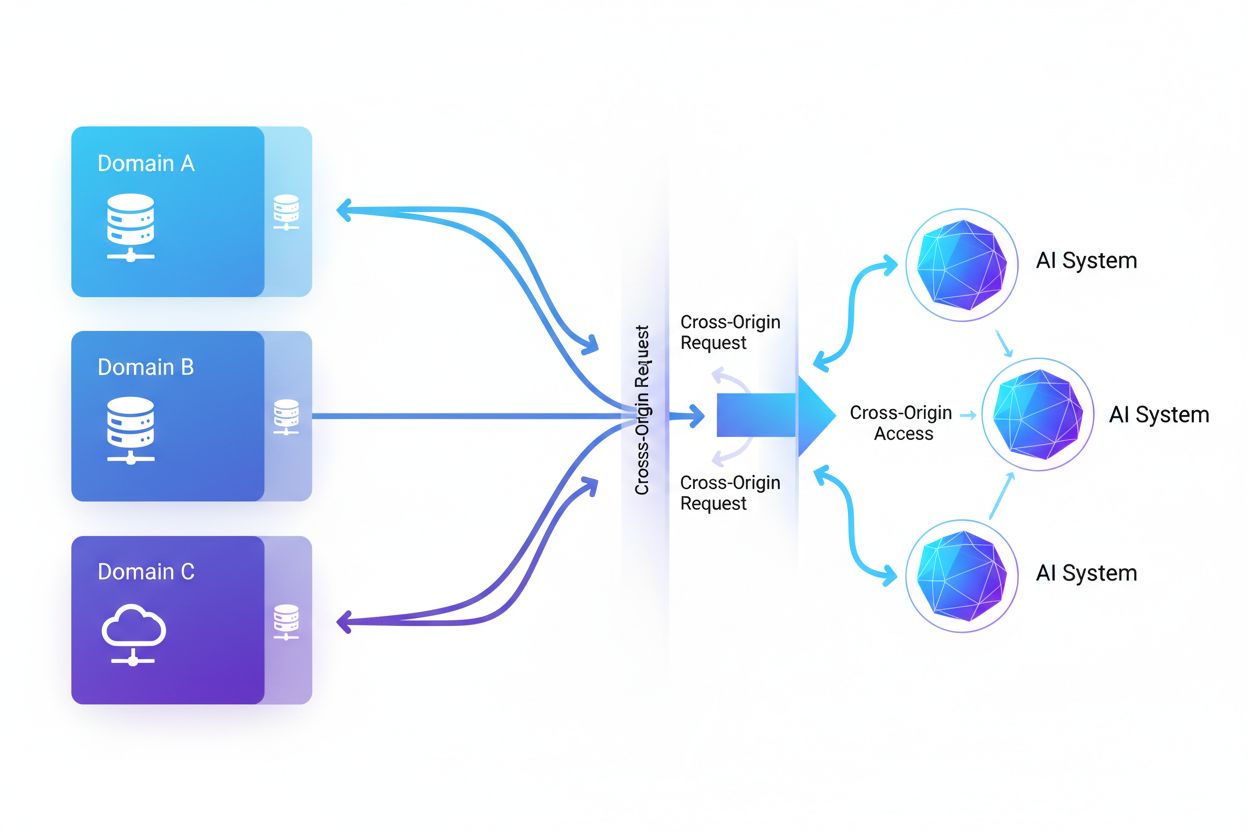
L’accès IA inter-origines désigne la capacité des systèmes d’intelligence artificielle et des robots d’indexation web à demander et récupérer du contenu depuis des domaines différents de leur origine, sous l’encadrement de mécanismes de sécurité comme CORS. Ce concept englobe la manière dont les entreprises d’IA intensifient la collecte de données pour l’entraînement de grands modèles de langage tout en contournant les restrictions inter-origines. Comprendre cette notion est crucial pour les créateurs de contenu et les propriétaires de sites web afin de protéger leur propriété intellectuelle et de garder la maîtrise sur l’utilisation de leur contenu par les systèmes d’IA. Disposer d’une visibilité sur l’activité IA inter-origines permet de distinguer l’accès légitime de l’IA du scraping non autorisé.
Accès IA inter-origines
L’accès IA inter-origines désigne la capacité des systèmes d’intelligence artificielle et des robots d’indexation web à demander et récupérer du contenu depuis des domaines différents de leur origine, sous l’encadrement de mécanismes de sécurité comme CORS. Ce concept englobe la manière dont les entreprises d’IA intensifient la collecte de données pour l’entraînement de grands modèles de langage tout en contournant les restrictions inter-origines. Comprendre cette notion est crucial pour les créateurs de contenu et les propriétaires de sites web afin de protéger leur propriété intellectuelle et de garder la maîtrise sur l’utilisation de leur contenu par les systèmes d’IA. Disposer d’une visibilité sur l’activité IA inter-origines permet de distinguer l’accès légitime de l’IA du scraping non autorisé.
Comprendre l’accès IA inter-origines
L’accès IA inter-origines désigne la capacité des systèmes d’intelligence artificielle et des robots d’indexation web à demander et récupérer du contenu depuis des domaines différents de leur origine, sous l’encadrement de mécanismes de sécurité comme le Cross-Origin Resource Sharing (CORS). À mesure que les entreprises d’IA intensifient la collecte de données pour entraîner de grands modèles de langage et autres systèmes d’IA, comprendre comment ces systèmes naviguent les restrictions inter-origines devient crucial pour les créateurs de contenu et les propriétaires de sites web. L’enjeu réside dans la distinction entre l’accès légitime de l’IA pour l’indexation de recherche et le scraping non autorisé à des fins d’entraînement de modèles, rendant la visibilité sur l’activité IA inter-origines essentielle pour protéger la propriété intellectuelle et garder la maîtrise sur l’utilisation du contenu.
Mécanisme CORS et robots IA
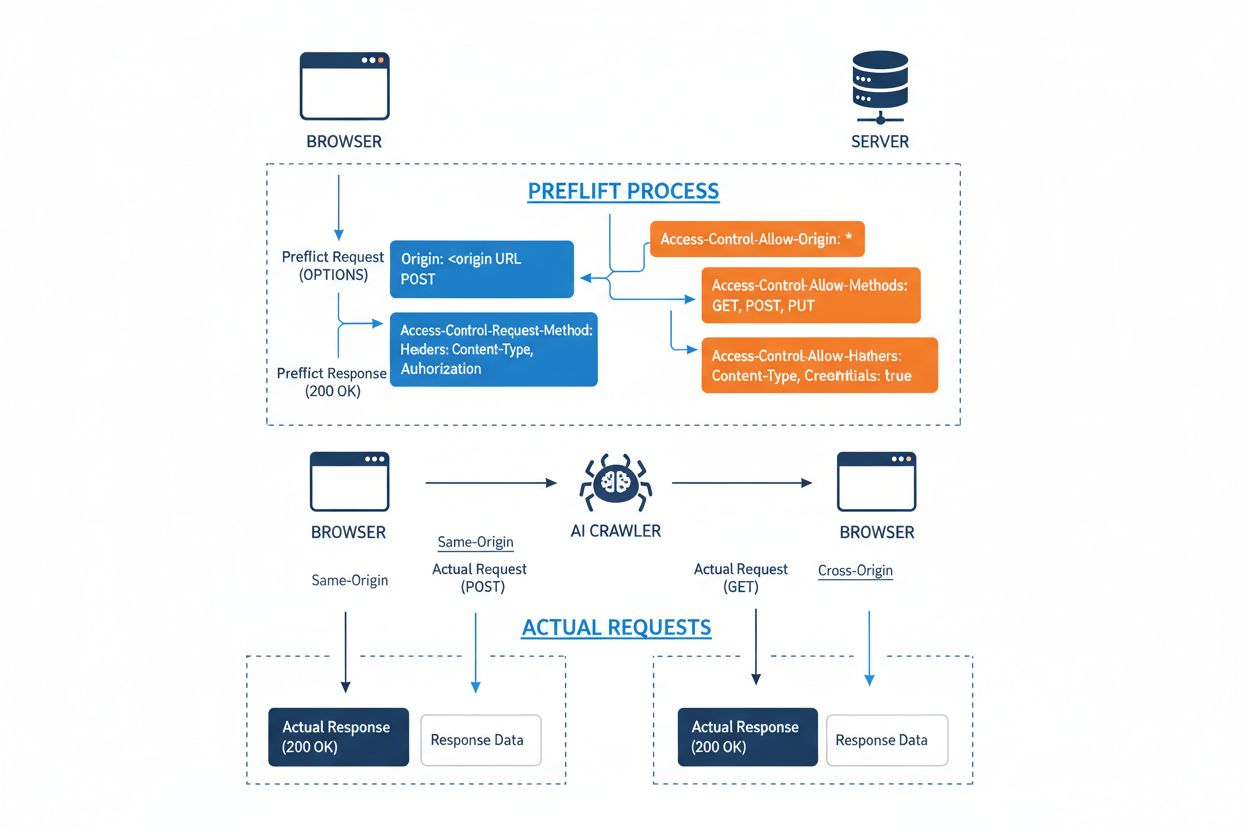
Le Cross-Origin Resource Sharing (CORS) est un mécanisme de sécurité basé sur les en-têtes HTTP qui permet aux serveurs de spécifier quelles origines (domaines, schémas ou ports) peuvent accéder à leurs ressources. Lorsqu’un robot IA ou tout autre client tente d’accéder à une ressource depuis une origine différente, le navigateur ou le client initie une requête préliminaire (preflight) utilisant la méthode HTTP OPTIONS pour vérifier si le serveur autorise la requête réelle. Le serveur répond avec des en-têtes CORS spécifiques qui dictent les permissions d’accès, notamment quelles origines sont autorisées, quelles méthodes HTTP sont permises, quels en-têtes peuvent être inclus et si les identifiants tels que cookies ou tokens d’authentification peuvent être envoyés avec la requête.
En-tête CORS
Rôle
Access-Control-Allow-Origin
Spécifie quelles origines peuvent accéder à la ressource (* pour toutes, ou domaines spécifiques)
Access-Control-Allow-Methods
Liste les méthodes HTTP autorisées (GET, POST, PUT, DELETE, etc.)
Access-Control-Allow-Headers
Définit quels en-têtes de requête sont autorisés (Authorization, Content-Type, etc.)
Access-Control-Allow-Credentials
Détermine si des identifiants (cookies, tokens d’authentification) peuvent être inclus dans les requêtes
Access-Control-Max-Age
Indique combien de temps les réponses préliminaires peuvent être mises en cache (en secondes)
Access-Control-Expose-Headers
Liste les en-têtes de réponse accessibles aux clients
Les robots IA interagissent avec CORS en respectant ces en-têtes lorsque ceux-ci sont correctement configurés, bien que de nombreux robots sophistiqués tentent de contourner ces restrictions en usurpant le user agent ou en utilisant des réseaux proxy. L’efficacité de CORS comme défense contre les accès IA non autorisés dépend entièrement d’une bonne configuration du serveur et de la volonté du robot de respecter les restrictions—une distinction critique devenue de plus en plus importante à mesure que les entreprises d’IA se concurrencent pour les données d’entraînement.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Le paysage des robots IA accédant au web s’est considérablement élargi, avec plusieurs acteurs majeurs dominant les modèles d’accès inter-origines. Selon l’analyse du trafic réseau de Cloudflare, les robots IA les plus répandus incluent :
Bytespider (ByteDance) – Utilisé pour collecter des données d’entraînement pour les modèles IA chinois, dont Doubao, accédant à environ 40% des sites du réseau Cloudflare
GPTBot (OpenAI) – Collecte des données d’entraînement pour ChatGPT et futurs modèles, accédant à environ 35% des sites protégés par Cloudflare
ClaudeBot (Anthropic) – Alimente l’assistant IA Claude, avec des volumes de requêtes en forte augmentation et accédant à environ 11% des sites
Amazonbot (Amazon) – Indexe le contenu pour les capacités de questions-réponses d’Alexa, représentant le deuxième plus grand volume de requêtes
CCBot (Common Crawl) – Robot à but non lucratif produisant des jeux de données web ouverts, utilisés par de nombreux projets IA, accédant à environ 2% des sites
Google-Extended (Google) – Distinct de Googlebot standard, explore spécifiquement le contenu pour Bard et Gemini
Perplexity Bot (Perplexity AI) – Récupère du contenu pour le moteur de recherche Perplexity, ayant notamment été pris à usurper des user agents pour contourner les restrictions
Ces robots génèrent des milliards de requêtes chaque mois, certains comme Bytespider et GPTBot accédant à la majorité du contenu public d’internet. L’ampleur et la nature agressive de cette activité ont poussé des plateformes majeures telles que Reddit, Twitter/X, Stack Overflow et de nombreux médias à mettre en place des mesures de blocage.
Vulnérabilités et risques de sécurité
Des politiques CORS mal configurées créent des vulnérabilités majeures que les robots IA peuvent exploiter pour accéder à des données sensibles sans autorisation. Lorsque les serveurs définissent Access-Control-Allow-Origin: * sans validation appropriée, ils permettent involontairement à toute origine—including des robots IA malveillants—d’accéder à des ressources qui devraient être restreintes. Une configuration particulièrement dangereuse survient lorsque Access-Control-Allow-Credentials: true est combiné à un paramétrage générique de l’origine, permettant aux attaquants de voler des données d’utilisateurs authentifiés via des requêtes inter-origines incluant des cookies de session ou des tokens d’authentification.
Les erreurs courantes de configuration CORS incluent la réflexion dynamique de l’en-tête Origin directement dans la réponse Access-Control-Allow-Origin sans validation, ce qui permet de fait à n’importe quelle origine d’accéder à la ressource. Des listes autorisées trop permissives, qui ne valident pas correctement les frontières de domaine, peuvent être exploitées via des attaques sur les sous-domaines ou la manipulation de préfixes. Par ailleurs, de nombreuses organisations n’implémentent pas une validation correcte de l’en-tête Origin lui-même, les rendant vulnérables aux requêtes usurpées. Les conséquences de ces vulnérabilités vont au-delà du vol de données et incluent l’entraînement non autorisé de modèles IA sur du contenu propriétaire, la collecte de renseignements concurrentiels et la violation de droits de propriété intellectuelle—des risques que des outils comme AmICited.com permettent de surveiller et de quantifier.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Méthodes de détection de l’accès IA inter-origines
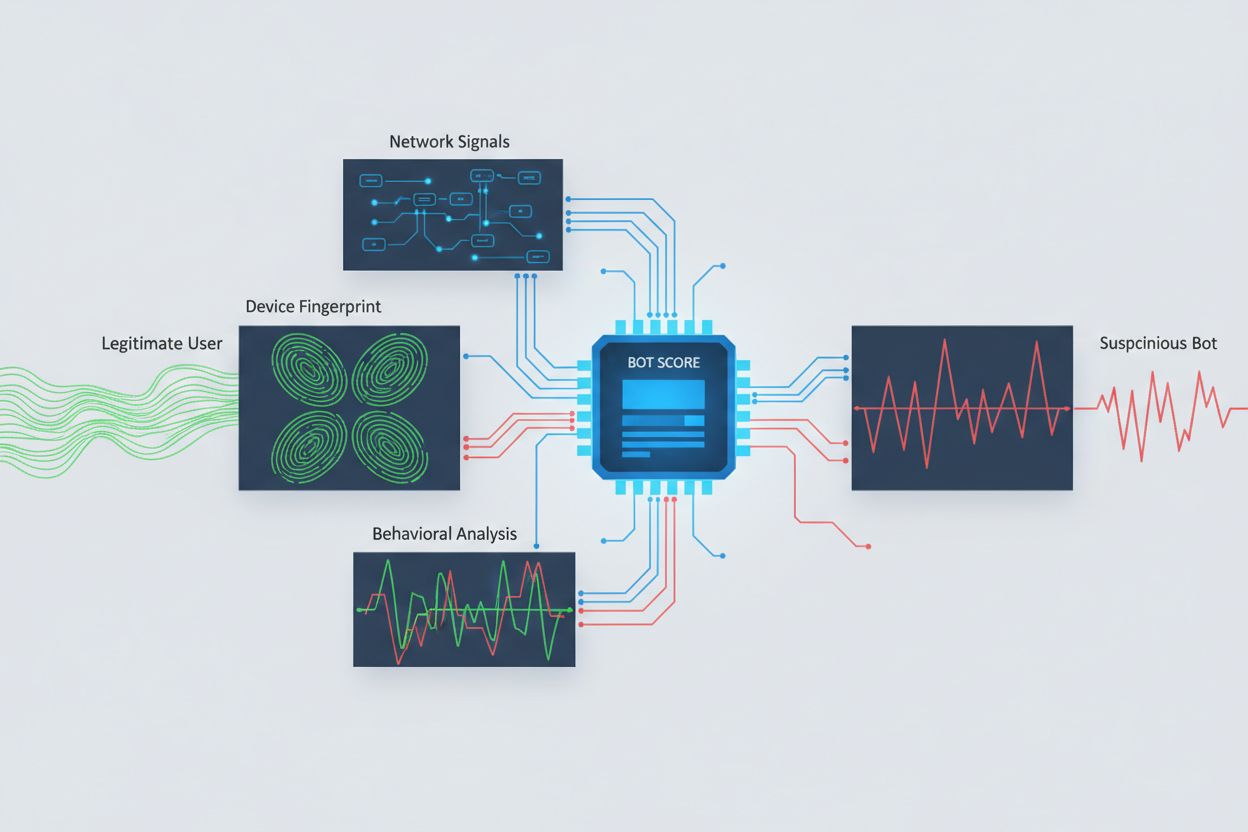
Identifier les robots IA tentant un accès inter-origines nécessite d’analyser plusieurs signaux au-delà des simples chaînes user agent, facilement usurpées. L’analyse du user agent reste une méthode de première ligne, car beaucoup de robots IA s’identifient via des chaînes user agent spécifiques comme “GPTBot/1.0” ou “ClaudeBot/1.0”, même si les robots sophistiqués masquent délibérément leur identité en se faisant passer pour des navigateurs légitimes. L’empreinte comportementale analyse la façon dont les requêtes sont effectuées—examinant des schémas comme la fréquence des requêtes, la séquence des pages visitées, la présence ou l’absence d’exécution JavaScript, et les interactions qui diffèrent fondamentalement du comportement de navigation humain.
L’analyse des signaux réseau offre des capacités de détection plus poussées en examinant les signatures de handshake TLS, la réputation des IP, les schémas de résolution DNS, et les caractéristiques de connexion révélant une activité de bot même lorsque les user agents sont usurpés. L’empreinte d’appareils agrège des dizaines de signaux incluant la version du navigateur, la résolution d’écran, les polices installées, les détails du système d’exploitation, et les empreintes TLS JA3 pour créer des identifiants uniques pour chaque source de requête. Des systèmes de détection avancés peuvent identifier lorsque plusieurs sessions proviennent du même appareil ou script, repérant ainsi les tentatives de scraping distribué cherchant à contourner la limitation de débit en répartissant les requêtes sur de nombreuses IP. Les organisations peuvent exploiter ces méthodes de détection via des plateformes de sécurité et des services de surveillance pour obtenir une visibilité sur les systèmes IA accédant à leur contenu et leurs méthodes de contournement.
Blocage et contrôle de l’accès IA
Les organisations mettent en œuvre plusieurs stratégies complémentaires pour bloquer ou contrôler l’accès IA inter-origines, reconnaissant qu’aucune méthode unique n’offre une protection totale :
Règles Disallow dans robots.txt – Ajouter des directives de refus pour les user agents IA connus (ex : User-agent: GPTBot suivi de Disallow: /) constitue un mécanisme poli mais volontaire ; efficace pour les robots respectueux mais facilement ignoré par les scrapers déterminés
Filtrage du user agent – Configurer les serveurs web ou les pare-feux pour bloquer ou rediriger certains user agents ; plus efficace que robots.txt mais vulnérable à l’usurpation car les user agents sont facilement falsifiés
Blocage d’adresses IP – Bloquer des plages IP associées à des robots connus ou à des fournisseurs cloud ; efficace contre les attaques distribuées mais contournable via la rotation de proxy et les réseaux IP résidentiels
Limitation de débit et throttling – Mettre en place des limites de fréquence de requêtes pour ralentir les robots ; réduit l’impact mais les bots sophistiqués peuvent répartir les requêtes sur de multiples IP pour rester sous les seuils
Honeypots et tarpits – Créer des liens cachés ou des labyrinthes de liens qu’interagissent uniquement les bots, gaspillant leurs ressources ; approche expérimentale mais peut dégrader la qualité des jeux de données collectés
Authentification et paywalls – Exiger des identifiants ou un paiement pour accéder au contenu ; très efficace mais contraignant pour les utilisateurs légitimes et inapplicable à tout type de contenu
Empreinte avancée des appareils – Analyser les signaux comportementaux et réseau pour identifier les bots, même en cas d’usurpation du user agent ; approche la plus sophistiquée mais nécessitant une intégration avec des plateformes de sécurité
La défense la plus efficace combine plusieurs couches, car des attaquants déterminés exploiteront les faiblesses de toute approche isolée. Les organisations doivent surveiller en continu l’efficacité de leurs méthodes de blocage et s’adapter à l’évolution des techniques de contournement des robots.
Bonnes pratiques pour la gestion de l’accès IA inter-origines
Une gestion efficace de l’accès IA inter-origines nécessite une approche globale et multicouche, équilibrant sécurité et besoins opérationnels. Les organisations doivent adopter une stratégie par paliers, commençant par les contrôles de base comme robots.txt et le filtrage du user agent, puis ajoutant progressivement des mécanismes de détection et de blocage plus sophistiqués selon la menace observée. La surveillance continue est essentielle—suivre quels systèmes IA accèdent à votre contenu, à quelle fréquence ils font des requêtes, et s’ils respectent vos restrictions, fournit la visibilité nécessaire pour prendre des décisions éclairées sur les politiques d’accès.
La documentation des politiques d’accès doit être claire et exécutoire, avec des conditions d’utilisation explicites interdisant le scraping non autorisé et précisant les conséquences des violations. Des audits réguliers des configurations CORS permettent d’identifier les erreurs avant qu’elles ne soient exploitées, tandis qu’un inventaire à jour des user agents et plages IP de robots IA connus permet de réagir rapidement aux nouvelles menaces. Les organisations doivent également considérer les enjeux business liés au blocage de l’IA—certains robots IA apportent de la valeur via l’indexation de recherche ou des partenariats légitimes, il convient donc de distinguer les accès bénéfiques des accès nuisibles. La mise en œuvre de ces pratiques requiert la coordination entre équipes sécurité, juridique et business pour garantir l’alignement des politiques avec les objectifs organisationnels et les exigences réglementaires.
Outils et solutions pour la gestion de l’accès IA
Des outils et plateformes spécialisés ont vu le jour pour aider les organisations à surveiller et contrôler l’accès IA inter-origines avec plus de précision et de visibilité. AmICited.com offre une surveillance complète de la façon dont les systèmes IA référencent et accèdent à votre marque sur GPTs, Perplexity, Google AI Overviews et d’autres plateformes IA, offrant une visibilité sur les modèles IA utilisant votre contenu et la fréquence d’apparition de votre marque dans les réponses générées par IA. Cette capacité de surveillance s’étend au suivi des schémas d’accès inter-origines et à la compréhension de l’écosystème plus large des systèmes IA interagissant avec vos ressources numériques.
Au-delà de la surveillance, Cloudflare propose des fonctionnalités de gestion des bots avec blocage en un clic des robots IA connus, s’appuyant sur des modèles d’apprentissage automatique entraînés sur des schémas de trafic réseau globaux pour identifier les bots même en cas d’usurpation de user agent. AWS WAF (Web Application Firewall) permet de créer des règles personnalisées pour bloquer des user agents ou plages IP spécifiques, tandis qu’Imperva offre une détection avancée combinant analyse comportementale et renseignements sur les menaces. Bright Data est spécialisé dans la compréhension des schémas de trafic de bots et peut aider à distinguer les différents types de robots. Le choix des outils dépend de la taille de l’organisation, du niveau de maturité technique et des besoins spécifiques—de la simple gestion de robots.txt pour les petits sites à des plateformes de gestion des bots de niveau entreprise pour les grandes structures manipulant des données sensibles. Quel que soit l’outil choisi, le principe fondamental reste le même : la visibilité sur l’accès IA inter-origines est la pierre angulaire d’un contrôle et d’une protection efficaces des actifs numériques.
Questions fréquemment posées
Quelle est la différence entre CORS et l'accès IA inter-origines ?
CORS (Cross-Origin Resource Sharing) est un mécanisme de sécurité qui contrôle quels origines peuvent accéder aux ressources d’un serveur. L’accès IA inter-origines fait spécifiquement référence à la manière dont les systèmes d’IA et robots d’indexation interagissent avec CORS pour demander du contenu depuis différents domaines. Tandis que CORS constitue le cadre technique, l’accès IA inter-origines décrit l’enjeu pratique de la gestion du comportement des robots IA dans ce cadre, y compris la détection et le blocage des accès IA non autorisés.
Comment les robots IA s’identifient-ils lors de l’accès au contenu ?
La plupart des robots IA respectueux s’identifient via des chaînes user agent spécifiques comme « GPTBot/1.0 » ou « ClaudeBot/1.0 » qui indiquent clairement leur fonction. Cependant, de nombreux robots sophistiqués usurpent délibérément le user agent en se faisant passer pour des navigateurs légitimes comme Chrome ou Safari pour contourner le blocage basé sur le user agent. C’est pourquoi des méthodes avancées de détection utilisant l’empreinte comportementale et l’analyse de signaux réseau sont nécessaires pour identifier les bots, quel que soit l’identité qu’ils revendiquent.
robots.txt peut-il effectivement bloquer les robots IA ?
robots.txt fournit un mécanisme volontaire pour demander aux robots de respecter les restrictions d’accès, et les robots IA respectueux comme GPTBot respectent généralement ces directives. Cependant, robots.txt n’est pas contraignant—les scrapers déterminés peuvent simplement l’ignorer. Beaucoup d’entreprises d’IA ont été prises en flagrant délit de contournement de robots.txt, ce qui en fait une défense nécessaire mais insuffisante, à compléter par des méthodes techniques comme le filtrage du user agent, la limitation de débit et l’empreinte des appareils.
Quels sont les principaux risques de sécurité liés à une mauvaise configuration de CORS pour l’accès IA ?
Des politiques CORS mal configurées peuvent permettre à des robots IA non autorisés d’accéder à des données sensibles, de voler des informations d’utilisateurs authentifiés via des requêtes avec identifiants, et de collecter du contenu propriétaire pour l’entraînement non autorisé de modèles IA. Les configurations les plus dangereuses combinent un paramétrage générique de l’origine (wildcard) avec la permission des identifiants, permettant de fait à n’importe quelle origine d’accéder aux ressources protégées. Ces mauvaises configurations peuvent entraîner le vol de propriété intellectuelle, la collecte de renseignements concurrentiels et la violation d’accords de licence de contenu.
Comment puis-je détecter si des systèmes IA accèdent à mon contenu ?
La détection nécessite l’analyse de plusieurs signaux au-delà des chaînes user agent. Vous pouvez examiner les journaux serveur pour repérer les agents utilisateurs de robots IA connus, mettre en œuvre l’empreinte comportementale afin d’identifier les bots d’après leurs schémas d’interaction, analyser les signaux réseau comme les handshakes TLS et les schémas DNS, et utiliser l’empreinte d’appareils pour repérer les tentatives de scraping réparties. Des outils comme AmICited.com offrent une surveillance complète de la manière dont les systèmes IA référencent votre marque, tandis que des plateformes comme Cloudflare proposent une détection des bots basée sur l’apprentissage automatique, capable d’identifier même les robots usurpés.
Quelle est la méthode la plus efficace pour bloquer les robots IA indésirables ?
Aucune méthode unique n’offre une protection totale, donc une approche multicouche est la plus efficace. Commencez par robots.txt et le filtrage du user agent pour une défense de base, ajoutez la limitation de débit pour réduire l’impact, implémentez l’empreinte d’appareils pour piéger les bots sophistiqués, et envisagez l’authentification ou les paywalls pour les contenus sensibles. Les organisations les plus efficaces combinent plusieurs techniques et surveillent en continu celles qui fonctionnent, en s’adaptant à mesure que les robots affinent leurs techniques de contournement.
Toutes les entreprises d’IA respectent-elles les restrictions d’accès inter-origines ?
Non. Bien que les grandes entreprises comme OpenAI et Anthropic affirment respecter robots.txt et les restrictions CORS, des enquêtes ont révélé que de nombreux robots IA contournent ces restrictions. Perplexity AI a été pris à usurper des user agents pour contourner les blocages, et des recherches montrent que des robots OpenAI et Anthropic ont été observés accédant à du contenu malgré des règles de refus explicites dans robots.txt. Cette incohérence explique pourquoi les méthodes de blocage technique et l’application juridique deviennent de plus en plus nécessaires.
Comment AmICited.com aide-t-il à surveiller l’accès IA à mon contenu ?
AmICited.com offre une surveillance complète de la façon dont les systèmes IA référencent et accèdent à votre marque sur GPTs, Perplexity, Google AI Overviews et d’autres plateformes IA. Il suit quels modèles IA utilisent votre contenu, à quelle fréquence votre marque apparaît dans les réponses générées par IA, et fournit une visibilité sur l’écosystème plus large des systèmes IA interagissant avec vos ressources numériques. Cette surveillance vous aide à comprendre l’étendue de l’accès IA et à prendre des décisions éclairées concernant votre stratégie de protection de contenu.
Surveillez comment les systèmes IA accèdent à votre contenu
Obtenez une visibilité complète sur les systèmes d’IA accédant à votre marque sur GPTs, Perplexity, Google AI Overviews et d’autres plateformes. Suivez les schémas d’accès IA inter-origines et comprenez comment votre contenu est utilisé dans l'entraînement et l’inférence IA.
L'IA peut-elle accéder au contenu protégé ? Méthodes et implications
Découvrez comment les systèmes d'IA accèdent au contenu payant et protégé, les techniques qu'ils utilisent, et comment protéger votre contenu tout en maintenant...
Exigences en matière de diversité des sources pour l’IA
Découvrez comment les systèmes d’IA choisissent entre la citation de multiples sources et la concentration sur des sources autorisées. Comprenez les schémas de ...
Comment tester l'accès des crawlers IA à votre site web
Découvrez comment vérifier si les crawlers IA comme ChatGPT, Claude et Perplexity peuvent accéder au contenu de votre site web. Découvrez les méthodes de test, ...
11 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.