marke als autoritative Entität mit eigener Informationsbox anerkennen. Voice Search-Integrationen zeigen, ob Ihre Inhalte in konversationellen KI-Antworten erscheinen, und generative Engine-Antwortquoten messen, wie oft KI-Systeme Ihre Inhalte bei Nutzeranfragen referenzieren. A/B-Tests verschiedener Formatansätze liefern die zuverlässigsten Performancedaten, da sie einzelne Variablen isolieren und deren Einfluss erkennbar machen. Legen Sie vor Änderungen Basiswerte fest und überwachen Sie die Performance wöchentlich, um Trends und Ausreißer zu erkennen, die auf erfolgreiche oder problematische Formatvarianten hinweisen.
Viele Unternehmen machen bei Format-Tests typische Fehler, die die Ergebnisse verfälschen und zu falschen Schlüssen führen. Zu kleine Stichproben sind der häufigste Fehler – zu wenige Zitate oder Interaktionen liefern statistisch nicht signifikante Ergebnisse, die zwar aussagekräftig erscheinen, aber tatsächlich Zufallsschwankungen widerspiegeln. Sammeln Sie mindestens 100 Zitate pro Variante, bevor Sie Schlussfolgerungen ziehen, und berechnen Sie mit Statistik-Tools die erforderliche Stichprobengröße für Ihr Konfidenzniveau und Ihren Effektbedarf.
Störvariablen führen zu Verzerrungen, wenn mehrere Faktoren gleichzeitig geändert werden und so nicht mehr nachvollziehbar ist, welche Veränderung das Ergebnis bewirkt hat. Halten Sie alle anderen Elemente (Keywords, Länge, Struktur, Veröffentlichungszeitpunkt) konstant und ändern Sie nur das Format. Zeitliche Verzerrungen entstehen, wenn Tests in atypischen Zeiträumen (Feiertage, große Ereignisse, Algorithmusänderungen) laufen und Ergebnisse verfälschen. Testen Sie in normalen Zeiträumen und berücksichtigen Sie Saisonalitäten durch mindestens 2–4-wöchige Testzeiträume. Selektionsverzerrungen entstehen, wenn Testgruppen sich in Merkmalen unterscheiden, die das Ergebnis beeinflussen könnten – verteilen Sie Inhalte zufällig auf die Varianten. Korrelation nicht mit Kausalität verwechseln – ziehen Sie keine vorschnellen Schlüsse, wenn externe Faktoren zufällig mit Ihrer Testphase zusammenfallen. Ziehen Sie immer alternative Erklärungen in Betracht und bestätigen Sie Ergebnisse durch mehrere Testzyklen, bevor Sie dauerhafte Änderungen umsetzen.
Ein Technologieunternehmen testete Inhaltsformate für KI-Sichtbarkeit und stellte fest, dass die Umstellung von Produktvergleichsartikeln von Fließtext auf strukturierte Vergleichstabellen innerhalb von 60 Tagen zu 52 % mehr KI-Zitaten führte. Die Tabellen boten klare, schnell erfassbare Informationen, die von KI-Systemen direkt extrahiert werden konnten, während die ursprüngliche Prosa komplexeres Parsing erforderte. Die Textlänge und Keyword-Optimierung blieben identisch, sodass allein das Format als Variable isoliert wurde.
Ein Finanzdienstleister implementierte FAQ-Schema auf bestehende Inhalte, ohne diese umzuschreiben, sondern fügte lediglich strukturiertes Markup zu vorhandenen Q&A-Abschnitten hinzu. Das führte zu einer Steigerung der Featured Snippet-Rate um 34 % und zu 28 % mehr KI-Zitaten innerhalb von 45 Tagen. Das Schema-Markup änderte den Inhalt selbst nicht, erleichterte KI-Systemen aber die Identifikation und Extraktion relevanter Antworten erheblich. Ein SaaS-Unternehmen führte multivariate Tests mit drei Formaten – Listen, Tabellen, klassische Absätze – für identische Inhalte zu Produktfeatures durch. Ergebnis: Listen schnitten 68 % besser ab als Absätze; Tabellen erzielten die höchste Parsing-Genauigkeit, aber geringeres Gesamtzitatvolumen. Das zeigt: Formatwirksamkeit hängt vom Inhaltstyp und der KI-Plattform ab, Testen ist unverzichtbar und allgemeine Best Practices reichen nicht. Diese Praxisbeispiele zeigen, dass Format-Testing bei korrekter Umsetzung messbare, signifikante Verbesserungen der KI-Sichtbarkeit bringt.
Das Testing von Inhaltsformaten entwickelt sich weiter, da KI-Systeme immer ausgefeilter werden und neue Optimierungsmethoden entstehen. Multi-Armed-Bandit-Algorithmen sind ein bedeutender Fortschritt gegenüber klassischem A/B-Testing, weil sie die Traffic-Verteilung dynamisch am Echtzeit-Performance orientieren, anstatt auf das Ende vordefinierter Testzeiträume zu warten. So werden Gewinner schneller identifiziert und die Performance bereits während der Testphase maximiert.
Adaptives Experimentieren mit Reinforcement Learning ermöglicht es KI-Modellen, fortlaufend aus laufenden Tests zu lernen und sich in Echtzeit zu verbessern, statt nur in diskreten Testzyklen. KI-gesteuerte Automatisierung im A/B-Testing nutzt KI selbst, um Testdesign, Ergebnisanalyse und Optimierungsempfehlungen zu automatisieren – so lassen sich mehr Varianten gleichzeitig testen, ohne dass die Komplexität proportional steigt. Diese neuen Ansätze ermöglichen schnellere Iterationszyklen und ausgefeiltere Optimierungsstrategien. Unternehmen, die heute Format-Testing für KI beherrschen, sichern sich einen Vorsprung, wenn diese Techniken Standard werden, und können frühzeitig von neuen KI-Plattformen und sich wandelnden Zitationsalgorithmen profitieren, bevor Wettbewerber ihre Strategien anpassen.
Das beste Inhaltsformat hängt von Ihrer Plattform und Zielgruppe ab, aber strukturierte Formate wie Listen, Tabellen und Q&A-Abschnitte erzielen durchweg höhere KI-Zitatraten. Listen erhalten 68 % mehr Zitate als Absätze, während Tabellen eine Parsing-Genauigkeit von 96 % erzielen. Entscheidend ist, verschiedene Formate mit Ihren spezifischen Inhalten zu testen, um herauszufinden, was am besten funktioniert.
Die meisten Experten empfehlen, Tests mindestens 2–4 Wochen durchzuführen, um zeitliche Schwankungen zu berücksichtigen und zuverlässige Ergebnisse zu gewährleisten. Diese Dauer ermöglicht es Ihnen, genügend Datenpunkte zu sammeln (typischerweise 100+ Zitate pro Variante) und saisonale Schwankungen oder Plattform-Algorithmus-Änderungen zu berücksichtigen, die Ergebnisse verfälschen könnten.
Ja, Sie können multivariate Tests über mehrere Formate gleichzeitig durchführen, dies erfordert jedoch sorgfältige Planung, um Komplexität bei der Ergebnisinterpretation zu vermeiden. Beginnen Sie mit einfachen A/B-Tests, in denen Sie zwei Formate vergleichen, und gehen Sie dann zu multivariaten Tests über, sobald Sie die Grundlagen verstanden haben und über ausreichende statistische Ressourcen verfügen.
Sie benötigen in der Regel mindestens 100 Zitate oder Interaktionen pro Variante, um statistische Signifikanz zu erreichen. Verwenden Sie statistische Rechner, um die genaue Stichprobengröße für Ihr gewünschtes Konfidenzniveau und Ihren Effektgrößenbedarf zu bestimmen. Größere Stichproben liefern zuverlässigere Ergebnisse, erfordern jedoch längere Testzeiträume.
Beginnen Sie damit, den relevantesten Schema-Typ für Ihre Inhalte zu identifizieren (Artikel, FAQ, HowTo usw.) und implementieren Sie ihn im JSON-LD-Format. Validieren Sie Ihr Markup mit dem Google Rich Results Test oder den Validierungstools von Schema.org, bevor Sie veröffentlichen. Ungültiges Schema-Markup kann Ihre KI-Zitat-Chancen tatsächlich verschlechtern – Genauigkeit ist also entscheidend.
Priorisieren Sie nach Ihrer Zielgruppe und Ihren Geschäftszielen. ChatGPT bevorzugt autoritative Quellen wie Wikipedia, Google AI Overviews bevorzugt Community-Inhalte wie Reddit und Perplexity legt Wert auf Peer-to-Peer-Informationen. Analysieren Sie, welche Plattformen den relevantesten Traffic auf Ihre Website bringen, und optimieren Sie zuerst für diese.
Setzen Sie kontinuierliches Testen als Teil Ihrer Content-Strategie ein. Starten Sie mit vierteljährlichen Format-Testzyklen und erhöhen Sie dann die Frequenz, sobald Sie Expertise und Basiskennzahlen aufgebaut haben. Regelmäßiges Testen hilft Ihnen, KI-Algorithmus-Änderungen voraus zu sein und neue Formatpräferenzen zu erkennen.
Überwachen Sie Verbesserungen der Zitatrate, die Erfassung von Featured Snippets, das Erscheinen im Knowledge Panel und die Antwortquoten generativer Engines. Legen Sie vor dem Testen Basiskennzahlen fest und verfolgen Sie die Entwicklung wöchentlich, um Trends zu erkennen. Ein erfolgreicher Test zeigt in der Regel eine Verbesserung Ihrer Hauptkennzahl um 20 % oder mehr innerhalb von 4–8 Wochen.
Verfolgen Sie, wie KI-Plattformen Ihre Inhalte in unterschiedlichen Formaten zitieren. Entdecken Sie, welche Inhaltsstrukturen die meiste KI-Sichtbarkeit erzielen, und optimieren Sie Ihre Strategie mit echten Daten.
Erfahren Sie, warum Vergleichsartikel das leistungsstärkste Content-Format in der KI-Suche sind. Lernen Sie, wie Sie Vergleichs-Content für ChatGPT-, Perplexity...

Erfahren Sie, wie Sie Ihre Inhalte strukturieren, um von KI-Suchmaschinen wie ChatGPT, Perplexity und Google AI zitiert zu werden. Expertenstrategien für KI-Sic...
Erfahren Sie die optimalen Anforderungen an Content-Tiefe, Struktur und Detailgrad, um von ChatGPT, Perplexity und Google KI zitiert zu werden. Entdecken Sie, w...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.