Mécanismes techniques et juridiques permettant aux créateurs de contenu et aux détenteurs de droits d’auteur d’empêcher l’utilisation de leurs œuvres dans les ensembles de données d’entraînement des grands modèles de langage. Ceux-ci incluent les directives robots.txt, les déclarations légales d’opt-out et les protections contractuelles prévues par des réglementations comme l’AI Act de l’UE.
Refus d'entraînement de l'IA
Mécanismes techniques et juridiques permettant aux créateurs de contenu et aux détenteurs de droits d'auteur d'empêcher l'utilisation de leurs œuvres dans les ensembles de données d'entraînement des grands modèles de langage. Ceux-ci incluent les directives robots.txt, les déclarations légales d'opt-out et les protections contractuelles prévues par des réglementations comme l'AI Act de l'UE.
Qu’est-ce que le refus d’entraînement de l’IA ?
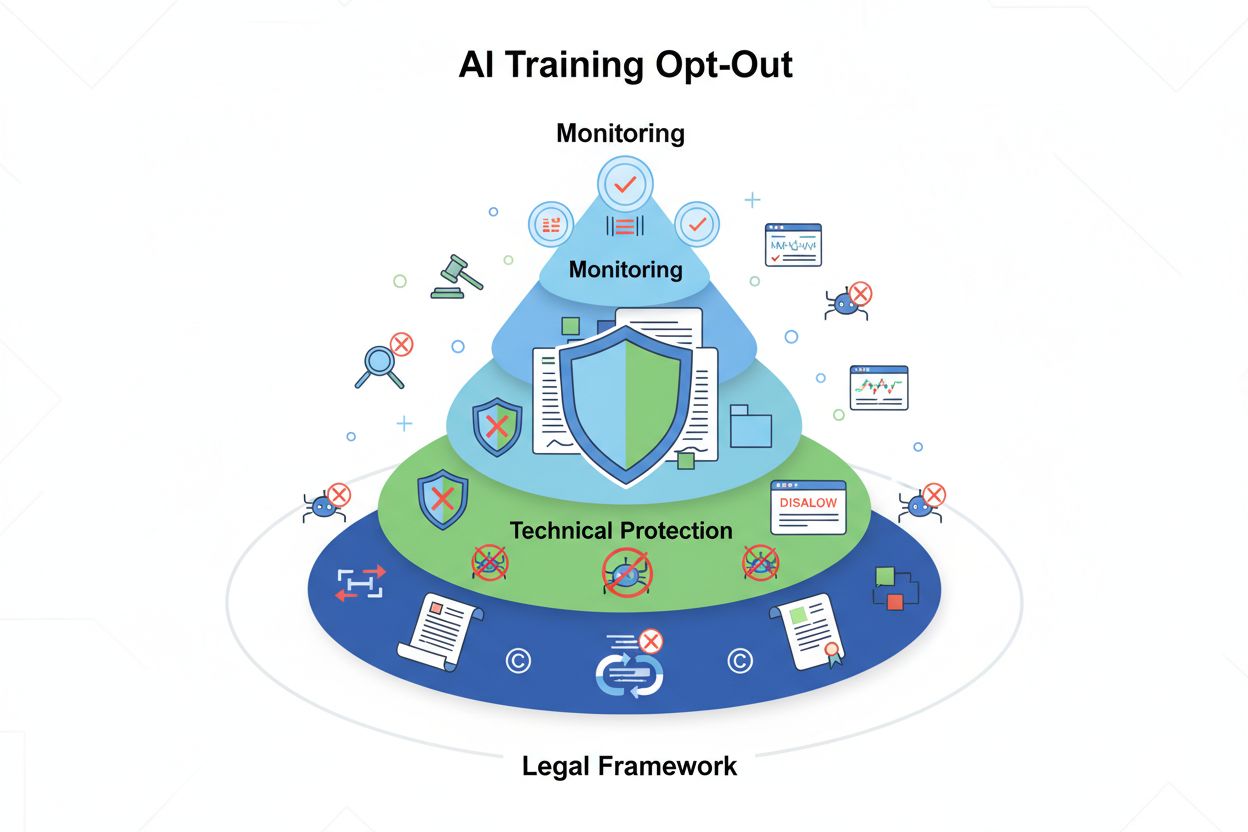
Le refus d’entraînement de l’IA fait référence aux mécanismes techniques et juridiques permettant aux créateurs de contenu, détenteurs de droits d’auteur et propriétaires de sites web d’empêcher l’utilisation de leurs œuvres dans les ensembles de données d’entraînement des grands modèles de langage (LLM). À mesure que les entreprises d’IA collectent d’énormes quantités de données sur Internet pour entraîner des modèles toujours plus sophistiqués, la capacité de contrôler la participation de votre contenu à ce processus est devenue essentielle pour protéger la propriété intellectuelle et garder la maîtrise créative. Ces mécanismes d’opt-out fonctionnent sur deux plans : des directives techniques qui ordonnent aux robots IA d’ignorer votre contenu, et des cadres juridiques qui établissent des droits contractuels pour exclure vos œuvres des ensembles de données d’entraînement. Comprendre ces deux dimensions est crucial pour toute personne soucieuse de la façon dont son contenu est utilisé à l’ère de l’IA.
Mécanismes techniques : robots.txt et agents utilisateurs
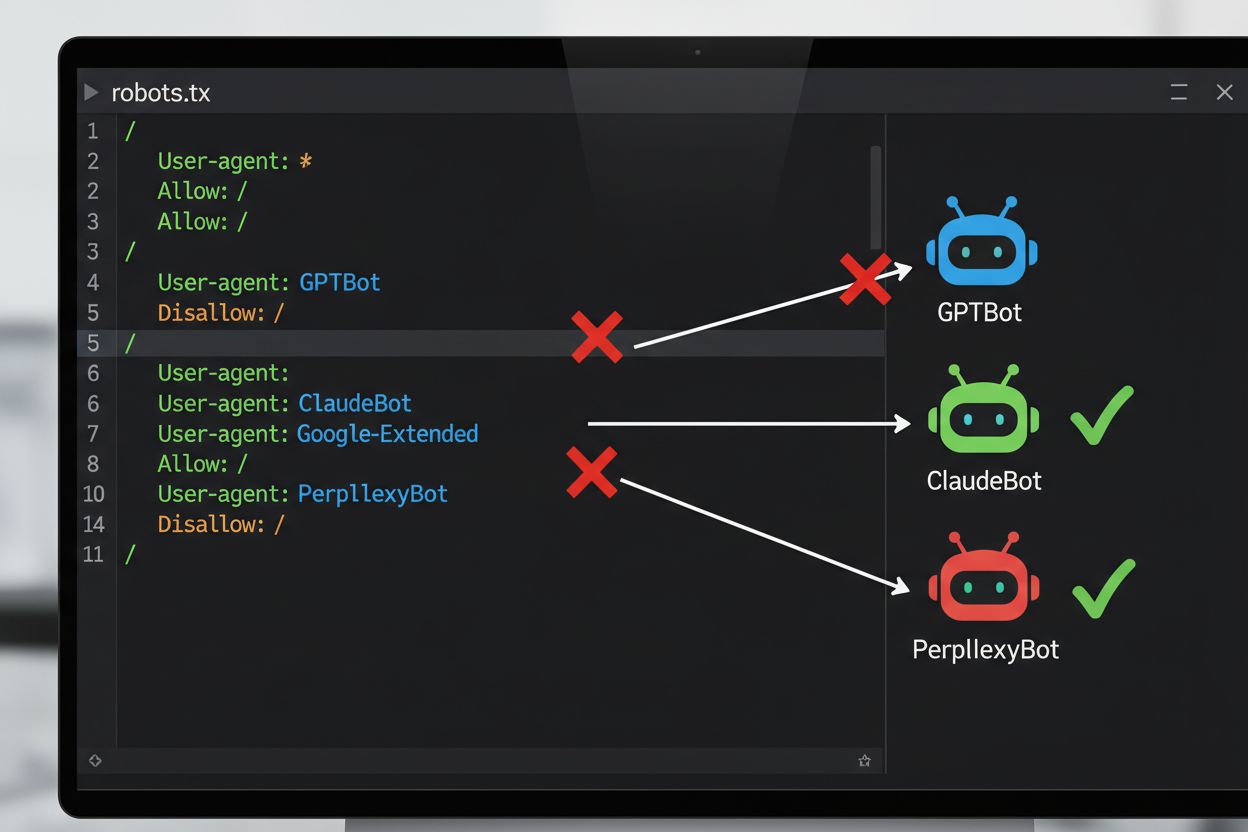
La méthode technique la plus courante pour refuser l’entraînement de l’IA passe par le fichier robots.txt, un simple fichier texte placé à la racine d’un site web qui communique les permissions d’accès aux robots automatisés. Lorsqu’un robot IA visite votre site, il vérifie d’abord le fichier robots.txt pour savoir s’il est autorisé à accéder à votre contenu. En ajoutant des directives Disallow pour certains agents utilisateurs de robots spécifiques, vous pouvez ordonner aux bots IA d’ignorer complètement votre site. Chaque entreprise d’IA exploite plusieurs robots avec des identifiants d’agent utilisateur distincts—ce sont essentiellement les « noms » que les bots utilisent pour s’identifier lors de leurs requêtes. Par exemple, le GPTBot d’OpenAI s’identifie avec la chaîne d’agent utilisateur “GPTBot”, tandis que Claude d’Anthropic utilise “ClaudeBot”. La syntaxe est simple : vous spécifiez le nom de l’agent utilisateur puis indiquez les chemins interdits, comme “Disallow: /” pour bloquer l’ensemble du site.
Le paysage juridique du refus d’entraînement de l’IA a fortement évolué avec l’introduction de l’AI Act de l’UE, entré en vigueur en 2024 et intégrant des dispositions de la directive sur l’exploration de textes et de données (TDM). Selon ces réglementations, les développeurs d’IA ne peuvent utiliser des œuvres protégées pour l’apprentissage automatique que s’ils disposent d’un accès légal au contenu et si le détenteur des droits n’a pas expressément réservé le droit d’exclure ses œuvres de l’exploration de textes et de données. Cela crée un mécanisme juridique formel d’opt-out : les titulaires de droits peuvent déposer des réserves d’opt-out avec leurs œuvres, empêchant leur utilisation dans l’entraînement de l’IA sans autorisation explicite. L’AI Act de l’UE marque un changement important par rapport à l’approche précédente du « move fast and break things », en imposant aux entreprises entraînant des modèles IA de vérifier si des ayants droit ont réservé leur contenu et de mettre en place des mesures techniques et organisationnelles pour empêcher l’utilisation non désirée des œuvres réservées. Ce cadre s’applique dans toute l’Union européenne et influence la manière dont les entreprises IA mondiales collectent et utilisent les données pour l’entraînement.
Fonctionnement pratique des mécanismes d’opt-out
La mise en œuvre d’un mécanisme d’opt-out implique à la fois une configuration technique et une documentation juridique. Côté technique, les propriétaires de sites ajoutent des directives Disallow dans leur fichier robots.txt pour des agents utilisateurs de robots IA spécifiques, que les robots conformes respecteront lors de leur visite. Côté juridique, les détenteurs de droits peuvent déposer des déclarations d’opt-out auprès des sociétés de gestion collective et organismes de droits—par exemple, la société néerlandaise Pictoright et la société française SACEM ont mis en place des procédures officielles permettant aux créateurs de réserver leurs droits contre l’entraînement IA. De nombreux sites web et créateurs de contenu incluent désormais des déclarations explicites d’opt-out dans leurs conditions d’utilisation ou leurs métadonnées, précisant que leur contenu ne doit pas être utilisé pour l’entraînement des modèles IA. Cependant, l’efficacité de ces mécanismes dépend de la conformité des robots : bien que des entreprises majeures comme OpenAI, Google et Anthropic aient publiquement annoncé respecter les directives robots.txt et les réserves d’opt-out, l’absence de mécanisme centralisé d’exécution signifie que la vérification du respect effectif de la demande d’opt-out nécessite une surveillance et une vérification continues.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Défis et limites de l’opt-out
Malgré l’existence de mécanismes d’opt-out, plusieurs défis majeurs limitent leur efficacité :
Norme volontaire : robots.txt repose sur un accord de bonne conduite sans force exécutoire, ce qui permet aux robots non conformes d’ignorer vos directives
Évasion des robots : Des bots sophistiqués peuvent usurper la chaîne agent utilisateur pour se faire passer pour des navigateurs légitimes et contourner les blocages
Rotation d’IP : Les scrapers peuvent utiliser des centaines de milliers d’adresses IP via des proxys ou des botnets, rendant le blocage par IP inefficace
Couverture incomplète : robots.txt bloque environ 40 à 60 % des bots IA, laissant passer un volume important sans mesures techniques complémentaires
Robots malveillants : Certaines entreprises IA non respectables et des scrapers indépendants peuvent ignorer totalement les mécanismes d’opt-out, opérant dans des zones juridiques grises
Lacunes d’application : Même en cas de violation de l’opt-out, les recours juridiques sont coûteux et lents, avec un résultat incertain devant les tribunaux
Méthodes techniques complémentaires au robots.txt
Pour les organisations nécessitant une protection plus forte que celle offerte par robots.txt seul, plusieurs méthodes techniques supplémentaires peuvent être déployées. Le filtrage des agents utilisateurs au niveau du serveur ou du pare-feu permet de bloquer les requêtes de certains identifiants de robots avant qu’elles n’atteignent votre application, bien que cela reste vulnérable à l’usurpation. Le blocage par adresse IP cible les plages IP connues publiées par les grandes entreprises IA, même si les scrapers déterminés peuvent contourner cette mesure via des réseaux de proxies. Le throttling et la limitation de débit ralentissent les scrapers en limitant le nombre de requêtes par seconde, rendant le scraping économiquement peu viable, même si les bots sophistiqués peuvent répartir leurs requêtes sur plusieurs IP pour contourner cette limite. Les exigences d’authentification et paywalls offrent une protection forte en réservant l’accès aux utilisateurs authentifiés ou payants, empêchant ainsi le scraping automatisé. Le fingerprinting de périphérique et l’analyse comportementale détectent les bots en analysant des schémas comme les API navigateur, les handshakes TLS et les interactions différentes de celles des humains. Certains organismes déploient même des honeypots et tarpits—liens cachés ou labyrinthes de liens infinis que seuls les robots suivraient—afin d’épuiser les ressources des robots et potentiellement polluer leurs ensembles de données d’entraînement avec des données inutiles.
Exemples concrets et cas d’usage
La tension entre les entreprises IA et les créateurs de contenu a donné lieu à plusieurs confrontations notables illustrant la difficulté d’appliquer le refus d’entraînement. Reddit a pris des mesures radicales en 2023 en augmentant fortement les prix d’accès API, ciblant spécifiquement les entreprises IA pour facturer l’accès aux données, ce qui a contraint OpenAI et Anthropic à négocier des licences. Twitter/X est allé plus loin en bloquant temporairement tout accès non authentifié aux tweets et en limitant le nombre de tweets accessibles aux utilisateurs connectés, ciblant explicitement les scrapers. Stack Overflow a initialement bloqué GPTBot d’OpenAI dans son fichier robots.txt par crainte de violation de licence du code utilisateur, avant de lever le blocage—signe possible de négociations avec OpenAI. Les médias ont réagi en masse : plus de 50 % des grands sites d’actualité ont bloqué les robots IA en 2023, des titres comme The New York Times, CNN, Reuters et The Guardian ajoutant GPTBot à leur liste de blocage. Certains médias ont choisi la voie judiciaire, avec The New York Times intentant un procès pour violation du droit d’auteur contre OpenAI, tandis que d’autres comme l’Associated Press ont négocié des accords de licence pour monétiser leurs contenus. Ces exemples démontrent que si les mécanismes d’opt-out existent, leur efficacité dépend à la fois de la mise en œuvre technique et de la volonté d’engager des actions juridiques en cas de violation.
Outils de surveillance et de conformité
La mise en place de mécanismes d’opt-out n’est qu’une première étape ; s’assurer de leur efficacité nécessite une surveillance et des tests réguliers. Plusieurs outils permettent de valider votre configuration : Google Search Console propose un testeur robots.txt spécifique à Googlebot, tandis que Merkle’s Robots.txt Tester et l’outil de TechnicalSEO.com permettent de tester le comportement de robots individuels selon l’agent utilisateur. Pour surveiller de façon approfondie le respect effectif de vos directives d’opt-out par les entreprises IA, des plateformes comme AmICited.com offrent une surveillance spécialisée pour suivre comment les systèmes IA référencent votre marque et votre contenu dans GPTs, Perplexity, Google AI Overviews et d’autres plateformes IA. Ce type de surveillance est particulièrement précieux car il révèle non seulement si des robots accèdent à votre site, mais aussi si votre contenu apparaît effectivement dans les réponses générées par l’IA—indicateur de l’efficacité réelle de votre opt-out. L’analyse régulière des logs serveur peut également révéler quels robots tentent d’accéder à votre site et s’ils respectent vos directives robots.txt, bien que cela nécessite des compétences techniques pour être interprété correctement.
Bonnes pratiques pour les créateurs de contenu
Pour protéger efficacement votre contenu contre l’entraînement non autorisé par l’IA, adoptez une approche multi-couches combinant mesures techniques et juridiques. Premièrement, mettez en place des directives robots.txt pour tous les robots d’entraînement IA majeurs (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot, etc.), en gardant à l’esprit que cela constitue une défense de base contre les entreprises respectueuses. Deuxièmement, ajoutez des déclarations explicites d’opt-out dans les conditions d’utilisation et les métadonnées de votre site, stipulant clairement que votre contenu ne doit pas être utilisé pour l’entraînement IA—ce qui renforce votre position juridique en cas de violation. Troisièmement, surveillez régulièrement votre configuration à l’aide d’outils de test et de logs serveur pour vérifier le respect de vos directives par les robots, et mettez à jour votre robots.txt chaque trimestre car de nouveaux robots IA apparaissent constamment. Quatrièmement, envisagez des mesures techniques supplémentaires comme le filtrage par agent utilisateur ou la limitation de débit si vous en avez les moyens, sachant que cela offre une protection incrémentale contre les scrapers plus sophistiqués. Enfin, documentez soigneusement vos efforts d’opt-out, car cette documentation sera cruciale si vous devez engager une action en justice contre des entreprises qui ignorent vos directives. Gardez à l’esprit que l’opt-out n’est pas une configuration ponctuelle mais un processus continu exigeant vigilance et adaptation à mesure que l’écosystème IA évolue.
Questions fréquemment posées
Quelle est la différence entre l'opt-out robots.txt et l'opt-out légal ?
robots.txt est une norme technique et volontaire qui indique aux robots d'ignorer votre contenu, tandis que l'opt-out légal consiste à déposer des réserves formelles auprès d'organismes de gestion collective ou à inclure des clauses contractuelles dans vos conditions d'utilisation. robots.txt est plus facile à mettre en œuvre mais n'a pas de force exécutoire, alors que l'opt-out légal offre une protection juridique plus forte mais nécessite des démarches plus formelles.
Toutes les entreprises d'IA respectent-elles les directives robots.txt ?
Les principales entreprises d'IA comme OpenAI, Google, Anthropic et Perplexity ont déclaré publiquement respecter les directives robots.txt. Cependant, robots.txt est une norme volontaire sans mécanisme d'exécution, de sorte que des robots non conformes et des scrapers malveillants peuvent totalement ignorer vos directives.
Le blocage des bots d'entraînement IA affectera-t-il mon classement dans les moteurs de recherche ?
Non. Bloquer les robots d'entraînement IA tels que GPTBot et ClaudeBot n'aura aucun impact sur votre classement Google ou Bing car les moteurs de recherche traditionnels utilisent d'autres robots (Googlebot, Bingbot) qui fonctionnent indépendamment. Ne bloquez ces derniers que si vous souhaitez disparaître complètement des résultats de recherche.
Quelle est la position de l'AI Act de l'UE concernant l'opt-out ?
L'AI Act de l'UE exige que les développeurs d'IA disposent d'un accès légal au contenu et respectent les réserves d'opt-out des détenteurs de droits. Les titulaires de droits peuvent déposer des déclarations d'opt-out avec leurs œuvres, empêchant ainsi leur utilisation dans l'entraînement de l'IA sans autorisation explicite. Cela crée un mécanisme juridique formel pour protéger le contenu contre l'utilisation non autorisée à des fins d'entraînement.
Puis-je utiliser l'opt-out pour empêcher mon contenu d'apparaître dans les résultats de recherche IA ?
Cela dépend du mécanisme spécifique. Bloquer tous les robots IA empêchera votre contenu d'apparaître dans les résultats de recherche IA, mais cela vous retire également complètement des plateformes de recherche alimentées par l'IA. Certains éditeurs préfèrent un blocage sélectif—en autorisant les robots centrés sur la recherche tout en bloquant ceux dédiés à l'entraînement—afin de conserver leur visibilité dans la recherche IA tout en protégeant leur contenu de l'entraînement des modèles.
Que se passe-t-il si une entreprise d'IA ignore mon opt-out ?
Si une entreprise d'IA ignore vos directives d'opt-out, vous disposez de recours juridiques via des plaintes pour violation du droit d'auteur ou rupture de contrat, selon votre juridiction et les circonstances précises. Cependant, une action en justice est coûteuse et lente, avec des résultats incertains. C'est pourquoi la surveillance et la documentation de vos efforts d'opt-out sont essentielles.
À quelle fréquence dois-je mettre à jour ma configuration d'opt-out ?
Examinez et mettez à jour votre configuration robots.txt au moins chaque trimestre. De nouveaux robots IA apparaissent constamment, et les entreprises introduisent fréquemment de nouveaux agents utilisateurs. Par exemple, Anthropic a fusionné ses bots 'anthropic-ai' et 'Claude-Web' en 'ClaudeBot', donnant à ce nouveau bot un accès temporaire illimité aux sites n'ayant pas encore mis à jour leurs règles.
L'opt-out est-il efficace contre tous les robots IA ?
L'opt-out est efficace contre les entreprises d'IA réputées et respectueuses des normes, qui suivent robots.txt et les cadres juridiques. Cependant, il est moins efficace contre les robots malveillants et les scrapers non conformes opérant dans des zones grises. robots.txt bloque environ 40 à 60 % des bots IA, d'où la recommandation d'une approche multi-couches combinant mesures techniques et juridiques.
Surveillez comment l'IA référence votre contenu
Suivez si votre contenu apparaît dans les réponses générées par l'IA sur ChatGPT, Perplexity, Google AI Overviews et d'autres plateformes d'IA avec AmICited.
Implications en matière de droits d'auteur des moteurs de recherche par IA et de l'IA générative
Comprenez les défis liés au droit d'auteur auxquels sont confrontés les moteurs de recherche par IA, les limites de l'usage loyal, les récents procès et les imp...
Faut-il refuser que nos contenus servent à l’entraînement de l’IA ? Inquiétude sur l’utilisation sans attribution – mais aussi envie de visibilité
Discussion communautaire sur le choix de refuser ou non l’entraînement de l’IA. Retours d’expérience de créateurs de contenu entre protection et avantages de vi...
Découvrez les accords de licence de contenu pour l’IA qui régissent l’utilisation des contenus protégés par le droit d’auteur par les systèmes d’intelligence ar...
10 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.