
Moet je AI-crawlers blokkeren of toestaan? Besliskader
Ontdek hoe je strategische beslissingen neemt over het blokkeren van AI-crawlers. Evalueer inhoudstype, verkeersbronnen, verdienmodellen en concurrentiepositie ...
11 min lezen

De strategische praktijk van het selectief toestaan of blokkeren van AI-crawlers om te bepalen hoe content wordt gebruikt voor training versus realtime-opvraging. Dit omvat het gebruik van robots.txt-bestanden, serverniveaucontroles en monitoringtools om te beheren welke AI-systemen toegang hebben tot je content en voor welke doeleinden.
De strategische praktijk van het selectief toestaan of blokkeren van AI-crawlers om te bepalen hoe content wordt gebruikt voor training versus realtime-opvraging. Dit omvat het gebruik van robots.txt-bestanden, serverniveaucontroles en monitoringtools om te beheren welke AI-systemen toegang hebben tot je content en voor welke doeleinden.
AI-crawlerbeheer verwijst naar de praktijk van het controleren en monitoren van hoe kunstmatige intelligentiesystemen toegang krijgen tot en gebruikmaken van websitecontent voor trainings- en zoekdoeleinden. In tegenstelling tot traditionele zoekmachinecrawlers die content indexeren voor webzoekresultaten, zijn AI-crawlers specifiek ontworpen om data te verzamelen voor het trainen van grote taalmodellen of het aandrijven van AI-zoekfuncties. De schaal van deze activiteit verschilt sterk per organisatie—de crawlers van OpenAI werken met een crawl-to-refer-verhouding van 1.700:1, wat betekent dat ze 1.700 keer content benaderen voor elke verwijzing die ze geven, terwijl Anthropic een verhouding van 73.000:1 bereikt, wat de enorme dataconsumptie voor het trainen van moderne AI-systemen benadrukt. Effectief crawlerbeheer stelt website-eigenaren in staat te bepalen of hun content bijdraagt aan AI-training, verschijnt in AI-zoekresultaten of beschermd blijft tegen geautomatiseerde toegang.
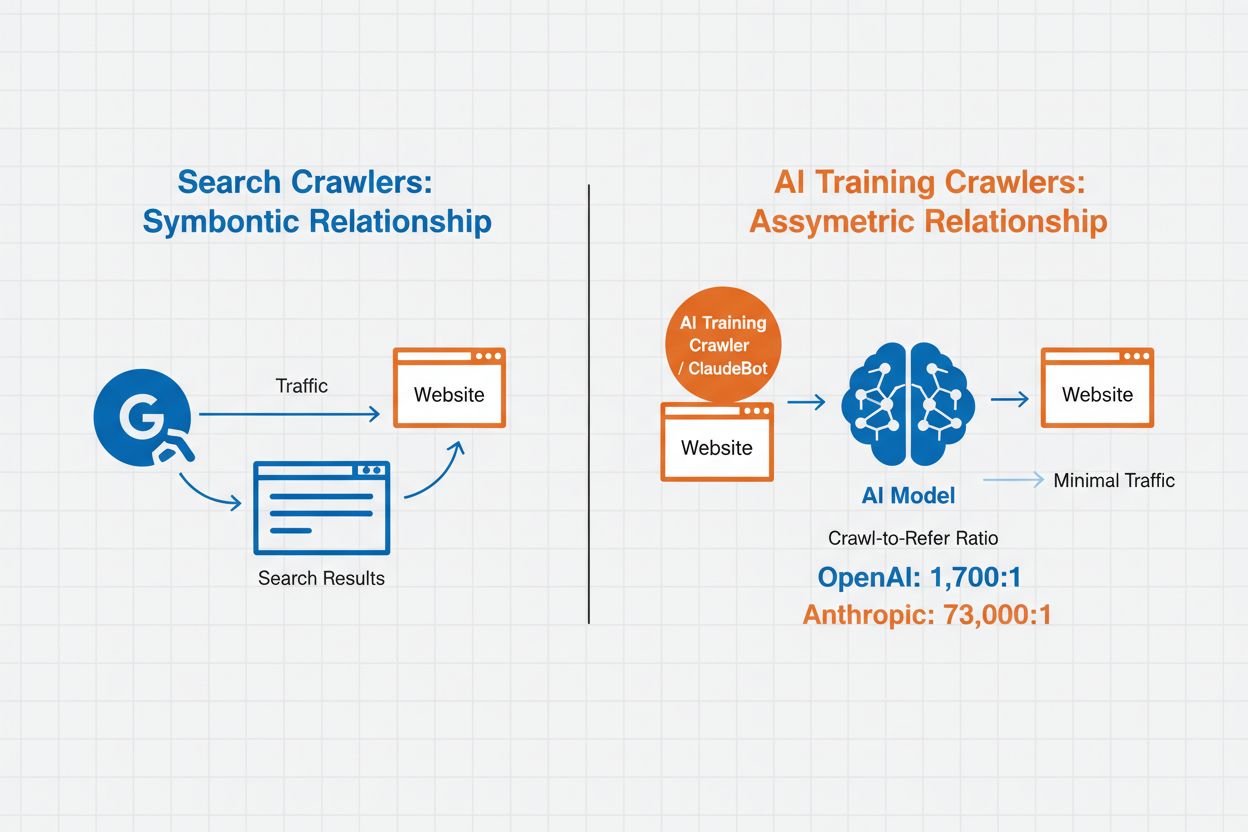
AI-crawlers vallen uiteen in drie verschillende categorieën op basis van hun doel en datagebruikspatronen. Trainingscrawlers zijn ontworpen om data te verzamelen voor het ontwikkelen van machine learning-modellen en gebruiken grote hoeveelheden content om AI-capaciteiten te verbeteren. Zoek- en citatiecrawlers indexeren content om AI-gedreven zoekfuncties mogelijk te maken en zorgen voor bronvermelding in AI-gegenereerde antwoorden, zodat gebruikers je content via AI-interfaces kunnen ontdekken. Gebruiker-geactiveerde crawlers werken op aanvraag wanneer gebruikers AI-tools gebruiken, bijvoorbeeld wanneer een ChatGPT-gebruiker een document uploadt of analyse van een specifieke webpagina aanvraagt. Door deze categorieën te begrijpen kun je weloverwogen beslissingen nemen over welke crawlers je toelaat of blokkeert op basis van je contentstrategie en bedrijfsdoelen.
| Crawertype | Doel | Voorbeelden | Gebruikt voor training |
|---|---|---|---|
| Training | Modelontwikkeling en verbetering | GPTBot, ClaudeBot | Ja |
| Zoek/Citatie | AI-zoekresultaten en bronvermelding | Google-Extended, OAI-SearchBot, PerplexityBot | Variabel |
| Gebruiker-geactiveerd | On-demand contentanalyse | ChatGPT-User, Meta-ExternalAgent, Amazonbot | Contextspecifiek |
AI-crawlerbeheer heeft direct invloed op het verkeer, de omzet en de waarde van je content. Wanneer crawlers je content zonder vergoeding gebruiken, loop je de kans mis om te profiteren van dat verkeer via verwijzingen, advertentie-impressies of gebruikersinteractie. Websites rapporteren aanzienlijke dalingen in verkeer doordat gebruikers rechtstreeks antwoord krijgen via AI-gegenereerde resultaten in plaats van door te klikken naar de oorspronkelijke bron, waardoor je verwijzingsverkeer en bijbehorende advertentie-inkomsten verdwijnen. Naast financiële gevolgen zijn er ook belangrijke juridische en ethische overwegingen—je content is intellectueel eigendom en je hebt het recht te bepalen hoe die wordt gebruikt en of je erkenning of compensatie ontvangt. Daarnaast kan onbeperkte toegang tot crawlers zorgen voor hogere serverbelasting en bandbreedtekosten, vooral door crawlers met agressieve crawl-snelheden die geen rekening houden met rate-limiting.
Het robots.txt-bestand is het basisinstrument voor het beheren van crawlertoegang, geplaatst in de hoofdmap van je website om voorkeuren door te geven aan geautomatiseerde agents. Dit bestand gebruikt User-agent-richtlijnen om specifieke crawlers te targeten en Disallow- of Allow-regels om toegang tot bepaalde paden en bronnen te beperken of toe te staan. Robots.txt kent echter belangrijke beperkingen—het is een vrijwillige standaard die afhankelijk is van medewerking door crawlers, en kwaadaardige of slecht ontworpen bots kunnen het volledig negeren. Bovendien voorkomt robots.txt niet dat crawlers toegang krijgen tot publiek beschikbare content; het vraagt alleen je voorkeuren te respecteren. Daarom moet robots.txt deel uitmaken van een gelaagde aanpak van crawlerbeheer en niet je enige verdedigingslinie zijn.
# Blokkeer AI-trainingscrawlers
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# Sta zoekmachines toe
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Standaardregel voor andere crawlers
User-agent: *
Allow: /
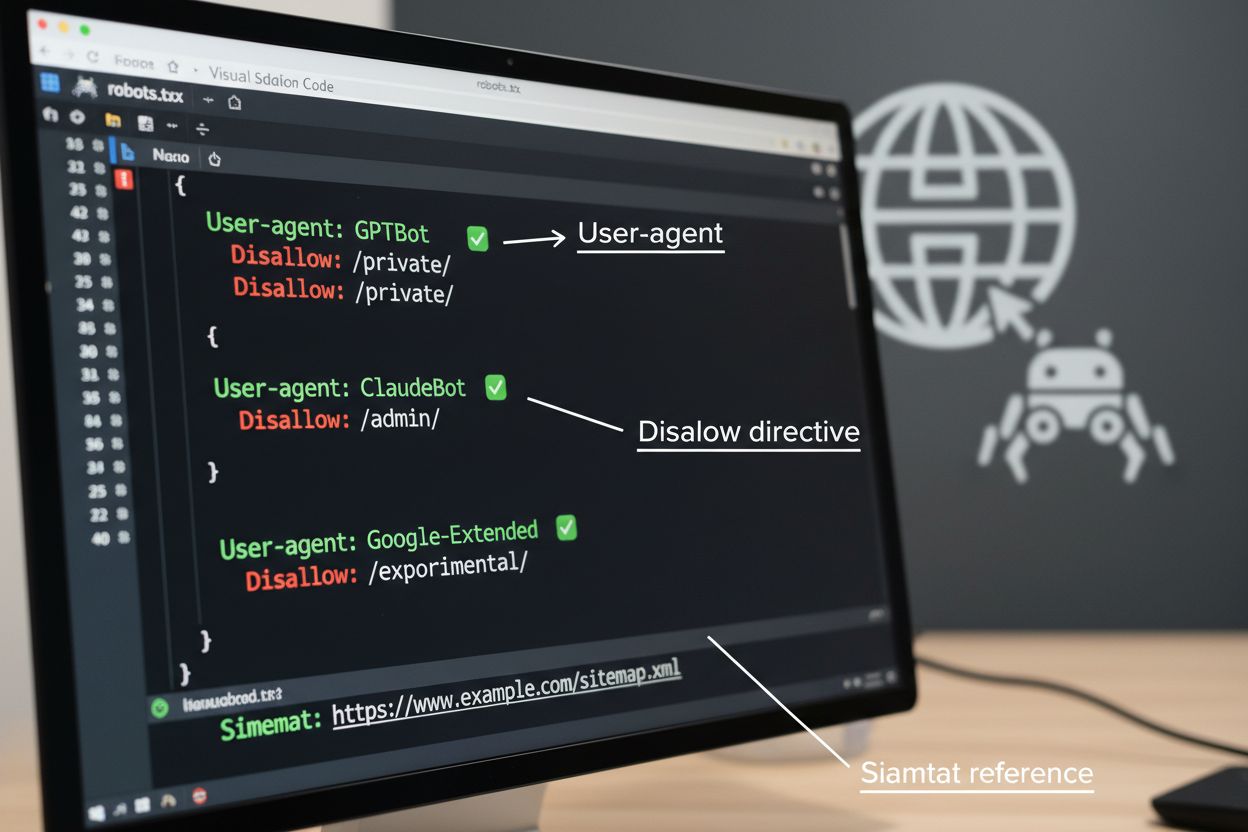
Naast robots.txt zijn er verschillende geavanceerde technieken die sterkere handhaving en meer gedetailleerde controle over crawlertoegang bieden. Deze methoden werken op verschillende lagen van je infrastructuur en kunnen worden gecombineerd voor totale bescherming:
De keuze om AI-crawlers te blokkeren betekent een belangrijke afweging tussen contentbescherming en vindbaarheid. Door alle AI-crawlers te blokkeren voorkom je dat je content verschijnt in AI-zoekresultaten, AI-samenvattingen of wordt geciteerd door AI-tools—je zichtbaarheid bij gebruikers die content via deze nieuwe kanalen ontdekken, kan afnemen. Onbeperkte toegang toestaan betekent echter dat je content AI-training voedt zonder compensatie en dat verwijzingsverkeer mogelijk afneemt doordat gebruikers direct door AI worden bediend. Een strategische aanpak is selectief blokkeren: crawlers toestaan die citaties en verwijzingsverkeer opleveren, zoals OAI-SearchBot en PerplexityBot, en trainingscrawlers blokkeren zoals GPTBot en ClaudeBot die data consumeren zonder erkenning. Je kunt er ook voor kiezen Google-Extended toe te staan voor zichtbaarheid in Google AI Overviews, wat veel verkeer kan opleveren, terwijl je trainingscrawlers van concurrenten blokkeert. De optimale strategie hangt af van je contenttype, verdienmodel en doelgroep—nieuwssites en uitgevers kiezen vaak voor blokkeren, terwijl makers van educatieve content mogelijk baat hebben bij bredere AI-zichtbaarheid.
Het instellen van crawlercontroles is alleen effectief als je controleert of crawlers zich daadwerkelijk aan je instructies houden. Serverloganalyse is de belangrijkste methode om crawleractiviteit te monitoren—analyseer je toegangslogs op User-Agent-strings en aanvraagpatronen om te zien welke crawlers je site bezoeken en of ze je robots.txt-regels respecteren. Veel crawlers beweren compliant te zijn maar blijven toch geblokkeerde paden bezoeken, waardoor voortdurende monitoring essentieel is. Tools zoals Cloudflare Radar geven realtime inzicht in verkeerspatronen en kunnen helpen bij het identificeren van verdachte of niet-conforme crawleractiviteit. Stel geautomatiseerde waarschuwingen in voor pogingen tot toegang tot geblokkeerde bronnen en controleer je logs regelmatig om nieuwe crawlers of veranderende patronen te ontdekken die op ontwijkingspogingen kunnen wijzen.
Effectief AI-crawlerbeheer vereist een systematische aanpak die bescherming en strategische zichtbaarheid in balans brengt. Volg deze acht stappen voor een uitgebreide crawlerbeheerstrategie:
AmICited.com biedt een gespecialiseerd platform om te monitoren hoe AI-systemen jouw content vermelden en gebruiken in verschillende modellen en toepassingen. De dienst biedt realtime tracking van je citaties in AI-gegenereerde antwoorden, zodat je inzicht krijgt in welke crawlers het meest actief je content gebruiken en hoe vaak je werk in AI-uitvoer verschijnt. Door crawlerpatronen en citatiegegevens te analyseren stelt AmICited.com je in staat om datagedreven beslissingen te nemen over je crawlerbeheerstrategie—je ziet exact welke crawlers waarde leveren via citaties en verwijzingen versus crawlers die content consumeren zonder erkenning. Deze inzichten transformeren crawlerbeheer van een verdedigende praktijk naar een strategisch middel om de zichtbaarheid en impact van je content op het AI-web te optimaliseren.
Trainingscrawlers zoals GPTBot en ClaudeBot verzamelen content om datasets te bouwen voor de ontwikkeling van grote taalmodellen en gebruiken jouw content zonder verwijzingsverkeer terug te geven. Zoekcrawlers zoals OAI-SearchBot en PerplexityBot indexeren content voor AI-aangedreven zoekresultaten en kunnen bezoekers via citaties terugsturen naar je site. Het blokkeren van trainingscrawlers beschermt je content tegen opname in AI-modellen, terwijl het blokkeren van zoekcrawlers je zichtbaarheid op AI-ontdekkingsplatforms kan verminderen.
Nee. Het blokkeren van AI-trainingscrawlers zoals GPTBot, ClaudeBot en CCBot heeft geen invloed op je zoekresultaten bij Google of Bing. Traditionele zoekmachines gebruiken andere crawlers (Googlebot, Bingbot) die onafhankelijk van AI-trainingsbots werken. Blokkeer alleen traditionele zoekcrawlers als je volledig uit de zoekresultaten wilt verdwijnen, wat je SEO zou schaden.
Onderzoek je servertoegangslogboeken om User-Agent-strings van crawlers te identificeren. Zoek naar vermeldingen met 'bot,' 'crawler,' of 'spider' in het User-Agent-veld. Tools zoals Cloudflare Radar bieden realtime inzicht in welke AI-crawlers je site bezoeken en hun verkeerspatronen. Je kunt ook analysetools gebruiken die botverkeer onderscheiden van menselijke bezoekers.
Ja. robots.txt is een adviserend standaardbestand dat afhankelijk is van medewerking van crawlers—het is niet afdwingbaar. Netjes werkende crawlers van grote bedrijven zoals OpenAI, Anthropic en Google respecteren doorgaans robots.txt, maar sommige crawlers negeren dit volledig. Voor sterkere bescherming kun je blokkades op serverniveau instellen via .htaccess, firewallregels of IP-gebaseerde restricties.
Dit hangt af van je zakelijke prioriteiten. Het blokkeren van alle trainingscrawlers beschermt je content tegen opname in AI-modellen, terwijl je zoekcrawlers mogelijk toestaat die verwijzingsverkeer genereren. Veel uitgevers gebruiken selectieve blokkering die zich richt op trainingscrawlers en zoek- en citatiecrawlers toestaan. Overweeg je contenttype, verkeersbronnen en verdienmodel bij het bepalen van je strategie.
Evalueer en werk je crawlerbeheerbeleid minimaal elk kwartaal bij. Nieuwe AI-crawlers verschijnen regelmatig en bestaande crawlers passen hun user agents aan zonder waarschuwing. Volg bronnen zoals het ai.robots.txt-project op GitHub voor door de community bijgehouden lijsten en controleer je serverlogboeken maandelijks om nieuwe crawlers te identificeren die je site bezoeken.
AI-crawlers kunnen aanzienlijke impact hebben op je verkeer en inkomsten. Wanneer gebruikers rechtstreeks door AI-systemen worden bediend zonder je site te bezoeken, verlies je verwijzingsverkeer en bijbehorende advertentie-impressies. Onderzoek toont crawl-to-refer-verhoudingen tot wel 73.000:1 voor sommige AI-platforms, wat betekent dat ze duizenden keren je content bezoeken voor elke keer dat ze een bezoeker terugsturen. Door trainingscrawlers te blokkeren bescherm je je verkeer, terwijl het toestaan van zoekcrawlers enige verwijzingsvoordelen kan opleveren.
Controleer je serverlogboeken om te zien of geblokkeerde crawlers toch in je toegangslogboeken verschijnen. Gebruik testtools zoals de robots.txt-tester van Google Search Console of de Robots.txt Tester van Merkle om je configuratie te valideren. Bekijk je robots.txt-bestand direct op jouwsite.com/robots.txt om te controleren of de inhoud klopt. Monitor je logs regelmatig om crawlers te traceren die ondanks blokkade toch verschijnen.
AmICited.com volgt realtime AI-verwijzingen naar je merk via ChatGPT, Perplexity, Google AI Overviews en andere AI-systemen. Neem datagedreven beslissingen over je crawlerbeheerstrategie.
Ontdek hoe je strategische beslissingen neemt over het blokkeren van AI-crawlers. Evalueer inhoudstype, verkeersbronnen, verdienmodellen en concurrentiepositie ...

Begrijp hoe AI-crawlers zoals GPTBot en ClaudeBot werken, hun verschillen met traditionele zoekmachine-crawlers en hoe je je site optimaliseert voor AI-zoekzich...

Ontdek welke AI-crawlers je moet toestaan of blokkeren in je robots.txt. Uitgebreide gids over GPTBot, ClaudeBot, PerplexityBot en 25+ AI-crawlers met configura...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.