
Crawler AI spiegati: GPTBot, ClaudeBot e altri
Comprendi come funzionano i crawler AI come GPTBot e ClaudeBot, le loro differenze rispetto ai crawler di ricerca tradizionali e come ottimizzare il tuo sito pe...
15 min di lettura

Guida completa ai crawler AI nel 2025. Identifica GPTBot, ClaudeBot, PerplexityBot e oltre 20 altri bot AI. Scopri come bloccare, consentire o monitorare i crawler con robots.txt e tecniche avanzate.
I crawler AI sono bot automatizzati progettati per navigare e raccogliere dati sistematicamente dai siti web, ma il loro scopo si è profondamente trasformato negli ultimi anni. Mentre i tradizionali crawler dei motori di ricerca come Googlebot si concentrano sull’indicizzazione dei contenuti per i risultati di ricerca, i moderni crawler AI danno priorità alla raccolta di dati di training per grandi modelli linguistici e sistemi di AI generativa. Secondo dati recenti di Playwire, i crawler AI ora rappresentano circa l'80% di tutto il traffico dei bot AI, segnando un aumento drastico nel volume e nella diversità dei visitatori automatizzati sui siti web. Questo cambiamento riflette la trasformazione più ampia nelle modalità di sviluppo e addestramento dei sistemi di intelligenza artificiale, che si spostano dai dataset pubblici verso la raccolta di contenuti web in tempo reale. Comprendere questi crawler è diventato essenziale per proprietari di siti, publisher e creatori di contenuti che devono prendere decisioni informate sulla propria presenza digitale.
I crawler AI possono essere classificati in tre categorie distinte in base alla loro funzione, comportamento e impatto sul tuo sito. I crawler di training rappresentano il segmento più ampio, con circa l'80% del traffico bot AI, e sono progettati per raccogliere contenuti utili all’addestramento dei modelli di machine learning; questi crawler operano tipicamente con elevato volume e con scarso traffico di referral, risultando intensivi in termini di banda ma difficilmente in grado di portare visitatori al tuo sito. I crawler di ricerca e citazione operano a volumi moderati e sono specificamente progettati per trovare e referenziare contenuti nei risultati di ricerca AI e nelle applicazioni; a differenza dei crawler di training, questi bot possono effettivamente inviare traffico al tuo sito quando gli utenti cliccano nelle risposte AI. I fetcher attivati dall’utente rappresentano la categoria più piccola e operano su richiesta, quando gli utenti richiedono esplicitamente il recupero di contenuti tramite applicazioni AI come la funzione di navigazione di ChatGPT; questi crawler hanno basso volume ma alta rilevanza per le singole richieste utente.
| Categoria | Scopo | Esempi |
|---|---|---|
| Crawler di training | Raccolta dati per l’addestramento AI | GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider |
| Crawler di ricerca/citazione | Trovare e referenziare contenuti nelle risposte AI | OAI-SearchBot, Claude-SearchBot, PerplexityBot, You.com |
| Fetcher attivati dall’utente | Recupero contenuti su richiesta per l’utente | ChatGPT-User, Claude-Web, Gemini-Deep-Research |
OpenAI gestisce l’ecosistema di crawler più diversificato e aggressivo nel panorama AI, con molteplici bot che svolgono funzioni diverse nella propria suite di prodotti. GPTBot è il loro principale crawler di training, responsabile della raccolta di contenuti per migliorare GPT-4 e i modelli futuri, e ha registrato una crescita impressionante del 305% nel traffico secondo dati Cloudflare; questo bot opera con un rapporto crawl/referral di 400:1, cioè scarica contenuti 400 volte per ogni visitatore rimandato al tuo sito. OAI-SearchBot ha una funzione completamente diversa, focalizzandosi sulla ricerca e citazione di contenuti per la funzione Search di ChatGPT senza utilizzare i contenuti per l’addestramento del modello. ChatGPT-User rappresenta la categoria di crescita più esplosiva, con un aumento del traffico del 2.825%, e opera ogni volta che gli utenti attivano la funzione “Browse with Bing” per ottenere contenuti in tempo reale su richiesta. Puoi identificare questi crawler dagli user-agent: GPTBot/1.0, OAI-SearchBot/1.0 e ChatGPT-User/1.0, e OpenAI fornisce metodi di verifica IP per confermare il traffico legittimo proveniente dalla loro infrastruttura.
Anthropic, l’azienda dietro Claude, gestisce una delle operazioni di crawling più selettive ma intensive del settore. ClaudeBot è il loro principale crawler di training e opera con uno straordinario rapporto crawl/referral di 38.000:1, cioè scarica contenuti molto più aggressivamente dei bot di OpenAI in proporzione al traffico di referral; questo riflette la volontà di Anthropic di raccogliere dati in modo esaustivo per l’addestramento. Claude-Web e Claude-SearchBot hanno funzioni diverse: il primo gestisce il recupero di contenuti attivato dall’utente, il secondo si occupa di ricerca e citazione. Google ha adattato la sua strategia di crawling per l’era AI introducendo Google-Extended, un token speciale che consente ai siti di optare per l’addestramento AI bloccando la classica indicizzazione di Googlebot, e Gemini-Deep-Research, che effettua ricerche approfondite per gli utenti dei prodotti AI di Google. Molti proprietari di siti discutono se bloccare Google-Extended, dato che proviene dalla stessa azienda che controlla il traffico di ricerca, rendendo la decisione più complessa rispetto ai crawler AI di terze parti.
Meta è diventata un attore di rilievo nello spazio dei crawler AI con Meta-ExternalAgent, che rappresenta circa il 19% del traffico dei crawler AI e viene usato per addestrare i modelli AI e alimentare funzionalità su Facebook, Instagram e WhatsApp. Meta-WebIndexer ha una funzione complementare, focalizzandosi sull’indicizzazione web per le funzionalità e raccomandazioni AI. Apple ha introdotto Applebot-Extended a supporto di Apple Intelligence, le funzionalità AI on-device, e questo crawler è cresciuto costantemente man mano che l’azienda espande le capacità AI su iPhone, iPad e Mac. Amazon gestisce Amazonbot per alimentare Alexa e Rufus, l’assistente AI per lo shopping, rendendolo rilevante per siti e contenuti orientati all’e-commerce. PerplexityBot rappresenta una delle crescite più drammatiche nel panorama dei crawler, con un incredibile aumento del traffico del 157.490%, riflettendo la crescita esplosiva di Perplexity AI come alternativa di ricerca; nonostante questa crescita, Perplexity rappresenta ancora un volume assoluto minore rispetto a OpenAI e Google, ma la traiettoria indica un’importanza in rapido aumento.
Oltre ai grandi player, numerosi crawler AI emergenti e specializzati raccolgono attivamente dati dai siti web di tutto il mondo. Bytespider, gestito da ByteDance (la casa madre di TikTok), ha registrato un calo drammatico dell’85% nel traffico, suggerendo un cambio di strategia o una riduzione delle esigenze di training. Cohere, Diffbot e il CCBot di Common Crawl sono crawler specializzati focalizzati su casi d’uso specifici, dal training linguistico all’estrazione di dati strutturati. You.com, Mistral e DuckDuckGo gestiscono ciascuno i propri crawler per supportare le funzionalità AI di ricerca e assistenza, aumentando la complessità del panorama. L’emergere di nuovi crawler è costante: startup e aziende affermate lanciano prodotti AI che richiedono raccolta dati dal web. Restare informati su questi crawler emergenti è cruciale, perché bloccarli o consentirli può influire notevolmente sulla visibilità nei nuovi canali AI.
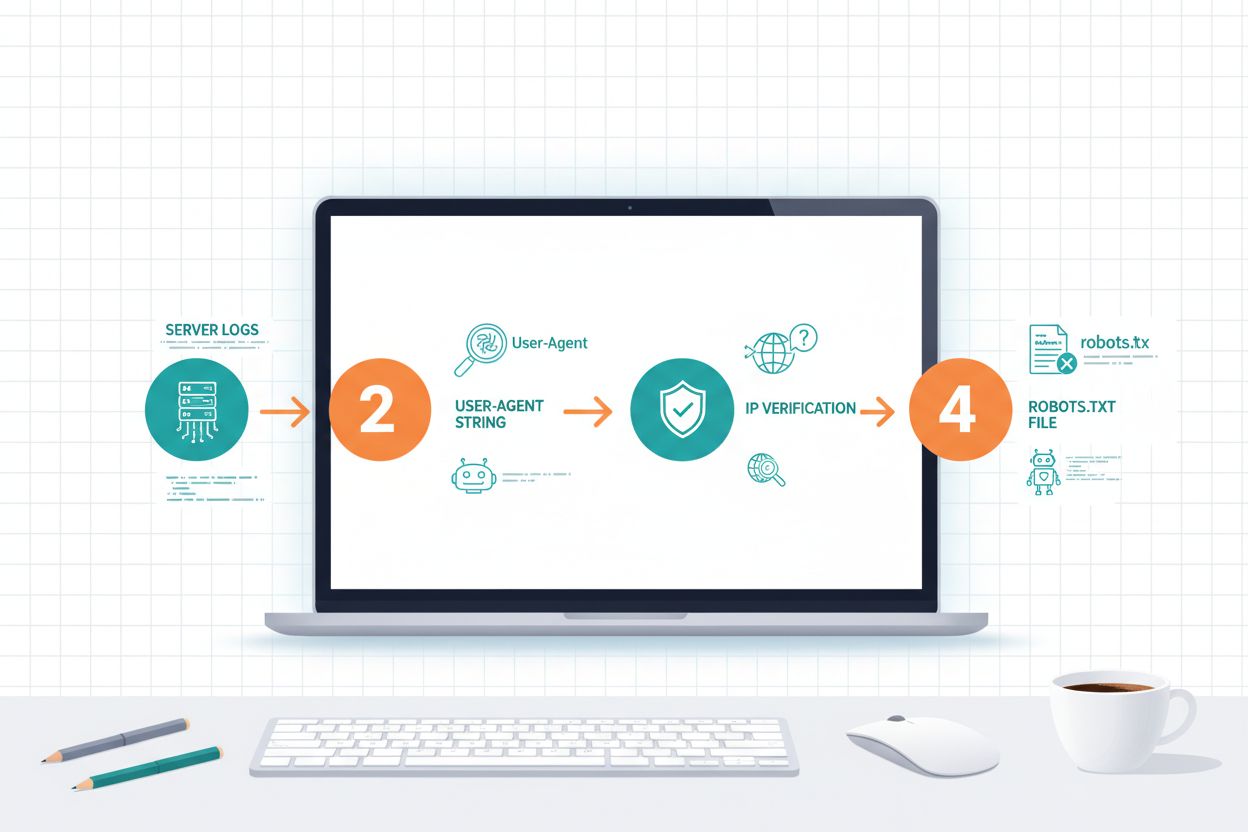
Identificare i crawler AI richiede la comprensione di come si dichiarano e l’analisi dei pattern di traffico sul server. Gli user-agent sono il principale metodo: ogni crawler si identifica con una stringa specifica nelle richieste HTTP; ad esempio, GPTBot usa GPTBot/1.0, ClaudeBot usa Claude-Web/1.0 e PerplexityBot usa PerplexityBot/1.0. Analizzare i log del server (di solito in /var/log/apache2/access.log su Linux o nei log IIS su Windows) ti permette di vedere quali crawler accedono al tuo sito e con quale frequenza. La verifica IP è un’altra tecnica fondamentale per confermare che un crawler che si dichiara di OpenAI o Anthropic provenga effettivamente dai loro IP pubblicati, che queste aziende condividono per motivi di sicurezza. Esaminare il proprio robots.txt rivela quali crawler sono esplicitamente consentiti o bloccati e confrontare questo dato con il traffico reale mostra se rispettano le tue direttive. Strumenti come Cloudflare Radar forniscono visibilità in tempo reale sui pattern di traffico dei crawler e aiutano a identificare i bot più attivi sul tuo sito. Passi pratici: verifica la tua piattaforma analytics per traffico bot, rivedi i log grezzi per pattern di user-agent, incrocia gli IP con quelli pubblicati dai crawler e usa strumenti di verifica online per confermare le fonti sospette.
Decidere se consentire o bloccare i crawler AI significa valutare varie considerazioni di business che non hanno una risposta univoca. I compromessi principali sono:
Poiché l'80% del traffico bot AI proviene dai crawler di training con scarso potenziale di referral, molti publisher scelgono di bloccare solo questi lasciando passare i crawler di ricerca e citazione. La decisione dipende dal tuo modello di business, dal tipo di contenuto e dalle priorità strategiche tra visibilità AI e consumo di risorse.
Il file robots.txt è lo strumento principale per comunicare le policy ai crawler AI, ma è importante ricordare che il rispetto è volontario e non tecnicamente vincolante. Robots.txt usa il matching sugli user-agent per indirizzare crawler specifici, permettendo di creare regole diverse per ogni bot; ad esempio, puoi bloccare GPTBot ma consentire OAI-SearchBot, o bloccare tutti i crawler di training ma permettere quelli di ricerca. Secondo recenti ricerche, solo il 14% dei primi 10.000 domini ha implementato regole robots.txt specifiche per l’AI, segno che la maggior parte dei siti non ha ancora ottimizzato le policy per questa nuova era. La sintassi è semplice: si indica il nome dell’user-agent seguito dalle direttive allow/disallow e si possono usare i wildcard per regole multiple.
Ecco tre scenari pratici di configurazione robots.txt:
# Scenario 1: Blocca tutti i crawler di training AI, consenti quelli di ricerca
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
# Scenario 2: Blocca completamente tutti i crawler AI
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Scenario 3: Blocco selettivo per directory
User-agent: GPTBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
User-agent: ClaudeBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
Ricorda che robots.txt è solo una raccomandazione e i crawler malevoli o non conformi possono ignorare le tue direttive. Il matching sugli user-agent non distingue maiuscole/minuscole: gptbot, GPTBot e GPTBOT sono equivalenti, e puoi usare User-agent: * per regole applicate a tutti i crawler.
Oltre a robots.txt, esistono metodi avanzati per proteggersi dai crawler AI indesiderati, ognuno con diversi livelli di efficacia e complessità. Verifica IP e regole firewall permettono di bloccare il traffico da specifici range IP associati ai crawler AI; puoi ottenere questi range dalla documentazione degli operatori e configurare il firewall o il Web Application Firewall (WAF) per respingere le richieste, ma serve manutenzione periodica perché gli IP cambiano. Il blocco a livello server tramite .htaccess (per Apache) controlla user-agent e IP prima di servire i contenuti, offrendo enforcement più affidabile di robots.txt.
Ecco un esempio pratico di blocco crawler avanzato su .htaccess:
# Blocca i crawler di training AI a livello server
<IfModule mod_rewrite.c>
RewriteEngine On
# Blocca in base allo user-agent
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|Meta-ExternalAgent|Amazonbot|Bytespider) [NC]
RewriteRule ^.*$ - [F,L]
# Blocca in base all’indirizzo IP (esempi - sostituire con quelli reali)
RewriteCond %{REMOTE_ADDR} ^192\.0\.2\.0$ [OR]
RewriteCond %{REMOTE_ADDR} ^198\.51\.100\.0$
RewriteRule ^.*$ - [F,L]
# Consenti crawler specifici bloccando altri
RewriteCond %{HTTP_USER_AGENT} !OAI-SearchBot [NC]
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
# Approccio meta tag HTML (aggiungere nell’header delle pagine)
# <meta name="robots" content="noarchive, noimageindex">
# <meta name="googlebot" content="noindex, nofollow">
I meta tag HTML come <meta name="robots" content="noarchive"> e <meta name="googlebot" content="noindex"> danno controllo a livello pagina, ma sono meno affidabili del blocco server perché i crawler devono analizzare l’HTML per vederli. Nota che è tecnicamente possibile lo spoofing IP, cioè attori avanzati possono camuffarsi da IP legittimi, quindi la combinazione di più metodi offre maggiore protezione. Ogni metodo ha pro e contro: robots.txt è facile ma non vincolante, il blocco IP è affidabile ma va mantenuto, .htaccess offre enforcement server-side, i meta tag danno granularità pagina per pagina.
Implementare le policy per i crawler è solo metà dell’opera: devi monitorare attivamente che i crawler rispettino le tue direttive e regolare la strategia in base ai pattern reali. I log del server sono la fonte principale, di solito in /var/log/apache2/access.log su Linux o nella cartella log IIS su Windows, dove puoi cercare user-agent per vedere quali crawler accedono e quanto spesso. Piattaforme di analytics come Google Analytics, Matomo o Plausible possono essere configurate per tracciare il traffico bot separatamente da quello umano, permettendoti di vedere volumi e comportamenti dei vari crawler nel tempo. Cloudflare Radar offre visibilità in tempo reale sui pattern di traffico dei crawler e confronta il tuo sito con la media del settore. Per verificare il rispetto dei blocchi: usa tool online per controllare robots.txt, rivedi i log per user-agent bloccati, incrocia gli IP con quelli pubblicati dagli operatori e conferma che il traffico provenga da fonti legittime. Passi pratici: analisi settimanale dei log per monitorare i crawler, alert per attività anomala, revisione mensile della dashboard analytics per trend bot e review trimestrale delle policy per mantenerle allineate ai tuoi obiettivi. Il monitoraggio regolare aiuta a individuare nuovi crawler, violazioni delle policy e prendere decisioni data-driven su chi bloccare o consentire.
Il panorama dei crawler AI continua a evolversi rapidamente, con nuovi player e crawler più sofisticati che ampliano le proprie capacità in modo inatteso. Crawler emergenti da aziende come xAI (Grok), Mistral e DeepSeek stanno iniziando a raccogliere dati su larga scala, e ogni nuova startup AI probabilmente lancerà il proprio crawler per supportare training e funzionalità. I browser agentici rappresentano la nuova frontiera, con sistemi come ChatGPT Operator e Comet che possono interagire con i siti come farebbe un utente umano, cliccando, compilando form e navigando interfacce complesse; questi agenti sono difficili da identificare e bloccare con i metodi tradizionali. Il problema dei browser-based agent è che spesso non si dichiarano chiaramente nell’user-agent e possono aggirare i blocchi IP usando proxy residenziali o infrastrutture distribuite. Nuovi crawler appaiono regolarmente, spesso senza preavviso, quindi è essenziale restare aggiornati sugli sviluppi AI e adeguare le policy. La tendenza indica che il traffico dei crawler continuerà a crescere: Cloudflare segnala un aumento del 18% del traffico crawler tra maggio 2024 e maggio 2025, e la crescita accelererà con la diffusione delle applicazioni AI. I proprietari di siti e i publisher devono restare vigili e adattabili, revisionando periodicamente le policy e monitorando i nuovi sviluppi per assicurare strategie efficaci in uno scenario in continua evoluzione.
Oltre a gestire l’accesso dei crawler al tuo sito, è altrettanto fondamentale capire come i tuoi contenuti vengono utilizzati e citati nelle risposte generate dalle AI. AmICited.com è una piattaforma specializzata pensata per risolvere proprio questo problema: traccia come i crawler AI raccolgono i tuoi contenuti e monitora se il tuo brand e i tuoi materiali vengono citati correttamente nelle applicazioni AI. La piattaforma ti aiuta a capire quali sistemi AI usano i tuoi contenuti, quanto spesso le tue informazioni compaiono nelle risposte AI e se viene fornita la dovuta attribuzione alle fonti originali. Per publisher e creatori, AmICited.com offre insight preziosi sulla tua visibilità nell’ecosistema AI, aiutandoti a misurare l’impatto delle tue scelte di blocco o consenso e il valore effettivo che ricevi dalla scoperta AI. Monitorando le citazioni su più piattaforme, puoi prendere decisioni più informate sulle policy crawler, individuare opportunità per aumentare la visibilità nelle risposte AI e assicurarti che la tua proprietà intellettuale sia correttamente attribuita. Se vuoi davvero capire la presenza del tuo brand nel web AI, AmICited.com offre trasparenza e strumenti di monitoraggio essenziali per restare informato e proteggere il valore dei tuoi contenuti in questa nuova era di scoperta guidata dall’AI.
I crawler di training come GPTBot e ClaudeBot raccolgono contenuti per costruire dataset utili allo sviluppo di grandi modelli linguistici, diventando parte della base di conoscenza dell'AI. I crawler di ricerca come OAI-SearchBot e PerplexityBot indicizzano i contenuti per esperienze di ricerca basate su AI e possono inviare traffico di referral ai publisher tramite citazioni.
Dipende dalle priorità del tuo business. Bloccare i crawler di training protegge i tuoi contenuti dall'essere incorporati nei modelli AI. Bloccare i crawler di ricerca può ridurre la tua visibilità su piattaforme di scoperta basate su AI come la ricerca ChatGPT o Perplexity. Molti publisher optano per un blocco selettivo che mira ai crawler di training permettendo invece quelli di ricerca e citazione.
Il metodo di verifica più affidabile è controllare l'IP della richiesta rispetto agli intervalli IP ufficialmente pubblicati dagli operatori del crawler. Grandi aziende come OpenAI, Anthropic e Amazon pubblicano gli indirizzi IP dei loro crawler. Puoi anche utilizzare regole firewall per inserire in whitelist gli IP verificati e bloccare le richieste da fonti non verificate che si spacciano per crawler AI.
Google afferma ufficialmente che bloccare Google-Extended non influisce sul posizionamento nei motori di ricerca né sull'inclusione nei Google AI Overviews. Tuttavia, alcuni webmaster hanno segnalato preoccupazioni, quindi monitora le tue performance di ricerca dopo aver implementato i blocchi. AI Overviews nella Ricerca Google seguono le regole standard di Googlebot, non quelle di Google-Extended.
Nuovi crawler AI emergono regolarmente, quindi rivedi e aggiorna la tua blocklist almeno ogni trimestre. Tieni d'occhio risorse come il progetto ai.robots.txt su GitHub per elenchi mantenuti dalla community. Controlla i log del server mensilmente per identificare nuovi crawler che visitano il tuo sito e che non sono nella tua configurazione attuale.
Sì, robots.txt è una raccomandazione e non è vincolante. I crawler ben comportati delle grandi aziende generalmente rispettano le direttive di robots.txt, ma alcuni crawler le ignorano. Per una protezione più forte, implementa blocchi a livello server tramite .htaccess o regole firewall e verifica i crawler legittimi utilizzando gli intervalli di indirizzi IP pubblicati.
I crawler AI possono generare un carico server e un consumo di banda significativi. Alcuni progetti hanno riportato che bloccare i crawler AI ha ridotto il consumo di banda da 800GB a 200GB al giorno, risparmiando circa 1.500$ al mese. I publisher ad alto traffico possono vedere riduzioni di costo significative grazie a blocchi selettivi.
Controlla i log del server (di solito in /var/log/apache2/access.log su Linux) alla ricerca di user-agent che corrispondono a crawler noti. Utilizza piattaforme di analytics come Google Analytics o Cloudflare Radar per tracciare il traffico bot separatamente. Imposta avvisi per attività insolite dei crawler e fai revisioni trimestrali delle tue policy sui crawler.
Traccia come le piattaforme AI come ChatGPT, Perplexity e Google AI Overviews fanno riferimento ai tuoi contenuti. Ricevi avvisi in tempo reale quando il tuo brand viene menzionato in risposte generate dall'AI.
Comprendi come funzionano i crawler AI come GPTBot e ClaudeBot, le loro differenze rispetto ai crawler di ricerca tradizionali e come ottimizzare il tuo sito pe...

Guida di riferimento completa ai crawler e bot AI. Identifica GPTBot, ClaudeBot, Google-Extended e oltre 20 altri crawler AI con user agent, frequenze di scansi...

Scopri quali crawler AI autorizzare o bloccare nel tuo robots.txt. Guida completa che copre GPTBot, ClaudeBot, PerplexityBot e oltre 25 crawler AI con esempi di...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.