
Recherche sémantique
La recherche sémantique interprète le sens et le contexte des requêtes à l’aide du NLP et de l’apprentissage automatique. Découvrez comment elle diffère de la r...
15 min de lecture

La correspondance sémantique des requêtes est une technique alimentée par l’IA qui comprend l’intention de l’utilisateur et la signification derrière les requêtes de recherche, fournissant des résultats pertinents même lorsque les mots-clés exacts ne correspondent pas. Elle utilise le traitement du langage naturel et l’apprentissage automatique pour interpréter le contexte, les synonymes et les relations entre concepts, permettant des expériences de recherche plus précises et intuitives à travers des systèmes d’IA comme les GPT, Perplexity et Google AI Overviews.
La correspondance sémantique des requêtes est une technique alimentée par l'IA qui comprend l'intention de l'utilisateur et la signification derrière les requêtes de recherche, fournissant des résultats pertinents même lorsque les mots-clés exacts ne correspondent pas. Elle utilise le traitement du langage naturel et l'apprentissage automatique pour interpréter le contexte, les synonymes et les relations entre concepts, permettant des expériences de recherche plus précises et intuitives à travers des systèmes d'IA comme les GPT, Perplexity et Google AI Overviews.
La correspondance sémantique des requêtes est une technologie de recherche sophistiquée qui comprend la signification et l’intention derrière les requêtes des utilisateurs plutôt que de simplement associer des mots-clés individuels. Contrairement à la correspondance traditionnelle de mots-clés, qui recherche des correspondances exactes ou des variantes simples, la correspondance sémantique analyse la signification contextuelle des termes de recherche pour fournir des résultats plus pertinents. Par exemple, un système sémantique reconnaîtrait que « Comment réparer l’écran cassé de mon téléphone ? » et « Mon écran d’appareil est fissuré » sont essentiellement la même requête, même si des mots complètement différents sont utilisés, tandis qu’un système basé sur les mots-clés traiterait ces recherches séparément.
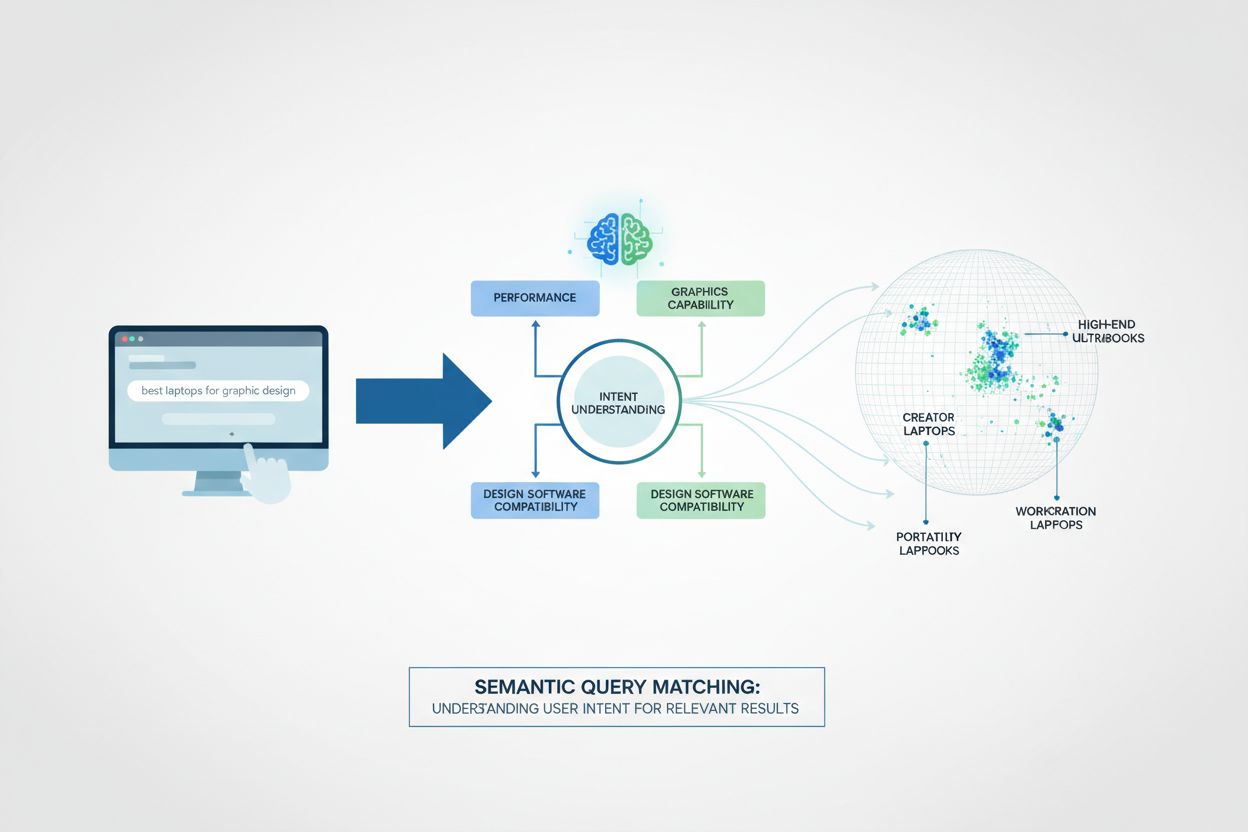
La correspondance sémantique des requêtes fonctionne grâce à un processus technique en plusieurs couches qui transforme à la fois les requêtes et les documents en représentations mathématiques appelées embeddings. Le système traite d’abord le langage naturel via des algorithmes NLP pour en extraire la signification, puis convertit cette compréhension en vecteurs de haute dimension qui capturent les relations sémantiques. Un mécanisme de score de similarité compare le vecteur de la requête à ceux des documents pour classer les résultats par pertinence plutôt que par fréquence de mots-clés. Cette approche permet au système de comprendre les synonymes, le contexte et l’intention de l’utilisateur sans programmation explicite pour chaque variation.
| Aspect | Recherche Traditionnelle par Mots-Clés | Correspondance Sémantique des Requêtes |
|---|---|---|
| Méthode d’appariement | Correspondance exacte ou partielle de mots | Score de similarité basé sur la signification |
| Compréhension de l’intention | Limitée ; dépend de la présence de mots-clés | Analyse contextuelle profonde de l’intention |
| Gestion des synonymes | Nécessite des listes de synonymes manuelles | Reconnaît automatiquement les équivalents sémantiques |
| Sensibilité au contexte | Minimale ; traite les mots indépendamment | Complète ; analyse les relations entre les termes |
| Capacité d’apprentissage | Statique ; n’évolue pas avec l’usage | Dynamique ; s’améliore grâce aux mises à jour des modèles et aux retours |
La base technologique de la correspondance sémantique des requêtes repose sur plusieurs composants interconnectés travaillant de concert :
La correspondance sémantique des requêtes est devenue indispensable dans de nombreux secteurs et applications. Dans le e-commerce, elle aide les clients à trouver des produits en utilisant des descriptions en langage naturel plutôt que le nom exact du produit—une recherche « chaussures confortables pour courir » renverra des chaussures de sport pertinentes même sans ces mots exacts. Les systèmes de support client utilisent la correspondance sémantique pour orienter les demandes vers les bons services en comprenant le problème sous-jacent plutôt qu’en se basant sur des mots-clés. Les plateformes de recherche d’entreprise permettent aux employés de retrouver des documents internes avec des requêtes conceptuelles. Les systèmes modernes d’IA comme ChatGPT, Perplexity et Google AI Overviews reposent fortement sur la correspondance sémantique pour comprendre l’intention utilisateur et récupérer des données d’entraînement pertinentes. Les moteurs de recommandation de contenu utilisent la correspondance sémantique pour suggérer des articles, vidéos et produits sur la base de la signification et non de simples balises explicites.
Les avantages de la correspondance sémantique des requêtes améliorent considérablement l’expérience utilisateur et l’efficacité des systèmes. Une pertinence accrue permet aux utilisateurs de trouver ce qu’ils recherchent du premier coup, réduisant la frustration et les itérations de recherche. La technologie excelle dans la gestion des requêtes ambiguës ou mal formulées, comprenant l’intention même lorsque l’utilisateur peine à exprimer précisément son besoin. La compréhension des synonymes élimine le besoin de deviner la terminologie exacte—que vous recherchiez « automobile », « voiture » ou « véhicule », les systèmes sémantiques reconnaissent l’équivalence. Cette capacité favorise un engagement accru en permettant aux utilisateurs de découvrir plus de contenu pertinent, ce qui mène à une plus grande satisfaction et à des taux de conversion plus élevés. L’expérience utilisateur supérieure offerte par la correspondance sémantique est devenue un impératif compétitif dans les produits numériques modernes.
Malgré ses avantages, la correspondance sémantique des requêtes fait face à d’importants défis techniques et pratiques. La complexité computationnelle reste élevée ; le traitement de vecteurs de grande dimension et le calcul de similarités sur des millions de documents nécessitent une puissance de calcul et une infrastructure importantes. Les préoccupations liées à la confidentialité des données émergent car les systèmes sémantiques doivent traiter et analyser en détail les requêtes des utilisateurs, soulevant des questions sur la rétention et la sécurité des données. L’entraînement des modèles exige de vastes ensembles de données de qualité et des ressources de calcul conséquentes, créant des barrières pour les petites organisations. La technologie comporte un risque de mauvaise interprétation—les modèles sémantiques peuvent retourner avec confiance des résultats hors-sujet lorsqu’ils comprennent mal le contexte ou rencontrent des requêtes hors domaine. Le classique compromis latence/précision signifie qu’une analyse sémantique plus poussée prend plus de temps, ce qui peut nuire à la performance en temps réel de la recherche.
AmICited.com exploite la correspondance sémantique des requêtes pour révolutionner la façon dont les marques surveillent leur présence dans le contenu et les réponses générés par l’IA. Plutôt que de simplement suivre les mentions exactes de la marque, la plateforme d’AmICited.com comprend l’intention et le contexte des références faites par les systèmes d’IA aux marques, produits et entreprises sur ChatGPT, Perplexity, Google AI Overviews et d’autres grandes plateformes d’IA. L’approche sémantique permet de détecter des références indirectes, des mentions comparatives et des citations contextuelles que la surveillance basée sur les mots-clés manquerait totalement. Cette compréhension approfondie offre aux marques une visibilité complète sur la façon dont les systèmes d’IA présentent leurs offres aux utilisateurs—une intelligence critique pour maintenir la réputation de la marque et son positionnement sur le marché. Les capacités sémantiques d’AmICited.com fonctionnent de manière fluide avec des outils complémentaires tels que FlowHunt.io, spécialisé dans l’optimisation des flux de travail, créant un écosystème complet pour la surveillance de l’IA et l’intelligence de marque. En comprenant la signification sémantique des réponses générées par l’IA, AmICited.com aide les marques à identifier des opportunités, corriger les mauvaises interprétations et optimiser leur présence dans le paysage informationnel piloté par l’IA.
La correspondance sémantique des requêtes continue d’évoluer vers des implémentations plus sophistiquées et efficaces. La correspondance multimodale représente la nouvelle frontière, permettant aux systèmes de comprendre les requêtes et de les associer à des images, vidéos et contenus audio à l’aide de cadres sémantiques unifiés. Les chercheurs développent des modèles d’embeddings plus efficaces qui maintiennent la compréhension sémantique tout en réduisant les besoins computationnels, rendant la recherche sémantique accessible aux plus petites organisations. Une personnalisation améliorée permettra aux systèmes sémantiques d’adapter la correspondance en fonction des préférences individuelles, de l’historique de recherche et du contexte. L’intégration avec les systèmes d’IA émergents étendra la correspondance sémantique au-delà de la recherche traditionnelle vers l’IA conversationnelle, les assistants vocaux et les systèmes autonomes. Les efforts de standardisation établissent des cadres et référentiels communs pour la correspondance sémantique, permettant une meilleure interopérabilité et comparaison entre plateformes. À mesure que ces technologies mûrissent, la correspondance sémantique des requêtes deviendra la norme attendue plutôt qu’une fonctionnalité premium.
La correspondance sémantique comprend l'intention et la signification, tandis que la recherche par mots-clés recherche des correspondances exactes. La correspondance sémantique peut trouver des résultats pertinents même lorsque les mots-clés exacts ne sont pas utilisés, en reconnaissant que différentes expressions peuvent exprimer le même concept.
Les embeddings vectoriels convertissent le texte en représentations numériques qui capturent la signification. Les concepts similaires sont positionnés proches les uns des autres dans l'espace vectoriel, permettant au système de trouver un contenu sémantiquement lié en calculant les distances entre les vecteurs.
Le traitement du langage naturel (NLP), les modèles d'apprentissage automatique comme BERT et GPT, les embeddings vectoriels et les graphes de connaissances travaillent ensemble pour comprendre l'intention de la requête et l'associer au contenu pertinent.
Oui, la correspondance sémantique excelle dans la compréhension des synonymes et des variations sémantiques. Elle reconnaît que « voiture », « véhicule » et « automobile » ont des significations similaires et peut associer des requêtes utilisant l'un de ces termes sans configuration manuelle.
Elle fournit des résultats plus pertinents plus rapidement, réduit le besoin pour les utilisateurs de reformuler leurs recherches, et permet une formulation de requêtes plus naturelle et conversationnelle sans exiger de correspondance exacte de mots-clés.
Les principaux défis incluent la complexité computationnelle, les préoccupations relatives à la confidentialité des données, la nécessité d'un entraînement continu des modèles, le risque de mauvaise interprétation et l'équilibre entre précision et rapidité de réponse.
La correspondance sémantique permet à des systèmes comme AmICited.com de comprendre l'intention derrière le contenu généré par l'IA et de suivre les mentions de marque même lorsque les noms exacts ne sont pas utilisés, offrant une surveillance complète de la visibilité de la marque.
Bien que la correspondance sémantique soit de plus en plus répandue, les deux approches coexistent. De nombreux systèmes modernes utilisent des approches hybrides combinant la compréhension sémantique et la correspondance de mots-clés pour des résultats optimaux.
AmICited.com utilise la correspondance sémantique des requêtes pour suivre les mentions de votre marque sur ChatGPT, Perplexity et Google AI Overviews—comprenant non seulement ce qui est dit, mais aussi l'intention derrière.
La recherche sémantique interprète le sens et le contexte des requêtes à l’aide du NLP et de l’apprentissage automatique. Découvrez comment elle diffère de la r...
Découvrez comment la recherche sémantique utilise l'IA pour comprendre l'intention de l'utilisateur et le contexte. Apprenez en quoi elle diffère de la recherch...
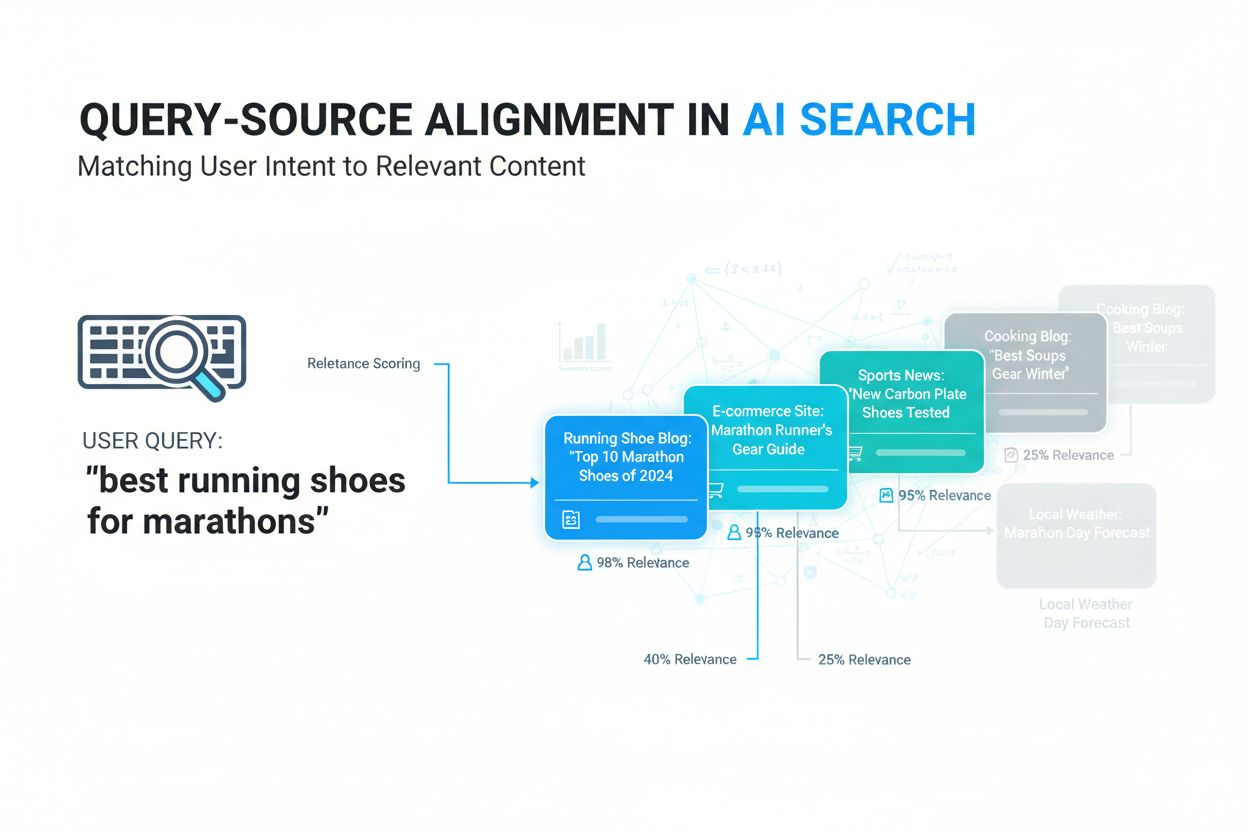
Découvrez ce qu'est l'alignement requête-source, comment les systèmes IA associent les requêtes utilisateurs aux sources pertinentes, et pourquoi cela est essen...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.