
ClaudeBot spiegato: il crawler di Anthropic e i tuoi contenuti
Scopri come funziona ClaudeBot, in cosa differisce da Claude-Web e Claude-SearchBot, e come gestire i web crawler di Anthropic sul tuo sito web tramite la confi...
9 min di lettura

ClaudeBot è il web crawler di Anthropic utilizzato per raccogliere dati di addestramento per i modelli Claude AI. Esso esplora sistematicamente i siti web pubblicamente accessibili per raccogliere contenuti da utilizzare nell’addestramento dei modelli di apprendimento automatico. I proprietari dei siti possono controllare l’accesso di ClaudeBot tramite la configurazione di robots.txt. Il crawler rispetta le direttive standard di robots.txt, consentendo ai siti di bloccare o permettere le sue visite.
ClaudeBot è il web crawler di Anthropic utilizzato per raccogliere dati di addestramento per i modelli Claude AI. Esso esplora sistematicamente i siti web pubblicamente accessibili per raccogliere contenuti da utilizzare nell'addestramento dei modelli di apprendimento automatico. I proprietari dei siti possono controllare l'accesso di ClaudeBot tramite la configurazione di robots.txt. Il crawler rispetta le direttive standard di robots.txt, consentendo ai siti di bloccare o permettere le sue visite.
ClaudeBot è un web crawler gestito da Anthropic per scaricare dati di addestramento per i suoi large language models (LLM) che alimentano prodotti AI come Claude. Questo AI data scraper esplora sistematicamente i siti web per raccogliere contenuti specificamente destinati all’addestramento dei modelli di apprendimento automatico, distinguendosi dai crawler tradizionali dei motori di ricerca che indicizzano i contenuti a fini di recupero. ClaudeBot può essere identificato tramite la sua stringa user agent e può essere bloccato o autorizzato tramite la configurazione di robots.txt, offrendo ai proprietari dei siti il controllo sull’utilizzo dei loro contenuti per l’addestramento dei modelli AI di Anthropic.

ClaudeBot opera tramite metodi sistematici di scoperta web, tra cui il follow dei link da siti già indicizzati, l’elaborazione delle sitemap e l’utilizzo di seed URL da elenchi pubblicamente disponibili di siti web. Il crawler scarica i contenuti dei siti per includerli nei dataset utilizzati per addestrare i modelli linguistici di Claude, raccogliendo dati da pagine accessibili pubblicamente senza richiedere autenticazione. Diversamente dai crawler dei motori di ricerca che danno priorità all’indicizzazione per il recupero, i pattern di crawling di ClaudeBot sono tipicamente opachi, con Anthropic che raramente divulga criteri specifici di selezione dei siti, frequenza di crawling o priorità per i diversi tipi di contenuto.
La tabella seguente confronta ClaudeBot con altri crawler di Anthropic:
| Nome Bot | Scopo | User Agent | Ambito |
|---|---|---|---|
| ClaudeBot | Recupero citazioni chat e dati training | ClaudeBot/1.0 | Crawling web generale per l’addestramento modelli |
| anthropic-ai | Raccolta dati training su larga scala | anthropic-ai | Compilazione di dataset di training su larga scala |
| Claude-Web | Crawling web per funzionalità di Claude | Claude-Web | Ricerca web e informazioni in tempo reale |
ClaudeBot opera in modo simile ad altri principali crawler di addestramento AI come GPTBot (OpenAI) e PerplexityBot (Perplexity), ma con differenze sostanziali in ambito e metodologia. Mentre GPTBot si concentra sulle esigenze di addestramento di OpenAI e PerplexityBot serve sia la ricerca che l’addestramento, ClaudeBot punta specificamente a raccogliere contenuti per l’addestramento dei modelli Claude. Secondo i dati di Dark Visitors, circa il 18% dei 1.000 siti web più visitati al mondo blocca attivamente ClaudeBot, segnalando una significativa preoccupazione da parte degli editori sulle sue pratiche di raccolta dati. La distinzione chiave risiede in come ogni azienda dà priorità alla raccolta dei contenuti: l’approccio di Anthropic enfatizza un crawling sistematico e di ampia portata per i dati di training, mentre i crawler focalizzati sulla ricerca bilanciano l’indicizzazione con la generazione di traffico referenziato.
I proprietari dei siti possono identificare le visite di ClaudeBot monitorando i log del server per la particolare stringa user agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com). ClaudeBot proviene tipicamente da range IP statunitensi e le visite possono essere tracciate tramite analisi dei log del server o strumenti di monitoraggio dedicati. Configurare piattaforme di agent analytics consente una visibilità in tempo reale sulle visite di ClaudeBot, permettendo di misurare la frequenza e i pattern di crawling.
Ecco un esempio di come appare ClaudeBot nei log del server:
203.0.113.45 - - [03/Jan/2025:09:15:32 +0000] "GET /blog/article-title HTTP/1.1" 200 5432 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
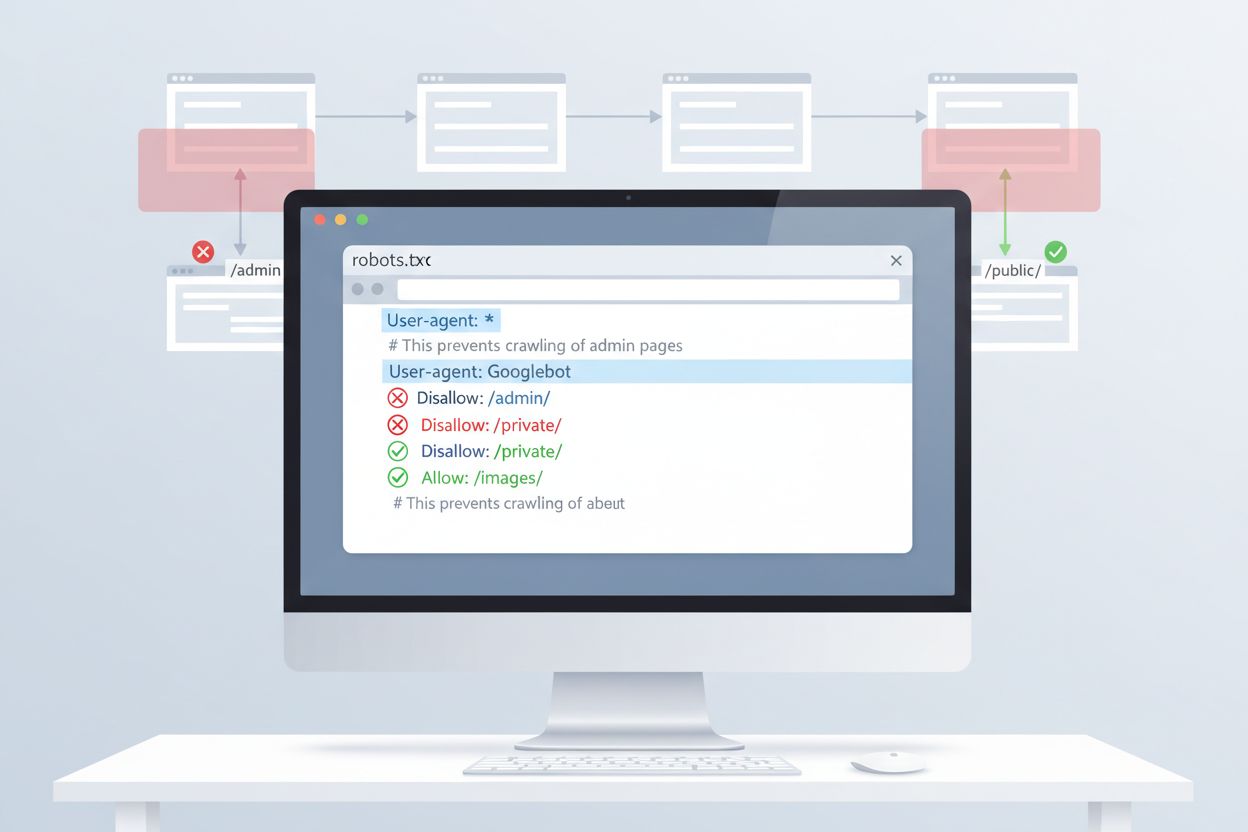
Il metodo più semplice per controllare l’accesso di ClaudeBot è tramite la configurazione di robots.txt nella directory principale del tuo sito. Questo file indica ai crawler quali parti del sito possono essere visitate, e il ClaudeBot di Anthropic rispetta tali direttive. Per bloccare tutta l’attività di ClaudeBot, aggiungi queste regole al tuo file robots.txt:
User-agent: ClaudeBot
Disallow: /
Per un blocco più selettivo che impedisca a ClaudeBot di accedere solo a determinate directory consentendo la scansione di altri contenuti, utilizza:
User-agent: ClaudeBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
Se desideri bloccare tutti i crawler di Anthropic (inclusi anthropic-ai e Claude-Web), aggiungi regole separate per ciascuno:
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
Sebbene robots.txt fornisca la prima linea di difesa, opera su base volontaria. Per gli editori che richiedono una protezione più forte, esistono diversi metodi aggiuntivi di blocco:
Questi metodi richiedono competenze tecniche superiori rispetto alla configurazione di robots.txt ma offrono una protezione più efficace contro crawler non conformi.
Bloccare ClaudeBot ha un impatto diretto minimo sulle classifiche SEO tradizionali poiché i crawler di training non contribuiscono all’indicizzazione per i motori di ricerca—Google, Bing e altri motori utilizzano crawler separati (Googlebot, Bingbot) che operano indipendentemente. Tuttavia, bloccare ClaudeBot potrebbe ridurre la rappresentazione dei tuoi contenuti nelle risposte AI generate da Claude, influenzando potenzialmente la futura visibilità tramite ricerca AI e interfacce chat. La decisione strategica di bloccare o consentire ClaudeBot dipende dal tuo modello di monetizzazione dei contenuti: se i tuoi ricavi dipendono dal traffico diretto al sito e dalle impressioni pubblicitarie, il blocco previene che i tuoi contenuti vengano assorbiti nei dataset di training che potrebbero ridurre il numero di visitatori. Al contrario, consentire ClaudeBot può aumentare la tua visibilità nelle risposte di Claude, potenzialmente generando traffico referenziato dagli utenti chat AI.
Una gestione efficace di ClaudeBot richiede monitoraggio continuo e verifica della configurazione. Usa strumenti come il tester robots.txt di Google Search Console, lo strumento di test robots.txt di Merkle o piattaforme specializzate come Dark Visitors per verificare che le tue regole di blocco funzionino correttamente. Rivedi regolarmente i log del server per confermare che ClaudeBot rispetti le tue direttive robots.txt e monitora eventuali cambiamenti nei pattern di crawling. Poiché il panorama dei crawler AI evolve rapidamente con la scoperta continua di nuovi bot, una revisione trimestrale della configurazione robots.txt ti assicura di fronteggiare i nuovi crawler e mantenere la tua strategia di protezione dei contenuti aggiornata. Testare la configurazione prima della messa in produzione previene il blocco accidentale di motori di ricerca legittimi o altri crawler importanti.
ClaudeBot è il web crawler di Anthropic che visita sistematicamente i siti web per raccogliere dati di addestramento per i modelli AI Claude. Scopre il tuo sito seguendo i link, processando le sitemap o tramite elenchi di siti pubblici. Il crawler raccoglie contenuti pubblicamente accessibili per migliorare le capacità del modello linguistico di Claude.
Puoi bloccare ClaudeBot aggiungendo una regola robots.txt nella directory principale del tuo sito. Basta aggiungere 'User-agent: ClaudeBot' seguito da 'Disallow: /' per impedire ogni accesso, oppure specificare determinati percorsi da bloccare selettivamente. ClaudeBot di Anthropic rispetta le direttive robots.txt.
No, bloccare ClaudeBot non inciderà sul tuo posizionamento su Google o Bing. I crawler di addestramento come ClaudeBot operano indipendentemente dai motori di ricerca tradizionali. Solo il blocco di Googlebot o Bingbot influirebbe sulle tue prestazioni SEO.
Anthropic gestisce tre principali crawler: ClaudeBot (recupero citazioni chat e dati di addestramento generali), anthropic-ai (raccolta dati di addestramento su larga scala) e Claude-Web (crawling web focalizzato su funzionalità in tempo reale). Ognuno svolge ruoli diversi nell'infrastruttura AI di Anthropic.
Controlla i log del tuo server per la stringa user agent di ClaudeBot: 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)'. Puoi anche utilizzare strumenti di monitoraggio come Dark Visitors o configurare analytics degli agenti per tracciare in tempo reale le visite di ClaudeBot.
Sì, ClaudeBot rispetta le direttive robots.txt secondo la documentazione ufficiale di Anthropic. Tuttavia, come per tutte le regole robots.txt, l'adesione è volontaria. Per una protezione più forte, puoi implementare blocchi a livello di server, filtraggio IP o regole WAF.
ClaudeBot può consumare una larghezza di banda significativa a seconda delle dimensioni e del volume di contenuti del tuo sito. Gli scraper AI possono effettuare crawling più aggressivi rispetto ai motori di ricerca tradizionali. Monitorare i log del server ti aiuta a capire l'impatto e decidere se bloccare o consentire il crawler.
La decisione dipende dal tuo modello di business. Blocca ClaudeBot se sei preoccupato per l'attribuzione dei contenuti, la compensazione o su come il tuo lavoro potrebbe essere utilizzato nei sistemi AI. Consentilo se vuoi che i tuoi contenuti appaiano nelle risposte di Claude e nei risultati di ricerca AI. Considera la tua strategia di monetizzazione del traffico quando decidi.
Traccia ClaudeBot e altri crawler AI che accedono ai tuoi contenuti. Ottieni informazioni su quali sistemi AI citano il tuo brand e su come i tuoi contenuti vengono utilizzati nelle risposte generate dall'AI.
Scopri come funziona ClaudeBot, in cosa differisce da Claude-Web e Claude-SearchBot, e come gestire i web crawler di Anthropic sul tuo sito web tramite la confi...
Claude è l’avanzato assistente AI di Anthropic alimentato da AI Costituzionale. Scopri come funziona Claude, le sue caratteristiche chiave, i meccanismi di sicu...

Scopri cos’è CCBot, come funziona e come bloccarlo. Comprendi il suo ruolo nell’addestramento IA, gli strumenti di monitoraggio e le best practice per protegger...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.