
Welke AI-crawlers moet ik toegang geven? Complete gids voor 2025
Ontdek welke AI-crawlers je moet toestaan of blokkeren in je robots.txt. Uitgebreide gids over GPTBot, ClaudeBot, PerplexityBot en 25+ AI-crawlers met configura...
10 min lezen

Leer hoe je noai- en noimageai-meta tags implementeert om AI-crawler-toegang tot je website-inhoud te beheren. Complete gids voor AI-toegangscontroleheaders en implementatiemethoden.
Webcrawlers zijn geautomatiseerde programma’s die systematisch het internet doorzoeken en informatie van websites verzamelen. Historisch gezien werden deze bots vooral gebruikt door zoekmachines zoals Google, waarvan Googlebot pagina’s crawlde, inhoud indexeerde en gebruikers via zoekresultaten terugstuurde naar websites—wat een wederzijds voordelige relatie opleverde. De opkomst van AI-crawlers heeft deze dynamiek echter fundamenteel veranderd. In tegenstelling tot traditionele zoekmachinebots die verkeer teruggeven in ruil voor toegang tot content, consumeren AI-trainingscrawlers enorme hoeveelheden webinhoud om datasets te bouwen voor grote taalmodellen, waarbij ze vaak weinig tot geen verkeer teruggeven aan uitgevers. Deze verschuiving heeft meta tags—kleine HTML-instructies die aan crawlers doorgeven wat ze wel en niet mogen doen—steeds belangrijker gemaakt voor makers die controle willen houden over hoe hun werk door kunstmatige intelligentie gebruikt wordt.
De noai- en noimageai-meta tags zijn in 2022 door DeviantArt ontwikkeld om makers te helpen voorkomen dat hun werk wordt gebruikt voor het trainen van AI-beeldgeneratoren. Deze tags werken op een vergelijkbare manier als de bekende noindex-richtlijn, die zoekmachines vertelt een pagina niet te indexeren. De noai-richtlijn geeft aan dat geen enkel deel van de pagina gebruikt mag worden voor AI-training, terwijl noimageai specifiek voorkomt dat afbeeldingen gebruikt worden voor AI-modeltraining. Je kunt deze tags in de head-sectie van je HTML opnemen met de volgende syntax:
<!-- Blokkeer alle content voor AI-training -->
<meta name="robots" content="noai">
<!-- Blokkeer alleen afbeeldingen voor AI-training -->
<meta name="robots" content="noimageai">
<!-- Blokkeer zowel content als afbeeldingen -->
<meta name="robots" content="noai, noimageai">
Hier is een vergelijkende tabel van verschillende meta tag-richtlijnen en hun doelen:
| Richtlijn | Doel | Syntax | Bereik |
|---|---|---|---|
| noai | Voorkomt gebruik van alle content voor AI-training | content="noai" | Hele paginainhoud |
| noimageai | Voorkomt gebruik van afbeeldingen voor AI-training | content="noimageai" | Alleen afbeeldingen |
| noindex | Voorkomt indexering door zoekmachines | content="noindex" | Zoekresultaten |
| nofollow | Voorkomt dat links gevolgd worden | content="nofollow" | Uitgaande links |
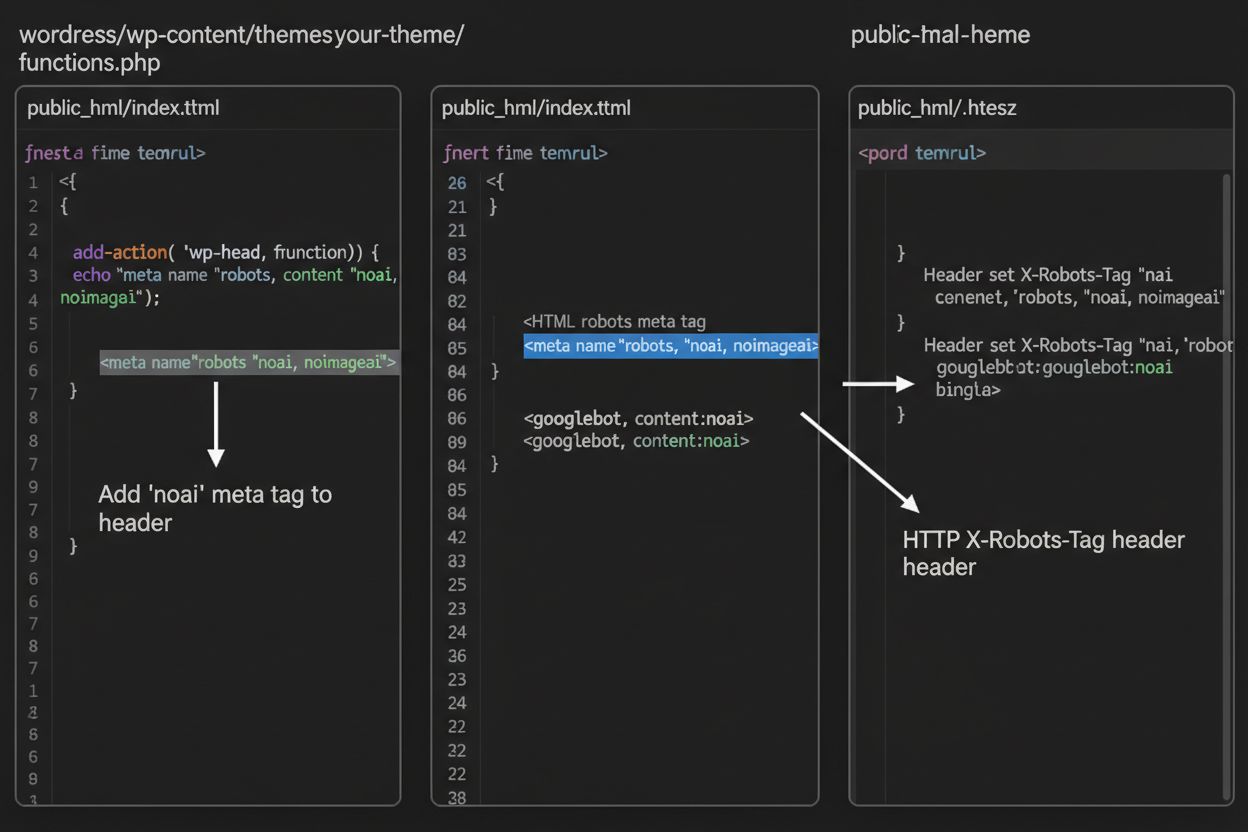
Terwijl meta tags direct in je HTML staan, bieden HTTP-headers een alternatieve methode om crawlerinstructies op serverniveau door te geven. De X-Robots-Tag-header kan dezelfde instructies bevatten als meta tags, maar werkt anders: hij wordt meegestuurd in het HTTP-antwoord voordat de pagina wordt geladen. Deze aanpak is vooral waardevol voor het beheren van toegang tot niet-HTML-bestanden zoals PDF’s, afbeeldingen en video’s, waar je geen HTML-meta tags kunt opnemen.
Voor Apache-servers kun je X-Robots-Tag-headers instellen in je .htaccess-bestand:
<IfModule mod_headers.c>
Header set X-Robots-Tag "noai, noimageai"
</IfModule>
Voor NGINX-servers voeg je de header toe in je serverconfiguratie:
location / {
add_header X-Robots-Tag "noai, noimageai";
}
Headers bieden globale bescherming voor je hele site of specifieke mappen, waardoor ze ideaal zijn voor een allesomvattende AI-toegangscontrole.
De effectiviteit van noai- en noimageai-tags hangt volledig af van de bereidheid van crawlers om ze te respecteren. Goed functionerende crawlers van grote AI-bedrijven houden zich doorgaans aan deze richtlijnen:
Slecht functionerende bots en kwaadaardige crawlers kunnen deze richtlijnen echter bewust negeren, omdat er geen handhavingsmechanisme is. In tegenstelling tot robots.txt, dat als industriestandaard door zoekmachines wordt gerespecteerd, is noai geen officiële webstandaard en zijn crawlers niet verplicht zich eraan te houden. Daarom raden beveiligingsexperts een gelaagde aanpak aan waarin je meerdere beschermingsmethoden combineert en niet alleen op meta tags vertrouwt.
Het implementeren van noai- en noimageai-tags verschilt per websiteplatform. Hier zijn stapsgewijze instructies voor de meest voorkomende platforms:
1. WordPress (via functions.php) Voeg deze code toe aan het functions.php-bestand van je child theme:
function add_noai_meta_tag() {
echo '<meta name="robots" content="noai, noimageai">' . "\n";
}
add_action('wp_head', 'add_noai_meta_tag');
2. Statische HTML-sites
Voeg direct toe aan de <head>-sectie van je HTML:
<head>
<meta name="robots" content="noai, noimageai">
</head>
3. Squarespace Navigeer naar Instellingen > Geavanceerd > Code-injectie en voeg toe aan de Header-sectie:
<meta name="robots" content="noai, noimageai">
4. Wix Ga naar Instellingen > Aangepaste code, klik op “Aangepaste code toevoegen”, plak de meta tag, selecteer “Head” en pas toe op alle pagina’s.
Elk platform biedt verschillende niveaus van controle—WordPress maakt pagina-specifieke implementatie via plugins mogelijk, terwijl Squarespace en Wix wereldwijde site-opties bieden. Kies de methode die past bij je technische vaardigheden en specifieke wensen.
Hoewel noai- en noimageai-tags een belangrijke stap zijn voor de bescherming van makers, kennen ze duidelijke beperkingen. Ten eerste zijn dit geen officiële webstandaarden—DeviantArt heeft ze als community-initiatief ontwikkeld, wat betekent dat er geen formele specificatie of handhaving is. Ten tweede is naleving volledig vrijwillig. Goed functionerende crawlers van grote bedrijven respecteren deze richtlijnen, maar slecht functionerende bots en scrapers kunnen ze zonder gevolgen negeren. Ten derde varieert het gebruik door gebrek aan standaardisatie. Sommige kleinere AI-bedrijven en onderzoeksinstellingen zijn wellicht niet eens op de hoogte van deze richtlijnen, laat staan dat ze ze ondersteunen. Tot slot kunnen meta tags alleen vastberaden kwaadwillenden niet tegenhouden. Een kwaadaardige crawler kan je instructies compleet negeren, waardoor extra beschermingslagen essentieel zijn voor volledige contentbeveiliging.
De meest effectieve AI-toegangsstrategie gebruikt meerdere beschermingslagen en vertrouwt niet op één enkele methode. Hier volgt een vergelijking van verschillende beschermingsaanpakken:
| Methode | Bereik | Effectiviteit | Moeilijkheid |
|---|---|---|---|
| Meta tags (noai) | Pagina-niveau | Middel (vrijwillige naleving) | Makkelijk |
| robots.txt | Site-breed | Middel (adviesfunctie) | Makkelijk |
| X-Robots-Tag headers | Serverniveau | Middel-hoog (voor alle types) | Gemiddeld |
| Firewallregels | Netwerkniveau | Hoog (blokkering infrastructuur) | Moeilijk |
| IP-allowlisting | Netwerkniveau | Zeer hoog (alleen geverifieerde bronnen) | Moeilijk |
Een uitgebreide strategie kan bestaan uit: (1) noai-meta tags op alle pagina’s, (2) robots.txt-regels die bekende AI-trainingscrawlers blokkeren, (3) X-Robots-Tag-headers op serverniveau voor niet-HTML-bestanden, en (4) serverlogs monitoren om crawlers te identificeren die je richtlijnen negeren. Deze gelaagde aanpak maakt het kwaadwillenden een stuk moeilijker, terwijl goed functionerende crawlers je voorkeuren blijven respecteren.
Na het implementeren van noai-tags en andere richtlijnen moet je controleren of crawlers je regels daadwerkelijk respecteren. De meest directe methode is het controleren van je server-toegangslogs op crawleractiviteit. Op Apache-servers kun je zoeken naar specifieke crawlers:
grep "GPTBot\|ClaudeBot\|PerplexityBot" /var/log/apache2/access.log
Als je aanvragen ziet van crawlers die je hebt geblokkeerd, negeren ze je richtlijnen. Voor NGINX-servers controleer je /var/log/nginx/access.log met hetzelfde grep-commando. Daarnaast bieden tools zoals Cloudflare Radar inzicht in AI-crawlerverkeer op je site, zodat je kunt zien welke bots het meest actief zijn en hoe hun gedrag zich ontwikkelt. Door minstens maandelijks je logs te controleren, kun je nieuwe crawlers identificeren en nagaan of je beschermingsmaatregelen werken zoals bedoeld.
Op dit moment bestaan noai en noimageai in een grijs gebied: ze worden breed erkend en door grote AI-bedrijven gerespecteerd, maar blijven onofficieel en niet-gestandaardiseerd. Er is echter een groeiende beweging richting formele standaardisatie. De W3C (World Wide Web Consortium) en diverse branchegroepen bespreken manieren om officiële standaarden voor AI-toegangsbeheer te creëren, waardoor deze richtlijnen net zo zwaar zouden wegen als bestaande standaarden zoals robots.txt. Als noai een officiële webstandaard wordt, zal naleving de industriële norm worden in plaats van vrijwillig, waardoor de effectiviteit aanzienlijk toeneemt. Deze standaardisatie weerspiegelt een bredere verschuiving in hoe de techindustrie kijkt naar rechten van contentmakers en de balans tussen AI-ontwikkeling en bescherming van uitgevers. Naarmate meer uitgevers deze tags adopteren en om sterkere bescherming vragen, neemt de kans op een officiële standaard toe, waardoor AI-toegangsbeheer net zo fundamenteel wordt voor het web als zoekmachine-indexering.
De noai-meta tag is een instructie die je in de head-sectie van je website-HTML plaatst en die aangeeft aan AI-crawlers dat je inhoud niet gebruikt mag worden voor het trainen van kunstmatige intelligentie-modellen. Het werkt door je voorkeur kenbaar te maken aan goed functionerende AI-bots, hoewel het geen officiële webstandaard is en sommige crawlers het kunnen negeren.
Nee, noai en noimageai zijn geen officiële webstandaarden. Ze zijn gemaakt door DeviantArt als een community-initiatief om makers te helpen hun werk te beschermen tegen AI-training. Grote AI-bedrijven zoals OpenAI, Anthropic en anderen zijn deze richtlijnen echter wel gaan respecteren in hun crawlers.
Belangrijke AI-crawlers, waaronder GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) en anderen respecteren de noai-richtlijn. Sommige kleinere of minder goed functionerende crawlers kunnen deze echter negeren. Daarom wordt een gelaagde beschermingsaanpak aanbevolen.
Meta tags worden in de head-sectie van je HTML geplaatst en zijn van toepassing op afzonderlijke pagina's, terwijl HTTP-headers (X-Robots-Tag) op serverniveau worden ingesteld en globaal of voor specifieke bestandstypen kunnen gelden. Headers werken ook voor niet-HTML-bestanden zoals PDF's en afbeeldingen, waardoor ze veelzijdiger zijn voor algehele bescherming.
Ja, je kunt noai-tags op WordPress implementeren via verschillende methoden: door code toe te voegen aan het functions.php-bestand van je thema, via een plugin zoals WPCode, of via paginabouwers zoals Divi en Elementor. De functions.php-methode is het meest gebruikelijk en houdt in dat je een eenvoudige hook toevoegt om de meta tag in de header van je site te plaatsen.
Dit hangt af van je bedrijfsdoelen. Door trainingscrawlers te blokkeren bescherm je je inhoud tegen gebruik bij de ontwikkeling van AI-modellen. Het blokkeren van zoekcrawlers zoals OAI-SearchBot kan echter je zichtbaarheid in AI-gestuurde zoekresultaten en ontdekkingsplatforms verminderen. Veel uitgevers kiezen voor een selectieve aanpak waarbij trainingscrawlers worden geblokkeerd en zoekcrawlers worden toegelaten.
Je kunt je serverlogs controleren op crawleractiviteit met commando's zoals grep om te zoeken naar specifieke bot user agents. Tools zoals Cloudflare Radar bieden inzicht in AI-crawlerverkeer. Controleer je logs regelmatig om te zien of geblokkeerde crawlers toch je content benaderen, wat erop wijst dat ze je richtlijnen negeren.
Als crawlers je meta tags negeren, implementeer dan extra beschermingslagen zoals robots.txt-regels, X-Robots-Tag HTTP-headers en serverniveau-blokkering via .htaccess of firewallregels. Voor sterkere verificatie kun je IP-allowlisting toepassen, zodat alleen verzoeken van geverifieerde crawler-IP-adressen van grote AI-bedrijven worden toegestaan.
Gebruik AmICited om te volgen hoe AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews jouw inhoud citeren en vermelden op verschillende AI-platforms.
Ontdek welke AI-crawlers je moet toestaan of blokkeren in je robots.txt. Uitgebreide gids over GPTBot, ClaudeBot, PerplexityBot en 25+ AI-crawlers met configura...

Compleet naslagwerk over AI crawlers en bots. Identificeer GPTBot, ClaudeBot, Google-Extended en meer dan 20 andere AI-crawlers met user agents, crawl rates en ...
Leer hoe je AI-crawlers zoals GPTBot, PerplexityBot en ClaudeBot kunt identificeren en monitoren in je serverlogs. Ontdek user-agent strings, IP-verificatiemeth...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.