
ClaudeBot erklärt: Anthropics Crawler und Ihre Inhalte
Erfahren Sie, wie ClaudeBot funktioniert, wie er sich von Claude-Web und Claude-SearchBot unterscheidet und wie Sie Anthropics Webcrawler mit einer robots.txt-K...
7 Min. Lesezeit

ClaudeBot ist Anthropics Web-Crawler, der zum Sammeln von Trainingsdaten für Claude-AI-Modelle eingesetzt wird. Er durchsucht systematisch öffentlich zugängliche Websites, um Inhalte für das Training von Machine-Learning-Modellen zu sammeln. Website-Betreiber können den Zugriff von ClaudeBot über die robots.txt-Konfiguration steuern. Der Crawler beachtet die Standard-Richtlinien von robots.txt, sodass Websites seine Besuche blockieren oder erlauben können.
ClaudeBot ist Anthropics Web-Crawler, der zum Sammeln von Trainingsdaten für Claude-AI-Modelle eingesetzt wird. Er durchsucht systematisch öffentlich zugängliche Websites, um Inhalte für das Training von Machine-Learning-Modellen zu sammeln. Website-Betreiber können den Zugriff von ClaudeBot über die robots.txt-Konfiguration steuern. Der Crawler beachtet die Standard-Richtlinien von robots.txt, sodass Websites seine Besuche blockieren oder erlauben können.
ClaudeBot ist ein Web-Crawler, der von Anthropic betrieben wird, um Trainingsdaten für seine großen Sprachmodelle (LLMs) zu sammeln, die KI-Produkte wie Claude antreiben. Dieser KI-Datensammler durchsucht systematisch Websites, um gezielt Inhalte für das Training von Machine-Learning-Modellen zu sammeln – im Unterschied zu traditionellen Suchmaschinen-Crawlern, die Inhalte zum Zweck der Auffindbarkeit indexieren. ClaudeBot ist anhand seines User-Agent-Strings identifizierbar und kann über die robots.txt-Konfiguration blockiert oder zugelassen werden, sodass Website-Betreiber kontrollieren können, ob ihre Inhalte zum Training von Anthropics KI-Modellen verwendet werden.

ClaudeBot arbeitet mit systematischen Web-Discovery-Methoden, darunter das Folgen von Links bereits indexierter Seiten, das Verarbeiten von Sitemaps und die Nutzung von Start-URLs aus öffentlich zugänglichen Website-Listen. Der Crawler lädt Website-Inhalte herunter und integriert sie in Datensätze für das Training von Claudes Sprachmodellen. Er sammelt Daten von öffentlich zugänglichen Seiten, ohne Authentifizierung zu benötigen. Anders als Suchmaschinen-Crawler, die das Indexieren für die spätere Auffindbarkeit priorisieren, sind die Crawling-Muster von ClaudeBot meist undurchsichtig: Anthropic veröffentlicht selten konkrete Kriterien zur Seitenauswahl, Crawling-Frequenz oder Prioritäten für unterschiedliche Inhaltstypen.
Die folgende Tabelle vergleicht ClaudeBot mit anderen Anthropics-Crawlern:
| Bot-Name | Zweck | User-Agent | Umfang |
|---|---|---|---|
| ClaudeBot | Chat-Zitat-Abruf und Trainingsdaten | ClaudeBot/1.0 | Allgemeines Web-Crawling für Modelltraining |
| anthropic-ai | Umfangreiche Trainingsdatensammlung | anthropic-ai | Zusammenstellung groß angelegter Trainingsdatensätze |
| Claude-Web | Weborientiertes Crawling für Claude-Funktionen | Claude-Web | Websuche und Echtzeitinformationen |
ClaudeBot arbeitet ähnlich wie andere große KI-Trainingscrawler wie GPTBot (OpenAI) und PerplexityBot (Perplexity), unterscheidet sich jedoch im Umfang und in der Methodik. Während GPTBot auf OpenAIs Trainingsbedarf fokussiert und PerplexityBot sowohl für Suche als auch für Training dient, zielt ClaudeBot speziell auf Inhalte für das Modelltraining von Claude ab. Laut Daten von Dark Visitors blockieren etwa 18 % der weltweit 1.000 größten Websites aktiv ClaudeBot – ein Hinweis auf die erheblichen Bedenken von Publishern hinsichtlich der Datensammlung. Der zentrale Unterschied liegt darin, wie jedes Unternehmen die Inhaltsauswahl priorisiert: Anthropics Ansatz setzt auf systematisches, breit angelegtes Crawling für Trainingsdaten, während suchfokussierte Crawler Indexierung und Referral-Traffic austarieren.
Website-Betreiber können Besuche von ClaudeBot erkennen, indem sie Server-Logs auf den charakteristischen User-Agent-String überwachen: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com). ClaudeBot stammt in der Regel aus US-amerikanischen IP-Bereichen, und seine Besuche lassen sich durch Server-Log-Analysen oder spezielle Monitoring-Tools verfolgen. Die Einrichtung von Agent-Analytics-Plattformen bietet Echtzeiteinblicke in ClaudeBot-Besuche und ermöglicht es Website-Betreibern, Crawling-Frequenz und -Muster zu messen.
So sieht ein Beispiel für ClaudeBot in Server-Logs aus:
203.0.113.45 - - [03/Jan/2025:09:15:32 +0000] "GET /blog/article-title HTTP/1.1" 200 5432 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
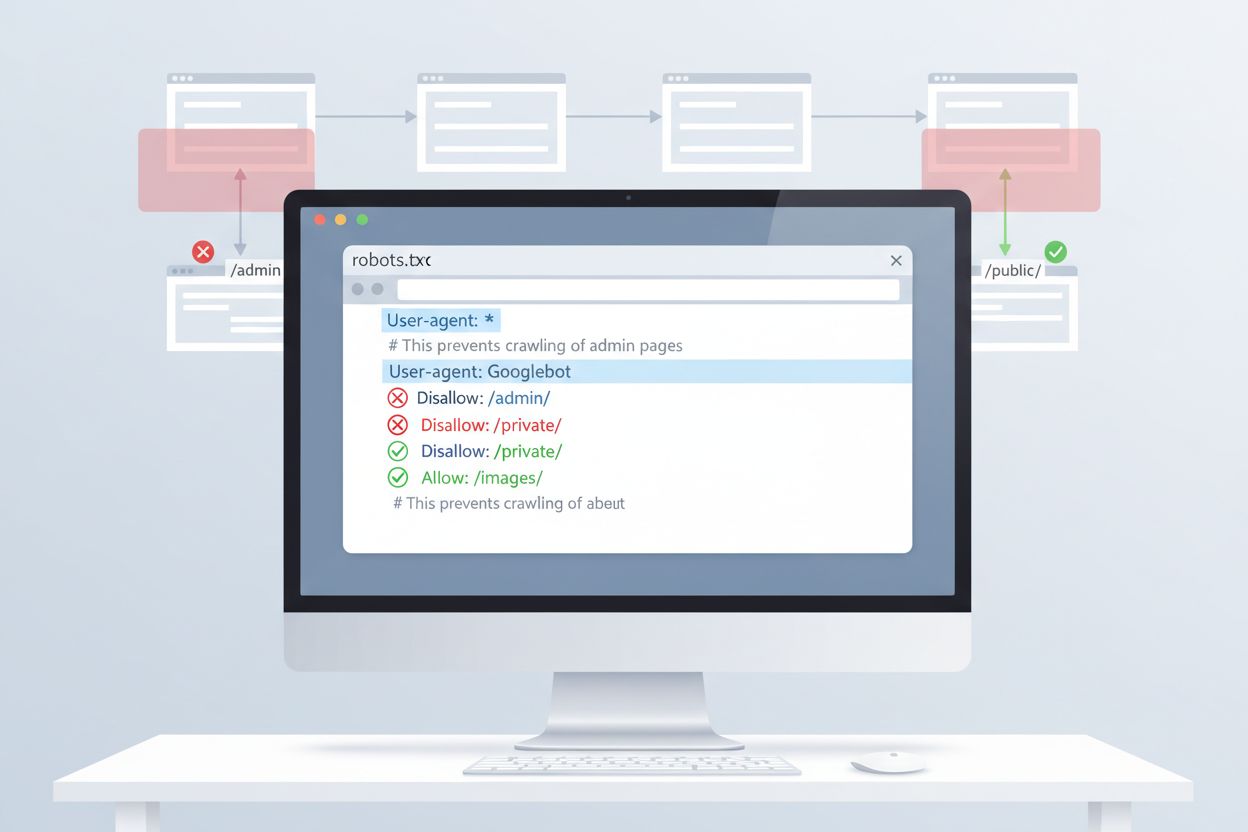
Die einfachste Möglichkeit, den Zugriff von ClaudeBot zu steuern, ist die robots.txt-Konfiguration im Stammverzeichnis Ihrer Website. Diese Datei gibt Crawlern vor, welche Bereiche sie durchsuchen dürfen. Anthropics ClaudeBot beachtet diese Anweisungen. Um ClaudeBot vollständig zu blockieren, fügen Sie folgende Regeln zu Ihrer robots.txt hinzu:
User-agent: ClaudeBot
Disallow: /
Für selektiveres Blockieren – etwa um ClaudeBot den Zugriff auf bestimmte Verzeichnisse zu verwehren, während andere Inhalte weiterhin gecrawlt werden dürfen – verwenden Sie:
User-agent: ClaudeBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
Wenn Sie alle Anthropics-Crawler (inklusive anthropic-ai und Claude-Web) blockieren möchten, fügen Sie für jeden eine eigene Regel hinzu:
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
Während robots.txt die erste Verteidigungslinie bildet, basiert sie auf freiwilliger Einhaltung. Für Publisher, die eine stärkere Durchsetzung benötigen, gibt es weitere Blockiermöglichkeiten:
Diese Methoden erfordern mehr technisches Know-how als die robots.txt-Konfiguration, bieten aber stärkeren Schutz gegenüber nicht-konformen Crawlern.
Das Blockieren von ClaudeBot hat keinen direkten Einfluss auf traditionelle SEO-Rankings, da Trainingscrawler nicht zur Suchmaschinenindexierung beitragen – Google, Bing und andere Suchmaschinen nutzen dafür eigene Crawler (Googlebot, Bingbot), die unabhängig agieren. Allerdings kann das Blockieren von ClaudeBot die Präsenz Ihrer Inhalte in KI-generierten Antworten von Claude verringern und so die künftige Auffindbarkeit über KI-Suche und Chat-Interfaces beeinflussen. Die strategische Entscheidung, ClaudeBot zu blockieren oder zuzulassen, hängt von Ihrem Monetarisierungsmodell ab: Wenn Ihr Umsatz auf direktem Website-Traffic und Werbeeinblendungen basiert, verhindert das Blockieren, dass Ihre Inhalte in Trainingsdatensätze fließen, die potenziell die Besucherzahlen verringern könnten. Umgekehrt kann die Zulassung von ClaudeBot Ihre Sichtbarkeit in Claudes Antworten erhöhen und Referral-Traffic durch KI-Chat-Nutzer generieren.
Eine effektive Verwaltung von ClaudeBot erfordert laufende Überwachung und Tests Ihrer Konfiguration. Nutzen Sie Tools wie den robots.txt-Tester der Google Search Console, das robots.txt-Testtool von Merkle oder spezialisierte Plattformen wie Dark Visitors, um sicherzustellen, dass Ihre Blockierregeln wie gewünscht funktionieren. Überprüfen Sie regelmäßig Ihre Server-Logs, um zu bestätigen, dass ClaudeBot Ihre robots.txt-Anweisungen beachtet, und achten Sie auf Veränderungen im Crawling-Verhalten. Da sich die KI-Crawler-Landschaft schnell entwickelt und regelmäßig neue Bots entdeckt werden, empfehlen sich quartalsweise Überprüfungen Ihrer robots.txt, um auf neue Crawler zu reagieren und Ihre Content-Protection-Strategie aktuell zu halten. Testen Sie Ihre Konfiguration vor dem Livegang, um versehentliches Blockieren legitimer Suchmaschinen oder wichtiger Crawler zu vermeiden.
ClaudeBot ist Anthropics Web-Crawler, der systematisch Websites besucht, um Trainingsdaten für Claude-AI-Modelle zu sammeln. Er findet Ihre Website durch das Folgen von Links, das Verarbeiten von Sitemaps oder öffentliche Website-Listen. Der Crawler sammelt öffentlich zugängliche Inhalte, um die Sprachmodellfähigkeiten von Claude zu verbessern.
Sie können ClaudeBot blockieren, indem Sie eine robots.txt-Regel im Stammverzeichnis Ihrer Website hinzufügen. Fügen Sie einfach 'User-agent: ClaudeBot' gefolgt von 'Disallow: /' hinzu, um jeglichen Zugriff zu verhindern, oder geben Sie bestimmte Pfade an, um selektiv zu blockieren. Anthropics ClaudeBot beachtet robots.txt-Anweisungen.
Nein, das Blockieren von ClaudeBot hat keinen Einfluss auf Ihr Google- oder Bing-Ranking. Trainingscrawler wie ClaudeBot arbeiten unabhängig von traditionellen Suchmaschinen. Nur das Blockieren von Googlebot oder Bingbot würde Ihre SEO-Leistung beeinflussen.
Anthropic betreibt drei Haupt-Crawler: ClaudeBot (Chat-Zitat-Abruf und allgemeines Training), anthropic-ai (umfangreiche Trainingsdatensammlung) und Claude-Web (weborientiertes Crawling für Echtzeit-Funktionen). Jeder dient unterschiedlichen Zwecken innerhalb der KI-Infrastruktur von Anthropic.
Überprüfen Sie Ihre Server-Logs auf die ClaudeBot-User-Agent-Zeichenkette: 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)'. Sie können außerdem Überwachungstools wie Dark Visitors verwenden oder Agent-Analytics einrichten, um ClaudeBot-Besuche in Echtzeit zu verfolgen.
Ja, ClaudeBot beachtet robots.txt-Anweisungen laut offizieller Dokumentation von Anthropic. Wie bei allen robots.txt-Regeln ist die Einhaltung jedoch freiwillig. Für eine stärkere Durchsetzung können Sie serverseitige Blockierung, IP-Filterung oder WAF-Regeln implementieren.
ClaudeBot kann je nach Größe und Inhaltsvolumen Ihrer Website erhebliche Bandbreite verbrauchen. KI-Datensammler crawlen möglicherweise aggressiver als traditionelle Suchmaschinen. Die Überwachung Ihrer Serverprotokolle hilft Ihnen, die Auswirkungen zu verstehen und zu entscheiden, ob Sie den Crawler blockieren oder zulassen.
Die Entscheidung hängt von Ihrem Geschäftsmodell ab. Blockieren Sie ClaudeBot, wenn Sie Bedenken hinsichtlich Inhaltszuordnung, Vergütung oder Nutzung Ihrer Arbeit in KI-Systemen haben. Lassen Sie ihn zu, wenn Sie möchten, dass Ihre Inhalte in Claudes Antworten und KI-Suchergebnissen erscheinen. Berücksichtigen Sie Ihre Traffic-Monetarisierungsstrategie bei der Entscheidung.
Verfolgen Sie ClaudeBot und andere KI-Crawler, die auf Ihre Inhalte zugreifen. Erhalten Sie Einblicke, welche KI-Systeme Ihre Marke zitieren und wie Ihre Inhalte in KI-generierten Antworten verwendet werden.
Erfahren Sie, wie ClaudeBot funktioniert, wie er sich von Claude-Web und Claude-SearchBot unterscheidet und wie Sie Anthropics Webcrawler mit einer robots.txt-K...
Claude ist der fortschrittliche KI-Assistent von Anthropic, der auf Constitutional AI basiert. Erfahren Sie, wie Claude funktioniert, welche Hauptfunktionen und...

Erfahren Sie, was CCBot ist, wie er funktioniert und wie Sie ihn blockieren können. Verstehen Sie seine Rolle beim KI-Training, Überwachungstools und bewährte P...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.